







关于远程调用:
使用背景:
在微服务开发时,不同的业务处在不同的模块内,不同的模块分别掌管不同的功能,不会出现重复的业务
如,进行多表查询时,针对每一个表都有一个模块。内置查询操作,不会因为需要多表查询而将对另一个表的功能在其他表内再写一遍,在这种情况下实现跨服务联查,就需要使用 远程调用
概念:
在微服务环境下,每一个模块本身都是可以通过浏览器地址栏发送http协议来进行访问业务的(对路径的声明在controller内定义),想要实现远程调用,就需要在模块内发送http协议,对其他的模块业务进行调用
其中,暴露接口给其他微服务调用的角色是 服务提供者 ,调用其他微服务的是 服务消费者 ,是相对的(类似相对运动那样)
方法:(http请求采取的是硬编码方式)
在SpringBoot的Application类(实际上本质是config)定义一个获取RestTemplate对象的方法,设置@Bean交给spring管理
在service层内需要进行查询时,创建@Autowire的RestTemplate对象,调用对象的getForObject或postForObject方法,将http请求填入这个方法的第一个参数(注意拼接),第二个参数声明返回类型(实际上是返回的那个pojo类)
such:
String url ="http://localhost:8081/user/"+order.getUserId();
User forObject = restTemplate.getForObject(url, User.class);
将这个对象set到本来需要返回到的对象内(比如order对象内的user对象的set方法),多表联查就成功了
Eureka注册中心:【调控远程调用】
分类:
eureka客户端【eureka-client】:服务消费者 和 服务提供者 的统称
eureka服务端【eureka-service】:注册中心
eureka-service 与 服务提供者:
每一个 服务提供者 都会将相关的服务信息(如端口号)注册进入 eureca-service 注册中心,
eureka-service 与 服务消费者
当 服务消费者 需要进行服务调用时,就会向eureka-service发送查询,获取对应的服务的 全部信息(比如同样的服务有三个,这三个信息将会被全部获取到)
然后通过负载均衡从这些信息内挑出一个,发送http请求,进行远程调用
服务信息存留与心跳续约:
这期间,服务提供者和eureca注册中心之间存在 心跳续约 ,即每间隔一定时间后就会向注册中心发送一次请求,表示这个服务可以正常使用,没有检测到请求,eureka就会将这个服务提供者的相关信息移除,这样这个出现异常的服务就不会被调用到了(让 服务消费者 可以 随时监控 到服务的状态)
服务列表缓存:
定时对eureca-service进行数据拉取,拉取到的数据存入服务列表缓存,提高效率,间隔一定时间后自动拉去更新信息
Eureka的搭建:
- 引入依赖
eureka-service内【服务端】:
<dependency>
<groupId>org.springframwork.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
eureka-client内【用户端】:
<dependency>
<groupId>org.springframwork.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
<version>4.0.0</version>
</dependency>
【未知原因,对用户端进行配置时,不添加版本信息会报错】
服务端版本信息在父类的如下依赖内:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
2 . 在SpringBoot的Application类【启动类】内添加开关注解 @EnableEurekaServer
