






实验二 玻尔兹曼机BM
一、实验学时: 2学时
二、实验目的
- 深入理解玻尔兹曼机的基本原理和结构;
- 掌握玻尔兹曼机的实现方法,包括模型构建、参数初始化、训练算法的实现等;
- 能够运用玻尔兹曼机对给定的数据进行处理和分析,通过实验结果评估模型性能,从而考察对玻尔兹曼机应用的掌握程度;
三、实验环境
(一)硬件环境:
- PC机一台;
- 内存要求:不少于2G;
- 磁盘空间要求 :不少于50G剩余磁盘空间;
(二)软件环境:
- 操作系统要求:Windows(32位/64位)7/10/11等均可;
- 文档工具要求:WPS或者office均可;
- 编程语言要求:Python;
四、实验内容与结果
- 详细阐述玻尔兹曼机的定义、结构特点,包括神经元连接方式、可见层与隐藏层的作用。
- 考察学生对玻尔兹曼机模型结构的实现能力,包括如何定义可见层和隐藏层神经元数量、连接权重的初始化方式;
- 描述训练算法(如对比散度)的具体实现步骤,包括如何进行采样、计算梯度和更新权重;
- 使用Python实现玻尔兹曼机(BM),要求构建一个简单的玻尔兹曼机,并使用对比散度(Contrastive Divergence, CD)算法进行训练。
注意:因为BM算法训练复杂度高,所以准备一点点数据进行训练即可;激活函数使用sigmoid;
实验内容:
- 玻尔兹曼机:
(1)定义:玻尔兹曼机是一种随机性神经网络,由节点(神经元)和节点间的连接权重组成。该网络通过模拟神经元之间的随机交互来调整自身的状态,以寻找系统的低能量状态。它的最终目的是学习数据的概率分布,即能够生成新的样本,类似于训练数据的样本。
(2)特点:① 网络结构:玻尔兹曼机包含可见层(输入层)和隐藏层,层与层之间的节点是全连接的,但同层内的节点不相连。
② 能量函数:网络中的状态由一个能量函数定义,该函数衡量了网络中所有节点状态的“能量”。
③ 概率分布:网络的平衡状态服从玻尔兹曼分布,这是一种描述粒子在不同状态下的概率分布的函数。
④ 学习机制:玻尔兹曼机通过模拟退火算法来调整权重,从而学习数据的分布。
⑤ 生成模型:玻尔兹曼机是一种生成模型,能够生成新的数据样本,这使得它在无监督学习中非常有用。
(3)玻尔兹曼机基本组成:
① 神经元:Boltzmann机中的神经元可以分为可见神经元和隐藏神经元。可见神经元用于接收输入数据和输出结果,它们与外部环境进行交互。隐藏神经元则在网络内部,用于辅助处理信息和捕捉数据中的复杂关系。每个神经元都有一个状态,通常是二进制的(0或1),不过在一些变体中也可以是连续值。
② 连接权重:神经元之间通过连接权重相互连接。设神经元i和神经元j之间的连接权重为
,权重矩阵
描述了整个网络的连接情况。权重的大小和正负决定了神经元之间相互影响的强度和性质。在Boltzmann机中,权重是对称的,即
,且
= 0 (无自连接)。这种对称的权重结构对于网络的能量函数和学习算法具有重要意义。
③ 偏置项:每个神经元还有一个偏置项,用于调整神经元的激活阈值。偏置项
对于可见神经元和隐藏神经元都存在,它在网络的能量计算和状态更新过程中发挥作用。
(4)玻尔兹曼机的类型:
① 标准玻尔兹曼机(BM):标准玻尔兹曼机是一个全连接的无向图模型,如图4-1所示,其中每个节点都可以与其他节点相连。每个神经元的激活状态取决于周围神经元的状态。由于节点间的连接非常复杂,标准玻尔兹曼机的训练和计算难度非常高,导致其应用受到限制。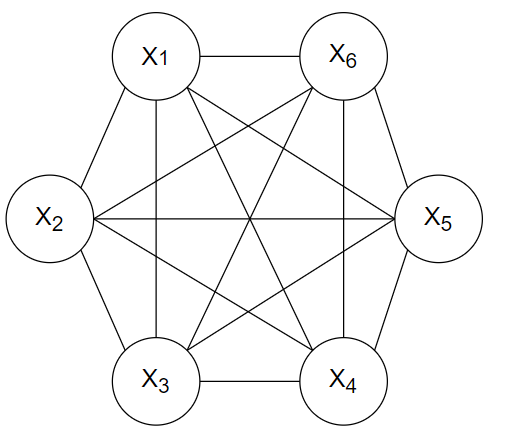
图4-1 六个变量的玻尔兹曼机
② 受限玻尔兹曼机(RBM):受限玻尔兹曼机是一种简化版本的玻尔兹曼机,如图4-2所示。它由两层神经元组成,即可见层和隐藏层。RBM中的节点连接受到限制:可见层和隐藏层之间是全连接的,但层内节点之间无连接(即可见层节点彼此独立,隐藏层节点彼此独立)。这种结构的简化使得RBM的训练效率更高,常用于推荐系统、特征学习和数据降维等任务。
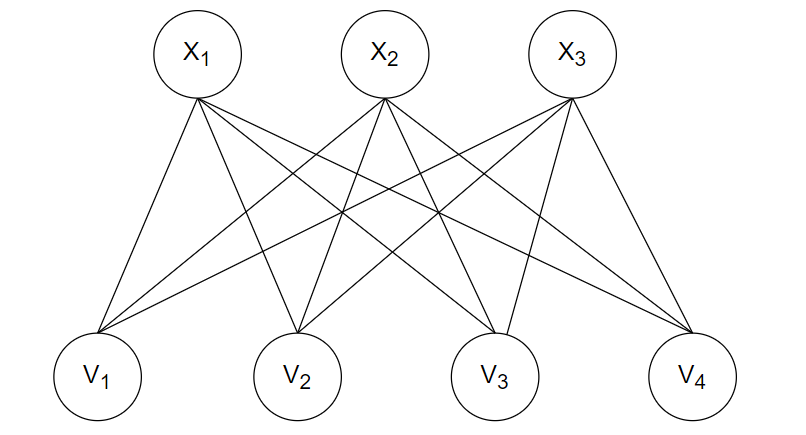
图4-2 受限玻尔兹曼机
③ 深度玻尔兹曼机(DBM):深度玻尔兹曼机通过堆叠多个RBM层构成,是一种多层结构的深度学习模型。DBM中每一层都可以看作一个RBM,通过逐层训练和调优,这种多层结构可以捕捉数据的复杂特征。DBM在图像处理和自然语言处理领域有一定应用。
(5)神经元连接方式:标准玻尔兹曼机有全连接结构,包括可见层内部、隐藏层内部以及层间连接。每个神经元都与所有其他神经元双向连接,形成对称权重;受限玻尔兹曼机有层间全连接,但同层内无连接。可见层和隐藏层之间的连接是双向的,但权重对称。
- 实现简单的受限玻尔兹曼机,代码如下:
