







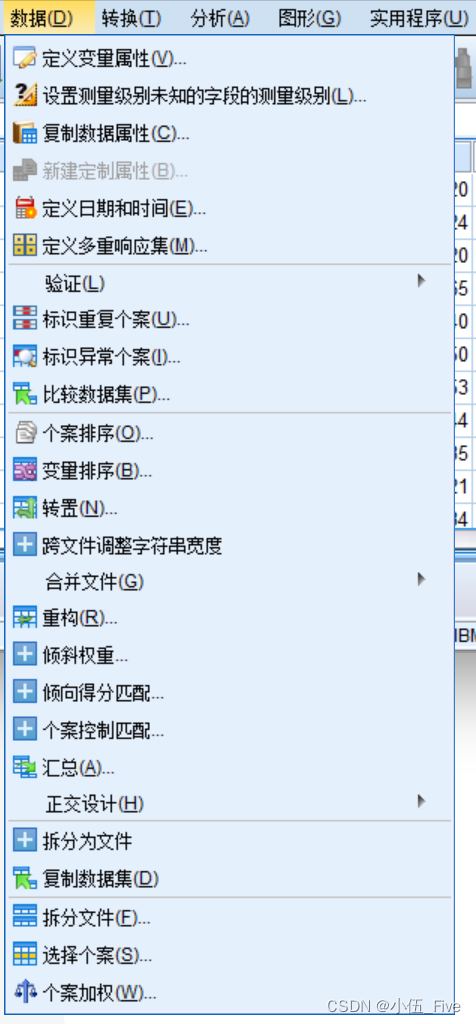
一、文件级别的数据管理
数据编辑窗口的"数据“菜单为用户创建和定义数据提供了方便的功能。
它的功能包括:对变量、观测量的编辑处理;对变量数据的变换;对观察量数据整理。
(1)简单命令:包括插入变量、插入记录和到达某条记录,他们的功能实际上都可以用鼠标在数据表界面上直接完成,很少会使用菜单来调用。
(2)常用的简单过程:包括排序、拆分文件、选择记录和加权记录。
(3)变量与数据文件属性导向:用于定义数据字典,或者将于定义的数据字典直接引入当前数据文件。
(4)数组重组向导:用于进行数据转置,或者对重复测量数据表进行长型、宽型记录间的转换。 (5)文件合并过程:将几个数据文件合并为一个大的spss数据文件,含横向合并和纵向合并两种情况。
(6)正交设计过程:实际上是联合分析模块的一部分,用于生成实施联合分析所需要的设计。 (7)其他过程:包括定义日期变量过程、数据汇总过程和查找重复记录导向。
1、记录排序
一、排序的两种方法:
