







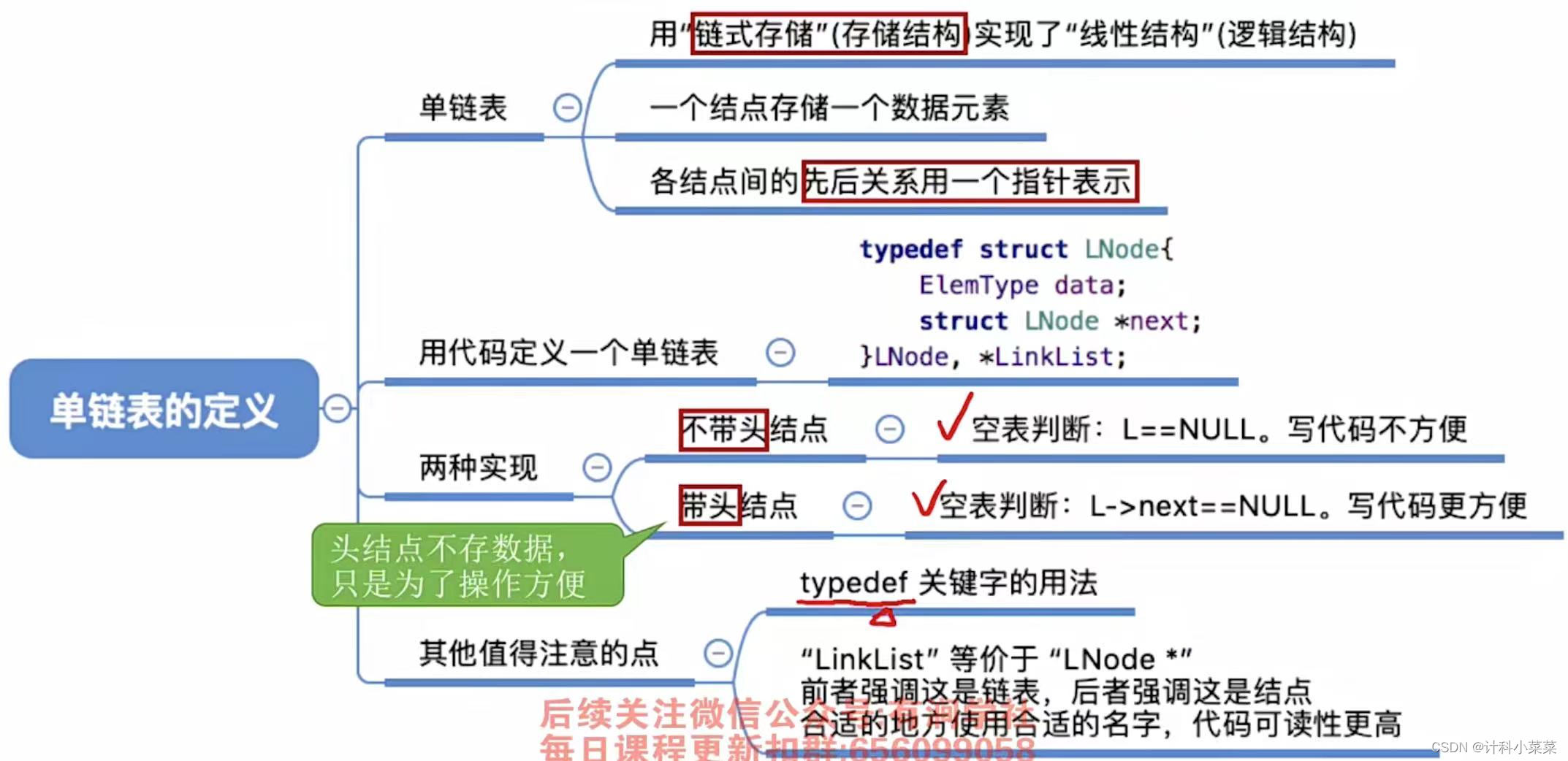
单链表
顺序表的存储位置可以用一个简单直观的公式表示,它可以随机存取表中任意一个元素,但插入和删除操作需要移动大量元素。链式存储线性表时,不需要使用地址连续的存储单元,即不要求逻辑上相邻的元素在物理位置上也相邻,它通过“链”建立起元素之间的逻辑关系,因此插入和删除操作不需要移动元素,而只需修改指针,但也会失去顺序表可随机存取的优点。
1 定义链表结构
线性表的链式存储又称单链表,它是指通过一组任意的存储单元来存储线性表中的数据元素。为了建立数据元素之间的线性关系,对每个链表结点,除存放元素自身的信息外,还需要存放一个指向其后继的指针。单链表结点结构如下代码所示,其中 data 为数据域,存放数据元素;next为指针域,存放其后继结点的地址
定义一个结构体来实现单链表
typedef 关键字的作用相当于起别名
有关结构体的定义,可以看看我的这篇博客c++结构体的定义
c语言也适用
typedef struct LNode {
int data; //单链表节点类型,即存放的数据类型
struct LNode* next; //指针指向下一个节点
}LNode,*LinkList;
//等价于
//struct LNode
//{
// int data;
// struct LNode* next;
//};
//typedef struct LNode LNode; LNode是struct LNode的别名
//typedef struct LNode* LinkLIst; LinkLIst 是struct LNode*的别名
//别名与本名功能一模一样,都可以用来定义变量,效果一样
//这里注意 Lnode* 与LinkList是等价的
别名与本名功能一模一样,都可以用来定义变量,效果一样
这里注意 Lnode* 与LinkList是等价的
2 链表的初始化
bool InitalList(LinkList& L){
L = (LNode*)malloc(sizeof(LNode));
if (L == NULL)return false; //内存不足,申请失败
L->next = NULL;//头结点之后还没有新的结点,所以传空
//会有人疑问为什么没有给头结点的data赋值
//因为头结点不参与保存数据,只是为了方便操作链表额外添加 的虚拟头结点
return true;
}
3 头插法创建单链表
因为每次创建新结点的时间复杂度是O(1),所以总时间复杂度为O(n)
看图
数字代表代码运行的先后步骤
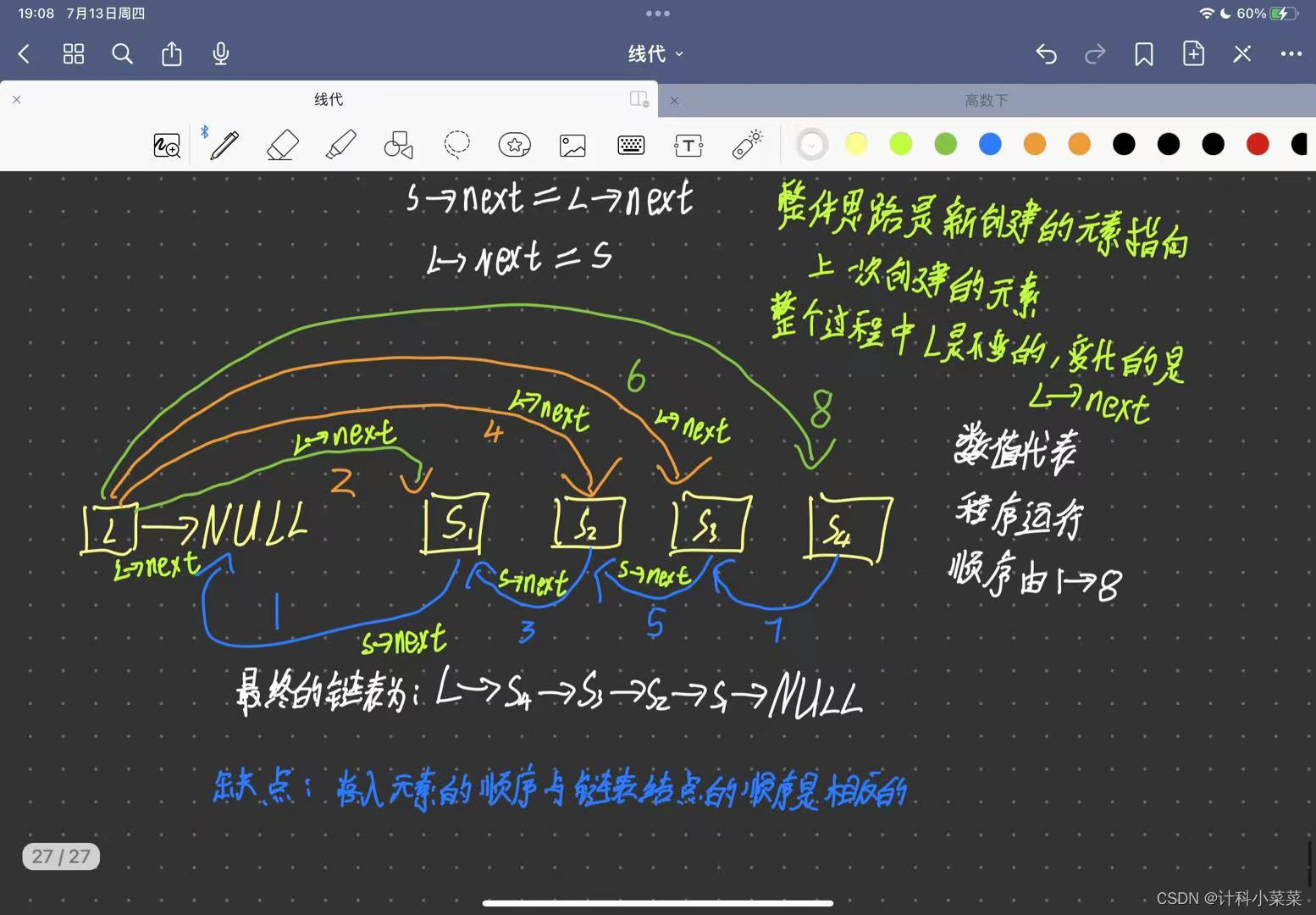
