








一、前言
本文会为大家打来零基础掌握Redis第一弹的学习,在本篇文章中会为浅浅讲解Redis,并为小伙伴们详细分布式系统的演变及相关策略,希望读者们能够从中有所收获!!!
二、正文
1.初识redis

上图是从Redis官网中截取的对于Redis的介绍,从中我们可以知道Redis是基于内存的,将数据存储在内存当中。而Redis的应用场景也有很多,比如说数据库,Cache,消息中间件等。下面我们就来谈谈Redis的几个应用场景:
● 数据库
说到数据库,相信C++的朋友可能下意识的就想到了MySQL,既然MySQL可以作为数据库来使用,为什么还需要Redis来做数据库呢?这是因为MySQL的数据是存储在硬盘上的,虽然能够存储大量的数据,但是其最大的问题在于访问速度比较慢,不过有很多互联网产品中,对于性能的要求是很高的,因此单纯使用MySQL可能就满足不了使用的需求,而Redis是基于内存的,根据内存读写数据的速度相较与硬盘是快很多的,因此Redis也就可以以这个优势来作为数据库。
说到这可能有的小伙伴就疑惑了,既然这样,那么我什么时候该用Redis,什么时候该用MySQL呢?其实很简单,根据自己的业务需求来选择就好了,如果存储的数据比较大,就选择MySQL;如果对性能的要求比较高,就选择Redis;但是如果我又要数据又大又快呢,那么有一种典型的方案,就是将Redis和MySQL结合起来使用。我们都知道在经济学中有一个“二八原则”,而这个原则对于数据来说也是适用的,即20%的热点数据,就能够满足80%的访问需求,因此我们对于大量的数据可以存储在MySQL中,而其中的热点数据就可以存储在Redis中,这样就能够满足又大又快的需要,但是需要注意的时,天下没有十全十美的事情,将MySQL与Redis结合,相较于使用单独的数据库会大大提升系统的复杂程度,而且如果数据发生修改,还会涉及到Redis和MySQL之间的数据同步问题
● Cache
Cache即缓存,缓存 (cache) 是计算机中的⼀个经典的概念. 在很多场景中都会涉及到。 核⼼思路就是把⼀些常⽤的数据放到触⼿可及(访问速度更快)的地⽅, ⽅便随时读取。 对于计算机硬件来说, 往往访问速度越快的设备, 成本越⾼, 存储空间越小,缓存是更快, 但是空间上往往是不⾜的. 因此⼤部分的时候, 缓存只放⼀些热点数据 (访问频繁的数据),就⾮常有⽤了。而Redis为什么可以作为Cache呢?
● 极高的读写速度:由于所有的操作都在内存中完成,因此Redis提供了毫秒级别的响应时间,非常适合需要高速读写的场景。
● 持久化机制:尽管主要运行于内存之中,但Redis也提供了RDB快照和AOF日志两种持久化方式来保障数据的安全性和可靠性。
● 丰富的API接口:除了基本的CRUD操作外,Redis还提供了大量高级命令用于复杂业务逻辑的实现。
● 分布式部署支持:借助主从复制、哨兵监控和集群模式等功能,Redis可以轻松构建高可用的服务架构。
● 消息中间件
消息中间件(Message-Oriented Middleware, MOM)是分布式系统中实现组件间异步通信的核心基础设施。它基于生产者-消费者模型,提供可靠的消息传递机制,确保不同服务、应用或设备之间数据的标准化交互。其实Redis的初心,最初就是用来作为一个“消息中间件”的(消息队列)的分布式系统的下的生产消费模型。不过当前很少会直接使用Redis作为消息中间件(业界有更多更专业的消息中间件使用)
