






 本文讲述了作者在学习爬虫过程中遇到的挑战,主要涉及动态渲染网站的字体文件和数据文件获取,以及通过selenium模拟浏览器抓取,利用字体文件中的坐标信息进行数据解码的过程。
本文讲述了作者在学习爬虫过程中遇到的挑战,主要涉及动态渲染网站的字体文件和数据文件获取,以及通过selenium模拟浏览器抓取,利用字体文件中的坐标信息进行数据解码的过程。
前言
前些阵子学了些爬虫知识,如今见到什么都想爬一遍,这不最近听说猫眼票房数据有什么字体加密引起了我注意,为了弘扬爬虫知识(装b),请看我表演。
如今随着技术发展,反爬技术也是可怕地进步着。在爬取之前我也看了很多大佬写的文章,但或多或少都有些落后以至于无法使用,其中最主要的改变就是网站现在采用了动态渲染,我们无法使用requests库获取源代码了;其二便是字体文件和数据文件获取后,我们该如何翻译(p.j.),这两个问题便是今天的主题。接下来,我会逐步分析这两步如何进行,完整代码请参照我的GitHub库:
https://github.com/Rasrea/python-spider
永远的神:selenium
对于学爬虫的xdm来说selenium多么好用,我就不多说了(模拟浏览器,IP被封大大降低)。使用之前除了pip一下,还要下载一个chromedriver,这里我一般使用chrome浏览器,如果想用edge浏览器的话可以下载相应的driver,!!!但记住必须与你的浏览器版本匹配,不然会报错的(想当初我一度怀疑电脑坏了)。这里是目前最新的chromedriver链接:Chrome for Testing availability,至于路径之类的问题,其他大佬的讲解都很详细(懒得写了),准备工作完成,下面开始秀操作。
打开网站猫眼专业版(猫眼专业版-实时票房),查看网站源代码。font标签对应的就是字体文件的位置。

这个时候可能有人会说,标签位置都知道了,只要用Beautiful Soup搜一下不就得了。只能说,你太小瞧人家了。这个网站实际上是所谓的Ajax渲染的,我们请求不到完整源代码,这个时候就要看哪个人有本事,能把这个你看得见却摸不着的玩意儿,搞下来。我选择让浏览器自己帮我下载,为什么这么说,请看官进入Network页面,点击Front类别,可以看到这些都是字体文件,而且每2秒还会更新一个新的字体文件,对应的数据文件也会跟着更新。
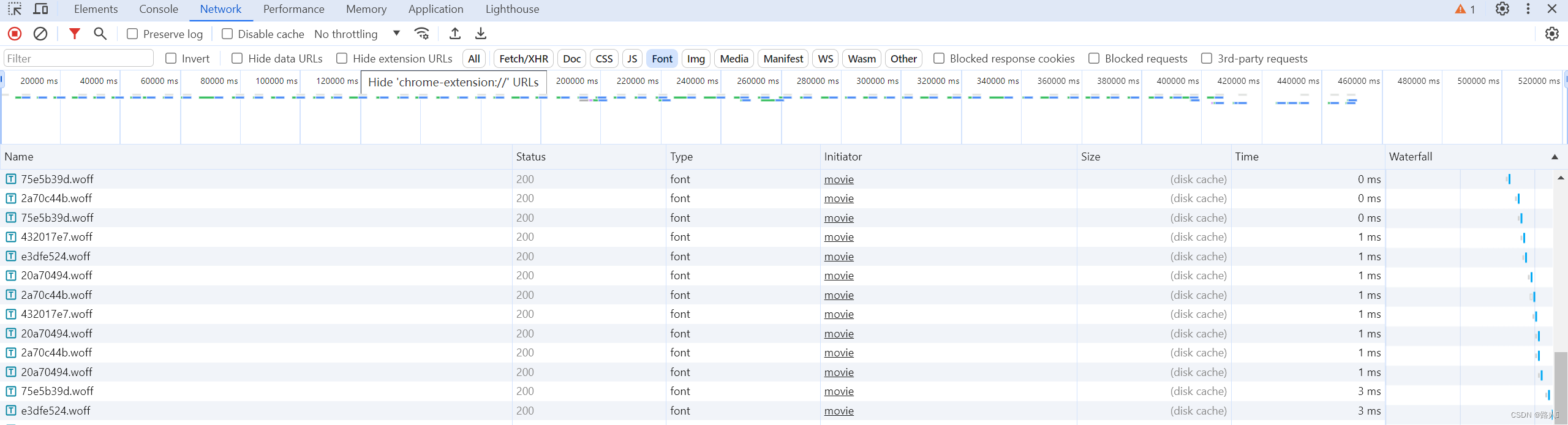
从刚才这个图中我们可以把这些字体文件下载(惊喜吧,可以下载),也就是说我们虽然不能从源代码中下载,但我们可以从浏览器中下载。OK,思路来了,我们可以让浏览器请求这些字体文件,因为是实时更新,所以我们请求最新的woff文件(字体文件的后缀)并保存起来就行了。上代码(自己就看完整代码吧),同理可以下载最新的数据文件(xhr类型)。如此这般,第一个问题解决,接下来就是重头戏,翻译(p.j.)。
是6还是9
这个标题刚开始可能会有人不明白,但这个问题一度困扰了我很久。话接上回,我们拿到了woff文件,双击打开,打开的话说明你电脑很nb,因此我们要把它转化成电脑能打开的格式才能直接打开,上代码:
# 转换成xml格式,便于破解
font = TTFont(font_filename)
font.saveXML(font_filename + '.xml')
xml_file = font_filename + '.xml'