大致思路就是,每一次新创建的结点,都让他指向上一次的结点,即每次创建的结点都是最新的头指针,最终发现是一个反向的链表,先存入的数据会在末尾,最晚存储的数据是头指针
因为L->next实际指向的就是上一次的结点,所以我们让s->next指向L->next
达到了让新结点指向上一次结点的功能
然后将L->next指向s 达到刷新的效果,让L->next始终指向的是上一次的结点
到最后因为没有新结点,L->next指向的就是头指针,L自己就是头结点
整个过程中L是没有变化的,发生变化的一直是L->next;
void BuildListHead(LinkList& L) {
LNode* s=L;
int x; //输入的值 规定当输入-1时结束创建
scanf_s("%d", &x);
while (x != -1) {
s = (LNode*)malloc(sizeof(LNode)); //为链表申请新空间
s->data = x;
s->next = L->next;
L->next = s;
scanf_s("%d", &x);
}
}
注意头插法是有缺陷的,它的存入顺序和链表节点是相反的,我们使用时可能会不方便,所以我们通常使用接下来介绍的尾插法
4 尾插法创建单链表
在这特意感谢王学姐对尾插法的指点
同头插法因为每次创建新结点的时间复杂度是O(1),所以总时间复杂度为O(n)
看图
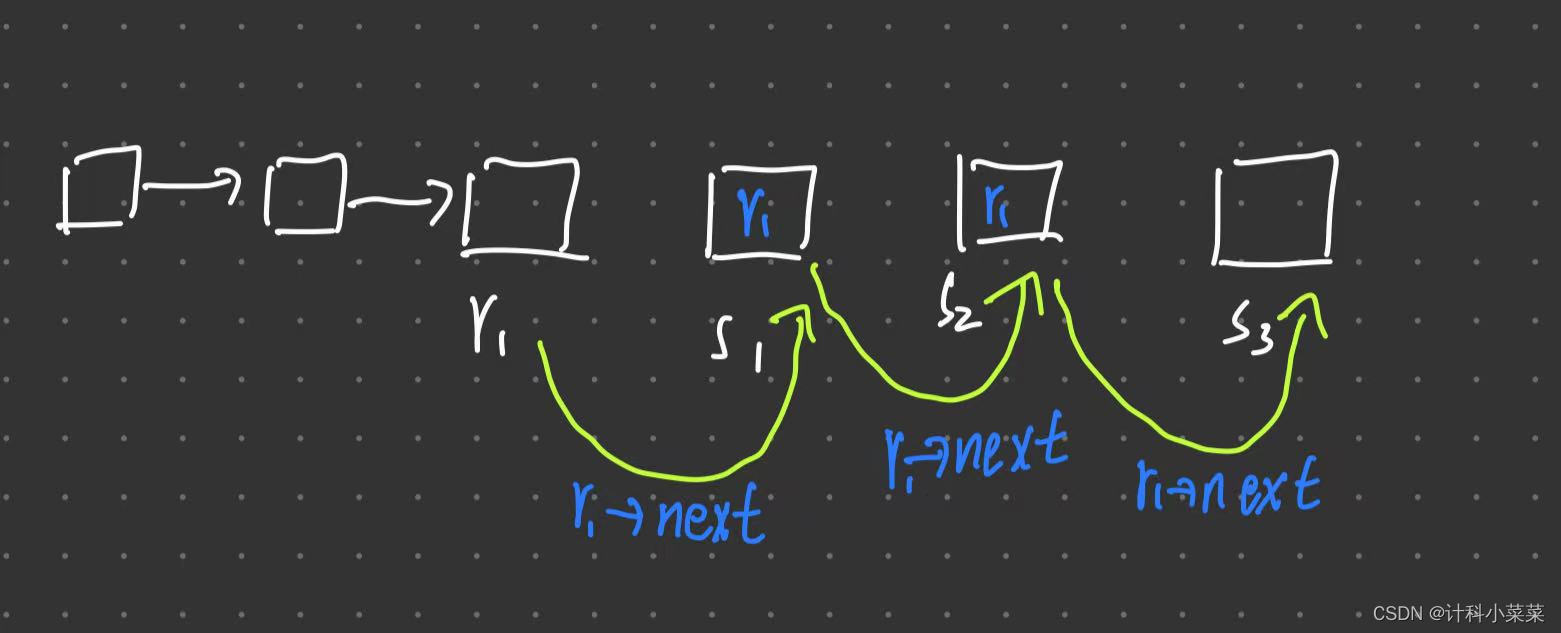
思路是,我们选择s为新来的结点,让r作为链表每次的尾节点,新创建一个结点,就让 r->next=s 来指向新结点,然后让 r=s 使新节点成为尾节点
r->next=s 的功能是实现了链表在地址上的链接指向,使每次的尾节点都指向新的结点
r=s 的功能实现了,让每次的新节点都作为新的尾节点
void BuildListTail(LinkList& L) {
LNode* s, * r = L;
int x;
scanf_s("%d", &x);
while (x != -1) {
s = (LNode*)malloc(sizeof(LNode));
s->data = x;
r->next = s;
r = s;
scanf_s("%d", &x);
}
r->next = NULL; //将尾节点指向空结点
}
5 链表的查找
LinkList 强调这是一个链表
LNode* 强调返回一个节点
实际上这两种方式完全等价
代码功能很简单,就是遍历输出
但是要注意边界问题以及空指针的问题,增强代码的健壮性
LNode* GetElem(LinkList L, int i) { //i是要找的第i个节点
