







1.哈夫曼树的定义
哈夫曼编码是一种压缩编码的编码算法,是基于哈夫曼树的一种编码方式。哈夫曼树又称为带权路径长度最短的二叉树。
哈夫曼编码跟 ASCII 编码有什么区别?ASCII 编码是对照ASCII 表进行的编码,每一个字符符号都有对应的编码,其编码长度是固定的。而哈夫曼编码对于不同字符的出现频率其使用的编码是不一样的。其会对频率较高的字符使用较短的编码,频率低的字符使用较高的编码。这样保证总体使用的编码长度会更少,从而实现到了数据压缩的目的。
2.哈夫曼树所需的结构定义
要创建和使用哈夫曼树,就要有相应的结构定义,首先要定义一个树结构,还要定义一个栈来存储每个字符对应的哈夫曼编码。
//最大读入的文本文件字符长度
#define MAXSIZE 100
typedef struct NODE {
char c;
int weight;
//记录节点表示的二进制,左0右1
int binary;
//是否创建节点,0未创建,1创建;
int flag;
struct NODE* lchild, * rchild, * parent;
}NODE,*PNODE;
typedef struct {
int value[MAXSIZE];
int top;
}STACK;3.树和栈的一些函数
其中包含栈的定义、入栈出栈,和树的定义、创建树节点。
void initStack(STACK& stack)
{
stack.top = 0;
}//off initStack
void push(STACK& stack, int value)
{
stack.value[stack.top++] = value;
}//off push
int pop(STACK& stack)
{
if (stack.top == 0)
{
return -1;
}//off if
stack.top--;
return stack.value[stack.top];
}//off pop
void initNode(PNODE node)
{
node->lchild = NULL;
node->rchild = NULL;
node->parent = NULL;
node->flag = 0;
node->weight = 0;
node->c = -1;
node->binary = 0;
}//off initNode
PNODE createNode(int weight)
{
PNODE node = (PNODE)malloc(sizeof(NODE));
if (node)
{
initNode(node);
node->weight = weight;
}//off if
return node;
}//off createNode4.创建哈夫曼树
4.1统一大小写
对于一个有大小写之分的英文文本,要创建哈夫曼树和哈夫曼编码必然将大小写统一,否则26个字母变成52个字母,将会增加哈夫曼树的深度和哈夫曼编码的长度。
char charTolowercase(char c)
{
if (c >= 'A' && c <= 'Z')
{
c += 'a' - 'A';
}//off if
return c;
}//off charTolowercase4.2计算出现的字母的权重
文本中每个字母出现的频率不同,字母的权重的不同,在创造哈夫曼树前,我们需要计算每个字母的权重。
PNODE readFromSource(const char* filePath, char* buff, PNODE childNodes, int& lenOfNodes)
{
//记录字符长度
int lenOfStr = 0, i;
//记录当前读取字符
char c;
FILE* file = fopen(filePath, "rb");
if (file == NULL)
{
puts("Cannot fine source file!");
exit(0);
}//off if
//一个个字符读入本地文本
c = fgetc(file);
while (!feof(file))
{
c = charTolowercase(c);
//初始化节点
initNode(&childNodes[lenOfNodes]);
buff[lenOfStr++] = c;
for (i = 0; i < lenOfNodes; i++)
{
if (childNodes[i].c == c)
{
childNodes[i].weight++;
break;
}//off if
}//off for
if (i == lenOfNodes)
{
childNodes[lenOfNodes].c = c;
childNodes[lenOfNodes++].weight++;
}//off if
c = fgetc(file);
}//off while
buff[lenOfStr] = '\0';
fclose(file);
return createHuffmanTree(childNodes, lenOfNodes, NULL);