print("字体文件格式转换完成!\n")这里我们转化成xml格式,其中font_filename是woff文件地址,OK双击打开(打不开?很好,说明你电脑有虫子)。在此之前各位先看看数据文件吧
看到num后面那两串乱码没,分别对应综合票房和分账票房的数据,经过对比我们会发现,每一个分号前的字符串都对应一个数字,所以我们只要找到对应关系就行了,就像如果=5,=2,=1,那么它们合起来就是521。照着这个思路我们来打开新的字体文件吧。映入眼帘的就是每个字符串所对应的信息,其中uniE132=2,uniE83D=3(这里有个误区,网站上还是&#x开头,怎么现在变成uni开头的了,其实这也是一种格式,你把这些uni都换成&#x你会发现只是头变了,后面4个字符没变).......
真的这么简单,我早就写省略号了(嘻嘻)。再往下滑,看到uniE132对应很多x和y有关的数据,仔细想一想,初中的时候一见到这么多x,y,最先想到什么,没错,是坐标。嗯嗯,也算一个思路,让我们试试,上代码
import re
import matplotlib.pyplot as plt
# 打开XML文件并以文本格式输出
with open('2a70c44b.woff.xml', 'r') as file:
xml_text = file.read()
# 找出XML文件中的加密信息
pattern = re.compile(r'<TTGl.*?name="(uni.*?)".*?xMin=.*?>(.*?)</TTGlyph>', re.S)
image = re.findall(pattern, xml_text)
# 循环遍历每个加密信息
for item in image:
# 0 对应加密内容,1 对应解密内容
print(item[0])
x = [int(i) for i in re.findall(r'<pt x="(.*?)" y=', item[1])]
y = [int(i) for i in re.findall(r'y="(.*?)" on=', item[1])]
# 创建新的图像对象
plt.figure()
plt.plot(x, y)
plt.fill(x, y, color='black') # 填充图形的内部
# 关闭当前图像对象,以便下一次循环时创建新的图像对象
plt.show()
plt.close()
我们以2a70c44b.woff.xml字体文件为例,提取每一个字符串所对应的x,y坐标然后画图,最终可以得到这些结果。

看到没有,除了第一个之外,每一个字符串对应一个数字,印证了我们的猜想。接下来就是把他们对应起来就好了,那么新的问题来了,如何让电脑识别图中的数字呢,电脑终究不是人,人学过123,电脑可不知道123怎么写的。现在又到了我们发挥想象的时候了,我能不能深度学习训练一个模型呢?而且还有一个现成的OCR技术识别软件(tesseract)。首先这两种方法都可行,但又都有点不可行,因为麻烦,这两种方法使用之前,你都需要先训练它们,不然还是识别不出来,那么还有其他方法吗?当然,要不然我还怎么传播爬虫精神(装b)。
打开字体对应的xml文件,仔细分析一下这些坐标点有什么规律,xdm可要看仔细了。好像也没规律啊,不行,还是放弃吧,专业版不适合我,再上网找找,嗯嗯,怎么还有个普通版猫眼啊!!什么这个票房数据怎么没加密,very good,虽然没专业版的电影多但好歹可以凑合着看嘛,完结散花。