int j = 1; //从第一个节点开始遍历
LNode* p = L->next;
if (i == 0) return L;
if (i < 0) {
printf("第%d个节点不存在\n",i); //说明i不合法
return NULL;
}
while (p != NULL && j < i) { //当i==j时跳出循环
p = p->next;
j++;
}
if(i==j) return p;
else {
printf("第%d个节点不存在\n", i);
return NULL;
}
}
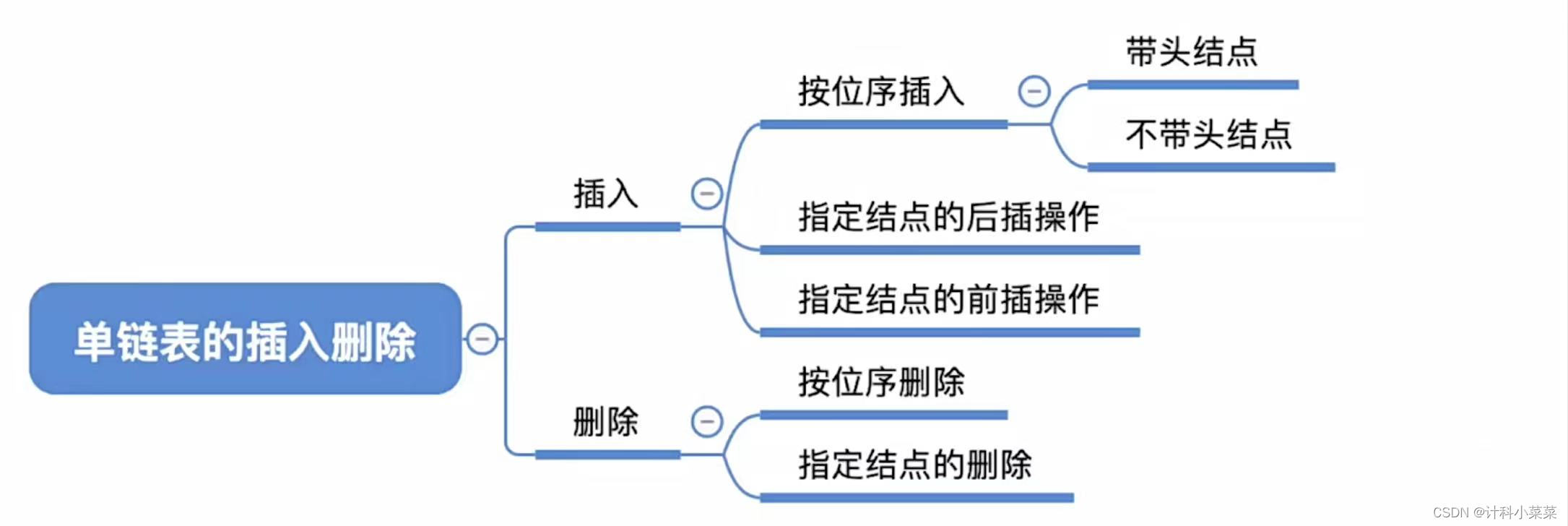
6 插入操作
1 按位序插入 带头结点
在第i个节点插入元素e
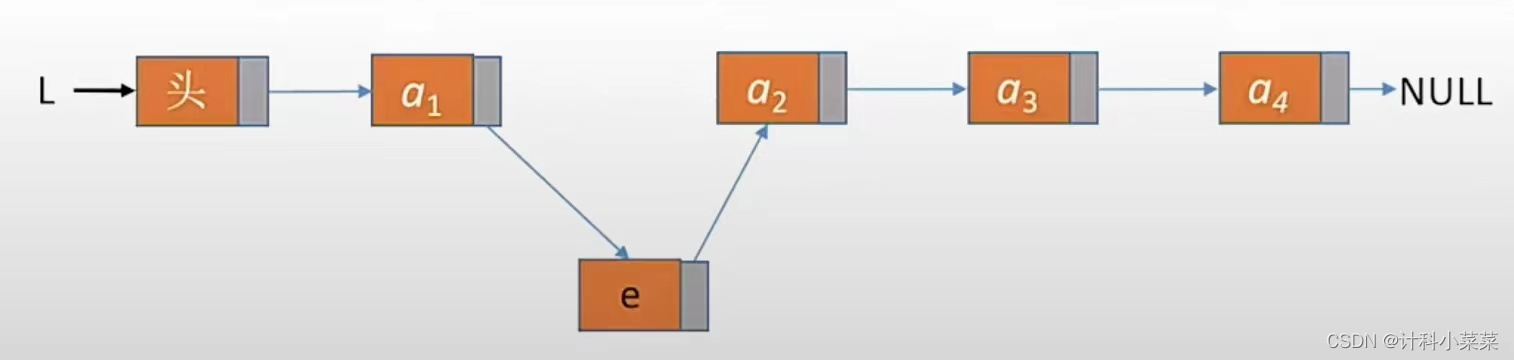
以图示为例,在第二个结点插入e
先遍历找到第i-1个结点,也就是第一个结点,先将e->next=a2,然后将i-1处的结点a1->next=e;,实现了链表的连接插入,注意这两步是不能颠倒顺序的
bool ListInsert(LinkList& L, int i, int e) {
if (i < 1) {
printf("插入位置不合法"); //增强代码的健壮性
return false;
}
//指针p指向当前扫描到的节点
LNode* p=L; // 现在指针p指向头结点,头结点是不保存数据的,即第0个节点
int j = 0; //j表示p指针当前指向的是第几个节点
while (p != NULL && j < i - 1) { //循环找到第i-1个节点
p = p->next;
j++;
}
if (p == NULL)
return false; //i不合法 //增强代码的健壮性
LNode* s = (LNode*)malloc(sizeof(LNode));
s->data = e;
s->next = p->next; //这两句不能颠倒顺序
p->next = s; //若是颠倒顺序,p->next还没有使用就被更新了
return true;
}
2 不带头结点的插入方法
他与带头结点的区别在于在第一个位置插入时需要更头结点
其他功能与带头结点的相同,为了节省代码量,这里不在展出,只展示核心代码
只展示有区别的在第一个节点位置的插入
bool ListInsert(LinkList& L, int i, int e) {
//在第一个位置插入e
if (i == 1) {
LNode* s = (LNode*)malloc(sizeof(LNode));
s->data = e;
