






论文:《Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results》
纯主观理解,如有错误,敬请斧正。请以原文为准。
提出一种改进时域集成(TE)在大数据集效果较差的半监督学习方式Mean Teacher。
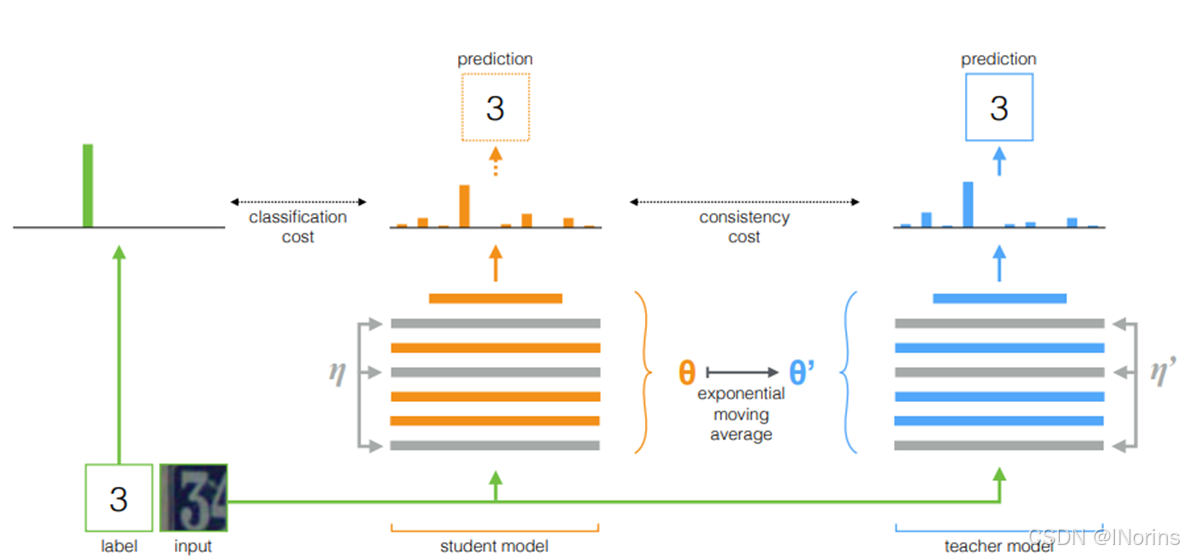

1. TE和MT的区别是什么:TE去EMA的是Prediction , 而MT去EMA的是模型参数。为了保存EMA的参数信息,MT比TE多了一个teacher model。
2. 优势:可以在使用更少的label数据的情况下,获得更高的Acc;大数据集中效果更好;
3. 缺点:EMA 模型参数要比EMA Prediction慢。
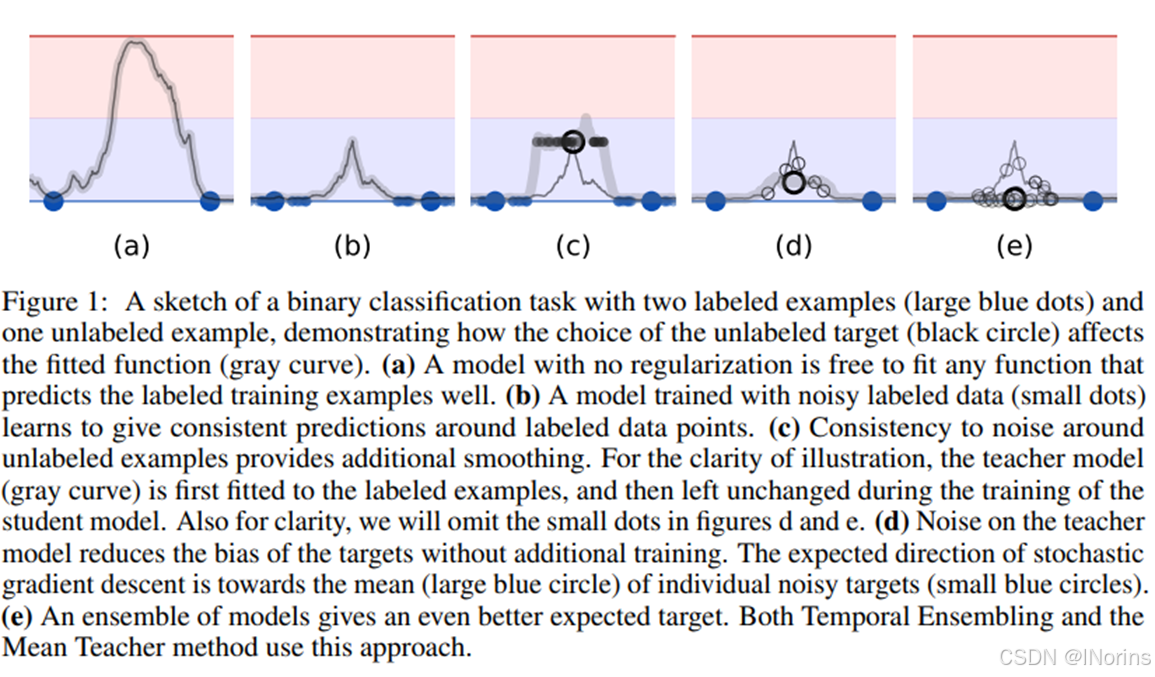
蓝点是label数据,黑点是unlabel数据, 大点是原始数据,小点是加噪数据,
上面的灰块是0类,下面的蓝块是1类 a, b 没有unlabel数据,c, d, e 有unlabel数据
4. 从二分类证明噪声和unlabel的作用
a). 没正则化的模型拟合的很自由,数据少的时候欠拟合,数据过多会过拟合。
b).在不加正则化的情况下,模型只关注zero-dimensional data points(就是无噪原始数据),单独优化每个点的分类性能,从而导致在这些点上过拟合。加噪之后,模型仅会在这些点的流形附近,从而不去过拟合原始数据,这样可以在保证决策边界有效的情况下使决策边界远离zero-dimensional data points,从而平滑决策边界