实不相瞒之前翻译的时候我也有点想放弃,算了不灌鸡汤了,步入正题。分析一个大问题的时候我们不妨先把它拆解成几个小问题,就比如这些数字对应的坐标点都在<contour>标签中,有1对的,2对的,最多3对,其中我们遍历每一种字体文件,会发现只有数字8有三对<contour>,OK,数字8翻译成功,然后是一对的分别对应数字:7,3,5,2,1;两对的:0,9,6,4。完美我们成功地把他们分成了三份,第一份只有8,也就是说8被翻译了,然后就是分析剩下两份。
不知道在座的各位看过我画画没有(应该都没有),数字1一笔下去就结束了,数字7还要再加一横,数字7真的好废颜料啊。。。对对对!就是颜料的问题,数字1比7用的颜料少,也就是说坐标点比7少,而每一行对应一对坐标。哇塞!思路又来了,我们只要找到每个数字对应多少行,再排个序没准儿就把剩下两组数据翻译了,说干就干,走你。代码我就不多写了,比较简单,将这些字体文件都遍历一遍,发现一对的行数大小分别都是数字3>2>5>7>1,漂亮!一下子又破解五个,然后是两对的:9>6>0>4,6>9>0>4,what?怎么有两种?原来6倒着写就是9??好吧,6和9我们要单独来研究一下了。
我们还用刚才的画图代码重新把6和9再画一遍,这回带上坐标值,如图:
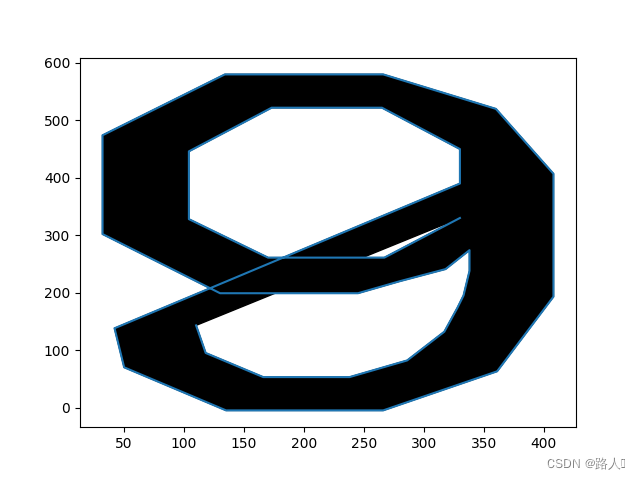
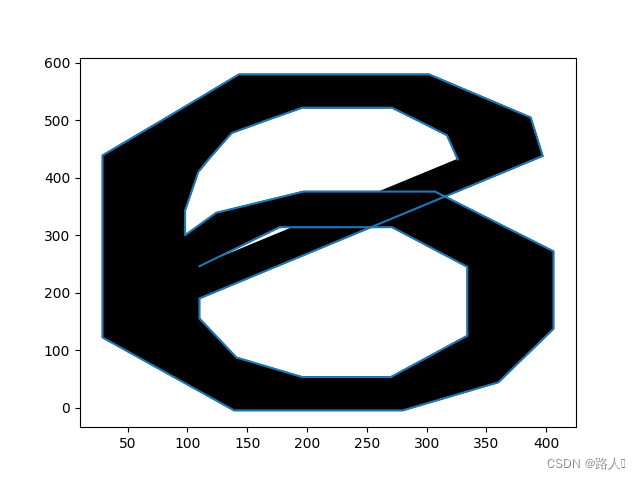
从这两个图中我们可以发现,你倒着看6其实就是9,真是。。。像。但是怎么能阻止我弘扬爬虫精神(装b)呢?仔细看还是会发现它们的坐标系是一样的,而且我们在画的时候,6的小肚子是在下面的,9的小肚子是在上面的,而两对<contour>中的第二对就是来画肚子的。完美!只要比较小肚子的y坐标之和就行了,大的就是9,小的就是6。上代码,完整翻译代码如下:
import re
import matplotlib.pyplot as plt
# 打开XML文件并以文本格式输出
with open("e3dfe524.woff.xml", 'r') as file:
xml_text = file.read()
# 找出XML文件中的加密信息
pattern = re.compile(r'<TTGl.*?name="(uni.*?)".*?xMin=.*?>(.*?)</TTGlyph>', re.S)
image_text = re.findall(pattern, xml_text)
# 将加密信息按字符'contour'个数分类
two_count = []
one_count = []
key_thr = {} # 以字典的形式存储破解信息
# 循环遍历每个加密信息
for i, str_text in enumerate(image_text):
count_text = re.findall(r'<contour>', str_text[1])
# 分别存放在各自的列表中
if len(count_text) == 3:
key_thr[str_text[0]] = 8
elif len(count_text) == 2:
two_count.append(str_text)
else:
if i == len(image_text): # 排除最后一个
break
else:
one_count.append(str_text)
# 根据图像数据的行数进一步区分列表中的值
line_dict = {}
list_two = [9, 6, 0, 4]
for data in two_count:
line_count = data[1].count('\n') + 1
