






目录
前言
在博主的《进程状态解析》一文中,在讨论进程创建时,提到了一个系统调用接口fork,它在使用过程中表现出对于父子进程不一致的返回结果,而且似乎还具有多次返回的特点,那么本文就来详细解释一下其中的缘由。博文中涉及到的图片如若不清可点击链接查找高清图《博主码云》
一、进程地址空间
在正式开始讲述之前我们先看一个有意思的现象(博主使用的centos7系统+shell,关于这个问题博主想说的是为了照应系统给我们实现的接口,不同的操作系统可能会有不同的方式,来实现这一目的,如果你对操作系统与硬件接口与我们使用的接口模糊不清的话可以看看博主写的这篇文章《浅谈冯诺依曼体系与Linux操作系统》),在windows平台上和Linux平台上同时执行以下码:
#include <stdio.h>
#include <stdlib.h>
int global_init_val = 1;
int global_uninit_val;
int main()
{
char* p1 = (char*)malloc(10);
char* p2 = (char*)malloc(10);
char* p3 = (char*)malloc(10);
static int static_uninit_val;
static int static_init_val = 2;
printf("i am stack!! my address:%p %p %p\n", &p1, &p2, &p3);
printf("i am heap!! my address:%p %p %p\n", p1, p2, p3);
printf("i am global!! my address:%p %p \n", &global_init_val, &global_uninit_val);
printf("i am function!! my address:%p \n", main);
printf("i am static!! my address:%p %p \n", &static_init_val, &static_uninit_val);
return 0;
}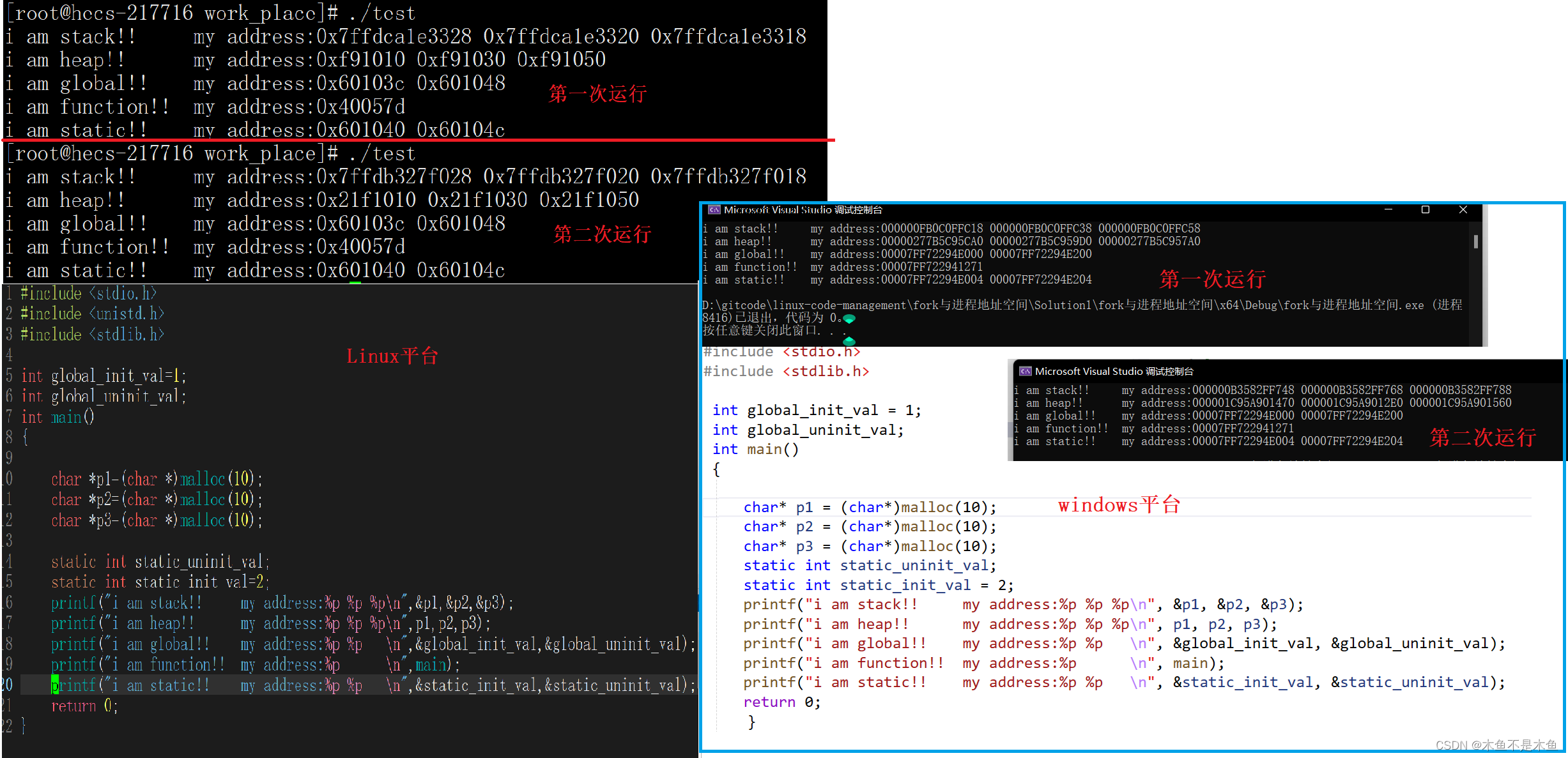
接下来的叙述将围绕这两张图展开。首先,我们可以看到在Linux平台下,两次运行结果是相同的,但是反观windows平台,两次运行结果得到的变量地址是不同的。这就是平台实现之间的差异,虽然他们都成功完成了对应的功能,但还是可以反映出处理的逻辑是不同的,但是就我们理解,Windows更符合我们的预期,Linux的处理反而让我们疑惑,我们都知道程序运行需要加载的内存,而内存又是随机存储的,所以两次打印数据分布地址是相同的,我们不妨大胆假设,程序显示的地址并非真正的物理内存,而是一种虚拟地址空间!!!!
那么到底是怎么实现的呢?这就要提到Linux处理的一种方式——进程地址空间。