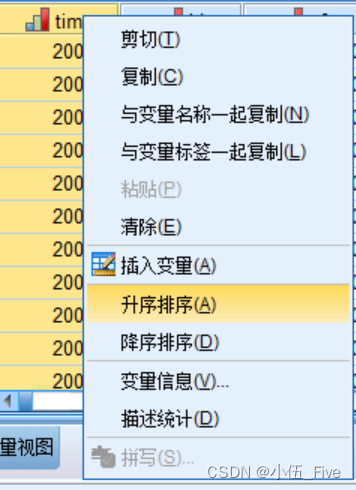
(1)对于单变量排序,在数据表格的变量名处单击右键,弹出的右键菜单最后两项就是“升序”和“降序”。
(2)对于多变量排序,则需要使用个案排序过程来进行。
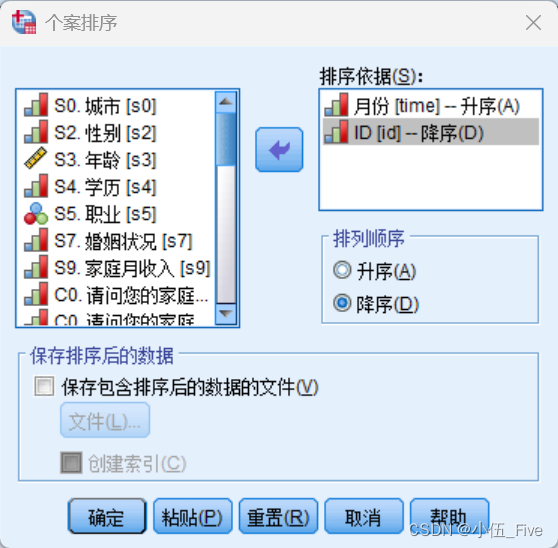
二、多变量排序需要注意的三点:
(1)在多重排序中,制定排序变量名是很关键的,先指定的变量在排序时必然优先于后制订的变量。
(2)可以指定按某变量值升序排序的同时按另一变量值降序排序,或相反。
(3)排序以后,原来记录数据的排列次序将被打乱。
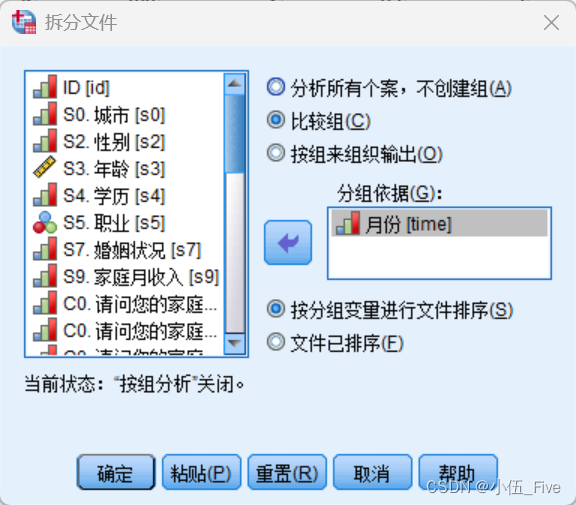
2、记录拆分
“数据”-->”拆分文件“:把当前工作分割成两个或两个以上的组,随后的分析将对每个组进行。
3、记录筛选
按要求分析其中的一部分,这时就可以使用“选择个案”对话框来操作。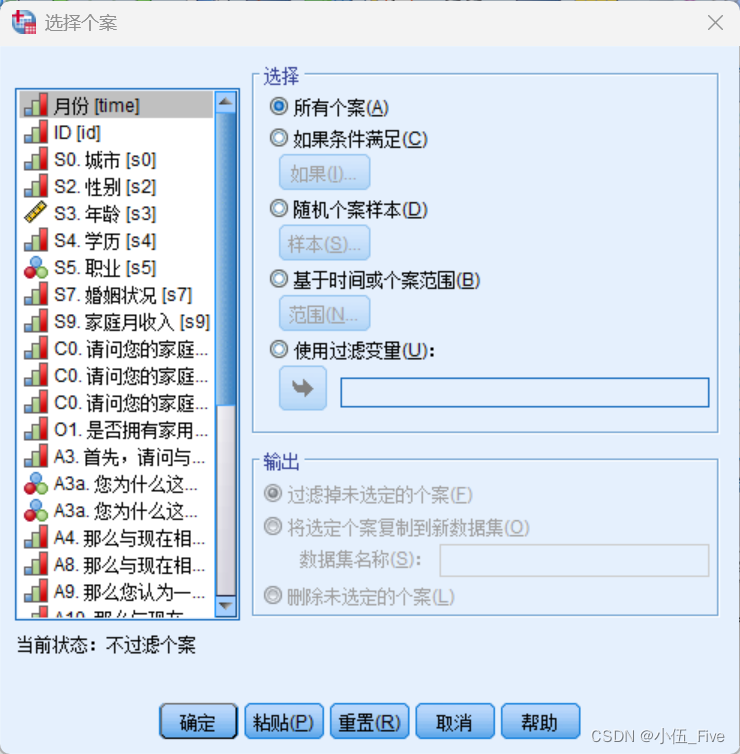