}//off readFromSource这里计算每个字母的权重的同时还用一个字符串buff记录文本内容,用一个整形lenOfNodes记录有多少个叶子节点,方便后续生成树和编码。
4.3找到当前最小权重的节点
哈夫曼树的每一个双亲节点都指向两个最小权重的节点,所以还要找到当前最小权重的节点。
PNODE getMinWeightNode(PNODE nodes, int lenOfNodes)
{
PNODE node;
int min = 0, i;
//对已创建的节点进行过滤
while (min < lenOfNodes)
{
if (nodes[min].flag == 0)
{
break;
}//off if
min++;
}//off while
if (min == lenOfNodes)
{
return NULL;
}//off if
for (i = min + 1; i < lenOfNodes; i++)
{
if (nodes[i].flag == 0 && nodes[i].weight < nodes[min].weight)
{
min = i;
continue;
}//off if
}//off for
nodes[min].flag = 1;
return &nodes[min];
}//off getMinWeightNode这里的思路是这样的,定义一个整形min表示最小权重的节点空间的下标,因为nodes存储的节点必定是叶子节点(带有权重的节点不能当双亲节点,只能是叶子节点),所以当min < lenOfNodes时,表示还有在nodes里还有没有并入树的节点,让min向后走,直到min==lenOfNodes时返回NULL表示没有最小节点了,即整棵树已经构建完成了;或者nodes[min].flag==0时让i=min+1找出最小权重的下标,将最小权值的下标赋值给min,最后返回最小权值下标的空间地址。
4.4创建哈夫曼树
PNODE createHuffmanTree(PNODE nodes, int lenOfNodes, PNODE childNode)
{
PNODE minWeightNode, parentNode;
minWeightNode = getMinWeightNode(nodes, lenOfNodes);
if (!minWeightNode)
{
return childNode;
}//off if
if (!childNode)
{
parentNode = minWeightNode;
}//off if
else
{
parentNode = createNode(childNode->weight + minWeightNode->weight);
if (childNode->weight < minWeightNode->weight)
{
parentNode->lchild = childNode;
parentNode->rchild = minWeightNode;
}//off if
else
{
parentNode->lchild = minWeightNode;
parentNode->rchild = childNode;
}//off else
parentNode->lchild->binary=0;
parentNode->rchild->binary=1;
childNode->parent = parentNode;
minWeightNode->parent = parentNode;
}//off else
createHuffmanTree(nodes, lenOfNodes, parentNode);
}//off createHuffmanTree创建哈夫曼树的树节点时,根据最小权重节点和孩子节点判断当前创建的双亲节点的类型:若是最小权重节点为空,代表nodes中的存储的所有叶子节点都有双亲结点指向,则返回上次孩子节点(递归传入的值是上一次的双亲结点)作为树的根节点;若是孩子节点为空,则代表当前的双亲节点是叶子节点,就将最小权重节点赋值给双亲结点;若是最小权重节点和孩子节点都不为空,则是正常的构建树结构。最后按照哈夫曼编码规则左孩子节点的编码值为0,右孩子的编码值为1。
5.哈夫曼编码
5.1记录单个字母的哈夫曼编码
STACK charEncode(char c, PNODE childrenNodes, int lenOfNodes)
{
STACK stack;
initStack(stack);
for (int i = 0; i < lenOfNodes; i++)
{
if (c == childrenNodes[i].c)
{
PNODE tmp = &childrenNodes[i];
while (tmp->parent != NULL)
{
push(stack, tmp->binary);
tmp = tmp->parent;
}//off while
break;
}//off if
}//off for
return stack;
