






大家好,小编来为大家解答以下问题,python随机森林特征重要性,python随机森林分类模型,现在让我们一起来看看吧!

前言
本文将介绍在数据分析中,一个完整的分析或挖掘的流程是怎么样的,指在帮助读者更好的了解掌握数据分析的整体步骤,通过一个利用随机森林分类器解决一个简单的分类问题:根据客户的年龄、性别和地理位置等特征来预测其购买行为(0表示未购买,1表示已购买),大致展示一个完整的分析流程。
一、数据预处理
1.生成示例数据集:
使用NumPy生成了一个包含随机生成的年龄、性别、地理位置和购买历史的示例数据集用python绘制满天星。使用 numpy 库生成随机的年龄、性别、地理位置和购买历史等数据。将生成的数据整理成一个 DataFrame 对象,其中每一列代表一个特征。
#导入库
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler #标准化库
from sklearn.ensemble import RandomForestClassifier #随机森林分类器
from sklearn.metrics import accuracy_score, classification_report #评价指标
from sklearn.model_selection import GridSearchCV #网格搜索
# 生成示例数据集
np.random.seed(42)
n_samples = 1000
age = np.random.randint(18, 70, n_samples)
gender = np.random.choice(['Male', 'Female'], n_samples)
location = np.random.choice(['Urban', 'Rural'], n_samples)
purchase_history = np.random.choice([0, 1], n_samples)
data = pd.DataFrame({'Age': age, 'Gender': gender, 'Location': location, 'Purchase': purchase_history})
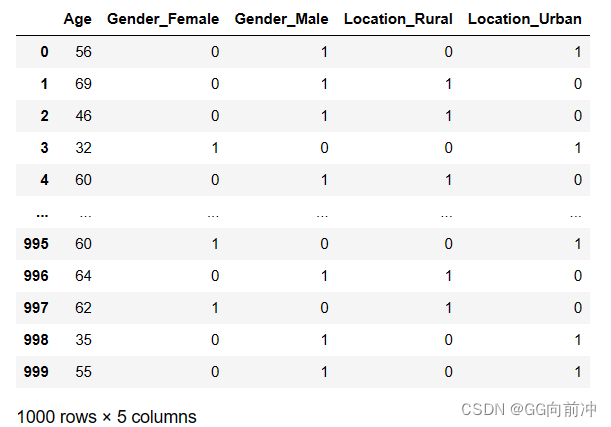
data

2.数据预处理:
使用pd.get_dummies()方法对分类变量进行独热编码(这里可以直接赋值代替,可以不用进行独热编码,编码有很多种方法),将其转换为数字表示,方便模型处理。
将数据集划分为特征(X)和标签(y),其中特征为除了购买历史以外的所有列,标签为购买历史。
# 数据预处理
# 对分类变量进行独热编码
data = pd.get_dummies(data, columns=['Gender', 'Location'])
data