s->next = L; //让s的next指向头指针
L = s; //然后将头指针改为s
//这样就实现了将s插入到第一个位置
return true;
}
}
7 指定结点的前插操作
你会发现,你是没办法找到给定节点的前驱节点
你可以选择从头结点挨个开始遍历,但是效率很低,而且若是不给头结点,则直接无法实现功能
所以,你可以采取下面的新方法
复制法 ----- 偷天换日大法
将给定结点的数据赋值给你新申请的节点,将要插入的节点复制给给定结点,实现数据错位的效果
即结点没有移动,但是结点内保存的数据发生了移动
bool InsertPriorNode(LNode* p, int e) {
if (p == NULL)
return false;
LNode* s = (LNode*)malloc(sizeof(LNode));
s->data = p->data;
s->next = p->next; //将p的所有信息复制给s
p->data = e;
p->next = s; //将要插入的节点复制给p
//俗称偷天换日大法
return true;
}
8 按位序删除(带头结点)
代码的逻辑与 6 插入操作很相似
bool DeleteList(LinkList& L, int i,int& e) {
if (i < 1) {
printf("删除的位置不合法"); //增强代码的健壮性
return false;
}
//指针p指向当前扫描到的节点
LNode* p = L; // 现在指针p指向头结点,头结点是不保存数据的,即第0个节点
int j = 0; //j表示p指针当前指向的是第几个节点
while (p != NULL && j < i - 1) { //循环找到第i-1个节点
p = p->next;
j++;
}
if (p == NULL||p->next==NULL)
return false; //增强代码的健壮性
LNode* q = p->next; //q结点创建的作用是为了能释放掉这一段内存空间
e = p->next->data; //用e可以记录下被删除的结点保存的值,不过我觉着这一步没什么用
p->next = p->next->next ;// 覆盖掉p->next达到实现删除的效果,虽然有点掩耳盗铃,但是效果有了
free(q);//释放掉没用的空间
return true;
}
9 删除给定结点
时间复杂度O(1)
思路同偷天换日大法
但是有如果要删除最后一个结点,这个代码是实现不了的,只能从表头开 始循环遍历
我们将给定节点的后继结点的信息复制给给定结点,然后释放掉后继节点,这样就实现了给定结点的删除