c). 在b的基础上,继续添加unlabel。然后为unlabel加噪。模型同时作为Stu和Tea,作为Stu,正常使用有标签数据和Tea拟合的伪标签数据进行学习,作为Tea,生成伪标签。但是由于模型本身生成伪标签可能是错误的,如果unlabel的一致性损失权重过大,模型就会更加偏向拟合伪标签,导致c这种情况,导致难以学习新的有效信息。这种风险可以通过提高目标质量来缓解
d). 模拟Π-model,通过学生模型本身来构建一个更强大的Tea,这里的Tea就是生成Z~的过程,模拟效果(d)显示带噪Tea可以生成更准确的目标,如图,d比b的边界更加平滑。
e). 然后e是一个集成模型(综合考虑模型在不同时期对同一个样本的预测的集成),模拟的是TE和MT,这种集成模型给出了更加平滑的决策边界(直接平了)。而MT和TE都是如e的“集成模型(时间上的集成)”所以MT是可行的

5. 为什么叫Mean Teacher:Tea是Stu模型参数的指数移动平均值,所以叫Mean Teacher
6. Stu和Tea用相同噪声 (η, η0 ) 为input加噪。将Stu的 softmax 输出和GT做监督损失(L)和Tea的伪标签做一致性损失(J(θ)),Loss=L+J对使用梯度下降法更新学生模型的权重后,教师模型权重将更新为学生权重的指数移动平均值。这两个模型输出都可用于预测,但最后保留Student模型,尽管原文说“but at the end of the training the teacher prediction is more likely to be correct”。