3 . 添加application.yml文件配置
- server:port:端口
- spring:application:name:这个微服务的名称(本质是id)
- eureka:client:service-url:defaultZone:http://localhost:eureka-service的端口号/eureka:eureka的地址【搭建多个eureka集群时,方便eureka之间互相关联管理,这里将会配置多个地址,将这些地址注册入eureka】
4 . 在浏览器地址栏输入服务端的http访问路径就可以对 Eureka 的情况进行查看了
Eureka的配置变动:
1 . 将eureka服务端搭建完成,且将客户端注册进入后,客户端之间的调用就可以使用yml里对应的 微服务名称【id】 代替手动填写的http请求中的 local host:8080
2 . 在application启动类内添加@LoadBalanced注解,开启负载均衡
Nacos注册中心:【Eureka的上位产品?】
对于服务注册信息,Eureka只支持定时拉取,Nacos则在支持定时拉取的同时,消息列表发生更新时,自动修改服务列表缓存内的信息【主动推送】
Nacos注册中心开启:
在nacos的bin目录呼出cmd窗口输入指令 startup.cmd -m standalone 开启nacos服务
pom文件内添加nacos 发现客户端 依赖【nacos仅有客户端发现依赖,没有服务端依赖,?因为不同于eureka,nacos的服务端设置方式是通过cmd?】
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
yml文件内添加 nacos服务端的地址端口配置【默认时即为8848】
spring:
cloud:
nacos:
server-addr: localhost:8848 #nacos服务地址
在浏览器的地址栏访问启动nacos后的cmd界面右侧的http请求地址:
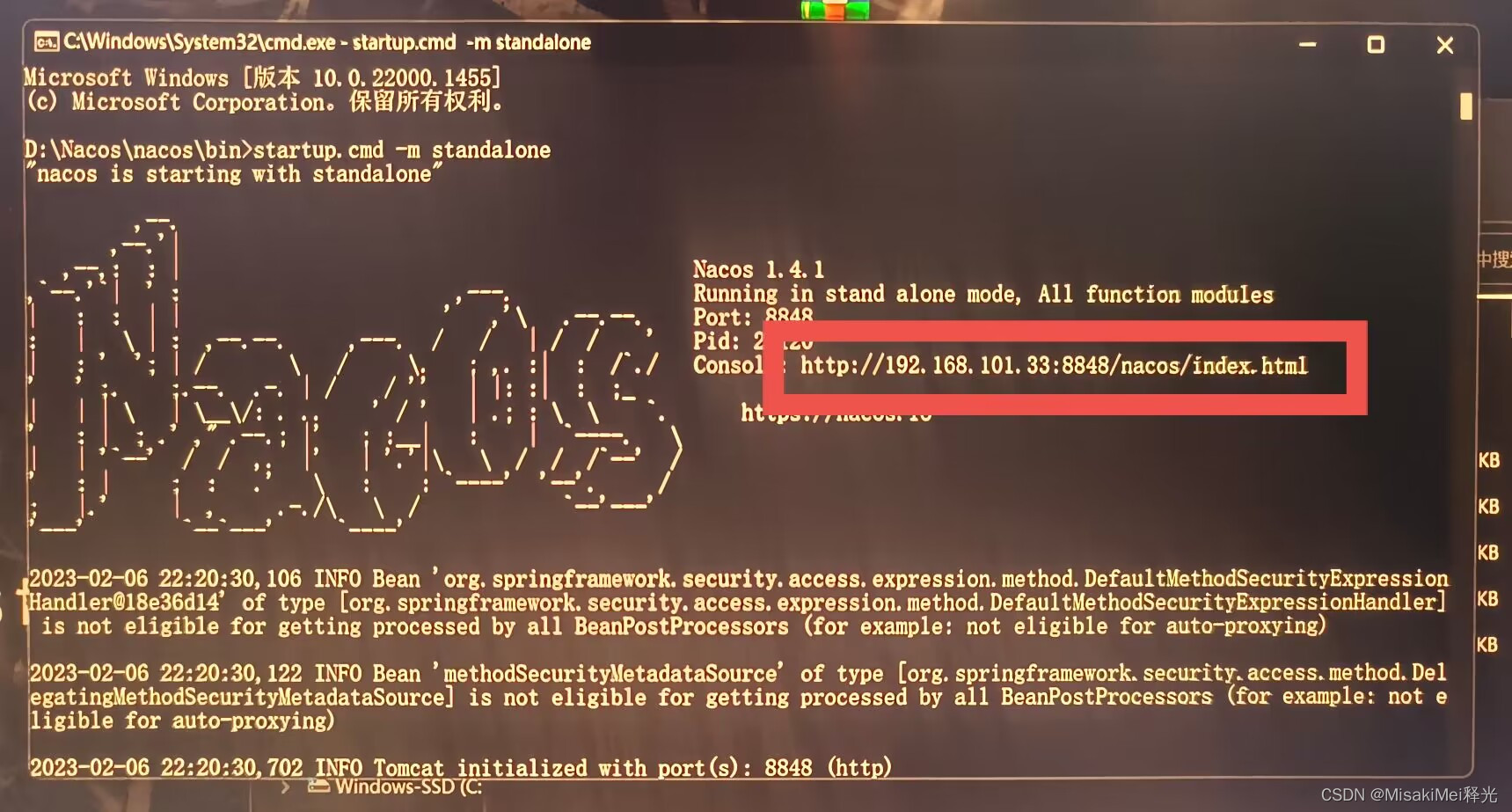
服务列表内就会出现nacos客户端的信息了
Nacos的服务分级存储模型:
第一级:服务【such:userservice这种服务】
第二级:集群【一般按地区划分,such:杭州集群,上海集群等】
第三级:实例【such:不同的userservice服务实现的实例】
实例集群的配置:
1 . 开启idea的多实例模式 【edit configuration内勾选指定服务的modify options内的allow multiple instances】 (这是因为要用一个实例来模拟多个实例)
2 . 在想要配置集群的服务的yml文件内添加集群配置spring:cloud:nacos:discovery:cluster-name:自定义集群名
NacosRule访问规则:
当 服务消费者 调用 服务生产者 时,可以 设置优先调用同一个集群内的服务 【因为集群一般是按地区划分的,跨地区的访问会耗费更多的时间,所以优先选择本地集群可以提高效率】
配置:
在服务消费者的yml文件内将IRule的负载均衡规则设置为NacosRule【优先本地,在本地集群的多个服务内随机访问】:
userservice【对应的服务生产者名】:ribbon:NFLoadBalancerRuleClassName:com.alibaba.cloud.nacos.ribbon.NacosRule
在设置为NacosRule访问规则时,出现跨集群调用会在服务消费者的控制台报一个跨集群调用的警告[非错误]:
