







1、rs控制器
1、rs介绍
-
rs通过标签控制po的,pod被误删的话,会自动的创建出来
-
副本数量
2、rs管理pod
[root@master rs]# cat rs1.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: rs1
namespace: dev
spec:
replicas: 3 #副本数量为3,三个pod
selector:
matchLabels:
app: ff1
template:
metadata:
labels:
app: ff1
spec:
containers:
- name: c1 #name没有意义, 根据控制器的名字决定的
image: docker.io/yecc/gcr.io-google_samples-gb-frontend:v3
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
startupProbe:
initialDelaySeconds: 20 #启动后过了20秒,开始检测,充分的时间加载配置文件
periodSeconds: 5
timeoutSeconds: 1
httpGet: #curl http://localhost:80
scheme: HTTP
port: 80
path: /
[root@master rs]# kubectl get rs -n dev
NAME DESIRED CURRENT READY AGE
rs1 3 3 3 42s
[root@master rs]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
rs1-8g47s 1/1 Running 0 45s
rs1-kphgx 1/1 Running 0 45s
rs1-vd6xk 1/1 Running 0 45s
#如果删除一个pod的话,会在重新创建一个pod
[root@master rs]# kubectl delete pod -n dev rs1-kphgx
pod "rs1-kphgx" deleted
[root@master rs]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
rs1-8g47s 1/1 Running 0 3m36s
rs1-rdf2m 0/1 Running 0 5s
rs1-vd6xk 1/1 Running 0 3m36s
3、rs扩容和缩容
都是通过改变文件中的副本数量来决定的
3、rs更新
换镜像的版本即可
- 非常的不方便,升级的话,需要删除原来的pod,这样的话,业务就终止了
# image: docker.io/yecc/gcr.io-google_samples-gb-frontend:v3换成nginx
#访问的页面不同
#需要删除原来的pod,然后就运行了新版本的pod
[root@master rs]# curl 10.244.104.41:80
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
2、deployment控制器
1、deployment介绍
-
创建deployment时,会创建一个新的rs,然后创建Pod,通过rs管理pod
-
删除deployment话,也会删除rs,pod
-
更细的话,新镜像的版本的会产生一个新的rs,把旧的rs替换掉,多个rs同时存在,但是只有一个rs存在
-
更新的话,会创建一个新的Pod,然后删除之前旧的pod,这个就是更新策略和更新逻辑
-
作用,滚动升级,回滚应用,扩容和缩容,暂停和继续ddeploy
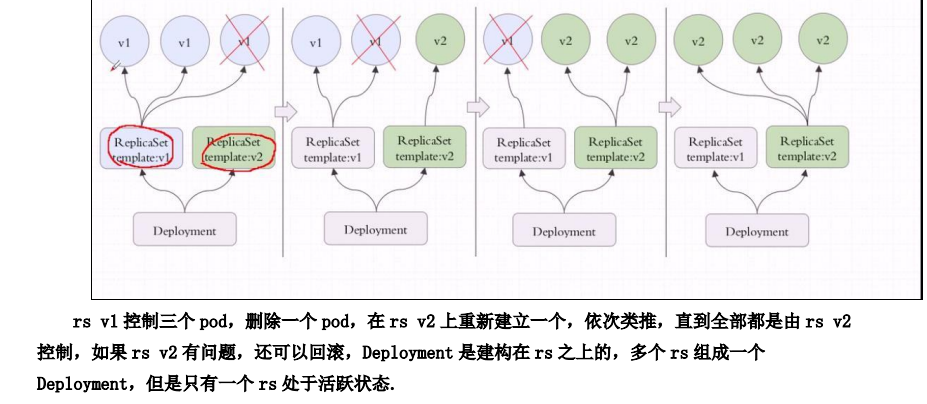
2、deployment管理pod
[root@master deploy]# cat web1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-v1
namespace: dev
spec:
replicas: 2
selector:
matchLabels:
app: myapp
version: v1
template:
metadata:
labels:
app: myapp
version: v1
spec:
containers:
- name: myapp
image: docker.io/janakiramm/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
startupProbe:
initialDelaySeconds: 20
periodSeconds: 5
timeoutSeconds: 1
httpGet:
scheme: HTTP
port: 80
path: /
#创建deploy后会创建rs,进而创建pod
[root@master deploy]# kubectl get deployments.apps -n dev
NAME READY UP-TO-DATE(创建了几个pod) AVAILABLE(pod就绪) AGE
web-v1 2(就绪状态)/2(期望的) 2 2 111m
[root@master deploy]# kubectl get rs -n dev
NAME DESIRED(期望管理pod) CURRENT(当前pod数量) READY(就绪pod) AGE
rs1 2 2 2 3h9m
web-v1-85c5595456 2 2 2 109m
[root@master deploy]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
rs1-dvkqz 1/1 Running 1 (12m ago) 173m
rs1-kpd75 1/1 Running 1 (12m ago) 173m
web-v1-85c5595456-ljk88 1/1 Running 1 (12m ago) 110m
web-v1-85c5595456-lpwb9 1/1 Running 1 (12m ago) 110m
[root@master deploy]# curl 10.244.166.169:80