总而言之,Redis是分布系统中,才能发挥威力的,因为通过内存来存储数据这与我们以前在单机程序,直接通过变量存储数据的方式在数据读写效率方面是没有竞争力的。只有在分布式系统中,我们要跨网络进行通信,这时候Redis就可以基于网络,把自己内存中的变量给别的进程,甚至别的主机的进程进行使用
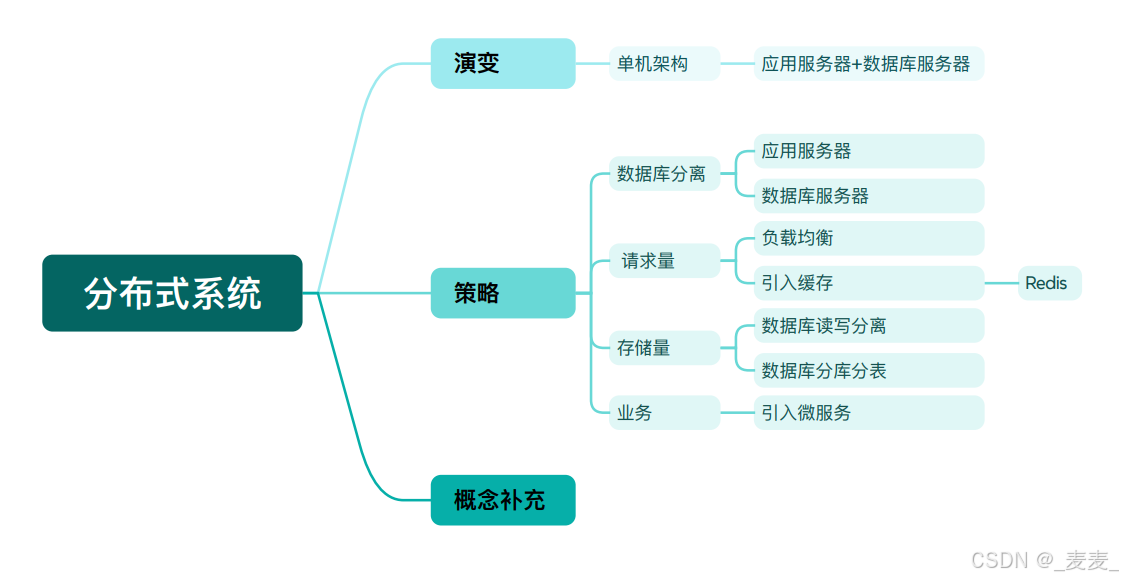
2.分布式系统
2.1 单机架构
在进行分布式系统的讲解之前,我们需要先了解一下单机架构。单机架构(Monolithic Architecture)是一种集中式系统设计模式,其所有功能模块(如业务逻辑、数据存储、用户界面等)均部署在单一物理服务器或进程中。这种架构的核心特点是高度耦合,各组件通过本地调用协作,无需依赖网络通信。
我们以电商网站为例,首先,用户通过网站可以进行用户注册登录,商品浏览,商品交易的等等服务端提供的应用服务,而对于用户的增删改查,商品信息的列举就会调用底层的数据库,就有了用户表,商品表,交易表等等。而应用服务就像我们之前写的HTTP服务器,数据库服务可以是MySQL,Redis等数据库,而这些都是集中在一个主机上,因此就叫做单机架构
不过大家也不要觉得用我一个服务器就用一台主机来跑会不会就很low,为啥不是那种大机房呀啥的,其实绝大部分公司的产品,都是这种单机架构!!!随着计算机硬件的迅速发展,现在的硬件水平已经不可同日而语了,哪怕只有一台主机,这一台主机的性能也是很高的,可以支持非常高的并发和非常大的数据存储
图
2.2 分布式架构
不过随着业务的进一步增长,可想而知,用户量和数据量也随之水涨船高,一台主机难以应付的时候,就需要引入更多的主机,引入更多的硬件资源,这其实就是分布式架构,本来用一台主机跑的服务分布到多台主机来部署服务。
我们都知道一台主机的硬件资源是有上限的,比如CPU、内存、硬盘、网络等等,服务器每次收到一个请求,都是需要消耗上述的一些资源的,如果同一时刻,处理的请求多了,此时就可能会导致某个硬件资源不够用了。无论是那个方面不够用了,都可能会导致服务器请求的时间变长,甚至于处理出错
如果我们真的遇到了这样的服务器不够用的场景,该怎么处理呢?大体思路就是开源节流。开源就是很简单粗暴,既然服务器资源不够用,那么我们就向主机增加更多的硬件资源,不过一台主机上面能增加的硬件资源也是有限的,取决于主板的拓展能力,而当一台主机拓展的硬件资源不能够再拓展的时候。就不得不引入多台主机了,一旦引入多台主机,那么这个系统就可以称为是“分布式系统了”。另一种方法就是节流,这个就需要比较高的编程水平了,需要对软件进行优化,不同的程序员就需要各凭本事,通过性能测试,找到是哪个环节出现了瓶颈再去对症下药。
不过要注意的是并不是引入多台主机就万事大吉了,因为新买的机器并不是直接就可以解决一台主机不够用的问题,也需要在软件上做出对应的调整和适配,会是的系统的复杂程度大大提高,出现bug的概率也会随之提高,因此分布式的引入其实是一种万不得已的举措,所以小伙伴们可不要树立分布式系统就一定比单机系统好,要根据实际的业务需求来进行选择
2.3 数据库分离
在上面我们已经讲过了可以通过多台主机来解决资源不足的问题,那么这多台主机我们要怎么部署呢。一种方法就是采取数据库分离的方式,即将含有数据库服务的存储服务器和应用服务器分开,将这两各服务器部署到不同的机器上面去。这样做有什么好处呢?