02-07 12:04:42:015 WARN 20584 --- [nio-8080-exec-1] c.alibaba.cloud.nacos.ribbon.NacosRule : A cross-cluster call occurs,name = userservice, clusterName = misakimei, instance =[Instance{instanceId='192.168.101.33#8083#misaki#DEFAULT_GROUP@@userservice', ip='192.168.101.33', port=8083, weight=1.0, healthy=true, enabled=true, ephemeral=true, clusterName='misaki', serviceName='DEFAULT_GROUP@@userservice', metadata={preserved.register.source=SPRING_CLOUD}}]
Nacos服务实例的权重:
原因:不同的服务器的工作能力是不同的,所以针对不同的服务实例可以通过对 实例权重 的修改来影响不同服务的使用次数
(权重的值越小,访问到的几率越低,权重为零时不会被访问到)
方法:在启动Nacos后打开的网址上找到对应的服务,点击编辑,直接修改权重
灰度测试:
在进行业务更新,重启服务后,首先将这个新的服务的 权重调小 ,让少部分用户进行使用,确认无问题后,再将权重值调大
环境隔离:
原因:按功能进行区域划分隔离
具体:namespace > group > service >集群 > 服务实例
配置:
1 . 在nacos启动的网站的 命名空间 选项内新建命名空间,将随机生成的id记录下来
2 . 在yml文件内进行如下配置
spring:
cloud:8
nacos:
discovery:
namespace:【命名空间的id】
【不在同一个命名空间内的两个业务无法作为服务消费者和提供者进行 互相调用,报错:找不到实例】
Nacos的实例:
不同于Eureka,Nacos的实例分为临时实例【默认】和非临时实例
临时实例【心跳模式】:和Eureka一样,隔一定时间后临时实例向Nacos注册中心发一次‘心跳’,证明这个程序还能正常运行,如果心跳检测失败,这个实例会被从列表移除
非临时实例【主动检测】:隔一段时间后,Nacos注册中心会向这个实例发送一次请求,确认这个实例是否还能正常运行,如果不能运行,并不会从列表剔除这个实例,而是等待这个实例可以运行为止【在非临时实例加载后,将这个实例的线程杀死,这个非临时实例仍然存在于Nacos检测中心内,只是 健康状态 变成了false】
注:主动检测对服务器的压力比较大,所以推荐使用临时检测
非临时实例的配置:
spring:
cloud:
nacos:
discovery:
ephemeral: false【非临时】
Nacos配置管理:【从添加到使用】
创建Nacos配置文件:
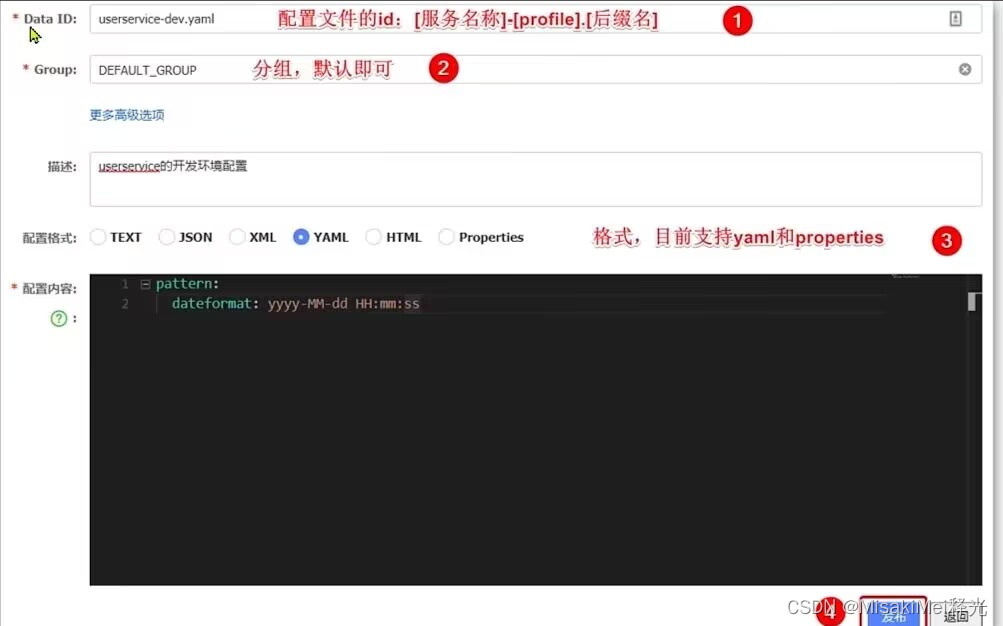
1 . 在注册中心网址内选择 配置管理 --> 配置列表 ,
2 . 点击新建配置,DataId 输入 服务名-环境类型.后缀名,在下方根据后缀名勾选对应的配置格式,
3 . 将需要修改的开关类配置填入配置内容模块
示例:
Nacos生效流程:
正常工程:项目启动 --> 读取本地配置文件[application.yml] --> 创建Spring容器 --> 加载Bean
有Nacos配置文件的工程:项目启动 --> 读取Nacos配置文件 --> 读取本地配置文件[application.yml] --> 创建Spring容器 --> 加载Bean
要 读取Nacos配置文件 ,必须提前知道他的地址,放在后执行的application.xml内显然不行,于是选择了将Nacos配置文件地址放在 执行非常早的 bootstrap.yml 配置文件内
配置步骤:
1 . 引入Nacos 配置管理客户端 依赖:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
2 . 新建 bootstrap.yml 文件【优先级更高的引导文件】,填入如下配置:
spring:
application:
name: userservice #服务名
