






以数组形式创建哈夫曼树,并进行编码解码
哈夫曼树
判断树:用于描述分类过程的二叉树
不同判断树的判断效率不同—>哈夫曼树(最优二叉树)
1 哈夫曼树基本概念
路径:从树中一个结点到另一个结点之间的分支构成这两个结点间的路径
结点路径的长度:两结点间路径上的分支数 树的路径长度:从树根到每一个结点的路径长度之和,记作:TL
权(weight):将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权
结点的带权路径长度:从根结点到该结点之间的路径长度与该结点的权的乘积
树的带权路径长度:树中所有叶子结点的带权路径长度之和,记作WPL (注意只需要乘叶子结点一个权)
哈夫曼树:最优树!带权路径长度(WPL)最短的树
注意:“带权路径长度最短”是在“度”相同的树中比较而得的结果,因此有最优二叉树,最优三叉树之称等。
满二叉树不一定是哈夫曼树,具有相同带权结点的哈夫曼树不唯一。
2 哈夫曼树的构造算法
哈夫曼树中权越大的叶子离根越近
贪心算法:构造哈夫曼树时首先选择权值小的叶子结点
构造哈夫曼树算法步骤:
(1)构造森林全是根,(2)选用两小造新树,(3)删除两小添新人,(4)重复2、3剩单根

哈夫曼树的结点的度数为0或2,没有度为1的结点!
包含n各叶子结点的哈夫曼树中一定有2n-1个结点!
包含n棵树的森林要经过n-1次合并才能形成哈夫曼树,共产生n-1个新结点
3 哈夫曼树算法的实现
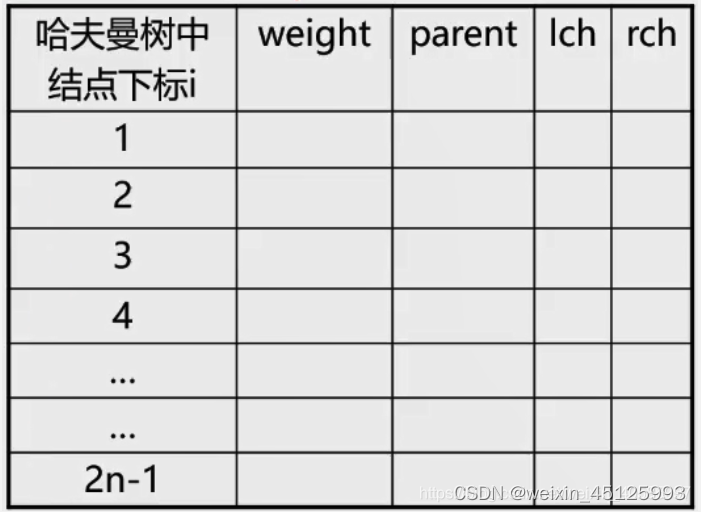
采用顺序存储结构->一维结构数组
结点类型定义:包含weigth,parent,lch,rch
4 哈夫曼编码
设计一种编码方式:
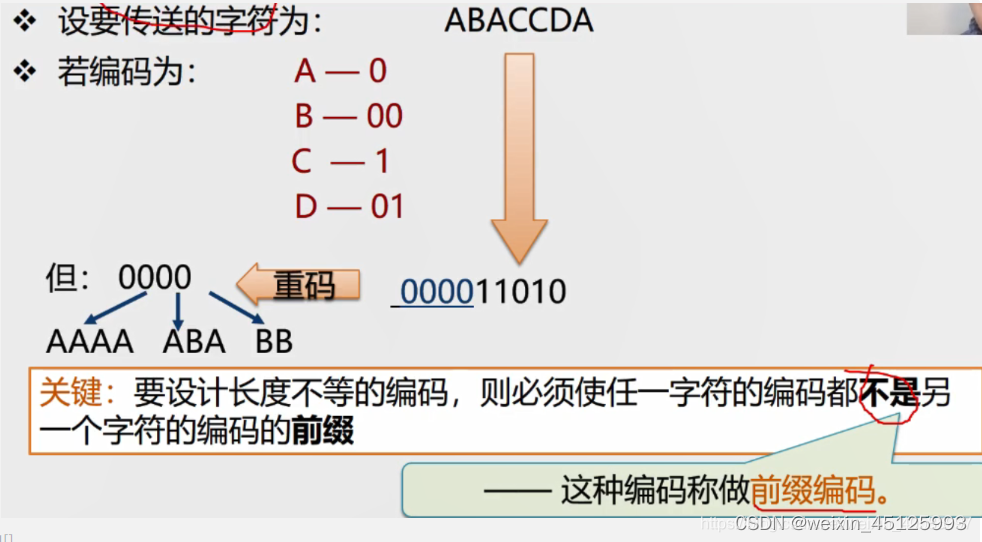
什么样的前缀码能够使得电文总长最短? —>哈夫曼编码
编码步骤:

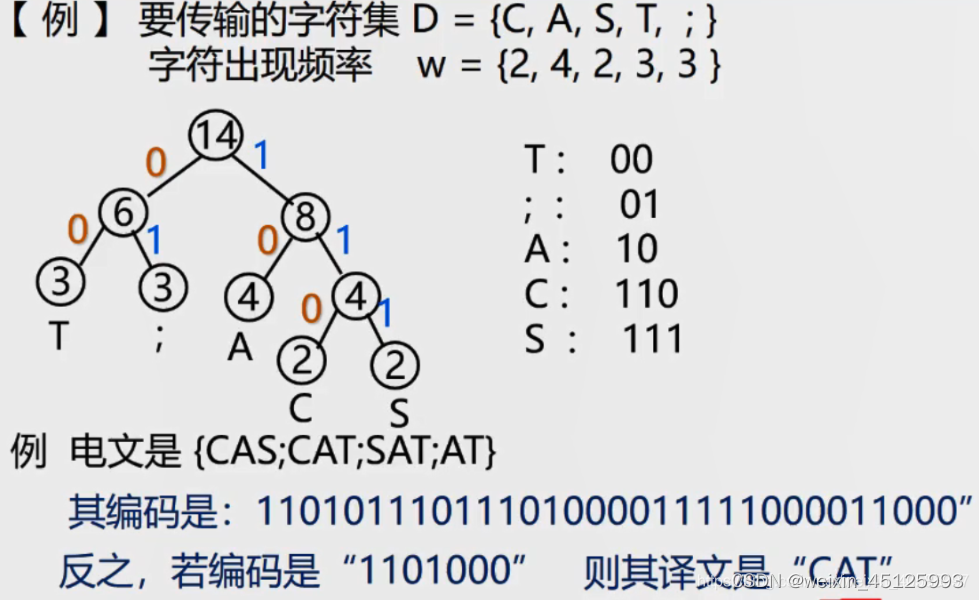
案例:
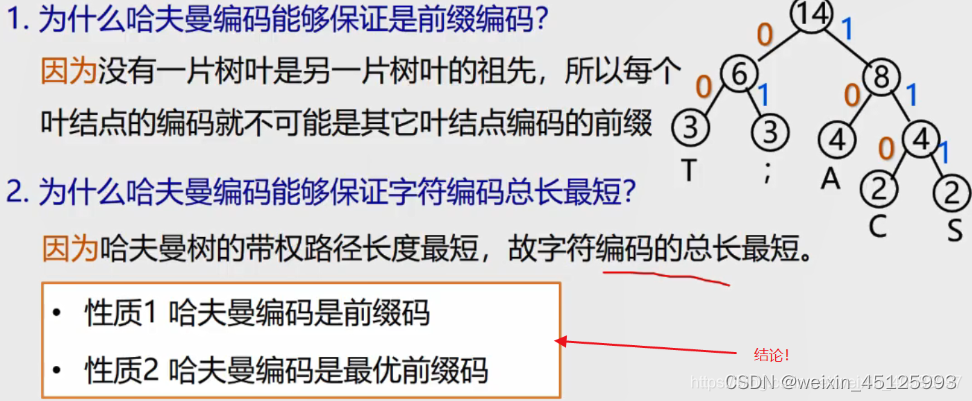
两个问题:
5 哈夫曼编码算法的实现
实现步骤:
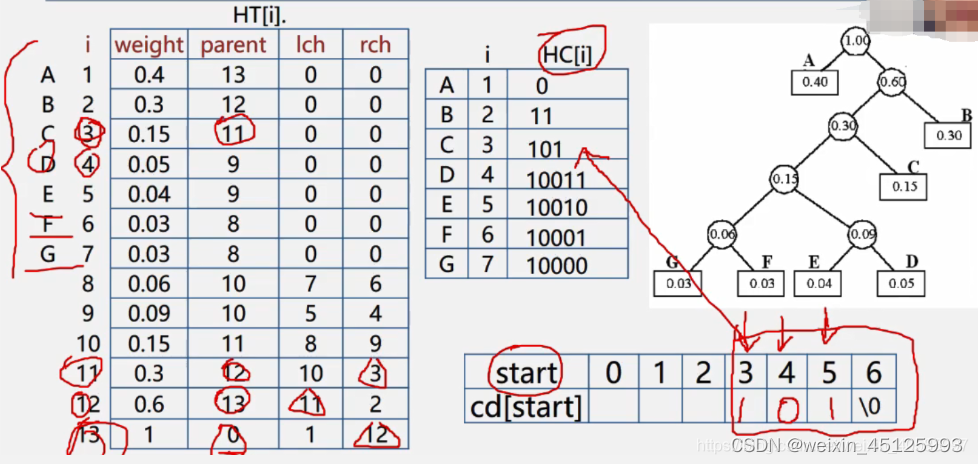
先将数据存储到哈夫曼树中,然后遍历n个子结点,左子树路径赋值0,右子树路径赋值1,使用一个字符数组(大小为n-1,并且最后一位赋值‘\0’,因为n个数据,最多产生n-2个路径)存储遍历过程中的路径值,最后将路径值反转存储到编码数组中即可。
代码实现:
#include<iostream>
using namespace std;
#include<vector>
#include <cstring>
//哈夫曼树的定义
typedef double ElemType;
struct HNode
{
ElemType weight; //权重