# 划分特征和标签
X = data.drop('Purchase', axis=1)
y = data['Purchase']
X
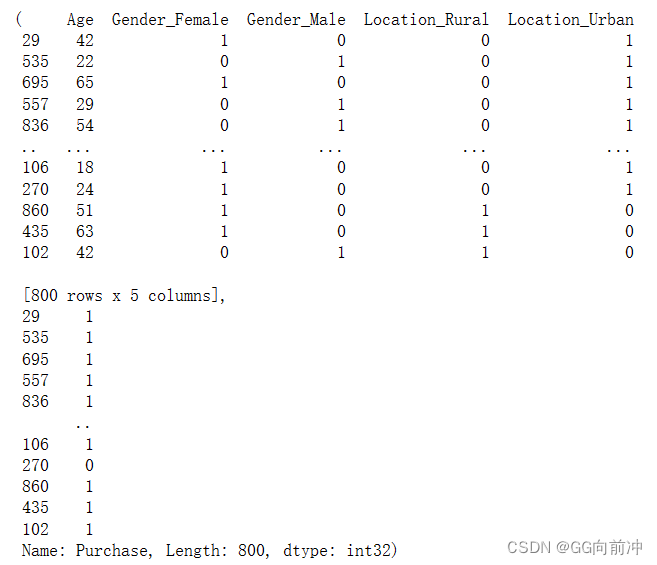
使用train_test_split()方法将数据集划分为训练集和测试集,以便对模型进行训练和评估。
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train,y_train
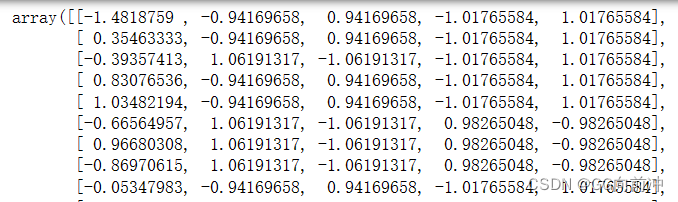
对特征变量进行标准化,确保不同特征的数值范围相似,以提高模型训练的稳定性和性能。
使用 StandardScaler(Z-score 标准化,数据标准化) 对特征变量进行标准化,将其缩放到均值为0,标准差为1的范围内。
# 特征缩放
scaler = StandardScaler() #(x - μ) / σ
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
X_test_scaled
二、模型训练与评估:
首先可以进行特征筛选,由于特征较少,故不进行
选择了随机森林分类器作为示例模型,因为随机森林适用于分类问题,并且在许多情况下表现良好,能够有效地处理复杂的分类任务,并且不容易过拟合。
# 模型选择
model = RandomForestClassifier(random_state=42)
# 模型训练
model.fit(X_train_scaled, y_train)
# 模型评估
y_pred = model.predict(X_test_scaled)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
print("Classification Report:")
print(classification_report(y_test, y_pred))
调用随机森林分类器的 fit() 方法,传入经过特征缩放后的训练数据,进行模型的训练。
评估模型在测试集上的性能,了解模型的预测能力:使用 accuracy_score 和 classification_report 等函数计算模型的准确率、精确率、召回率、F1-score 等评估指标,并输出评估报告。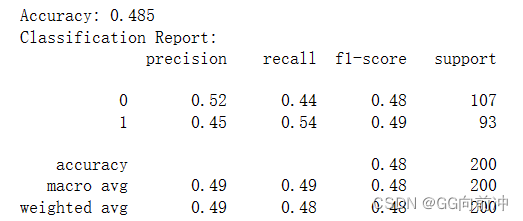
三、模型优化:
通过网格搜索寻找最优的超参数组合,以进一步提高模型性能。
定义超参数网格,包括随机森林分类器的树的数量和深度等超参数。
使用 GridSearchCV 进行网格搜索,寻找最优超参数组合。
获得最优模型,并使用最优超参数重新训练模型。
输出模型在测试集上的准确率和其他评估指标,以及最优模型的性能指标。
# 模型优化
param_grid = {
'n_estimators': [30,50, 100, 200],
'max_depth': [None, 5, 10, 20],
'min_samples_leaf':[1,2,3,4]
}
grid_search = GridSearchCV(model, param_grid, cv=5)
grid_search.fit(X_train_scaled, y_train)
best_model = grid_search.best_estimator_
best_model
RandomForestClassifier(max_depth=10, min_samples_leaf=4, n_estimators=50,
random_state=42)
# 用最优模型重新训练
best_model.fit(X_train_scaled, y_train)
# 最优模型评估
y_pred_best = best_model.predict(X_test_scaled)
accuracy_best = accuracy_score(y_test, y_pred_best)
print("\nBest Model Accuracy:", accuracy_best)
print("Best Model Classification Report:")
print(classification_report(y_test, y_pred_best))
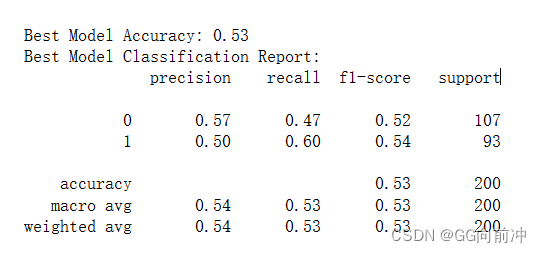
准确率稍微提高了一些,但是字体模型准确率还是较低,可能受数据集质量影响(样本不平衡等)或者是编码方面的问题,这里只是一个简单的示例,实际任务可能会更加复杂,需要对数据进行更加精细化的处理以及特征工程等。
总结
本文首先生成了一个模拟的客户数据集,包括年龄、性别、地理位置和购买历史等信息,选择随机森林分类器作为模型进行训练,并使用网格搜索找到最优超参数组合来优化模型。最后输出模型在测试集上的性能指标。提供了一个完整的示例,涵盖了数据预处理、特征工程、模型选择、调优和评估等关键步骤。通过实际操作,可以加深对数据处理技术、模型选择和性能评估方法的理解,帮助学习者掌握数据分析与挖掘的基本流程和技能,并且通过修改代码和尝试不同的模型、特征工程方法等,可以进一步提升实践能力和解决问题的能力。















 8966
8966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