这是因为虽然存储服务器与应用服务器共同构成了我们的一个项目,但是其实他们两个所使用的资源还是有所不同的。对于应用服务器来说,里面可能会包含很多的业务逻辑,可能会吃CPU和内存;而数据库服务器,需要更大的硬盘空间,更快地数据访问速度。那么根据他们之间的差异化,就可以相对应的选择更合适它们的主机,从而达到更高的一个性价比
图
2.4 负载均衡
在上面中我们将单机式架构转变为分布式架构,其中应用服务器和存储服务器部署到不同的机器上面去。不过由于用户请求的不断增加,我们用一台主机来部署应用服务器可能也不太够,因为应用服务器是比较吃CPU和内存的,如果把CPU或者内存吃没了,这时候应用服务器就顶不住,这时候就需要引入更多的应用服务器来协同合作解决上述问题。不过又有新问题随之到来。
当一个请求到来的时候,这个请求我们要转发给哪个主机来处理,尤其当大量请求到来的时候,我们又该如何分配这些请求给我们的多台主机,这时候就需要负载均衡(Load Balance)来实现了。这个负载均衡就像我们在公司中的一个组的领导一样,要负责管理,负责把任务分配给每个组员。因此当用户的请求到来的时候,是先到达负载均衡器/网关处理器(这个也是一个单独的服务器),然后再分配给下面的应用服务器。举个例子,假设有1w的用户请求,而我们有两个应用服务器,此时按照负载均衡的方式,就可以让每个应用服务器承担5k的访问量,和我们在操作系统中的“多线程”有点类似。
讲到这里,可能有的小伙伴又会问了,负载均衡器看起来不是承担了所有的请求嘛,那么这个东西能够顶住嘛?首先,我们要明确的是,负载均衡器,对于请求量的承担能力,要远超过应用服务器的。要怎么理解呢?我们可以把负载均衡器看做是领导,负责分配工作;而应用服务器看作组员,负责执行任务。那么显而易见,对于执行任务而言,分配工作的压力是更小的。不过是否可能会出现,请求量大到负载均衡器也扛不住了呢??也是有可能的,这时候的解决方案就可以引入更多的负载均衡器(即引入多个机器)
现有的负载均衡算法主要分为静态和动态两类。静态负载均衡算法以固定的概率分配任务,不考虑服务器的状态信息,如轮转算法、加权轮转算法等;动态负载均衡算法以服务器的实时负载状态信息来决定任务的分配,如最小连接法、加权最小连接法等。有兴趣的小伙伴可以自行了解一下。
2.5 数据库读写分离
在上面的场景,我们通过增加服务器,确实能够处理更高的请求量,但是随之而来的是存储服务器要承担的请求量也就更多了,解决方案依旧是两种,开源或者节流。节流的门槛更高更复杂,我们就来谈一谈开源的方法。
依旧是引入多个机器,不过与之前不同,我们是将存储服务器分为两种,一种是主数据库(master)负责处理应用服务器中的写操作;另一种是从数据库(slave),负责处理应用服务器中的读操作,这样子将存储数据库的读写分离,将请求分为读和写分配到不同的机器上,就能缓解大量的请求对单台存储服务器的压力。在实际的应用场景中,读的频率是比写的频率要高很多的,因此在一般场景中,主服务器一般是一个,从服务器可以有多个(一主多从),而这多个从服务器也可以采取负载均衡的方式,让应用服务器来进行访问。
2.6 引入缓存
我们都知道数据库天然有个问题,就是它在硬盘的响应速度是很慢的!既然这样子的话,我们能不能将数据分为冷热数据,将热数据,也就是经常用到的数据放入到缓存中,而缓存的访问速度就比数据库访问要快很多了!因此我就可以引入额外的机器作为缓冲服务器,存放小部分热点数据,而且我们之前也讲过了“二八原则”,即20%的三个月数据就能够支持80%的访问量,甚至极端一点的情况能够达到一九,因此虽然我们额外使用了机器,但是带来的数据处理速度的提高,还是非常有性价比的,毕竟要想要得到一个效果,就要付出一定的代价。而这个缓存服务器我们就可以使用前面讲过的Redis