(1)如果条件满足:此时将只分析满足所指定条件的记录,单击下方的“如果”按钮会打开“如果”对话框,用于定义筛选条件,该对话框几乎和图3.2所示的变量赋值过程对话框完全相同,因此不再重复解释。
(2)随机个案样本:从原数据中按某种条件抽样,使用下方的“样本”按钮进行具体设定,可以按百分比抽取记录,或者精确设定从前若干个记录中抽取多少条记录。
(3)基于时间或个案全距:基于时间或记录序号来选择记录,使用下方的“范围”按钮设定记录序号范围。
(4)使用筛选器变量:此时需要在下面选入一个筛选指示变量,该变量取值为非0的记录将被选中,进行之后的分析。
“输出”单选按钮组则用于选择对没有选中的记录的处理方式,可以选择以下可选项之一来处理未选定个案。
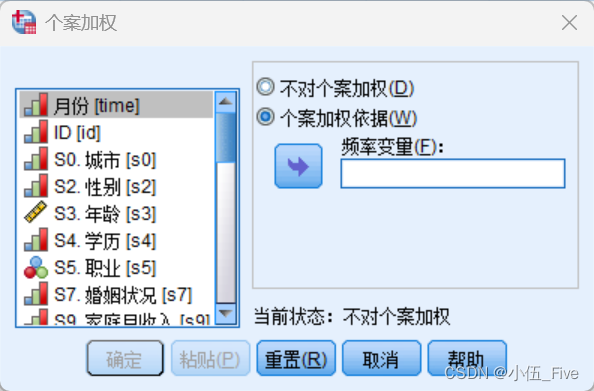
4、加权记录
针对如下两种情形:
5、数据汇总
所谓分类汇总就是按指定的分类变量对观测值进行分组,对每组记录的各变量求指定的描述统计量,结果可以存入新数据文件,也可以替换当前数据文件
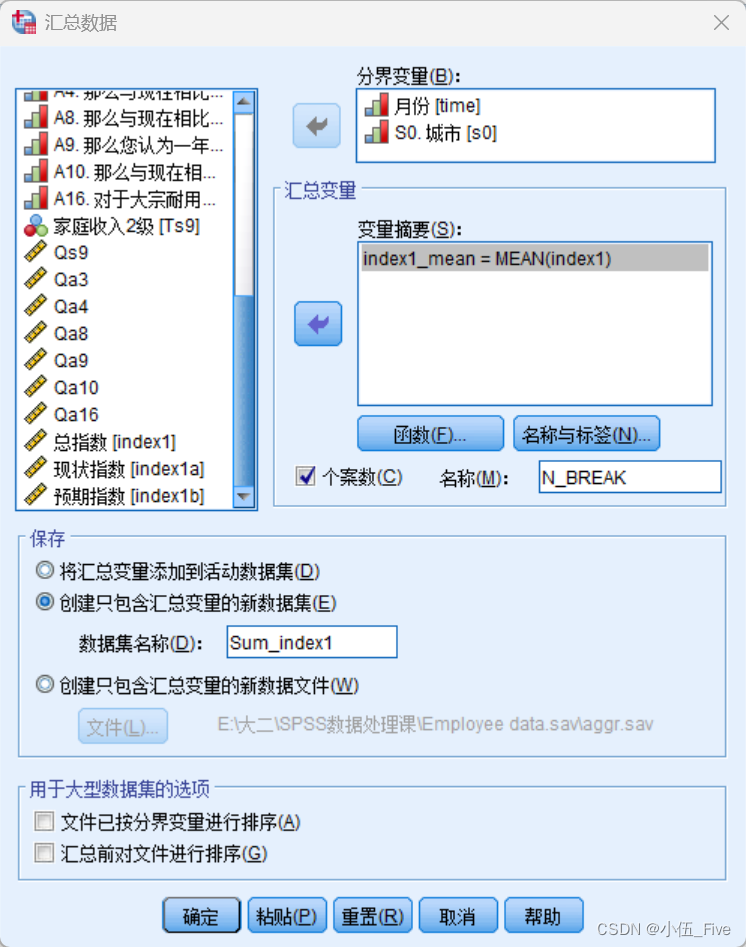