实际上是保护了后继结点的数据,覆盖了当前结点的信息,来达到实现删除的效果
如果是删除给定结点的后继,传参数的时候可以传给定结点的下一个结点,即传p->next
bool DeleteNode(LNode*p){
if (p == NULL||p->next)return false;
//如果p是最后一个结点,那么p->next==NULL ,p->next->next是不存在的
LNode* q = p->next; //q结点创建的作用是为了能释放掉这一段内存空间
p->data = p->next->data;
p->next = p->next->next;
free(q);
return true;
}
10 完整代码
#include<stdio.h>
#include<stdlib.h>
// 本博客不特殊指出,默认带头结点
// 1 定义一个结构体来实现单链表
// typedef 关键字的作用相当于起别名
typedef struct LNode {
int data; //单链表节点类型,即存放的数据类型
struct LNode* next; //指针指向下一个节点
}LNode,*LinkList;
//等价于
//struct LNode
//{
// int data;
// struct LNode* next;
//};
//typedef struct LNode LNode; LNode是struct LNode的别名
//typedef struct LNode* LinkLIst; LinkLIst 是struct LNode*的别名
//别名与本名功能一模一样,都可以用来定义变量,效果一样
//这里注意 Lnode* 与LinkList是等价的
// 2 链表的初始化
bool InitalList(LinkList& L){
L = (LNode*)malloc(sizeof(LNode));
if (L == NULL)return false; //内存不足,申请失败
L->next = NULL;//头结点之后还没有新的结点,所以传空
//会有人疑问为什么没有给头结点的data赋值
//因为头结点不参与保存数据,只是为了方便操作链表额外添加的虚拟头结点
return true;
}
// 3 头插法创建单链表
void BuildListHead(LinkList& L) {
LNode* s=L;
int x; //输入的值 规定当输入-1时结束创建
scanf_s("%d", &x);
while (x != -1) {
s = (LNode*)malloc(sizeof(LNode)); //为链表申请新空间