}//off charEncode记录每个字母对应的哈夫曼编码需要用到栈和链式结构,这里的思路是:传入一个字母,储存全部字母c的树结构childrenNodes和存储字母有多少的整形lenOfNodes,当i < lenOfNodes时,代表还有字母没有进行编码,如果字母c == childrenNodes[i].c时,开始进行编码,将指向childrenNodes[i]的地址的指针tmp存储的编码值入栈,找到tmp的双亲结点,重复进行编码值入栈操作,最后得到存储和实际编码相反的整形数组的栈。
5.2得到完整的哈夫曼编码
char* strEncode(char* str, PNODE childrenNodes, int lenOfNodes)
{
char* result = (char*)malloc(sizeof(char) * MAXSIZE * lenOfNodes);
int len = 0;
while (*str != '\0')
{
STACK stack = charEncode(*str, childrenNodes, lenOfNodes);
while (stack.top > 0)
{
result[len++] = pop(stack) + '0';
}//off while
str++;
}//off while
result[len] = '\0';
return result;
}//off * strEncode定义一个能存储完整哈夫曼编码的字符数组*result,当传入的字符*str(实参为之前定义的字符串buff中的一个字符)不为'\0'时,将*str传入charEncode函数获取存储该字符相反的编码的栈,进行出栈操作得到该字符的哈夫曼编码,str的地址向后移一位,重复操作当前操作,最后对字符数组进行封装,返回数组的首地址。
5.3写入哈夫曼编码
void writeResult(const char* filePath, char* result)
{
FILE* fp = fopen(filePath, "wb");
if (fputs(result, fp) >= 0)
{
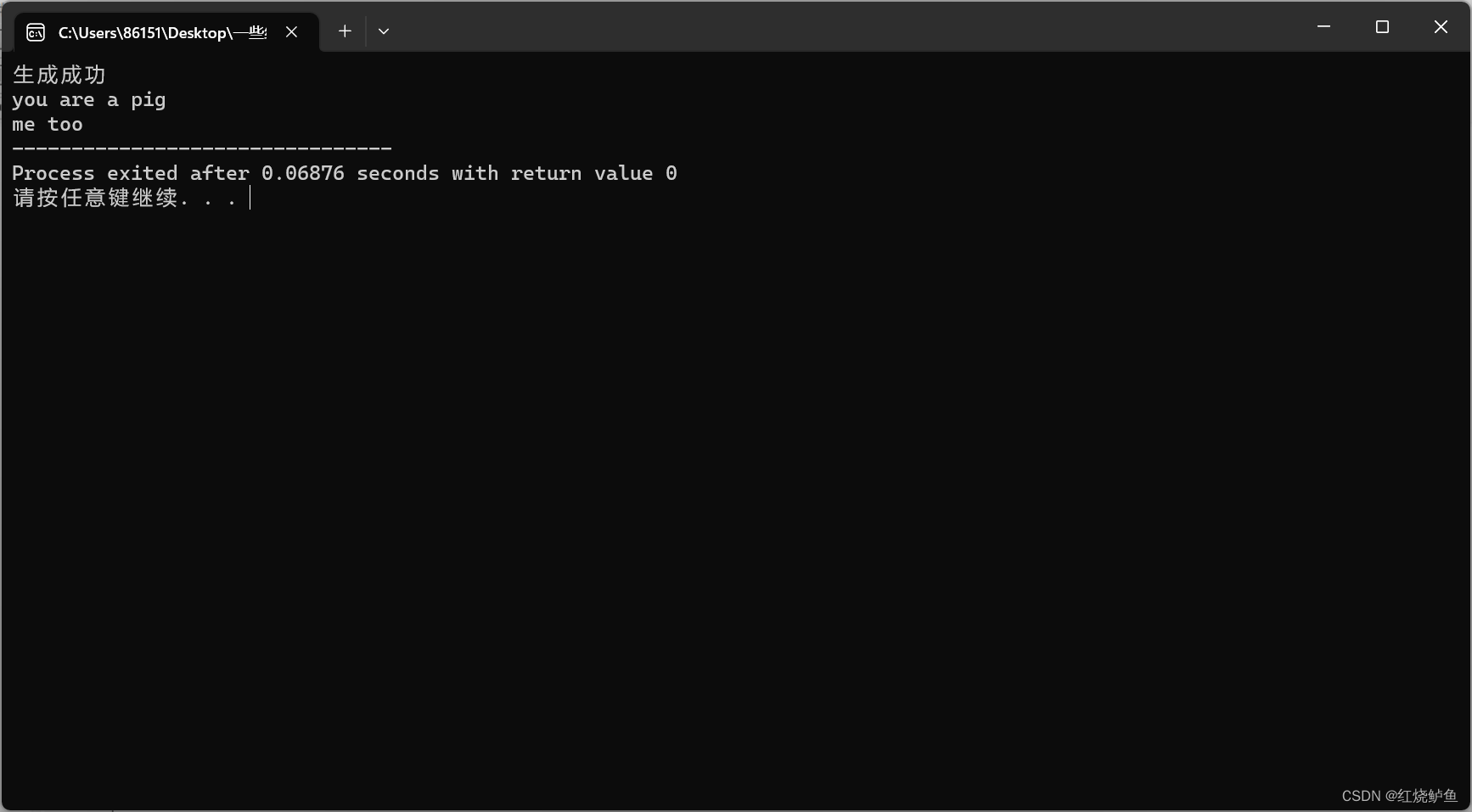
printf("生成成功\r\n");
}//off if
fclose(fp);
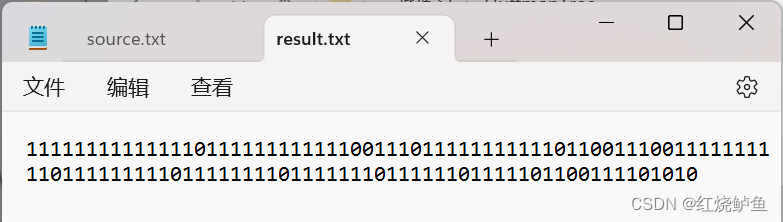
}//off writeResult得到哈夫曼编码后,我们将得到的哈夫曼编码写入一个新的文本文件中用于储存,该哈夫曼编码只对应source.txt文本生成的哈夫曼树(一棵树对应一个哈夫曼编码),也可以在后续的解码操作中测试编码是否正确。
5.4解码哈夫曼编码
char* strDecode(const char* str, PNODE TreeRoot)
{
const char* tmp = str;
char* result = (char*)malloc(MAXSIZE * sizeof(char));
//用来记录字符串长度
int len = 0;
while (*tmp != '\0')
{
PNODE tmpNode = TreeRoot;
while (tmpNode->lchild && tmpNode->rchild)
{
tmpNode = *tmp == '0' ? tmpNode->lchild : tmpNode->rchild;
tmp++;
}//off while
result[len++] = tmpNode->c;
}//off while
result[len] = '\0';
return result;
}//off * strDecode编译哈夫曼树的核心是判断由0和1组成的编码在那里隔断,所以这里套用两个循环,外循环是判断传入的字符串是否走到终点,内循环的字符串主要是找到哈夫曼树上对应的叶子节点:当内循环tmpNode的左右孩子都存在时,根据承接了传入的字符串*str的指针*tmp的值判断tmpNode该往左孩子走还是往右孩子走,直到走到一个叶子节点,该叶子节点的值就是到当前哈夫曼编码的值的解码,存入字符串result中,最后封装字符串再返回字符串首地址。
6完整代码
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<stdlib.h>
//最大读入的文本文件字符长度
#define MAXSIZE 100
typedef struct NODE {
char c;
int weight;
//记录节点表示的二进制,左0右1
int binary;
//是否创建节点,0未创建,1创建;
int flag;
struct NODE* lchild, * rchild, * parent;
}NODE,*PNODE;
typedef struct {
int value[MAXSIZE];
int top;
}STACK;
void initStack(STACK& stack)
{
stack.top = 0;
}//off initStack
void push(STACK& stack, int value)