int parent, lchild, rchild; //每个结点的双亲、左右孩子的数组下标
};
static char Node[9] = "computer";//保存正文
typedef HNode* HuffmanTree;
typedef char ** HuffmanCode;
void InitHTree(HuffmanTree &H, const int n);
void CreatHuffman(HuffmanTree &H, const int length);
void Select(HuffmanTree &H, const int n, int &i1, int &i2);
void CreateHuffmanCode(HuffmanTree &H, HuffmanCode &HC ,const int n);
void HuffmanTranslateCoding(HuffmanTree &H, int n, char * ch);
void PrintHuffmanWeight(HuffmanTree &H, int n);
//哈夫曼树的初始化
void InitHTree(HuffmanTree &H, const int n)
{
//哈夫曼树的存储结构为顺序存储
//由哈夫曼树的构造过程得知,n个权重结点构造出的哈夫曼树具有2*n-1个结点
//通常哈夫曼树的顺序存储结构下标从1开始计数,因此,如果我们使用数组实现的话
//那么数组的长度应该是2*n
H = new HNode[2 * n];
for (int i = 1; i < 2 * n; ++i)//初始化H[1,2n-1]
{
H[i].parent = H[i].lchild = H[i].rchild = 0;//右结合律
}
//输入初始n个叶子结点:设置H[1,n]的weight值
ElemType input;
for (int i = 1; i <= n; ++i)
{
cin >> input;
H[i].weight = input;
}
}
//哈夫曼树的构造算法
void CreatHuffman(HuffmanTree &H, const int length)
{
//第一步:对哈夫曼树进行初始化
InitHTree(H, length);
//第二步:找出当前森林中最小的两棵树,创建新树,并让原来的两个树作为新树的孩子,i1和i2是最小的两棵树的下标
for (int i = length + 1; i < 2 * length; ++i)//合并产生n-1个结点
{
int i1 = 0, i2 = 0;
Select(H, i - 1, i1, i2);//重点是这个Select算法
H[i].weight = H[i1].weight + H[i2].weight;//
H[i1].parent = H[i2].parent = i;
H[i].lchild = i1;
H[i].rchild = i2;