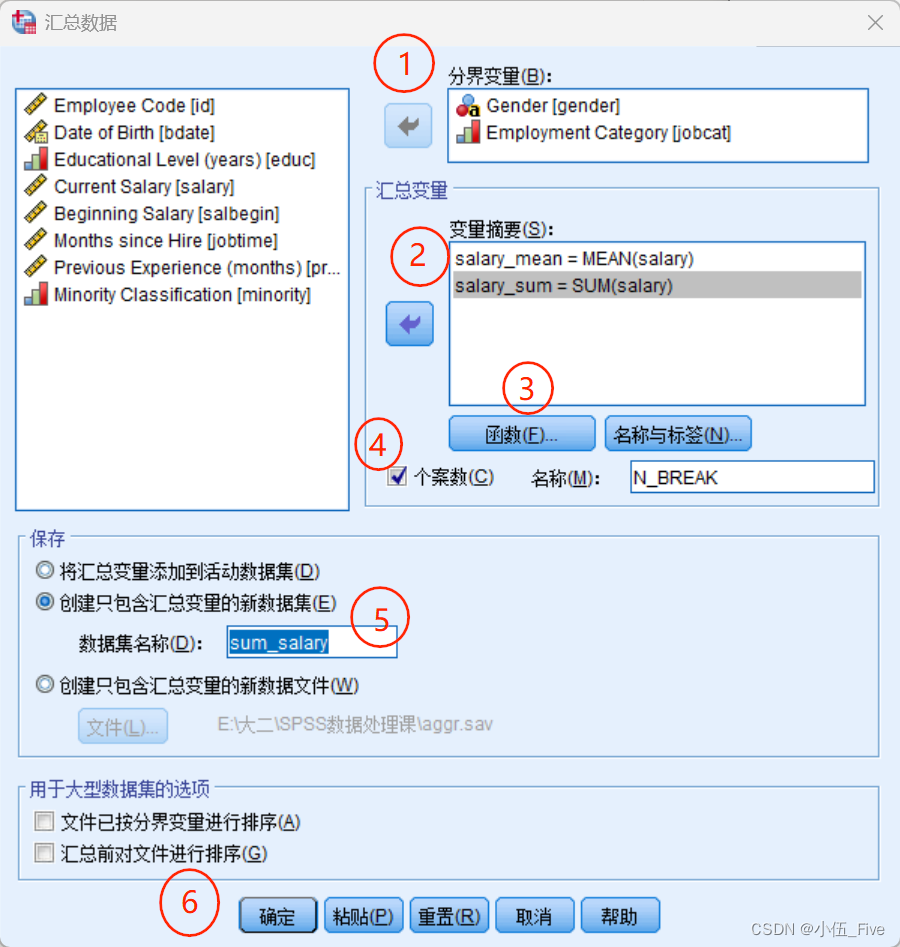
(1)“分组变量”列表框:用于选择分组变量,可以有多个。
(2)“变量摘要”列表框:用于选择被汇总的变量,可以有多个,包括对同一个变量的多种不
同汇总方式。
(3)“函数”按钮:单击该按钮会打开定义汇总函数的对话框,此处共提供了5组函数,分别
为“摘要统计量”、“特定值”、“个案数”、“百分比”和“分数”(Fraction)。以最常用的第一组为
例,可选的函数有“均值”、“中值”、“总和”、“标准差”4种。SSS默认对各类记录分别计算汇总
变量的均值。
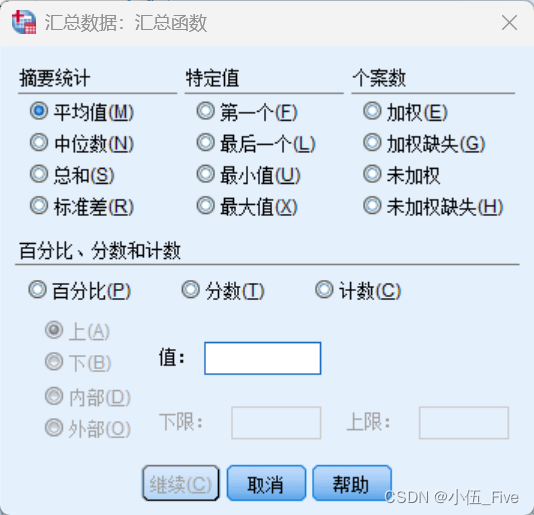
(4)“变量名与标签”按钮:单击该按钮打开的对话框用于定义新产生的汇总变量的名称和
标签。
(5)“个案数”复选框:用于定义一个新变量以存储同组的个案数。
(6)“保存”框组:设定汇总结果的具体输出方式,可以将汇总后的结果直接加入当前数据
文件中,也可以定义一个新文件以存储汇总的结果,或者用汇总的结果替换原来的数据。
