






文章目录
主要内容
尝试使用不同的方式运行wordcount程序。
1)windows的Eclipse中运行wordcount处理本地文件或完全分布式文件
2)将上面的程序打包在linux中运行,注意处理的文件式完全分布式文件
3)将上面的打包程序在windows的cmd中运行
4)在windows的Eclipse中使用伪分布或分布式运算完成wordcount程序
1.左方工作区右键New,选择Map文件
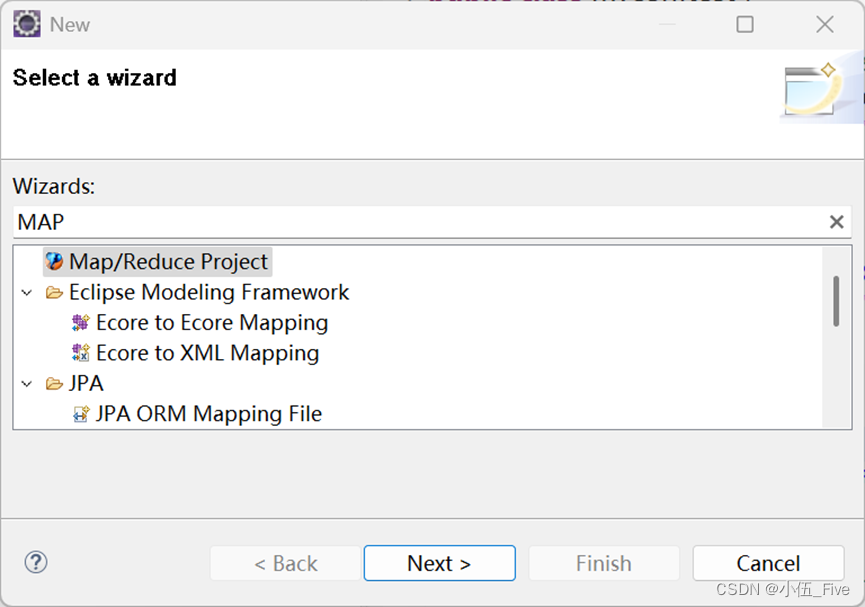
定义项目名称:
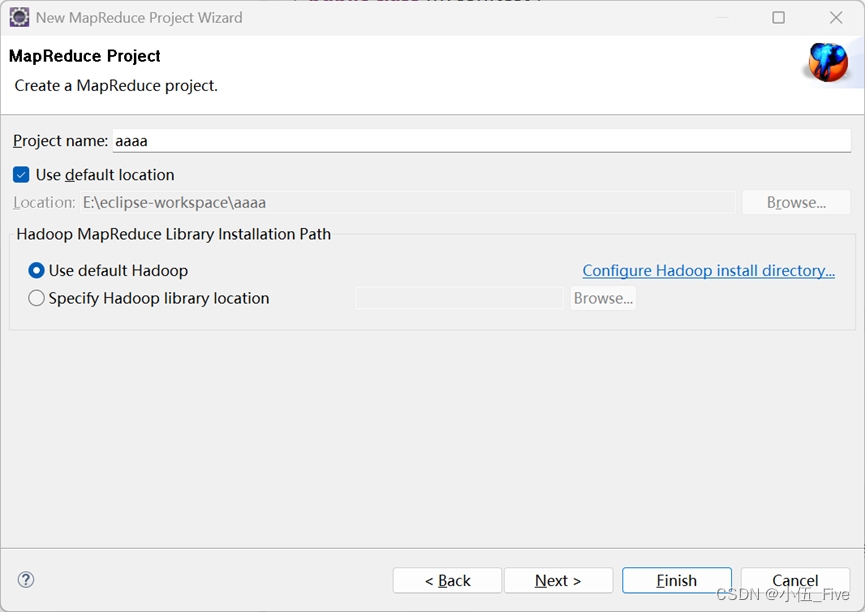
创建包:
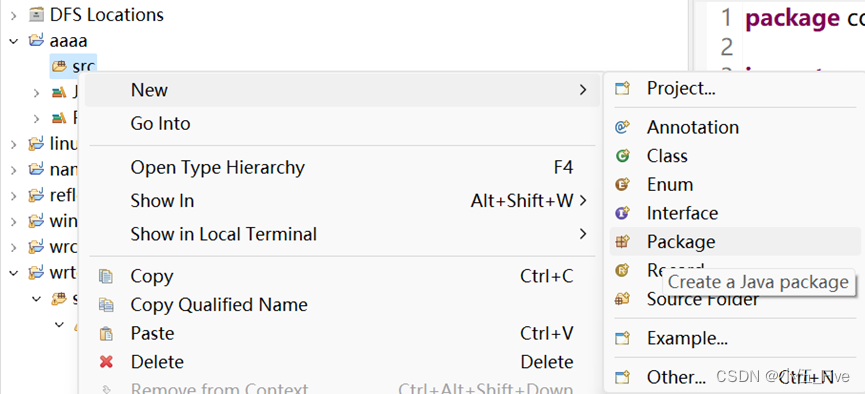
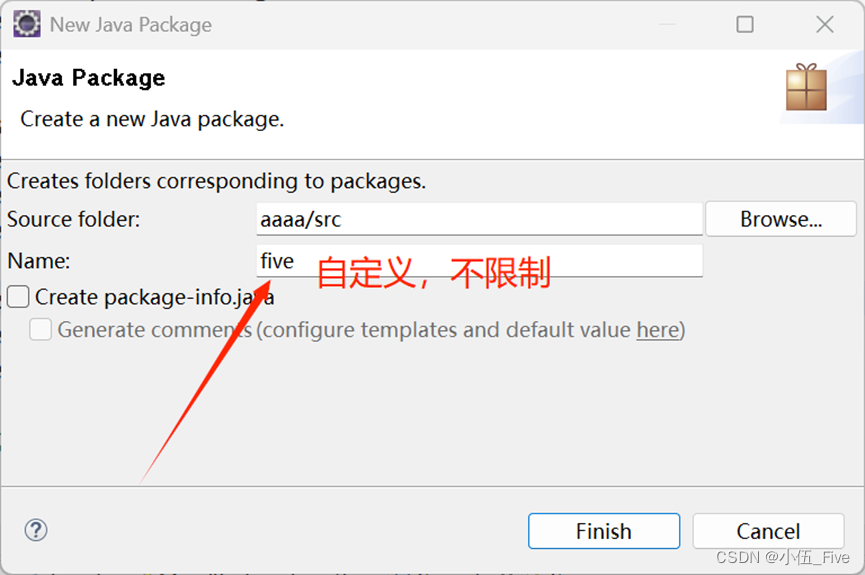
2.再创建mymap,myreducer,mywordcount类:
mymap类代码:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class mymap extends Mapper<LongWritable, Text,Text, IntWritable> { //Mapper类的四个泛型参数分别代表输入键、输入值、输出键和输出值的类型
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //输入键是LongWritable(长整型),输入值是Text(文本),输出键是Text,输出值是IntWritable(整型)