profiles:
active: dev #开发环境类型
cloud:
nacos:
server-addr: localhost:8848 #Nacos配置文件地址【即端口】
config:
file-extension: yaml #配置文件类型【与上文设置的相同】
测试这个配置文件是否配置成功:
创建一个变量,注明@Value注解,内填 配置内容的ID 【如${pattern.dateformat}】,验证这个变量是否注入成功
不成功的原因:
1 . 配置没有添加在public命名空间内
2 . springboot版本2.4后,bootstrap.yml文件不再被优先读取了
3 . 输入数据时拼写出错
Nacos配置的热更新实现:
仅仅配置了Nacos配置文件。对于已经打开的网页,修改配置文件并刷新网页并不能生效,达到热更新目的,需要进行其他配置
方法一 . 在controller内创建一个成员变量,使用@value注解,内置 配置内容的ID 【如${pattern.dateformat}】
在这个controller类上添加注解@RefreshScope【在控制台上可以查看到这次热更新的细节情况】
方法二 . (更常用) 创建一个类,添加@Component注解将这个类交给Spring容器,类内置一个属性,类上添加 @ConfigurationProperties(prefix = "pattern") 注解,类内定义一个变量
确保注解内prefix的值和类内的变量名拼接起来是需要读取的 Nacos配置文件内 对应的id,在需要打印的controller类内创建这个类的对象,添加@Autowire注解
在@ConfigurationProperties注解的作用下,热更新的目的达到了
Nacos配置分享:
目的:实现多环境下相同的配置不进行重复配置
方法:在Nacos配置环境添加配置文件 服务名.yaml 如:【userservice.yaml】,这样的配置可以在dev,test等不同的环境下配置【区别于常规的userservice-dev.yaml】
优先级:
userservice-dev.yaml > userservice.yaml > idea内的本地配置文件
微服务启动时会从Nacos内读取的配置文件:userservice.yaml userservice-dev.yaml
Nacos集群搭建:
尚未掌握【涉及知识】
总结Nacos和Eureka的区别:
Nacos主动检测,Nacos非临时实例,Nacos消息推拉,Nacos集群AP,非临时转CP,Eureka恒定AP
Feign:【http请求】
简介:
在远程调用时,使用String拼接,RestTemplate的方式进行模块间的业务调用不方便且难以维护,于是使用Feign进行客户端访问
步骤:
1 . 引入Feign依赖【在服务消费者的pom内】
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
2 . 在Application启动类上添加 @EnableFeignClients 注解【相当于开关】
3 . 编写一个FeignClient接口:【代替之前的String拼接】
@FeignClient("userservice")//设置http请求内的服务名称
public interface UserClient {
@GetMapping("/user/{id}")
User findById(@PathVariable("id") Long id);
}
4 . 改变service内的操作:
public Order queryOrderById(Long orderId) {
// 1.查询订单
Order order = orderMapper.findById(orderId);
// 2.利用RestTemplate发起http请求,实现对用户的查询
// User user = userClient.findById(order.getUserId());