line_dict[data[0]] = line_count
# 使用sorted函数对字典的键值对进行排序,根据值进行排序,reverse参数设置为True表示降序
key_two = dict(sorted(line_dict.items(), key=lambda item: item[1], reverse=True))
# 使用循环遍历使解码结果分别对应
for key, value in zip(key_two.keys(), list_two):
key_two[key] = value
# 区分数字9和6,比较第二部分y坐标的大小
# 获取字典的键列表
keys = list(key_two.keys())
nin_text = ''
six_text = ''
for text in image_text:
if text[0] == keys[0]:
nin_text = text
if text[0] == keys[1]:
six_text = text
# 获得数字9第二部分y坐标值和
sec_nin_text = re.search('</cont.*?tour>(.*?)</contour>', nin_text[1], re.S).group(1)
nin_y = [int(i) for i in re.findall(r'y="(.*?)" on=', sec_nin_text)]
# 同理得数字6
sec_six_text = re.search('</cont.*?tour>(.*?)</contour>', six_text[1], re.S).group(1)
six_y = [int(i) for i in re.findall(r'y="(.*?)" on=', sec_six_text)]
# 比较第二部分y坐标的值
if sum(nin_y) < sum(six_y):
# 9, 6需要调换
keys = list(key_two.keys())[:2] # 获取字典中的前两个键
key_two[keys[0]], key_two[keys[1]] = 6, 9
# 同理破译
line_dict = {}
list_one = [3, 2, 5, 7, 1]
for data in one_count:
line_count = data[1].count('\n') + 1
line_dict[data[0]] = line_count
key_one = dict(sorted(line_dict.items(), key=lambda item: item[1], reverse=True))
for key, value in zip(key_one.keys(), list_one):
key_one[key] = value
# 合并成解码字典
key_dict = {**key_thr, **key_two, **key_one}
for key, value in key_dict.items():
print(f'{key}: {value}')
如此这般,所有的数都翻译完了,组合成一个字典,到时候和数据文件一一对照就行了,这是结果图,导入了csv文件中:

总结
真快的!我可算唠叨完了,各位看懂了吗?没看懂也没问题只要拨打号码1314521,本人就会飞奔到你身边帮助你。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