import numpy as np # 受限玻尔兹曼机(RBM) class RBM: def __init__(self, num_visible, num_hidden): self.num_visible = num_visible # 可见层神经元数量 self.num_hidden = num_hidden # 隐藏层神经元数量 # 权重矩阵 W, 随机初始化权重,均值为 0,标准差为 0.1 self.W = np.random.normal(0, 0.1, (num_visible, num_hidden)) self.b = np.zeros(num_visible) # 可见层的偏置项 self.c = np.zeros(num_hidden) # 隐藏层的偏置项 def energy(self, v, h): return -np.sum(self.W * v.reshape(-1, 1) * h.reshape(1, -1)) - np.sum(self.b * v) - np.sum(self.c * h)其中能量函数为
另外,权重初始化使用均值为0、标准差为0.1的高斯分布初始化权重矩阵和隐藏层偏置
初始化为零向量。
- 核心思想:通过运行k步吉布斯采样(通常k=1)快速逼近梯度,避免传统吉布斯采样需要达到平稳分布的高计算代价。
(1)正向传播,计算隐藏层概率,计算隐藏层激活概率:
其中为 Sigmoid 函数:
代码如下:def sample_hidden(self, v): # 从可见层采样隐藏层 h_prob = 1 / (1 + np.exp(-np.dot(v, self.W) - self.c)) # 隐藏层概率 return np.random.binomial(1, h_prob) # 二值化采样(2)负相采样从隐藏层
重构可见层
代码如下:def sample_visible(self, h): # 从隐藏层采样可见层 v_prob = 1 / (1 + np.exp(-np.dot(h, self.W.T) - self.b)) # 可见层概率 return np.random.binomial(1, v_prob) # 二值化采样(3)二次正向传播,根据重构的可见层
计算隐藏层概率。
(4)通过正相(数据分布)和负相(模型分布)的统计量计算参数梯度。对比散度(CD-k)梯度公式如下:
其中:
为学习率
为权重衰减系数(L2正则化)
表示期望值
k为吉布斯采样步数(通常k=1)
完整代码如下:
import numpy as np class RBM: def __init__(self, num_visible, num_hidden, lr=0.01, weight_decay=1e-4): self.num_visible = num_visible self.num_hidden = num_hidden self.lr = lr self.weight_decay = weight_decay # 初始化参数 self.W = np.random.normal(0, 0.01, (num_visible, num_hidden)) self.b = np.zeros(num_visible) self.c = np.zeros(num_hidden) def sample_hidden(self, v): # 从可见层采样隐藏层 h_prob = 1 / (1 + np.exp(-np.dot(v, self.W) - self.c)) # 隐藏层概率 return np.random.binomial(1, h_prob) # 二值化采样 def sample_visible(self, h): # 从隐藏层采样可见层 v_prob = 1 / (1 + np.exp(-np.dot(h, self.W.T) - self.b)) # 可见层概率 return np.random.binomial(1, v_prob) # 二值化采样 def train_step(self, v0, k=1): # 正相:计算隐藏层 h0 = self.sample_hidden(v0) # 负相:k 步吉布斯采样 vk = v0.copy() for _ in range(k): hk = self.sample_hidden(vk) vk = self.sample_visible(hk) # 计算梯度 positive_grad = np.dot(v0.T, h0) / v0.shape[0] negative_grad = np.dot(vk.T, self.sample_hidden(vk)) / vk.shape[0] delta_W = positive_grad - negative_grad delta_b = np.mean(v0 - vk, axis=0) delta_c = np.mean(h0 - self.sample_hidden(vk), axis=0) # 更新参数 self.W += self.lr * delta_W - self.weight_decay * self.W self.b += self.lr * delta_b self.c += self.lr * delta_c - Python实现标准玻尔兹曼机,使用对比散度(Contrastive Divergence, CD)算法进行训练,采用sigmoid激活函数,详细代码如下:
import numpy as np class BoltzmannMachine: def __init__(self, num_visible, num_hidden, lr=0.1, weight_decay=1e-4): self.nv = num_visible # 可见层神经元数 self.nh = num_hidden # 隐藏层神经元数 self.lr = lr # 学习率 self.wd = weight_decay # 权重衰减系数 # 初始化对称权重矩阵 (包含可见层和隐藏层内部的连接) self.W = np.random.normal(0, 0.01, (self.nv + self.nh, self.nv + self.nh)) np.fill_diagonal(self.W, 0) # 禁止自连接 self.W = (self.W + self.W.T) / 2 # 强制对称 # 初始化偏置项 self.b = np.zeros(self.nv + self.nh) def sigmoid(self, x): return 1 / (1 + np.exp(-x)) def sample_units(self, state, steps=1): for _ in range(steps): order = np.random.permutation(self.nv + self.nh) for unit in order: # 计算激活概率 logit = np.dot(self.W[unit, :], state) + self.b[unit] prob = self.sigmoid(logit) state[unit] = np.random.binomial(1, prob) return state def train_step(self, visible_data, k=1): """对比散度训练""" batch_size = visible_data.shape[0] # 构建完整初始状态 state_0 = np.zeros((batch_size, self.nv + self.nh)) state_0[:, :self.nv] = visible_data # 正相采样 state_0 = np.array([self.sample_units(s.copy(), steps=3) for s in state_0]) # 负相采样(k步) state_k = state_0.copy() state_k = np.array([self.sample_units(s.copy(), steps=k) for s in state_k]) # 计算梯度 positive = np.dot(state_0.T, state_0) / batch_size negative = np.dot(state_k.T, state_k) / batch_size grad_W = positive - negative - self.wd * self.W # 更新参数 self.W += self.lr * (grad_W + grad_W.T) / 2 # 对称更新 self.b += self.lr * (state_0.mean(axis=0) - state_k.mean(axis=0)) # 计算可见层重构误差 error = np.mean((state_0[:, :self.nv] - state_k[:, :self.nv]) ** 2) return error # 测试运行 if __name__ == "__main__": # 3个可见神经元,2个样本 data = np.array([[1, 0, 1], [0, 1, 0]], dtype=np.float32) # 创建模型(可见层3,隐藏层2) bm = BoltzmannMachine(num_visible=3, num_hidden=2, lr=0.1) # 训练循环 for epoch in range(50): err = bm.train_step(data, k=1) if (epoch + 1) % 5 == 0: print(f"Epoch {epoch + 1:2d} | Error: {err:.4f}"
五、实验小结(包括问题和解决办法、心得体会、意见与建议等)
1.问题和解决办法:
问题1:程序抛出数值错误,能量函数或概率计算异常。
解决方法:初始化时使用更小的标准差如0.01。
问题2:程序报错ValueError: shapes (5,) and (2,5) not aligned: 5 (dim 0) != 2 (dim 0)。
解决方法:使用公式计算梯度是转置后的行列不对。
2.心得体会:通过本次实验,我不仅掌握了玻尔兹曼机的核心原理和实现技巧,更深刻体会到 理论推导与工程实现的鸿沟。BM 的实现过程像一面镜子,映射出概率图模型的优雅与复杂性。尽管其实用性受限,但手动实现 BM 的经历为我理解更复杂的生成模型(如深度玻尔兹曼机等)奠定了坚实基础。未来,我将继续探索高效的概率建模方法,平衡模型表达力与计算效率,推动其在真实场景中的应用。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