}
}
//select算法
void Select(HuffmanTree &H, const int n, int &i1, int &i2)
{
vector<int> vec;
for (int i = 1; i <= n; ++i)
{
if (H[i].parent == 0)//未被选择的结点下标加入vector内
{
vec.push_back(i);
}
}
//找出最小的一个
auto flag1 = vec.begin();
for (auto it = vec.begin() + 1; it != vec.end(); ++it)
{
if (H[*it].weight < H[*flag1].weight)
{
flag1 = it;
}
}
i1 = *flag1; //最小的元素下标
vec.erase(flag1);//去除最小的元素下标
auto flag2 = vec.begin();
for (auto it = vec.begin() + 1; it != vec.end(); ++it)
{
if (H[*it].weight < H[*flag2].weight)
{
flag2 = it;
}
}
i2 = *flag2; //第二小的元素的下标
}
//哈夫曼树编码算法
void CreateHuffmanCode(HuffmanTree &H, HuffmanCode &HC ,const int n)
{
//从叶子到根逆向求每个字符的哈夫曼编码,存储在编码表Hc中
for (int i = 1; i <= n; i++)
{
/*建立临时存放字符串的数组,倒序存放,正序读取,
因为叶子结点只有n个,必然有两个结点合并,所以huffman树最多有n-1层,
字符数组ch的最大长度为n即可,存储n-1个数据*/
HC = new char *[n + 1]; //数组从下标1开始存储
char * cd = new char[n];
cd[n-1] = '\0';
int start = n - 1;//逆序存放,正序读取
int c = i;//临时存放当前结点的下标
int f = H[i].parent;//从当前结点的父节点开始查找
while (f != 0)//查找到父节点不存在为止
{
--start;
if (H[f].lchild == c)
{
cd[start] = '0';//左孩子为0
}
else
{
cd[start] = '1';//左孩子为1
}
c = f;//当前结点成为孩子结点
f = H[f].parent;//更新父节点
}
HC[i] = new char[n-start];
strcpy(HC[i], &cd[start]);//找完之后把编码赋值给HC
delete cd;
}
}
//哈夫曼树解码算法
void HuffmanTranslateCoding(HuffmanTree &H, int n, char * ch)
