






 该文介绍了一个使用Python爬虫从链家网抓取保定市二手房数据的项目,涉及12项房产指标,包括小区、价格、面积等。数据爬取后,进行了初步的清洗和存储,并展示了部分样本。此外,还提及了如何查找和修改爬取目标以及尝试抓取北京天气信息的情况,但遇到了问题。后续计划对数据进行编码和数值型分析以进行房价相关指标的描述性统计研究。
该文介绍了一个使用Python爬虫从链家网抓取保定市二手房数据的项目,涉及12项房产指标,包括小区、价格、面积等。数据爬取后,进行了初步的清洗和存储,并展示了部分样本。此外,还提及了如何查找和修改爬取目标以及尝试抓取北京天气信息的情况,但遇到了问题。后续计划对数据进行编码和数值型分析以进行房价相关指标的描述性统计研究。
房价一直是国民所关心的问题,为探索目前房价形势,本项目通过链家网爬取河北省保定市的二手房数据共1470条,解决系列问题。本次爬取与房价相关的12项指标
对家乡的房价进行爬虫
本次通过Pycharm软件在链家网对河北省保定市二手房数据进行爬取,共爬取1470条有效数据,其中属性包括:标题、小区名称、地名、户型、房屋面积、朝向、装修规格、楼层数、建筑类型、总价、单价、发布信息共计12项。取其中五个样本信息进行展示如表所示:
| 标题 | 小区 | 地名 | 基本信息 | 总价(万) | 单价(元/平) | 发布信息 | |||||
| 精装修好楼层,南向2居室,满二税费低 | 香邑溪谷 | 涿州 | 2室2厅 | 89.92平米 | 南 | 精装 | 32层 | 板塔结合 | 75 | 8,341 | 0人关注 / 4天以前发布 |
| 鸿坤理想湾经典南向小三居 中楼层采光好 | 鸿坤理想湾北区 | 涿州 | 3室2厅 | 89.99平米 | 南 | 简装 | 25层 | 板塔结合 | 101 | 11,224 | 6人关注 / 一年前发布 |
| 高铁 狮子城 南北通透三居 两梯五户 | K2狮子城南区 | 涿州 | 3室1厅 | 90.26平米 | 南 北 | 毛坯 | 24层 | 板塔结合 | 101 | 11,190 | 0人关注 / 一年前发布 |
| 东边户 南北通透三居室 三个阳台 急售 三面采光 | 世纪华庭 | 莲池区 | 3室2厅 | 136.52平米 | 南 北 东 | 简装 | 11层 | 板楼 | 135 | 9,889 | 0人关注 / 1个月以前发布 |
| 精装修三居室 高新区 哈罗城 全天采光 南北通透 双卫 | 哈罗城西区 | 竞秀区 | 3室2厅 | 124平米 | 南 北 | 精装 | 26层 | 暂无数据 | 104 | 8,388 | 0人关注 / 1个月以前发布 |
| .... | … | … | … | … | … | … | … | … | … | … | … |
代码如下:
#Pycharm
#1 爬取房价信息
#(一)爬取保定二手房数据(pycharm)
import csv
import requests
import time
import re
import parsel
for page in range (1,50):
print(f'\n======正在抓取第{page}页数据======')
url = f'https://bd.lianjia.com/ershoufang/pg{page}/'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.26' }
response=requests.get(url= url,headers=headers)
print(response.text) #字符串
selector = parsel.Selector(response.text)
lis = selector.css('.clear.LOGCLICKDATA')
for li in lis:
# 标题
title = li.css('.title a::text').get()
# 地址
positionInfo = li.css('.positionInfo a::text').getall()
community = ''
address = ''
if len(positionInfo):
# 小区
community = positionInfo[0]
# 地名
address = positionInfo[1]
# 房子基本信息
houseInfo = li.css('.houseInfo::text').get()
# 房价
print('数据类型:', type(li.css('.totalPrice span::text').get()))
txt = li.css('.totalPrice span::text').get()
Price = ''
if isinstance(txt, str):
Price = li.css('.totalPrice span::text').get() + '万'
# 单价
print('单价数据类型:', type(li.css('.unitPrice span::text').get()))
txt = li.css('.unitPrice span::text').get()
unitPrice = ''
if isinstance(txt, str):
unitPrice = li.css('.unitPrice span::text').get().replace('单价', '')
# 发布信息
followInfo = li.css('.followInfo::text').get()
dit = {
'标题': title,
'小区': community,
'地名': address,
'房子基本信息': houseInfo,
'房价': Price,
'单价': unitPrice,
'发布信息': followInfo,
}
print(dit)
# 创建文件
f = open('保定二手房数据.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['标题', '小区', '地名', '房子基本信息',
'房价', '单价', '发布信息'])
# 写入表头
csv_writer.writeheader()
csv_writer.writerow(dit)
如果想爬取自己所需要的信息,需要改一下这里:
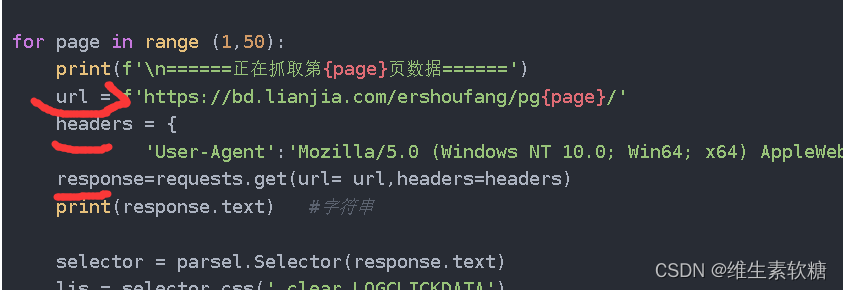
然而这个要怎么找呢,需要打开所在网页的开发者工具,可以使用快捷键Ctrl+shift+i