{
stack.value[stack.top++] = value;
}//off push
int pop(STACK& stack)
{
if (stack.top == 0)
{
return -1;
}//off if
stack.top--;
return stack.value[stack.top];
}//off pop
void initNode(PNODE node)
{
node->lchild = NULL;
node->rchild = NULL;
node->parent = NULL;
node->flag = 0;
node->weight = 0;
node->c = -1;
node->binary = 0;
}//off initNode
PNODE createNode(int weight)
{
PNODE node = (PNODE)malloc(sizeof(NODE));
if (node)
{
initNode(node);
node->weight = weight;
}//off if
return node;
}//off createNode
STACK charEncode(char c, PNODE childrenNodes, int lenOfNodes)
{
STACK stack;
initStack(stack);
for (int i = 0; i < lenOfNodes; i++)
{
if (c == childrenNodes[i].c)
{
PNODE tmp = &childrenNodes[i];
while (tmp->parent != NULL)
{
push(stack, tmp->binary);
tmp = tmp->parent;
}//off while
break;
}//off if
}//off for
return stack;
}//off charEncode
char* strEncode(char* str, PNODE childrenNodes, int lenOfNodes)
{
char* result = (char*)malloc(sizeof(char) * MAXSIZE * lenOfNodes);
int len = 0;
while (*str != '\0')
{
STACK stack = charEncode(*str, childrenNodes, lenOfNodes);
while (stack.top > 0)
{
result[len++] = pop(stack) + '0';
}//off while
str++;
}//off while
result[len] = '\0';
return result;
}//off * strEncode
PNODE getMinWeightNode(PNODE nodes, int lenOfNodes)
{
PNODE node;
int min = 0, i;
//对已创建的节点进行过滤
while (min < lenOfNodes)
{
if (nodes[min].flag == 0)
{
break;
}//off if
min++;
}//off while
if (min == lenOfNodes)
{
return NULL;
}//off if
for (i = min + 1; i < lenOfNodes; i++)
{
if (nodes[i].flag == 0 && nodes[i].weight < nodes[min].weight)
{
min = i;
continue;
}//off if
}//off for
nodes[min].flag = 1;
return &nodes[min];
}//off getMinWeightNode
PNODE createHuffmanTree(PNODE nodes, int lenOfNodes, PNODE childNode)
{
PNODE minWeightNode, parentNode;
minWeightNode = getMinWeightNode(nodes, lenOfNodes);
if (!minWeightNode)
{
return childNode;
}//off if
if (!childNode)
{
parentNode = minWeightNode;
}//off if
else
{
parentNode = createNode(childNode->weight + minWeightNode->weight);
if (childNode->weight < minWeightNode->weight)
{
parentNode->lchild = childNode;
parentNode->rchild = minWeightNode;
}//off if
else
{
parentNode->lchild = minWeightNode;