String aline= value.toString(); //将输入值(一行文本)转换成字符串
String[] words = aline.split(" "); //使用空格将字符串分割成单词数组
for (String w:words ) { //for-each循环,遍历数组中的每个单词
context.write(new Text(w),new IntWritable(1)); //在循环体内,每个单词被写入上下文(Context)中,作为输出键值对。输出键是单词本身(new Text(w)),输出值是整数1(new IntWritable(1)),表示这个单词出现了一次
}
}
}
myreducer类代码:
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class myreducer extends Reducer<Text, IntWritable, Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//它覆盖了父类Reducer的reduce方法。reduce方法负责处理每个键和与之关联的值的集合
Iterator<IntWritable> iterator = values.iterator();//获取values的迭代器,用于遍历所有的值
int sum=0;//初始化一个整数sum,用于累加单词出现的次数
while(iterator.hasNext()){//遍历迭代器中的每个元素
IntWritable i= iterator.next();//: 获取迭代器中的下一个IntWritable对象
sum+=i.get();//将IntWritable对象的值加到sum上
}
context.write(key,new IntWritable(sum));//将累加的结果和对应的键写入上下文(Context)中,作为输出键值对
//读取映射阶段输出的键值对,将具有相同键(单词)的值(出现次数)进行累加,最后输出每个单词的总出现次数
}
}
mywordcount类代码:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class mywordcount {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration(); //创建一个Hadoop作业配置对象
conf.set("fs.defaultFS", "hdfs://192.168.222.171:9000");//设置文件系统的默认类型为HDFS,并指定NameNode的地址
//根据不同运行要求设置相关属性
//tips1:独立模式无需配置属性,文件可以是本地或分布式
//tips2:在linux或cmd中用hadoop jar也不用配置属性,文件式伪分布式或完全分布式