3、扩容和缩容
修改文件副本数即可
4、deployment更新策略
-
kube-controller-manager管理控制器的
-
有重建更新和滚动更新
#控制更新的速度
maxSurge #1最多比目标数量多一个
maxUnavailable #为0个pod不能用
[root@master deploy]# cat web2.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deploy
namespace: dev
spec:
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-deploy
image: docker.io/library/nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
strategy: #会先创建一个pod就绪了,在删除一个pod即可
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
[root@master deploy]# cat s2.yaml
apiVersion: v1
kind: Service
metadata:
name: my-service
namespace: dev
spec:
selector:
app: my-app
type: NodePort #服务端口映射到主机端口上面
ports:
- port: 80
targetPort: 80
#pod端口映射到了服务上了,服务端口映射到了主机的端口上面了
#有一个service,外界就能访问pod里面内容了,类型为NodePort
[root@master deploy]# kubectl get svc -n dev
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-service NodePort 10.103.187.233 <none> 80(服务端口):30901(主机端口)/TCP 55s
#升级镜像
#修改文件的镜像,动态的观察deploy,rs,pod即可
#无感知的升级
#升级镜像后,会再创建一个rs,多个rs只有一个起作用
[root@master deploy]# kubectl get rs -n dev -l app=my-app
NAME DESIRED CURRENT READY AGE
my-deploy-5cc4c69d9f 3 3 3 4m24s
my-deploy-7fbd6d476c 0 0 0 26m
#查看历史版本,尽量在配置文件里面写好每个版本的镜像
[root@master deploy]# kubectl rollout history deployment -n dev my-deploy
deployment.apps/my-deploy
REVISION CHANGE-CAUSE
1 <none>
2 <none>
#回滚
#可以通过命令行或者改yaml文件即可,但是通过命令行修改的话,yaml文件没有被修改掉
[root@master deploy]# kubectl rollout undo deployment -n dev my-deploy --to-revision=1
5、基于反亲和性创建deployment
- 创建的pod不会调度到同一个节点上面
[root@master deploy]# cat web3.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web3
namespace: dev
spec:
replicas: 2
selector:
matchLabels:
app: myapp1
template:
metadata:
labels:
app: myapp1
spec:
containers:
- name: web3
image: docker.io/library/nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: kubernetes.io/hostname
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- myapp1
#这样的话,创建pod的话,就不会再同一个节点上面了
6、自定义滚动更新策略
-
maxUnavailable 这个值越小,服务更加稳定,建议为0
-
maxSurge值越大,更新的越快,建议为1
#更新的时候,允许最多3个pod运行,最少1个pod运行
#在更新的时候,会创建一个为就绪的pod,然后删除一个pod,这样只有一个Pod提供服务,就绪好后,在来创建一个pod,删除原来的pod,就绪,不稳定
#2个pod提供服务,突然删除一个pod,流量的均衡会受到影响
[root@master deploy]# cat web4.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web4
namespace: dev
spec:
replicas: 2
selector:
matchLabels:
app: web4
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
template:
metadata:
labels:
app: web4
spec:
containers:
- name: web4
image: docker.io/library/nginx:1.9.1
imagePullPolicy: IfNotPresent
3、statfulset控制器
1、statfulse原理
-
为了解决无状态服务的问题而设计的
-
创建的pod是有dns和名字的
-
有状态服务
-
他所管理的pod名称不能随意变化的,数据持久化目录也是不一样的
-
每一个pod都有自己独有的数据持久化存储目录
-
-
无状态服务
-
rc,deployment,daemonset,都是无状态的服务
-
管理的podip名字,启动顺序都是随机的,都是公用一个数据卷
-
2、操作
1、创建一个headliness service与statefulset结合
