






1.读取mainland.csv文件创建一个DataFrame,以province作为索引列。添加新列GDP_P计算各省的人均GDP,并根据人均GDP(GDP*106106/population)进行降序排序。最终结果是一个命名为df1的DataFrame。
提示:obj['GDP_P']=val,直接创建新列。计算结果取整(astype)。
df1=pd.read_csv(abspath('mainland.csv'),index_col='province')
df1['GDP_P']=((df1['GDP']*(10**6))/df1['population']).astype('int64')
df1=df1.sort_values(by='GDP_P',ascending=False)2.读取数据trains.csv,添加字段Duration计算每个车次的历时。如果到达时间小于出发时间,表示第二天到达。最终结果是一个命名为df2的DataFrame。参考教材9.6节。
提示:
1) timedelta(days=1)表示一天的时间差,因此a<timedelta(days=0)表示时间差为负数。
2) datetime类型可以计算时间差,但time类型无法计算时间差
部分结果样例: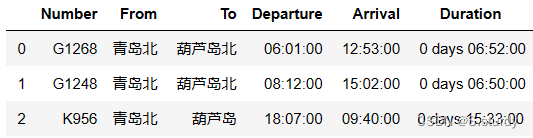
from datetime import timedelta
df2=pd.read_csv(abspath('trains.csv'),parse_dates=['Departure','Arrival'])
df2['Duration']=df2['Arrival']-df2['Departure']
df2.loc[df2['Duration']<timedelta(days=0),'Duration']+=timedelta(days=1)
df2['Arrival']=df2['Arrival'].dt.time#删除年月日
df2['Departure']=df2['Departure'].dt.time3.在第2题的基础上,添加字段Order计算历时从少到多的顺序(从1开始)。最终结果是一个命名为df3的DataFrame。
注意:注意:不要改变原始数据顺序
部分结果样例: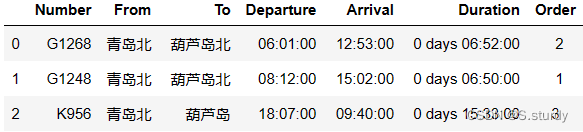
df3=df2.sort_values('Duration')
df3['Order']=pd.Series(range(1,len(df2)+1),index=df3.index)
df3.sort_index(inplace=True)4.读取鸢尾花数据iris.csv,返回其中petal_length列为指定输入为s的所有petal_width之和。结果保留一位小数。
样例输入:
1.4
样例输出:
2.7
def fun4(s):
"""
return a float with accuracy of 1 decimal points
"""
df4=pd.read_csv(abspath('iris.csv'),index_col='petal_length')
res=df4[df4.index==s]['petal_width'].sum()
return round(res,1)5.对于给定文件Chicago.csv,输入一个Department名称,输出该部门的平均工资(保留小数点后2位)。注意,工资字段Salary列的数值前有一个$符号。
样例输入:
AVIATION
样例输出:
70638.25
def fun5(department='AVIATION'):
"""
return a float with accuracy of 2 decimal points
"""
df5=pd.read_csv(abspath('Chicago.csv'),index_col='Department',converters={'Salary':lambda x:float(x.replace('$',''))})
res=df5[df5.index==department]['Salary'].mean()
return round(res,2)6.
- 教材9.7的源代码如下。求每个部门最高收入的所有员工信息。要求不使用自定义函数ranker,不新增列,利用内嵌函数numpy.idxmax完成。返回结果为符合要求的所有数据构成的DataFrame,包含所有列。Salary中不包含\。结果按Department升序排序,重置索引重置索引。结果名称为df6。
提示:现获取目标员工的index,然后用isin函数或loc对索引进行布尔选择。
教材源代码:
chicago = pd.read_csv(abspath('Chicago.csv'),encoding='utf8',converters={'Salary': lambda x: float(x.replace('$', ''))})
by_dept = chicago.groupby('Department')
def ranker(df):
"""Assigns a rank to each employee based on salary, with 1 being the highest paid."""
df['d_rank'] = np.arange(len(df)) + 1
return df
chicago.sort_values('Salary', ascending=False, inplace=True)
chicago = chicago.groupby('Department').apply(ranker)
chicago[chicago.d_rank == 1][['Name','Position Title','Department','Salary']].head()部分结果示例:
df6=pd.read_csv(abspath('Chicago.csv'),converters={'Salary':lambda x:float(x.replace('$',''))})
max=df6.groupby('Department').idxmax()
df6=df6[df6.index.isin(max['Salary'])==True]#布尔选择
df6=df6.sort_values('Department')
df6.index=range(len(df6))#注意重置索引















 1582
1582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