在进程开始执行的时候,Linux操作系统会同时为进程申请一块名为进程地址空间(就是一块空间)的空间,这个空间储存的是进程数据的虚拟地址(虚拟地址就是可以通过一定映射关系映射到实际唯一物理内存地址的地址,关于其意义稍后解释),操作系统会将虚拟地址表与物理内存地址表建立映射关系,以达到定址访问的效果。
也许你现在听的晕头转向——啥是映射关系?映射关系是如何建立的??
我们先来解释映射关系,实际上我们常常使用的数组就是一种经典的映射关系。你应该知道,我们可以通过下标的形式来访问数组中的元素,这就是一种朴素的映射关系,就像我们知道如果我们使用下标0就可以访问数组中的第一个元素,使用下标1就可以访问数组中的第二元素一样。这就是一种映射关系(注意:映射关系应该是一 一对应的逻辑,不应该存在多对一、一对多的情况)。

所以我们的操作系统是如何将虚拟地址映射为物理内存地址的呢?
参照数组映射关系,操作系统也对虚拟地址和物理内存进行了映射:
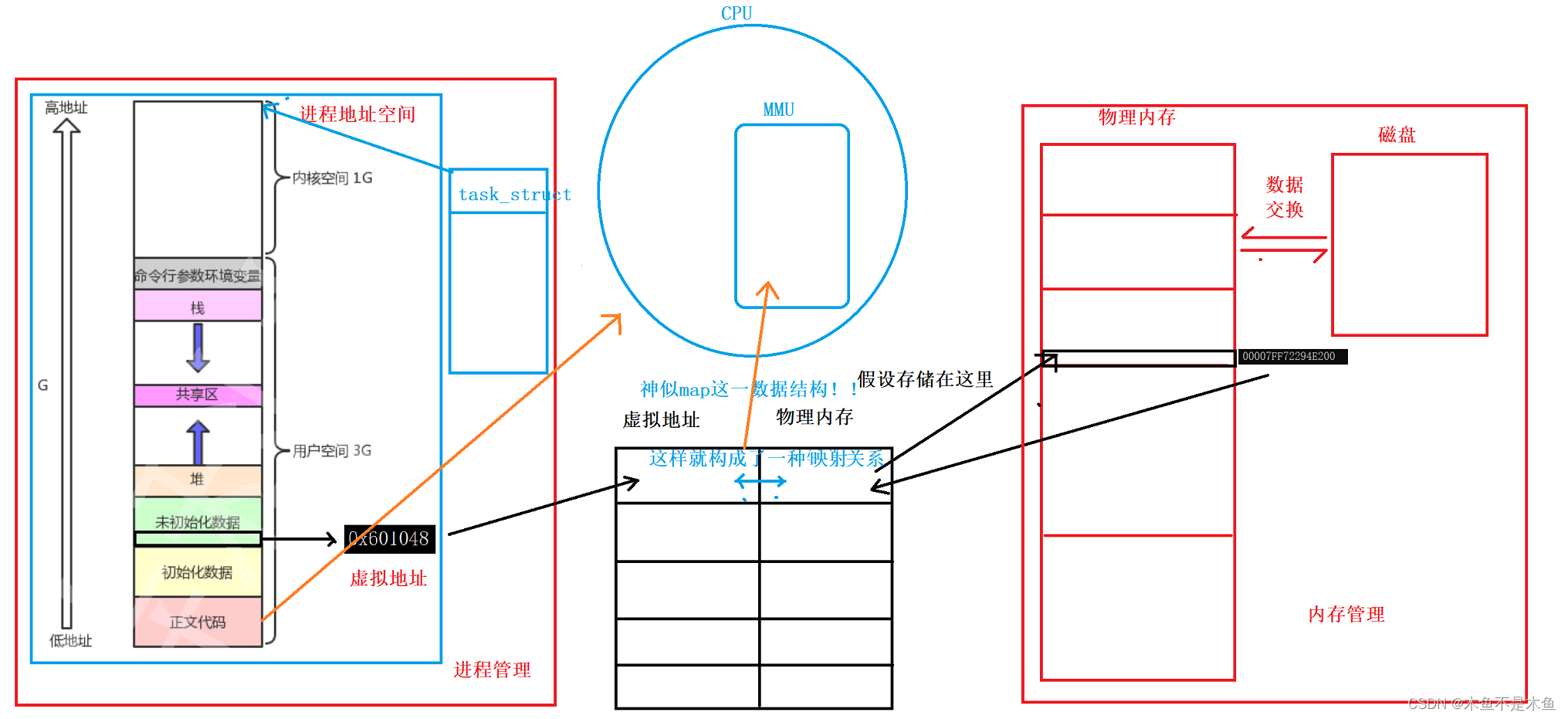
在计算机解读映射关系的时候会将页表读取到CPU中的MMU(内存管理单元)中,而后CPU读取正文代码进程程序的执行。
这里的管理虚拟地址与物理内存的映射表被称作“页表”,关于页表是什么不是本文的重点,这个内容将在其他文章中进行讲解。那么说了这么多,我们需要考虑一下为什么Linux要这样进行设计。