parentNode->rchild = childNode;
}//off else
parentNode->lchild->binary=0;
parentNode->rchild->binary=1;
childNode->parent = parentNode;
minWeightNode->parent = parentNode;
}//off else
createHuffmanTree(nodes, lenOfNodes, parentNode);
}//off createHuffmanTree
char charTolowercase(char c)
{
if (c >= 'A' && c <= 'Z')
{
c += 'a' - 'A';
}//off if
return c;
}//off charTolowercase
PNODE readFromSource(const char* filePath, char* buff, PNODE childNodes, int& lenOfNodes)
{
//记录字符长度
int lenOfStr = 0, i;
//记录当前读取字符
char c;
FILE* file = fopen(filePath, "rb");
if (file == NULL)
{
puts("Cannot fine source file!");
exit(0);
}//off if
//一个个字符读入本地文本
c = fgetc(file);
while (!feof(file))
{
c = charTolowercase(c);
//初始化节点
initNode(&childNodes[lenOfNodes]);
buff[lenOfStr++] = c;
for (i = 0; i < lenOfNodes; i++)
{
if (childNodes[i].c == c)
{
childNodes[i].weight++;
break;
}//off if
}//off for
if (i == lenOfNodes)
{
childNodes[lenOfNodes].c = c;
childNodes[lenOfNodes++].weight++;
}//off if
c = fgetc(file);
}//off while
buff[lenOfStr] = '\0';
fclose(file);
return createHuffmanTree(childNodes, lenOfNodes, NULL);
}//off readFromSource
void writeResult(const char* filePath, char* result)
{
FILE* fp = fopen(filePath, "wb");
if (fputs(result, fp) >= 0)
{
printf("生成成功\r\n");
}//off if
fclose(fp);
}//off writeResult
char* strDecode(const char* str, PNODE TreeRoot)
{
const char* tmp = str;
char* result = (char*)malloc(MAXSIZE * sizeof(char));
//用来记录字符串长度
int len = 0;
while (*tmp != '\0')
{
PNODE tmpNode = TreeRoot;
while (tmpNode->lchild && tmpNode->rchild)
{
tmpNode = *tmp == '0' ? tmpNode->lchild : tmpNode->rchild;
tmp++;
}//off while
result[len++] = tmpNode->c;
}//off while
result[len] = '\0';
return result;
}//off * strDecode
int main()
{
char buff[MAXSIZE];
NODE childrenNodes[MAXSIZE];
int len = 0;
//确保source.txt和exe处于同目录
PNODE root = readFromSource("source.txt", buff, childrenNodes, len);
writeResult("result.txt", strEncode(buff, childrenNodes, len));
printf("%s", strDecode("11111111111110111111111110011101111111111011001110011111111101111111101111111011111101111101100111101010", root));
print(root);
return 0;
}















 3356
3356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