-
servicename pod直接通过这个进行通信
-
创建一个svc的服务即可
#创建一个statefulset控制器,svc
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
namespace: dev
spec:
serviceName: "nginx" #就是headless service,为每一个pod提供了网络标识符,唯一的dns
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: docker.io/library/nginx
imagePullPolicy: IfNotPresent
---
apiVersion: v1
kind: Service
metadata:
name: nginx
namespace: dev
spec:
type: ClusterIP
clusterIP: None #设置为None就是一个headless service,不会分配一个集群的ip,直接暴露每个pod的ip地址,让statefulset里的Pod通过dns互相访问
selector:
app: nginx
ports:
- name: nginx
targetPort: 80
port: 80
#创建的pod是有顺序的
[root@master kongzhiqi]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 66s
web-1 1/1 Running 0 65s
[root@master kongzhiqi]# kubectl get statefulsets.apps -n dev
NAME READY AGE
web 2/2 71s
#删除一个pod的话,ip会变但是名字不会变化
[root@master kongzhiqi]# kubectl delete pod -n dev web-0
pod "web-0" deleted
[root@master kongzhiqi]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 3s
web-1 1/1 Running 0 6m3s
#svc没有ip的话,直接进行解析svc的话,访问到pod对应的域名
#这个就是headless service,每一个pod都有唯一的dns
/ # nslookup nginx #这个就是那个无头服务,通过这个可以访问pod之间的域名和ip
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: nginx
Address 1: 10.244.104.31 web-1.nginx.dev.svc.cluster.local
Address 2: 10.244.166.154 web-0.nginx.dev.svc.cluster.local
#svc有ip的话,解析服务的ip出来
/ # nslookup nginx
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: nginx
Address 1: 10.109.172.145 nginx.dev.svc.cluster.local
#svc有ip更好,这样的话,直接进行转发到svc对应的pod上面
#没有ip的话,要进行dns域名解析为对应的ip才能进行访问呢
2、statefulset扩容和缩容
-
通过修改配置文件即可实现扩容和缩容
-
更新的策略,默认是滚动更新
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
namespace: dev
spec:
updateStrategy: #更新策略
rollingUpdate:
partition: 1 #序号大于等于1的pod进行更新
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: docker.io/library/nginx:1.9.1
imagePullPolicy: IfNotPresent
4、daemonset控制器
1、daemonset原理
-
daemonset控制器能够确保k8s集群每个节点上面都运行一个相同的pod
-
当增加了node节点时,daemonset控制器也会增加一个pod
-
删除daemonset控制器的话,Pod也会被删除
-
daemonset会监听daemonset对象,pod对象,node对象,监听的对象发生了变化的话,就会触发一个机制,syncloop会让k8s集群向daemonset演进
-
典型的应用场景
-
在每个节点上面运行存储,ceph
-
在每个节点上运行日志收集组件
-
在每个节点上面运行监控组件
-
-
daemonset和deployment区别
-
deployment可以在一个节点上面运行多个pod
-
daemonset只能在节点上面运行一个pod
-
2、daemonset字段
apiVersion:
kind:
metadata: #描述信息
spec:
selector: #标签选择器
3、操作
4、日志收集
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: d1
namespace: dev
spec:
selector:
matchLabels:
app: d1
template:
metadata:
labels:
app: d1
spec:
tolerations: #定义一个容忍度
- key: node-role.kubernetes.io/control-plane
operator: Exists #存在,不需要管value
effect: NoSchedule
containers:
- name: d1
image: docker.io/xianchao/fluentd:v2.5.1
imagePullPolicy: IfNotPresent
resources: #资源的限制,节点必须100m 200mi,这个pod超过这个资源的限制
requests:
cpu: 100m