s->data = x;
s->next = L->next;
L->next = s;
scanf_s("%d", &x);
}
}
// 4 尾插法创建单链表
void BuildListTail(LinkList& L) {
LNode* s, * r = L;
int x;
scanf_s("%d", &x);
while (x != -1) {
s = (LNode*)malloc(sizeof(LNode));
s->data = x;
r->next = s;
r = s;
scanf_s("%d", &x);
}
r->next = NULL; //将尾节点指向空结点
}
// 5 链表的查找
// LinkList 强调这是一个链表
// LNode* 强调返回一个节点
// 实际上这两种方式完全等价
LNode* GetElem(LinkList L, int i) { //i是要找的第i个节点
int j = 1; //从第一个节点开始遍历
LNode* p = L->next;
if (i == 0) return L;
if (i < 0) {
printf("第%d个节点不存在\n",i); //说明i不合法
return NULL;
}
while (p != NULL && j < i) { //当i==j时跳出循环
p = p->next;
j++;
}
if(i==j) return p;
else {
printf("第%d个节点不存在\n", i);
return NULL;
}
}
// 6 插入操作 按位序插入 带头结点
// 在第i个节点插入元素e
bool ListInsert(LinkList& L, int i, int e) {
if (i < 1) {
printf("插入位置不合法"); //增强代码的健壮性
return false;
}
//指针p指向当前扫描到的节点
LNode* p=L; // 现在指针p指向头结点,头结点是不保存数据的,即第0个节点
int j = 0; //j表示p指针当前指向的是第几个节点
while (p != NULL && j < i - 1) { //循环找到第i-1个节点
p = p->next;
j++;
}
if (p == NULL)
return false; //i不合法 //增强代码的健壮性
LNode* s = (LNode*)malloc(sizeof(LNode));
s->data = e;
s->next = p->next; //这两句不能颠倒顺序
p->next = s; //若是颠倒顺序,p->next还没有使用就被更新了