{
int m = 2 * n - 1;//从根节点遍历到叶子结点
int i, j = 0; //i是建立的哈夫曼编码的数组下标,j是要解码的char数组下标
// char str[] = NULL;
cout << "After Translation:" << endl;
while(ch[j]!='\0')//ch[]:你输入的要译码的字符串
{
i = m;//从根节点遍历到叶子结点
while(0 != H[i].lchild && 0 != H[i].rchild)//从顶部找到最下面
{
if('0' == ch[j])//0 往左子树走
{
i = H[i].lchild;
}
else//1 往右子树走
{
i = H[i].rchild;
}
++j;//下一个路径
}
cout << Node[i-1] << endl;//打印出来
}
}
//遍历树的权重
void PrintHuffmanWeight(HuffmanTree &H, int n)
{
cout << "树的weight:" << endl;
for (int i = 1; i < 2 * n; i++)
{
cout << H[i].weight << " ";
}
cout << endl;
cout << "树的parent:" << endl;
for (int i = 1; i < 2 * n; i++)
{
cout << H[i].parent << " ";
}
cout << endl;
cout << "树的lch:" << endl;
for (int i = 1; i < 2 * n; i++)
{
cout << H[i].lchild << " ";
}
cout << endl;
cout << "树的rch:" << endl;
for (int i = 1; i < 2 * n; i++)
{
cout << H[i].rchild << " ";
}
cout << endl;
}
int main(){
HNode * Huffman = NULL;
int n = 7;
CreatHuffman(Huffman, n);
PrintHuffmanWeight(Huffman, n);
HuffmanCode Hcode = NULL;
CreateHuffmanCode(Huffman, Hcode, n);
char nd [] = "0001100001000110011010101111";
HuffmanTranslateCoding(Huffman, n, nd);
system("pause");
return 0;
}














 3949
3949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