memory: 200Mi
limits:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlib
mountPath: /var/lib/docker/containers
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlib
hostPath:
path: /var/lib/docker/containers
#
[root@master kongzhiqi]# kubectl get pod -n dev -l app=d1 -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
d1-5lzf7 1/1 Running 0 93s 10.244.166.161 node1 <none> <none>
d1-mn5ml 1/1 Running 0 93s 10.244.219.67 master <none> <none>
d1-t8jb2 1/1 Running 0 93s 10.244.104.41 node2 <none> <none>
5、滚动更新策略
- 因为每一个节点只能运行一个pod,所以在更新的时候,需要删除一个pod,然后来创建一个镜像
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: d1
namespace: dev
spec:
updateStrategy:
rollingUpdate:
maxUnavailable: 1 #滚动更新,就是先减少一个然后创建1一个
selector:
matchLabels:
app: d1
template:
metadata:
labels:
app: d1
spec:
tolerations:
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
containers:
- name: d1
image: docker.io/library/nginx
imagePullPolicy: IfNotPresent
resources:
requests:
cpu: 100m
memory: 200Mi
limits:
cpu: 100m
memory: 200Mi
5、hpa控制器
1、了解
- 实现扩缩容的控制器
-
扩缩容分为2种
-
node层面,实现node的扩缩容
-
pod层面
-
通过rs来进行控制副本的数量,之前的扩容和缩容的话,都是手动的
-
所以不能确定流量是否暴涨,需要一个监控访问的流量的一个软件,来实现自动扩缩容,从而应对流量突然的暴涨的情况
-
-
-
hpa(pod水平自动扩缩容)
-
监控cpu使用率,磁盘自定义等,来实现自动扩缩容服务中的pod数量
-
无缝增加pod的数量
1.哪些指标决定了扩缩容
-
cpu和内存指标,但是对于大多数的web的话,基于每秒的请求数量进行扩缩容,自定义
-
hpa v1基于cpu来实现
-
hpa v2基于cpu和内存和自定义指标(每秒请求数)
-
如何实现自动扩缩容
-
默认情况下30秒检查一下
-
为了避免频繁的扩缩容,5分钟之内没有扩缩容的情况,才实现扩缩容
-
-
扩容之后,流量立马减了下来,也不会立即进行缩容,hpa有一定的周期,几分钟
-
-
kpa
-
vpa
2、hpa工作原理
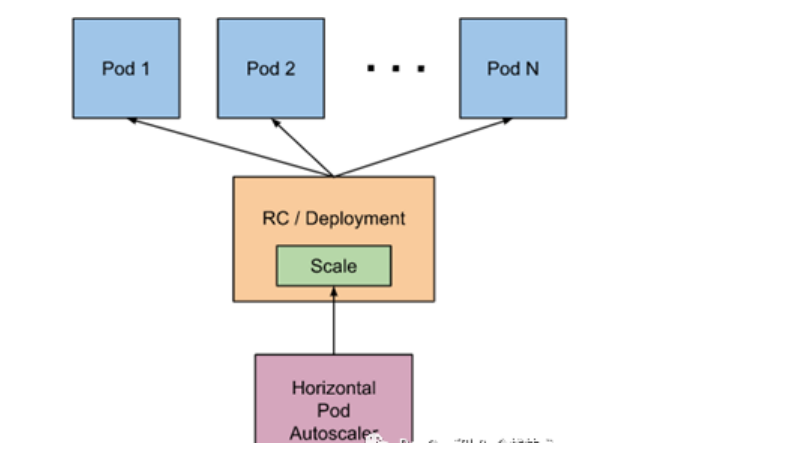
-
hpa如何工作
-
是一个控制循环
-
创建hpa资源,设定cpu使用率限制,以及最大,最小的pod数
-
收集一组中每个pod最近一分钟内的cpu使用率,并且计算平均值
-
读取hpa设定的cpu使用限额
-
计算平均值/限额,求出目标调整pod数
-
3、安装数据采集组件mertrics-server
-
收集资源数据,不提供数据存储服务
-
资源的调度量是通过api实现的,cpu,文件描述符,内存请求延时等
[root@master hpa]# cat components.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-view: "true"
name: system:aggregated-metrics-reader
rules:
- apiGroups:
- metrics.k8s.io
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- apiGroups:
- ""
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
ports:
- name: https
port: 443
protocol: TCP
targetPort: https
selector:
k8s-app: metrics-server
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: metrics-server
strategy:
rollingUpdate:
maxUnavailable: 0
template:
metadata:
labels:
k8s-app: metrics-server
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
- --kubelet-insecure-tls
image: registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.6.3
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /livez
port: https
scheme: HTTPS
periodSeconds: 10
name: metrics-server
ports:
- containerPort: 4443
name: https
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /readyz
port: https
scheme: HTTPS
initialDelaySeconds: 20