User user = userClient.findById(orderId);
// 3. 封装user到order
order.setUser(user);
// 4.返回
return order;
}
注意:
使用Feign时实现了负载均衡,是因为Feign依赖了Ribbon
Feign日志:
默认情况下没有日志,如果要修改日志配置,可以进行如下配置:
1 . 使用配置文件修改日志信息:
在application.yml文件内添加如下配置:
feign:
client:
config:
default: #default指全部,如果想进行单个服务的配置,就将这个config改成对应的服务名称
loggerLevel: #FULL指定日志模式
2 . 使用Java代码进行修改:
创建一个配置类(config),声明Bean:【该配置对应服务提供者的controller类内方法的配置】
public class DefaultFeignConfiguration {
@Bean
public Logger.Level logLevel(){
return Logger.Level.FULL; 在return时,填写这里枚举的日志级别。
}
}
但是仅仅是创建这样一个config类,这个Bean并不会被创建,还要根据需求声明这个Bean
(1) . 使用Java代码进行全局修改:
在springboot的启动类内的 @EnableFeignClients 注解内,将defaultconfiguration的值定义为设置日志级别的这个config类:
例:
@EnableFeignClients(defaultConfiguration = DefaultFeignConfiguration.class)
(2) . 使用Java代码进行针对单个服务的修改:、
在配置http请求发送的client类内的 @FeignClient 注解内,将configuration的值定义为设置日志级别的这个config类:
例:
@FeignClient(value = "userservice",configuration = DefaultFeignConfiguration.class)
注:
value对应的是日志级别针对的服务
日志级别:full:全部日志,basic:基本,headers:基本+请求头,none:没有日志
注:
正常情况下使用basic,调错时用full
Feign性能调优:
Feign实际上是一个声明式客户端【将声明转变为http请求】,其依赖底层的客户端实现完成http请求的发送
URLConnection:默认的底层客户端【不支持连接池,性能低】
Apache HttpClient:支持连接池
OKHttp:支持连接池
调优的本质:
1 . 使用其他的底层客户端代替低效率的 URLConnection
2 . 改变日志模式【full等记录过多日志的日志模式会显著拖缓效率】
步骤:
1 . 引入HttpClient依赖
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-httpclient</artifactId>
<version>9.5.0</version>
</dependency>
未知原因,版本不能省略【大概是springboot版本问题】
2 . 在application.yml文件内添加如下配置:【真实业务中连接数要通过压测来判断】
feign:
httpclient:
enabled: true #支持httpclient开关
max-connections: 200 #最大连接数
max-connections-per-route: 50 #单个路径最大连接数
Feign的最佳实践:
方法一:继承【面向契约的编程思想】
因为服务消费者的Client类内的http设置和服务提供者的controller内的路径方法一一对应,所以可以设置一个统一的父接口让两者继承
缺点:
1 . 紧耦合
2 . controller内的业务代码仍然需要书写
方法二:抽取
针对情况:当多个服务消费者均需调用同一个服务提供者实现业务时,FeignConfig,pojo,DefaultConfig【日志级别】书写了多次,效率过低
步骤:
1 . 将client,pojo,Feign日志config抽取成一个独立的模块
2 . 在其他服务消费者的pom内添加这个Feign-api的依赖
在这种情况下直接启动会出现一个报错:
a bean of type 'cn.misakimei.feign.clients.UserClient' that could not be found
因为在模块抽取前,client类因为在 启动类所在的包下 而被spring容器实例化成功,抽取模块后不再被扫描到
解决方法:
1 . 在启动类的@EnableFeignClient注解内对bacePackages赋值为client所在的包路径
such:
1 . 在启动类的@EnableFeignClient注解内对clients赋值为具体的client类名
such:
clients = UserClient.class
出现的异常:
Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception
原因【可能】:feign-httpclient和spring-cloud-starter-openfeign依赖的版本不统一
Ribbon:【负载均衡】
流程:
发起 拼接 http请求的流程:【拉取返回信息的eureka-server,向eureka-service拉去获得信息的DynamicServerListLoadBalancer,负载均衡的IRule,直接连接 服务提供者 和 服务消费者 】
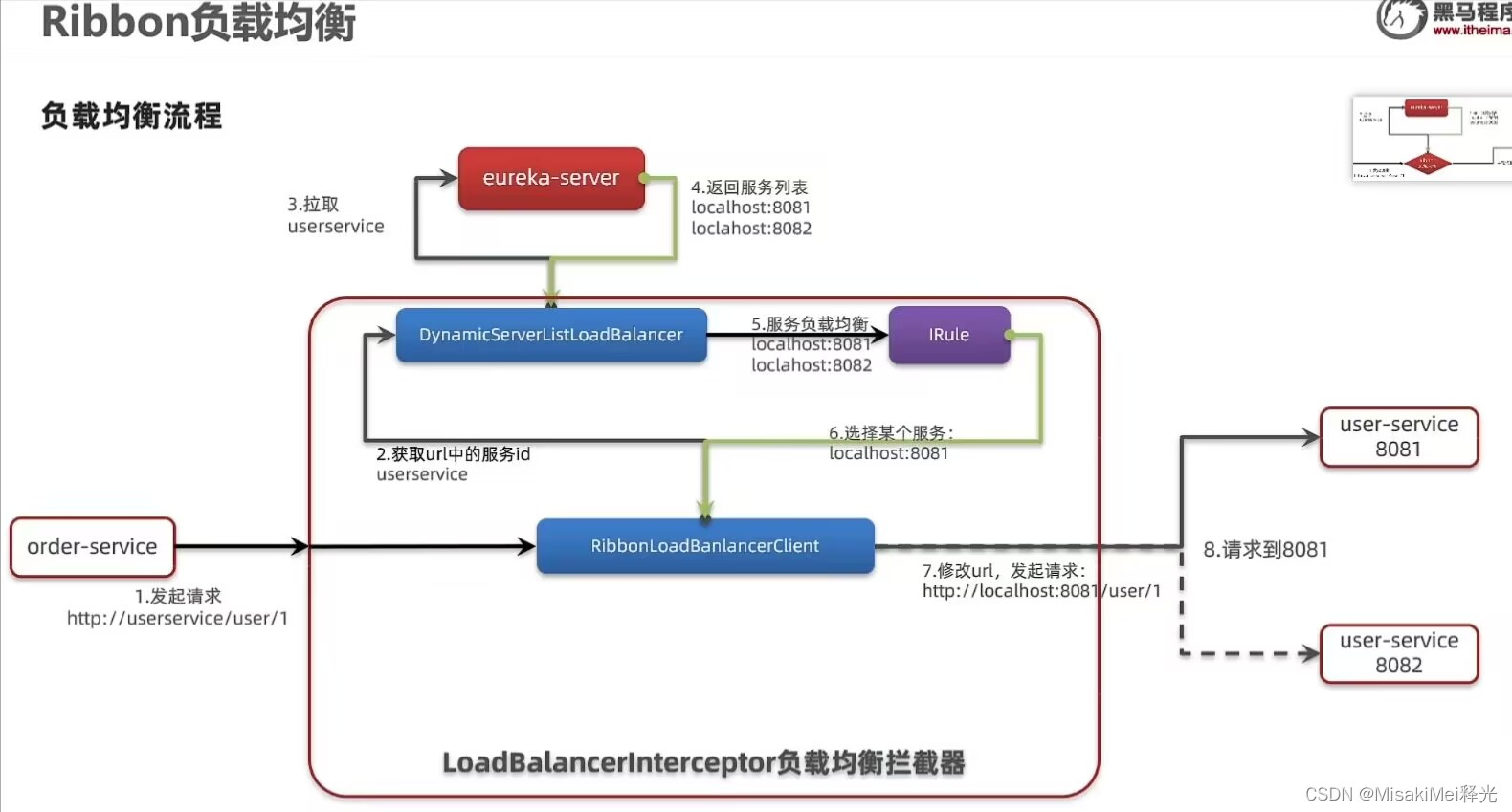
IRule:【负载均衡组件】
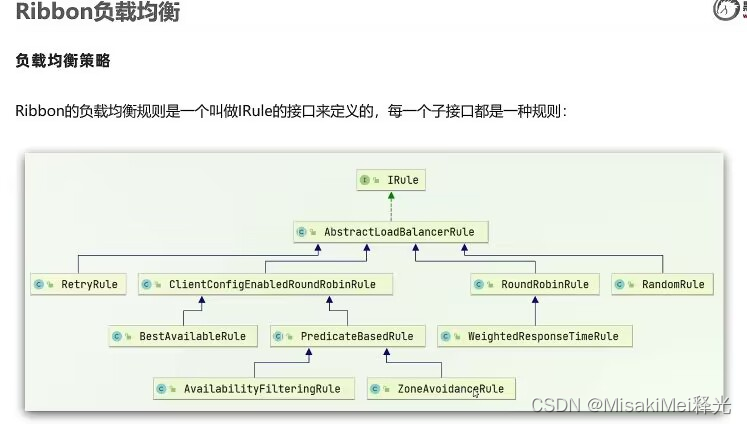
AvailabilityFilteringRule:
忽略 三次连接均失败的服务器 和 并发数过高的服务器
ZoneAvoidanceRule:
通过Zone进行 服务器的区域划分【可以理解成分 机架 和 机房 】,然后再对Zone内的服务进行轮询【但是在正常情况下,没有Rule这个概念,本质就仅仅是轮询】
BestAvailableRule:
忽略短路的服务器,选择并发量低的服务器
RandomRule:
随机选择可用的服务器
RoundRobinRule:
简单轮询列表选择服务器
WeightedResponseTimeRule:
为服务器赋一个权重值,值的大小影响这个服务器被选中的概率
ReturyRule:
重置选择逻辑
负载均衡策略的调整:
方法一 :【修改这个服务消费者调用的 所有 服务提供者的 负载均衡策略 】
在 服务消费者 的Application启动类内【或者是controller类内等可以配置@Bean的地方】添加一个@Bean标注的方法,返回类型为,
return一个RandomRule对象,这样就将服务消费者的 所有服务调用 的负载均衡策略调整为随机。
方法二:【修改这个服务消费者调用的 指定 服务提供者的 负载均衡策略 】
在 服务消费者的yml文件 内进行负载均衡的相关配置,添加如下配置:
userservice【服务提供者的服务名】:
ribbon:
NFLoadBalancerRuleClassName:com.netflix.loadbalancer.RandomRule
这样能将 指定的服务提供者 的负载均衡策略调整成随机
加载方式:
概况:
正常情况下,第一次http请求的耗时会远大于之后的请求,因为Ribbon默认采取了 懒加载 的加载方式,在访问发出时,才去创建 LoadBalanceClient ,花费了很长的请求时间
对于这种i情况可以配置 饥饿加载 来减少这个时间
在 yml 内添加如下配置
ribbon:
eager-load:
enabled: true 【开启饥饿加载】
clients: 【设置修改为 饥饿加载 的服务名称 (id) 】
- userservice
Gateway:【统一网关】
作用:
1 . 身份认证前沿先校验
2 . 服务路由,负载均衡
3 . 请求限流
实质:
将直接针对服务发送的请求改成针对网关发起,然后网关向Nacos拉取信息再调用对应的服务
配置:
单独为Gateway创建一个SpringBoot工程(SpringBoot相关依赖均继承自父工程)
1 . 添加依赖:nacos服务发现依赖 和 网关gateWay依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
<version>2.2.1.RELEASE</version>
</dependency>
2 . 添加配置文件:
添加网关端口,为GateWay:
设置端口号,
创建服务的名称和对应的nacos的地址,
将GateWay服务注册进nacos注册中心
设置网关路由:
id是每一个路由规则的独特标识,
url设置负载均衡的地址:
lb://userservice,意义:路由的目标地址为userservice服务,且告知nacos使用负载均衡机制(lb是负载均衡loadbalance的缩写)
url也可以取http: //127.0.0.1:8080/这样写死的地址,但是一般不这样使用,因为无法使用负载均衡等
断言(判断路由的规则)指定的路径前加端口号将是对网关访问的方式
解析路由规则需要通过PredicateFactory:断言工厂
path是指定的断言规则,针对每一种路由规则,都有对应的断言工厂进行解析,path是最常用的,同一个路由内可以配置多个断言限制,只有全部符和才能成功访问
after断言:指定时间之后,且地区等参数符合
Before断言:指定时间之前,且地区等参数符合
例: - After=2033-02-23T13:24:46.433+08:00[Asia/Shanghai]
例:
server:
port: 10010 //网关端口
spring:
application:
name: gateway //服务名称
cloud:
nacos:
server-addr: localhost:8848 //nacos地址
gateway:
routes: //网关路由配置
- id: user-service //路由id
uri: lb://userservice //路由目标地址
predicates: //路由断言(指定路由规则)
- Path=/user/** //指定的路径
- id: order-service
uri: lb://orderservice
predicates:
- Path=/order/**
具体变化:
直接访问:http://localhost:8085/userservice/1
通过网关:http://localhost:10010/user/1
GatewayFilter:【路由过滤器】
作用:
对请求和响应做一些处理
配置:【yml配置方法实现过滤器】
在GateWay的yml内添加过滤器,
针对单个断言所对应的单个工程:添加filters,配置过滤器
针对网关内全部断言:添加与routes标签平行的default-fileters【默认过滤器】,整体配置过滤器
spring:
application:
name: gateway
cloud:
nacos:
server-addr: localhost:8848
gateway:
routes:
- id: user-service
uri: lb://userservice
predicates:
- Path=/user/**
# - After=2033-02-23T13:24:46.433+08:00[Asia/Shanghai]
filters:
- AddRequestHeader=Truth,misakimei is cool!