2.7 数据库分库分表
前面我们讲到的数据库分离,负载均衡等其实都是分布式系统应对更高的请求量(并发量)的做法,但我们对于数据库来说,我们也要能够应对更大的数据量,虽然一个存储服务器存储的数据量可以达到几十个TB,即使如此也可能会存不下,比如存储短视频等需要大量存储空间,既然一台主机存不下,就需要多台主机来存储。
因而除了可以对数据库进行读写的分离,我们还可以对数据库进行进一步的拆分——分库分表。本来一个数据库服务器,这个数据库服务器上有多个数据库(指的是逻辑上的数据集合,create database创建的),那么现在就可以引入多个数据库服务器,每个数据库服务器存储一个或者一部分的数据库(分库);如果某个某个表特别大,达到一台主机存不下,也可以针对表进行拆分(分表)。
话说回来,具体在分布式系统中分库分表要如何实践,还是要结合实际的业务场景来进行展开,技术只是给业务提供支持的,业务决定了技术的使用!!!
2.8 引入微服务
在解决了分布式框架请求量和数据量的问题,接下里就是人的问题了,随着业务的不断拓展,一个服务器程序里面就做了很多的业务,这就可能会导致这一个服务器的代码变得越来越复杂。为了方便于代码的维护以及后期问题出现的追踪,就可以把这样的一个复杂的服务器拆分成更多的,功能更单一,但是更小的服务器,而这样的一个服务器我们就可以叫做微服务。通过引入微服务,服务器的种类和数量就增加了,那么就可以将不同种类的服务器划分给不同的组,由各个组配备的领导来进行管理。
在了解了微服务后,总结一下其优势和付出的代价。
优势:
1. 解决了人的问题
2. 使用微服务器,可以更方便于功能的复用
3. 可以给不同的服务进行不同的部署
代价:
1. 系统的性能下降,拆出来更多的服务,多个功能之间要更依赖网络通信,而网络通信的速度很可能是比硬盘更慢的
2. 系统的复杂程度提高,可用性收到影响。显然,服务器更多了,出现问题的概率就更大了,这就需要一系列的手段来保证系统的可用性,如更丰富的监控报警,配套的运维人员
2.9概念补充
● 应用(Application)/系统(system):一个应用,就是一个组/服务器程序
● 模块(Model)/组件(Compontent):一个应用,里面有很多个功能,每个独立的功能,就可以称为是一个模块/组件
● 分布式(Distribu):引入多个主机/服务器,协同配合完成一系列的工作(物理上多个主机
)
● 集群(Cluster):引入多个主机/服务器,协同噢诶和完成一系列的工作(逻辑上的多个主机
)
● 主(Master)/从(Slave):分布系统中一种比较典型的结构,对于多个服务器节点,其中一个是主,另外的是从,从节点的数据要从主节点这里同步过来
● 中间件(Middleware):和业务无关的服务(功能更通用的服务),比如说:数据库,缓存,消息队列等
● 可用性(Availability):系统整体可用时间/总的时间(一个系统的第一要务就是保证可用性)
● 响应时长(Response Time RT):衡量服务器的性能,和具体服务器要做的业务相关,越小越好
● 吞吐(Throughtput)/并发(Concurrent):衡量系统的处理请求的能力,衡量性能的一种方式
三、思维导图
四、结语
到此为止,本文关于【从零掌握Redis】第一弹——分布式系统的内容到此结束了,如有不足之处,欢迎小伙伴们指出呀!
关注我 _麦麦_分享更多干货:_麦麦_-CSDN博客
大家的「关注❤️ + 点赞👍 + 收藏⭐」就是我创作的最大动力!谢谢大家的支持,我们下期见!!


















 1640
1640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