return true;
}
// 这个是不带头结点的插入方法
// 他与带头结点的区别在于在第一个位置插入时需要更头结点
// 其他功能与带头结点的相同,为了节省代码量,这里不在展出,只展示核心代码
// bool ListInsert(LinkList& L, int i, int e) {
// //在第一个位置插入e
// if (i == 1) {
// LNode* s = (LNode*)malloc(sizeof(LNode));
// s->data = e;
//
// s->next = L; //让s的next指向头指针
// L = s; //然后将头指针改为s
// //这样就实现了将s插入到第一个位置
// return true;
// }
//
//}
// 7 指定结点的前插操作
// 你会发现,你是没办法找到给定节点的前驱节点
// 你可以选择从头结点挨个开始遍历,但是效率很低,而且若是不给头结点,则无法实现
// 所以,你可以采取下面的新方法
// 复制法 ----- 偷天换日大法
// 将给定结点的数据赋值给你新申请的节点,将要插入的节点复制给给定结点
bool InsertPriorNode(LNode* p, int e) {
if (p == NULL)
return false;
LNode* s = (LNode*)malloc(sizeof(LNode));
s->data = p->data;
s->next = p->next; //将p的所有信息复制给s
p->data = e;
p->next = s; //将要插入的节点复制给p
//俗称偷天换日大法
return true;
}
// 8 按位序删除(带头结点)
bool DeleteList(LinkList& L, int i,int& e) {
if (i < 1) {
printf("删除的位置不合法"); //增强代码的健壮性
return false;
}
//指针p指向当前扫描到的节点
LNode* p = L; // 现在指针p指向头结点,头结点是不保存数据的,即第0个节点
int j = 0; //j表示p指针当前指向的是第几个节点
while (p != NULL && j < i - 1) { //循环找到第i-1个节点
p = p->next;
j++;
}
if (p == NULL||p->next==NULL)
return false; //增强代码的健壮性
LNode* q = p->next; //q结点创建的作用是为了能释放掉这一段内存空间
e = p->next->data; //用e可以记录下被删除的结点保存的值,不过我觉着这一步没什么用