显示以下界面,在网络选项里找一下:
二、附加北京天气信息爬取
# 导入第三方包
import os
import pandas as pd
import requests
from bs4 import BeautifulSoup
# 构造请求头
url_header ='http://www.tianqihoubao.com'
#
# headers={
# 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.137 Safari/537.36 LBBROWSER'
# }
#
cookies = {
'__gads': 'ID=d1b7532da3ce65bb-22bf9551bdd50093:T=1661327736:RT=1661327736:S=ALNI_MbUHczV1pAqNkQLjnFnLSOSlWe7dQ',
'Hm_lvt_f48cedd6a69101030e93d4ef60f48fd0': '1664800857',
'__51cke__': '',
'ASP.NET_SessionId': 'ohpg4t55jbcyvq45iuhabe55',
'Hm_lpvt_f48cedd6a69101030e93d4ef60f48fd0': '1664870978',
'__tins__21287555': '%7B%22sid%22%3A%201664870977936%2C%20%22vd%22%3A%201%2C%20%22expires%22%3A%201664872777936%7D',
'__51laig__': '9',
'__gpi': 'UID=000008fac0a5f937:T=1661327736:RT=1664870978:S=ALNI_MYZPtUCieIqRmGjnkTRucedU9-yOg',
}
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
# Requests sorts cookies= alphabetically
# 'Cookie': '__gads=ID=d1b7532da3ce65bb-22bf9551bdd50093:T=1661327736:RT=1661327736:S=ALNI_MbUHczV1pAqNkQLjnFnLSOSlWe7dQ; Hm_lvt_f48cedd6a69101030e93d4ef60f48fd0=1664800857; __51cke__=; ASP.NET_SessionId=ohpg4t55jbcyvq45iuhabe55; Hm_lpvt_f48cedd6a69101030e93d4ef60f48fd0=1664870978; __tins__21287555=%7B%22sid%22%3A%201664870977936%2C%20%22vd%22%3A%201%2C%20%22expires%22%3A%201664872777936%7D; __51laig__=9; __gpi=UID=000008fac0a5f937:T=1661327736:RT=1664870978:S=ALNI_MYZPtUCieIqRmGjnkTRucedU9-yOg',
'If-Modified-Since': 'Tue, 04 Oct 2022 08:01:50 GMT',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36 Edg/105.0.1343.53',
}
#获取html页面,使用BeautifulSoup处理
def get_html_soup(url):
url=url.replace('\r','').replace('\n','')#去除影响爬取的字符
print("request:", url)
for i in range(10):
try:
r=requests.get(url,headers=headers,timeout=(3,7))#发起GET请求
r.encoding='gb2312' #设置页面编码
print("status_code:",r.status_code)
html_text=r.text
soup = BeautifulSoup(html_text, 'html.parser') #BeautifulSoup
return soup
except:
str = "请求超时,继续第%d次请求" %(i+2)
print(str)
if i == 10:
return -1
#一级页面,获取城市和对应的链接
def get_city_link_list():
city_link_list=[] #解析页面
soup=get_html_soup("http://www.tianqihoubao.com/aqi/")
if soup==-1:
return city_link_list
all_dl=soup.find_all('dl')
for dl in all_dl:
item=dl.find_all('a')
for i in range(len(item)):
if not (dl==all_dl[0] and item[i].text.strip() in ['广州','深圳','成都','杭州','全国空气质量排名']):
city_link_list.append([item[i].text.strip(),item[i]['href']])
return city_link_list
#获取城市的历史数据链接
def get_city_historical_link_list(city_link_list, cityname):
href_month_list=[] #解析页面数据
for city_link_item in city_link_list:
if cityname == city_link_item[0]:
url=url_header+city_link_item[1]
soup=get_html_soup(url)
if soup == -1:
continue
all_div=soup.find_all('div',{'class','box p'})#发现对应的对象
for href_month in all_div[0].find_all('a'):
href_month_list.append([href_month['title'],href_month['href']])
break
return href_month_list