- id: order-service
uri: lb://orderservice
predicates:
- Path=/order/**
default-filters:
- AddRequestHeader=Truth,misakimei is cool! #格式:添加请求头=请求头名称,请求头具体内容
此处AddRequestHeader过滤器为添加请求头,可以在controller内的参数栏添加形参,形参前添加@RequestHeader注解,注解内对value属性赋值为请求头名称
例:
@GetMapping("/{id}")
public User queryById(@PathVariable("id") Long id,@RequestHeader(value = "Truth",required = false)String truth) {
System.out.println(truth);
return userService.queryById(id);
}
GlobalFilter【全局过滤器】:
1 . 创建一个类,继承GlobalFilter接口,继承接口内的方法,添加接口@Component和@Order
2 . 对方法的第一个形参exchange调用getRequest方法得到一个ServerHttpRequest类,调用类的getQueryParams方法获取 全部的请求参数(http请求内的)【在一个Map内】
3 . 对Map调用getFirst方法,方法内填写参数名
4 . 对这个参数进行一系列判断【此处添加自定义的业务逻辑】
5 . 根据判断的结果,自主选择放行或拦截
放行:
return 接口方法的第二个形参chain的filter方法,方法内传第一个形参exchange,将业务放行到下一个过滤器
拦截:
设置状态码【方便管理】: exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);//此处添加了401状态码
return 接口方法的第一个形参exchange.getResponse().setComplete();
关于上文提到的下一个过滤器:
过滤器类添加的@Order注解内设置的数字,越小执行优先级越高
@Order(-1)
@Component
public class AuthorizeFilter implements GlobalFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//获取请求参数
ServerHttpRequest request = exchange.getRequest();
MultiValueMap<String, String> queryParams = request.getQueryParams();
//获取具体参数
String authorization = queryParams.getFirst("authorization");
//判断
if ("admin".equals(authorization)) {
//放行
return chain.filter(exchange);
}
//设置状态码
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);
//拦截
return exchange.getResponse().setComplete();
}
}
像这样配置后,需要这样访问:http://localhost:10010/user/1?authorization=admin
缺乏authorization【授权】属性或者授权属性不正确均会被拦截
过滤器链:
原理:
当同时配置了路由过滤器和全局过滤器时,会依次路由到这些过滤器,然后连接成过滤器链,依次执行
注:
本质上,两种路由过滤器【gatewayfilter】是同一种类型,但是globalfilter是其他类型,于是底层存在继承gatewayfilter接口的gatewayfilteradapter【网关过滤器适配器】,内置了globalfilter类型的变量,这样所有的过滤器就都整合成了gatewayfilter,这样,所有的过滤器就可以放在一个集合内进行排序了
排序:
本质上,排序的依据就是Order内的值。
对于貌似无法添加order的两种路由过滤器,其Order值是spring自动提供的。从他们各自的第一个过滤器开始,Order值自1递增
例:
filters:
- AddRequestHeader=Truth,misakimei is cool! #Order=1
- AddRequestHeader=Truth,misakimei is cool! #Order=2
- AddRequestHeader=Truth,misakimei is cool! #Order=3
default-filters:
- AddRequestHeader=Truth,misakimei is cool! #Order=1
- AddRequestHeader=Truth,misakimei is cool! #Order=2
- AddRequestHeader=Truth,misakimei is cool! #Order=3
【GlobalFilter】
@Order(1)
@Order(2)
@Order(3)
对于Order值相等的过滤器,按照:【Defaultfilter > 路由过滤器 > Globalfilter】的顺序执行
GateWay跨域:
暂时未掌握【涉及ajax前端知识】
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