1.首先因为操作系统使用的虚拟的地址+页表的映射方式,这意味着有心之人是无法通过虚拟的地址对核心数据进行破坏。
2.其次因为进程地址空间是一块连续的空间,这意味着对于数据管理要比非连续空间的轻松的多。
3. 最重要的是,操作系统只需要管理进程地址空间就可以对进程管理,可以无需考虑内存管理的影响——将进程管理与内存管理进行解耦。
二、fork的值返回
上文解释了这样一个非常重要的点,就是在进程使用的并非是真实的物理内存地址,而是使用的是一种虚拟地址。那么现在我们看一个这样的示例:
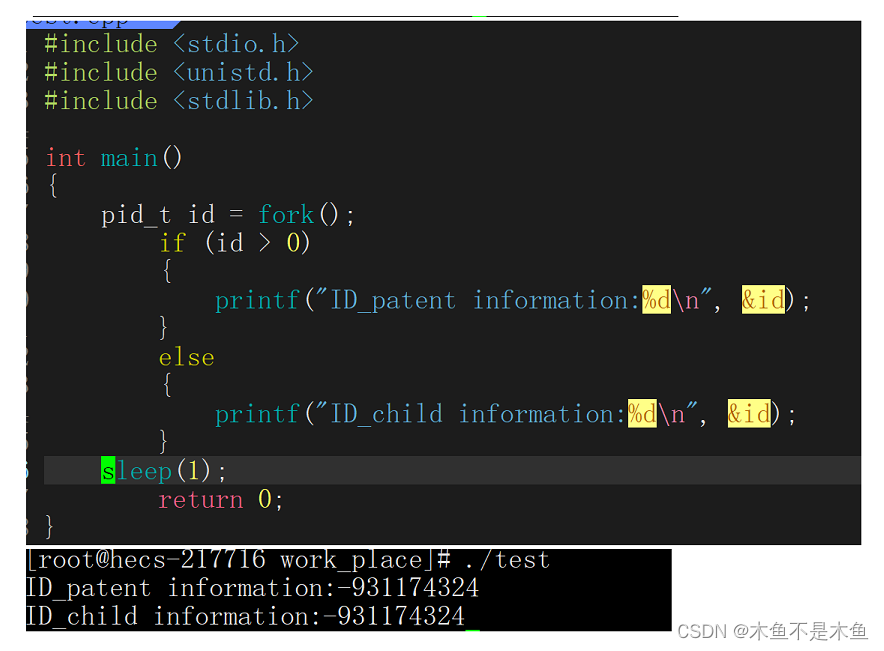
从上图中我们不难发现,在子进程与父进程中的id变量是同一个。我们知道这样一个事实,进程与进程之间是相互独立运行的,对于父子进程更是如此,虽然父子进程共享fork之后的代码,与数据(需要注意的是页表数据也会被共享)。(页表是随着进程的创建而创建,这里指的共享指的是数据共享,而非页表共享)
但是我们也要考虑:
当一个进程对变量进行改变时,为了不影响其父子进程,被修改的变量就必须与其父子进程不同的一份变量——这样的行为叫做“进程的写时拷贝”,当父子进程中共享数据改变时,改变数据的进程需要额外申请一块空间来存储改变的数据。具体的关系可参考图2.2
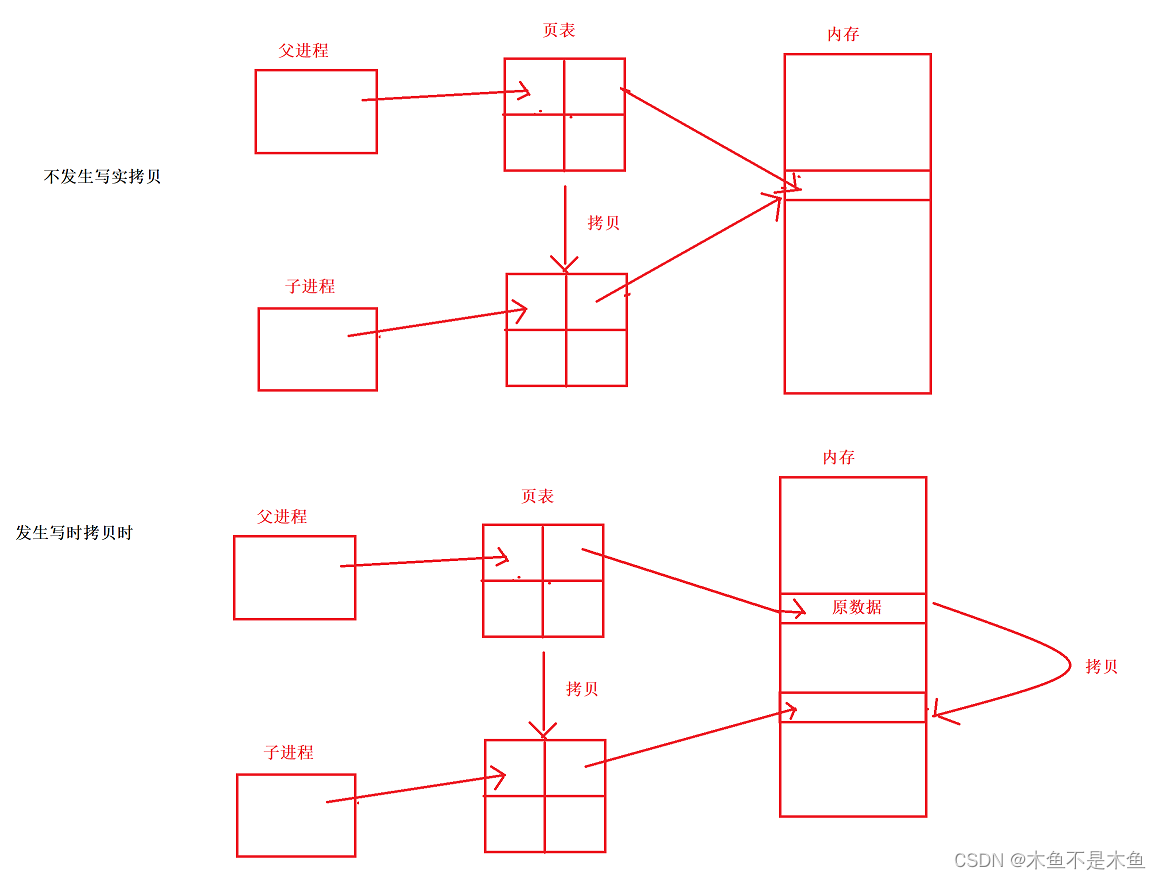
顺带一提为什么即使要更改还是要将原数据拷贝进新开辟的空间中,我们要知道数据不一定是内置类型,他可能是复杂的自定义类型数据,对于这样的数据,有可能我们只是修改自定义类型数据中的一部分,所以还是要将其他没有更改的数据进行拷贝的。