def deal_href_month_list(href_month_list,start_time,end_time):
crop_href_month_list=[]
for href_month in href_month_list:
year_month_str = href_month[0]
year = year_month_str[0:4]
month = year_month_str[5:7]
strtime = int(year+month)
if(strtime>=start_time and strtime<=end_time):
crop_href_month_list.append(href_month)
return crop_href_month_list
#获得页面的数据并进行打包
def get_pages_data(href_month_list):
flag = 0
data_list=[]
for city_link_item in href_month_list:
url=url_header+city_link_item[1]
soup=get_html_soup(url)
if soup ==-1:
continue
table=soup.find_all('table')
for i in range(len(table[0].find_all('tr'))):#对行数据进行解析
if flag >0 and i==0:
continue
flag = flag+1
print(flag)
td_all=table[0].find_all('tr')[i].find_all('td') #对每一行的数据进行解析
data=td_all[0].text.strip()
quality=td_all[1].text.strip()
AQI=td_all[2].text.strip()
AQI_Rank=td_all[3].text.strip()
PM25=td_all[4].text.strip()
PM10=td_all[5].text.strip()
So2=td_all[6].text.strip()
No2=td_all[7].text.strip()
Co=td_all[8].text.strip()
O3=td_all[9].text.strip()
data_list.append({"data":data,"quality":quality,"AQI":AQI,"AQI_Rank":AQI_Rank,
"PM25":PM25,"PM10":PM10,"So2":So2,"No2":No2,"Co":Co,"O3":O3})
data_dataframe=pd.DataFrame(data_list,columns=["data","quality","AQI","AQI_Rank","PM25","PM10","So2","No2","Co","O3"])
#文件命名
root_path="D:/csv"
city=city_link_item[0][8:10]
#year=city_link_item[0][0:4]
path=os.path.join(root_path,city)
#-------
if not os.path.exists(path):#没有文件夹则新建文件夹
os.makedirs(path)
csv_name=os.path.join(path,city_link_item[0]+".csv")
print("csv write:",csv_name)
data_dataframe.to_csv(csv_name,index=False,header=0, encoding = 'utf_8_sig')#保存CSV文件
#设置主函数组装
def main():
#city_link_list=get_city_link_list()
city_link_list = [['北京', '/aqi/beijing.html']]
href_month_list=get_city_historical_link_list(city_link_list,'北京')
crop_href_month_list = deal_href_month_list(href_month_list, 201401, 201512)
get_pages_data(crop_href_month_list)
main()
但是后来再用这个网站爬取的时候,最后有报错。。。。
三、剩余内容
接下来,为方便进一步的数据分析,使用pandas库pd.get_dummies对数据进行编码。将数字变量改成浮点型数据并保留两位小数,再次取出数据预处理后的其中4例进行展示,展示结果如表所示:
| 面积(平米) | 层数(层) | 总价(万) | 单价(元/平) | 室 | 厅 | 涿州 | 竞秀区 | 莲池区 | … | 板塔结合 | 板楼 | |
| 0 | 89.92 | 32.00 | 75.00 | 8341.00 | 2.00 | 2.00 | 1.00 | 0.00 | 0.00 | ... | 1.00 | 0.00 |
| 1 | 77.00 | 22.00 | 57.00 | 7403.00 | 2.00 | 1.00 | 1.00 | 0.00 | 0.00 | ... | 1.00 | 0.00 |
| 2 | 93.00 | 24.00 | 75.00 | 8065.00 | 3.00 | 1.00 | 1.00 | 0.00 | 0.00 | ... | 1.00 | 0.00 |
| 3 | 121.00 | 30.00 | 100.00 | 8265.00 | 3.00 | 2.00 | 1.00 | 0.00 | 0.00 | ... | 1.00 | 0.00 |
| 4 | 54.06 | 6.00 | 22.00 | 4070.00 | 2.00 | 1.00 | 1.00 | 0.00 | 0.00 | ... | 0.00 | 1.00 |
| ... | … | … | … | … | … | … | … | … | … | … | … | … |
房价相关指标分析
接下来对与房价相关的各类指标做描述性统计分析,其中包括地名、户型、房屋面积、朝向、装修规格、楼层数、建筑类型、总价、单价。
数值型数据分析
...........


如需完整实验报告请si xin 哦



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