//tips3:直接在idea中或Eclipse中运行,且是伪分布式模式需要配置fs.defaulstFS yarnhost //mapreduce框架等3个属性,详见ppt
//tip4:直接在idea中或Eclipse中运行,且是完全分布式计算,即windows跨平台提交//wordcount 需要设置跨平台提交参数为true,设置并启动historyserver服务,详见ppt
//tips5:遇到访问权限问题,在程序中添加System.setProperty("HADOOP_USER_NAME","root");
Job job=Job.getInstance(conf);// 根据配置创建一个新的作业实例
job.setMapperClass(mymap.class);//设置作业的Mapper类为mymap
job.setReducerClass(myreducer.class);//设置作业的Reducer类为myreducer
job.setMapOutputValueClass(IntWritable.class);//设置Mapper输出值的类型为IntWritable
job.setMapOutputKeyClass(Text.class);//设置Mapper输出键的类型为Text
job.setOutputKeyClass(Text.class);//设置作业最终输出键的类型为Text
job.setOutputValueClass(IntWritable.class);//设置作业最终输出值的类型为IntWritable
// job.setJar("d:/myhdfswordcount.jar");//在idea或Eclipse直接运行用 作业的jar包路径设置
job.setJarByClass(mywordcount.class);//独立模式或hadoop jar运行时用 指定作业的jar包,通过作业的主类来查找
FileInputFormat.setInputPaths(job,new Path("/myinput.txt"));//注意不同模式下文件 设置作业的输入路径
FileOutputFormat.setOutputPath(job,new Path ("/output"));//输出路径
boolean b = job.waitForCompletion(true); //提交作业并等待执行完成,返回值表示作业是否成功执行
if (b)
System.out.println("success!");
}
}
以上代码缺一不可
3.打包在linux中运行,注意处理的文件式完全分布式文件
虚拟机打开,启动hadoop,
关防火墙
systemctl stop firewalld
退出安全模式:
hadoop dfsadmin -safemode leave
保证正常连接
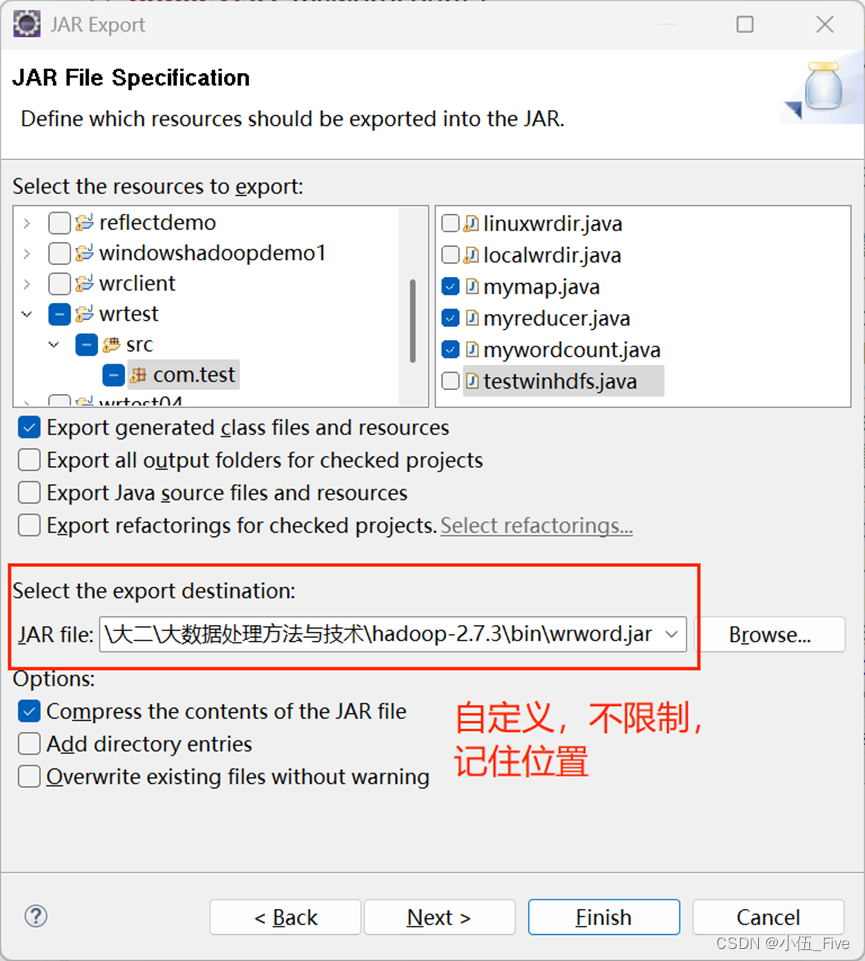
3.1打jar包步骤:
1.右键src,点export
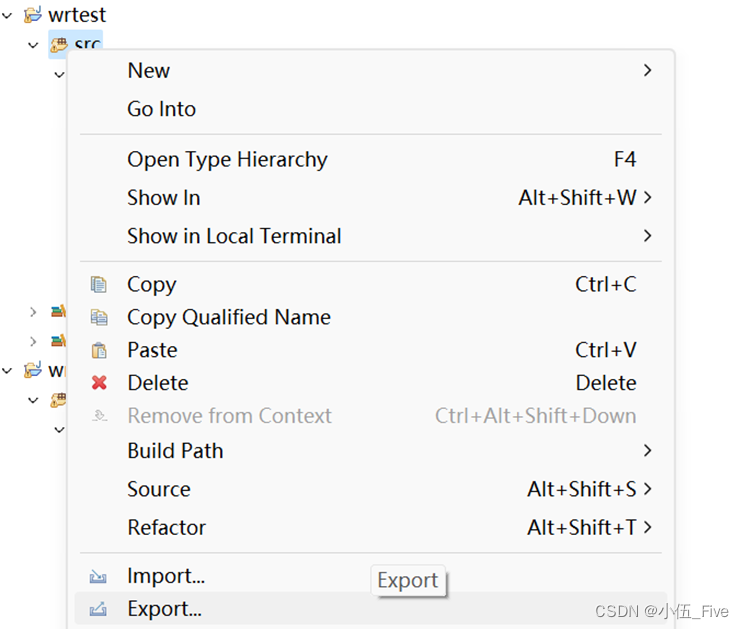
选择JAR File:
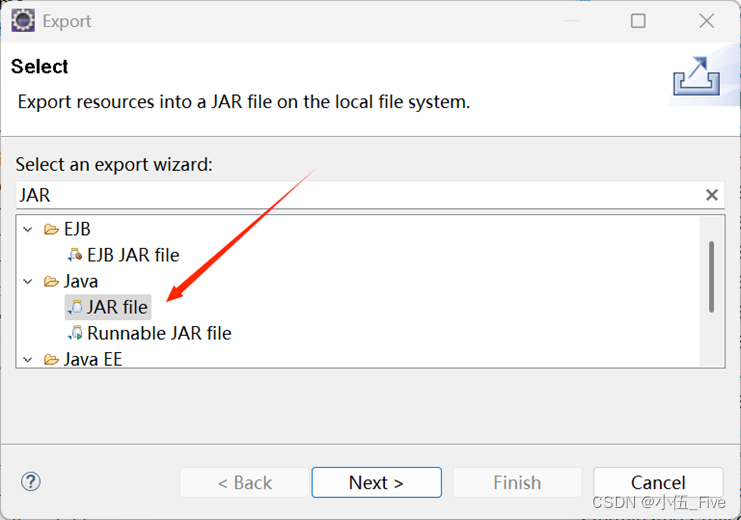
都点上:
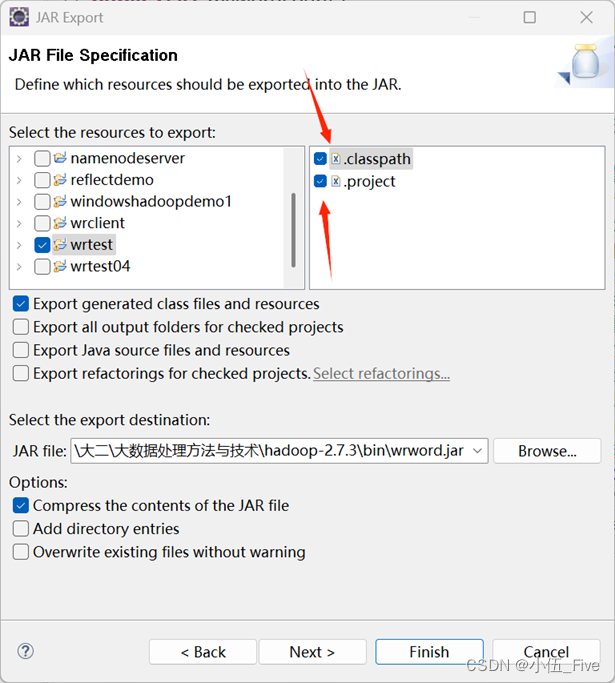
勾选三个类即可:
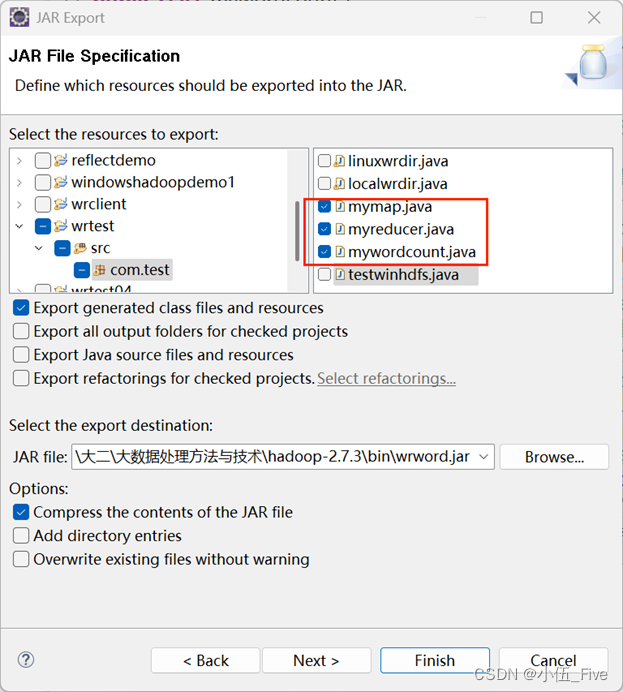
找到jar包,上传到虚拟机指定位置(无限制):【黄色小标就是上传按钮】
之后上传统计文字的txt文件到hdfs中!(put方法)或者eclipse里面连接的DFS直接上传文件【选择一种方式即可】
Hadoop fs -put /myinput.txt /
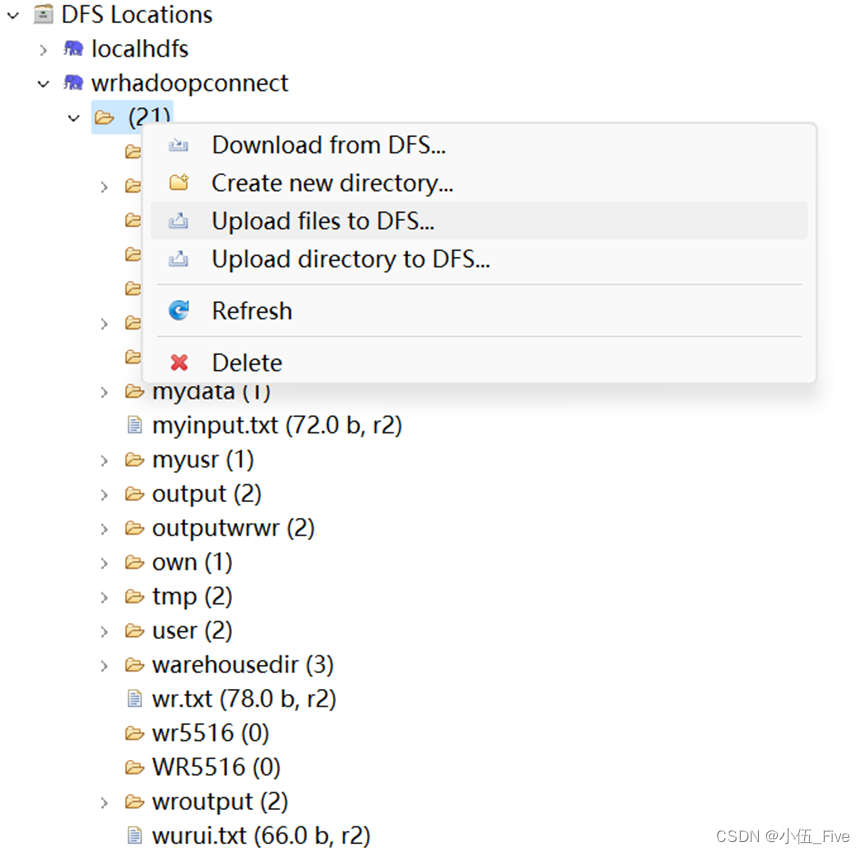
输出文件名必须是hdfs里面不存在的!
然后,到上传jar包的指定位置:

使用命令:
Hadoop jar jar包名 包名.类名
我的就是:Hadoop jar wrword.jar five.mywordcount
伪分布式是相同思想(类比虚拟机)
仅修改mywordcount文件代码
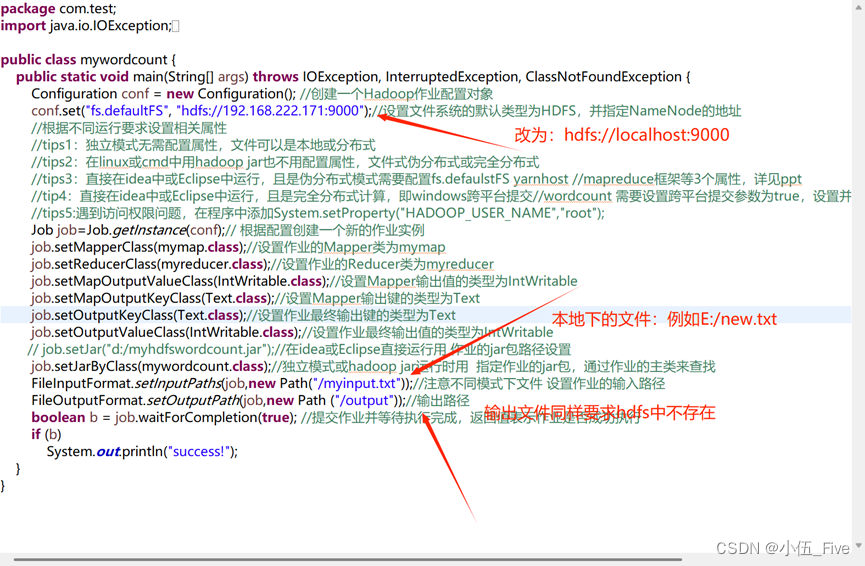
在cmd运行命令:
Hadoop.cmd jar jar包名 包名.类名
我的就是:Hadoop.cmd jar wrword.jar five.mywordcount
4.完成内容
结束!
















 309
309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