好了,现在让我们把目光放回到fork本身并在靠近一点观察它,我们知道fork也是一个有返回值的函数,那么在该函数进行返回值之前就一定已经将子进程开辟好并进行管理了,那我们之前说的父子进程共享fork之后的数据实际上可以进行一下更正——父子进程共享子进程完成创建并组织后的数据,所以父子进程也共享返回语句,因为父子进程各自进行一次返回,所以fork才会看起来返回了两次,有两个返回值。那返回值语句都被共享了,那么id变量呢?诚然其也被共享!但父子进程的fork返回对id变量进行了更改,进而引发了我们刚刚说的写时拷贝,由于我们所能看见的是虚拟地址,所以才会出现地址相同内容不同的错觉。
那么我们将父子进程套入到我们说的写时拷贝是什么样子的呢?
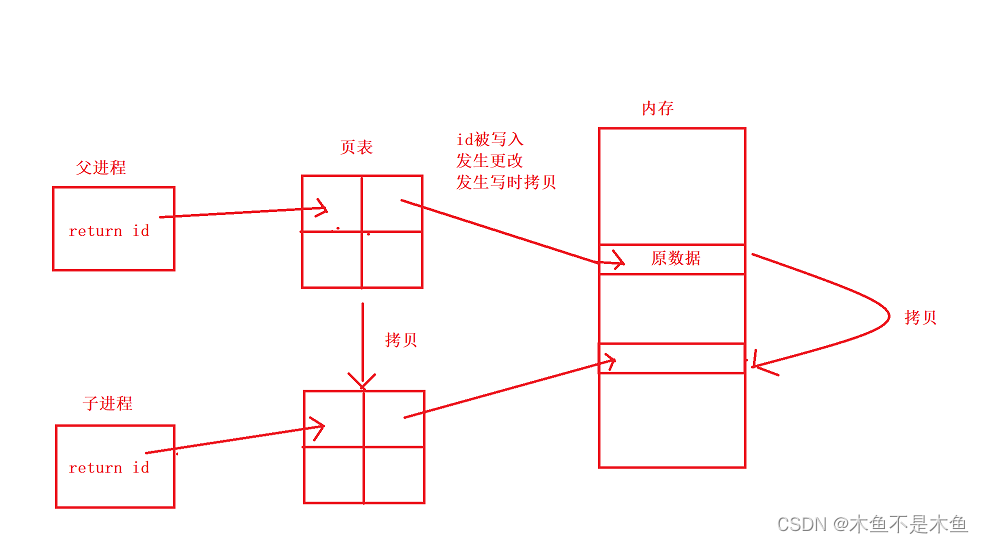
到这我们解释清楚了为什么fork会呈现不同的返回值,一个变量为什么会有多个值的原因。
三、高清图链接
本文涉及到了一些不太清晰的图片想要获取这些图片点击博主码云即可获取【点我】
总结
本文解释了有关fork的一些特殊现象并解释了一些有关进程空间的概念。
















 1468
1468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