periodSeconds: 10
resources:
requests:
cpu: 100m
memory: 200Mi
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
volumeMounts:
- mountPath: /tmp
name: tmp-dir
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-cluster-critical
serviceAccountName: metrics-server
volumes:
- emptyDir: {}
name: tmp-dir
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 100
#拉取这个镜像
ctr image pull registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.6.3
#运行了这个监控软件
[root@master hpa]# kubectl get pod -n kube-system | grep me
metrics-server-598575c967-vd7mh 1/1 Running 0 40m
#显示这个就证明软件安装成功
[root@master hpa]# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
master 241m 6% 1457Mi 38%
node1 99m 2% 794Mi 20%
node2 96m 2% 798Mi 20%
4、运行一个deployment
[root@master hpa]# cat deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: tomcat
namespace: dev
spec:
replicas: 1 #一个副本数量
selector:
matchLabels:
app: tomcat-pod #标签选择器
template:
metadata:
labels:
app: tomcat-pod
spec:
containers:
- name: tomcat
image: docker.io/library/nginx:1.9.1
resources:
requests:
cpu: 100m #最少需要100毫核才能启动
#创建一个服务
kubectl expose deployment nginx --type=NodePort --port=80 -n dev
[root@master hpa]# kubectl get svc -n dev
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
tomcat NodePort 10.104.32.164 <none> 80:30468/TCP 79m
5、创建一个hpa控制器
hpa字段
apiVersion:
kind:
metadata:
spec:
maxReplicas: #允许最大的扩容pod数量
minReplicas: #允许缩容最小的pod数量
behavior: #定义自动扩容和缩容的行为
scaleDown: #定义自动缩容
policies:
- type: #
periodSeconds: #周期 必须大于等于0小于30分钟
value: #每次缩容的数量
scaleUp: #定义自动扩容
policies:
- type: 资源类型,一般为resource
periodSeconds: #周期性
value: #每次扩容的数量
metrics: #定义计算副本数量
- type: Resource #伸缩类型为资源
resource: #d定义资源使用的标准,cpu和内存
name: cpu
target: #定义外部指标的目标值
type: #Utilization 指标利用率
averageUtilization: #定义平均利用率,超过了这个就进行扩容,50对应50%
[root@master hpa]# cat hpa.yaml
apiVersion: autoscaling/v2 #v1版本的被弃用了
kind: HorizontalPodAutoscaler
metadata:
name: hpatomcat
namespace: dev
spec:
scaleTargetRef: #控制的deploy控制器
apiVersion: apps/v1
kind: Deployment
name: tomcat
minReplicas: 1 #最小Pod数量
maxReplicas: 10 #最大pod数量
metrics: #定义伸缩规则
- type: Resource #伸缩类型是资源
resource:
name: cpu #要伸缩的资源是cpu
target:
type: Utilization #目标类型是利用率
averageUtilization: 3 #cpu的平均利
[root@master hpa]# kubectl get hpa -n dev
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpatomcat Deployment/tomcat 0%/3% 1 10 1 17h
6、压力测试
#访问这个svc即可
[root@master hpa]# kubectl get svc -n dev
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
tomcat NodePort 10.104.32.164 <none> 80:30468/TCP 89m
#访问这个页面即可
[root@master hpa]# cat test.sh
while `true`
do
curl 192.168.200.100:30468 &> /dev/null
done















 7007
7007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