p->next = p->next->next ;// 覆盖掉p->next达到实现删除的效果,虽然有点掩耳盗铃,但是效果有了
free(q);//释放掉没用的空间
return true;
}
// 9 删除给定结点
// 思路同偷天换日大法
// 但是有如果要删除最后一个结点,这个代码是实现不了的,只能从表头开始循环遍历
// 我们将给定节点的后继结点的信息复制给给定结点,然后释放掉后继节点,这样就实现了给定结点的删除
// 如果是删除给定结点的后继,传参数的时候可以传给定结点的下一个结点,即传p->next
bool DeleteNode(LNode*p){
if (p == NULL||p->next)return false;
//如果p是最后一个结点,那么p->next==NULL ,p->next->next是不存在的
LNode* q = p->next; //q结点创建的作用是为了能释放掉这一段内存空间
p->data = p->next->data;
p->next = p->next->next;
free(q);
return true;
}
int main() {
LinkList L; // 1 声明一个指向单链表的指针
InitalList(L); // 2 初始化链表,为链表添加头结点(即第0个结点)
// BuildListHead(L); // 3 头插法创建单链表 本博客使用尾插法
BuildListTail(L); // 4 尾插法创建链表
// 注意1和3或者1和4可以合并在一起,方便新手学习理解,本博客分开处理
LinkList se=GetElem(L, 2); // 5 查找单链表元素
printf("查找到的数据为%d\n", se->data);
ListInsert(L, 2, 66); // 6 按位插入
InsertPriorNode(L->next->next, 99); // 7 指定节点的前插操作
int e;
DeleteList(L, 5, e); // 8 按位序删除(带头结点)
DeleteNode(L->next->next); // 9 删除给定结点
LinkList p = L->next; // 10 打印链表 没有再单独封装函数
while (p) {
printf("%d,", p->data);
p = p->next;
}
return 0;
}
//单链表的局限性,不能逆向检索
















 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