7. MT在每个step后聚合信息就马上投入下一step进行使用,而不是像TE是在每个epoch后聚合信息后在下一轮再投入使用,所以由这个优势,MT会更优于TE,获得更好的网络参数,从而达到更优的拟合效果。
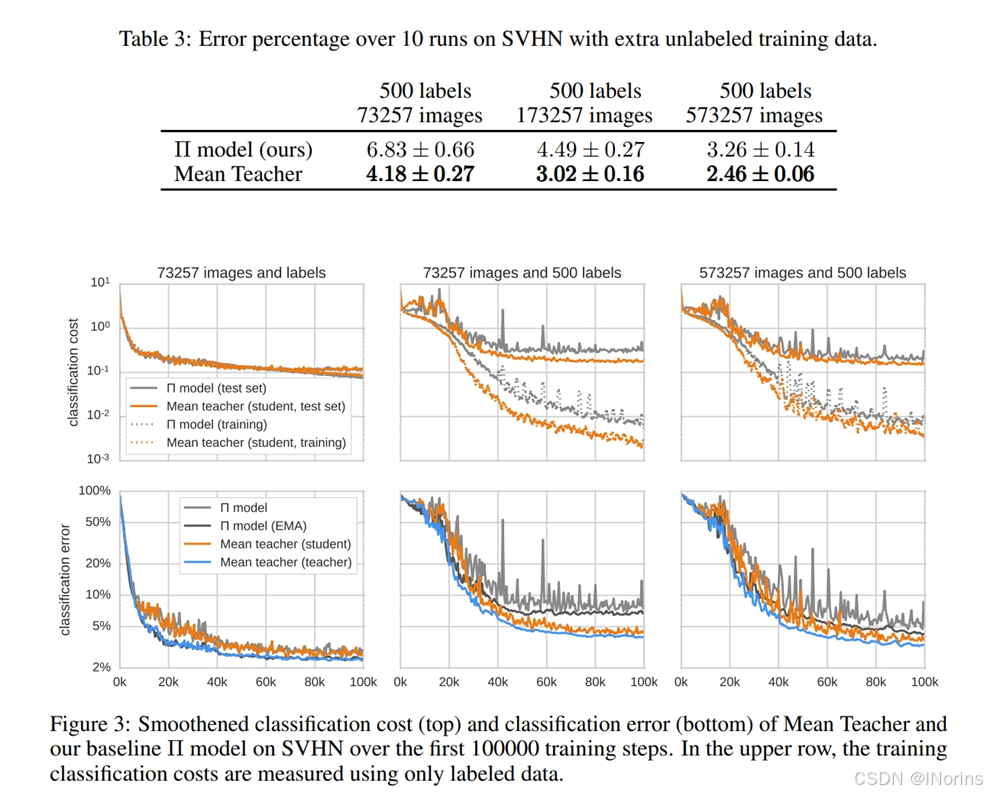
8. Teacher模型:如右图下面三张图,说明了分类错误概率的的变化,Tea明显比Stu的分类错误概率跟低,而且减小趋势更稳定。 Tea的参数是通过对 Stu的参数进行EMA更新的。由于 EMA 平滑了参数变化,Tea的权重更新更稳定,对噪声和波动的响应较小。因此,Tea会逐渐积累更可靠的特征表示,捕捉到学习过程中的长时间稳定趋势,降低了训练过程中不稳定的影响。(但我实际上测试起来还是Student好一点,就一点点)
9. 为什么每个step立即使用学习到的信息比等到每一轮结束后再使用学习到的信息更好:每一步的更新都立即为模型做出贡献,使其更好地适应数据的变化,从而提升效率。
10. 右图上面三张图,Tea和Stu有效的EMA循环反馈是良性的,因为当EMA参数α为0时,模型退化为Π-model,即灰线,学习速度明显变慢,而且模型会更早开始过拟合。但有一个问题,左到右数据量逐渐增大,可以看到MT和Π-model差距越来越小,大量的数据抵消了 Π 模型较差的预测效果(注:这里Π模型理论上是不变的,但是他用了两个模型,而非原来的一个模型,因为这样更好控制变量,为了拟合α=0退化成Π-model的效果,Tea和Stu都进行了反传)
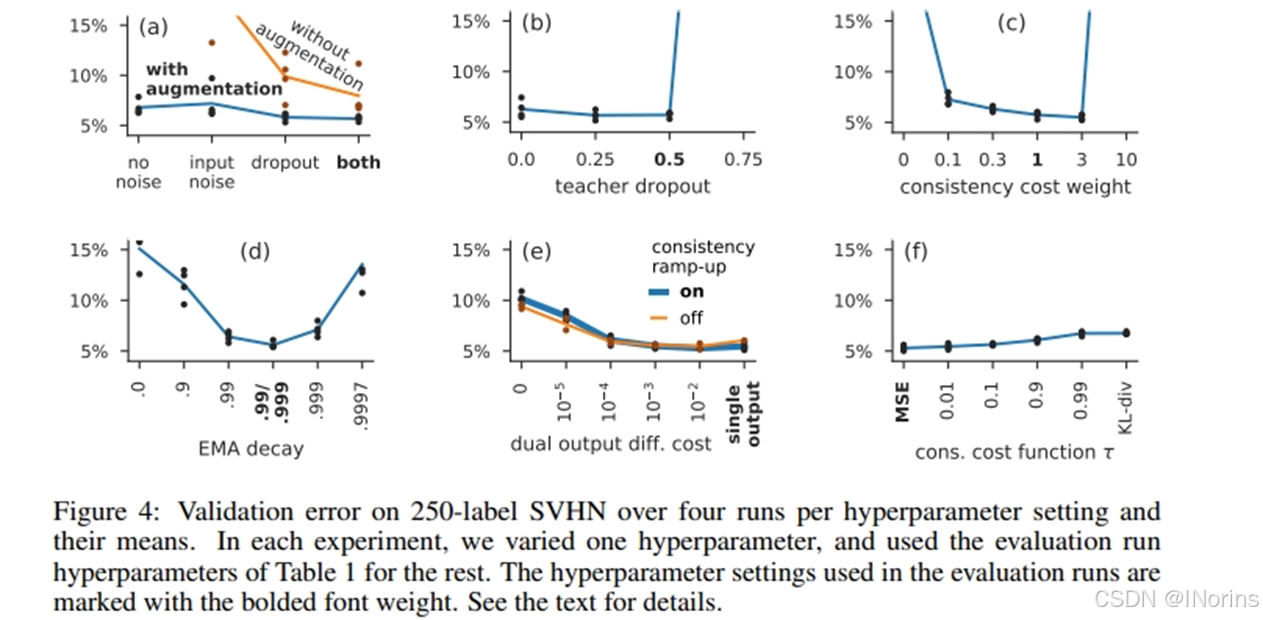
11. 消融实验:
a), b): 噪声消融:加入数据增强和dropout后性能提升。Tea应用dropout的效果没有Stu明显。
c): 一致性损失的权重超参十分敏感,应保持权重最大值在0.1~3之间,其他区间有明显的性能下降。
d) EMA的参数α应为0.99或者0.999以保持最佳性能,d图最低点使用的是预热阶段0.99,达到最大一致性损失权重后0.999。因为 Student 模型在早期训练中进步较快, Tea应快速遗忘旧的、不准确的 Student 参数。随Stu进步减缓,Tea记忆力增加,从更长的记忆中受益。
e). 图像分类和Tea、Stu一致性解耦合,并控制一致性损失权重预热是否开启:把分类输出和一致性输出分离,两个输出之间用MSE控制他们的输出关系调整权重,由e,强耦合的拟合效果明显优于弱耦合,但是耦合到一定程度时,是否启动一致性损失权重预热变得不再必要了。
11. 消融实验:
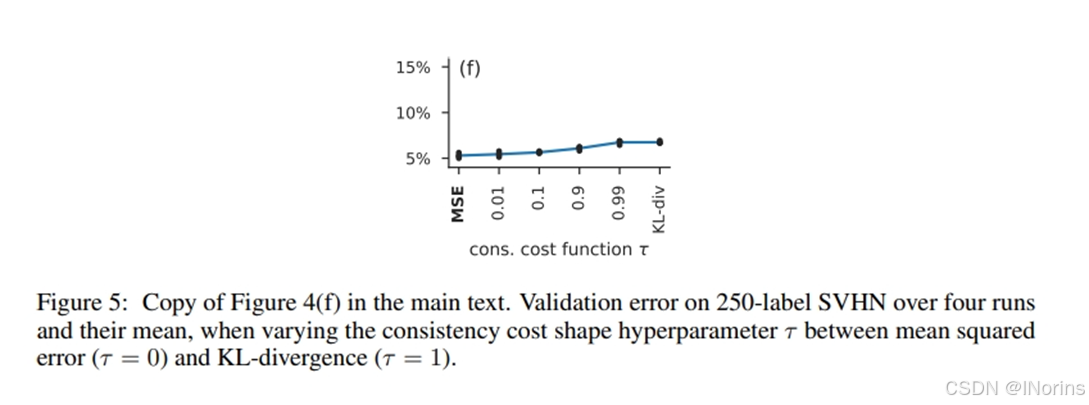
f). 说明MSE效果比KL-散度(相对熵)在计算一致性损失时拥有更好的效果。文章说MSE 表现优于 KL 散度的具体原因尚不明确,但提出了一个解释(还没有经过实验验证):现代神经网络架构往往生成准确但过于自信的预测,假设GT是准确的,Tea生成的伪标签是存疑的,所以监督损失可以设置为τ=1( τ 在0到1之间,越高给GT的信任度越高),给极高的信任,然后给Tea的伪标签较低的信任( τ<1 ),从而对对过于自信的输出进行调整。
以上!

















 442
442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