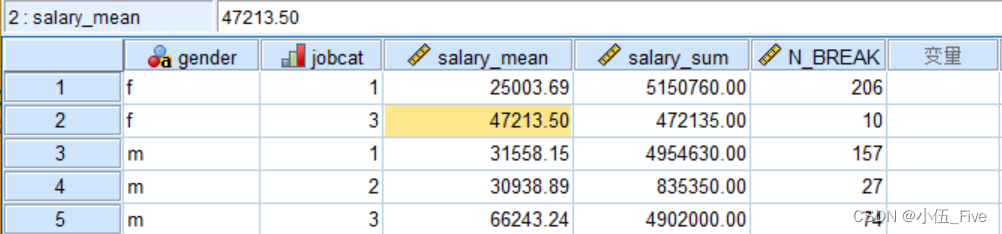
举个栗子:

6、与数据字典相关的功能
1)定义变量属性

2)复制数据属性
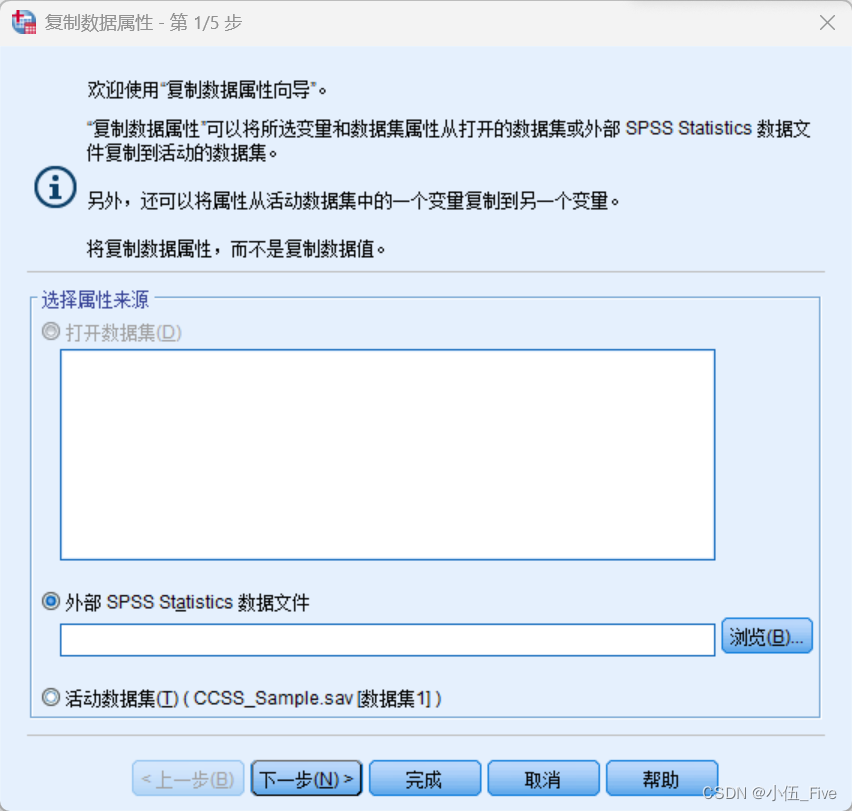
选择“数据”→“复制变量属性”菜单项,则首先会打开“复制数据属性”对话框
操作时不仅可以将一个外部数据文件相关属性拷贝到当前数据文件中,还可以进行自行定义,只选择某些变量,或者某些属性进行拷贝,这无疑大大提高了连续性项目对原有资源的利用程度。
7、查找重复记录
标识重复个案的相应功能被整合到一个对话框中实现,只需通过简单的菜单操作,用户就可以迅速地发现个别变量值重复,或者所有数值完全重复的记录。
举栗子:

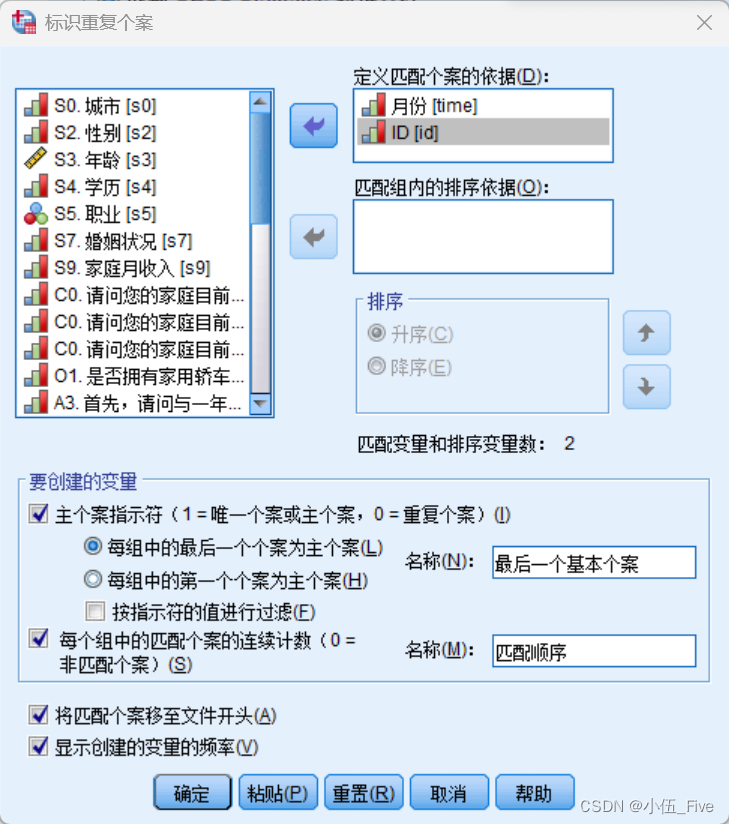
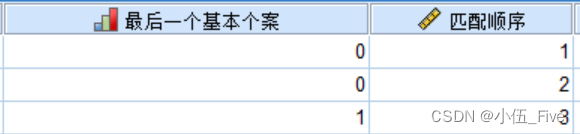
操作完毕后,可见变量“最后一个基本个案”等于0表示相应的记录为重复记录,本例中共发现2条,它们均与第3条个案记录重复,这正是前面所设定的情形。
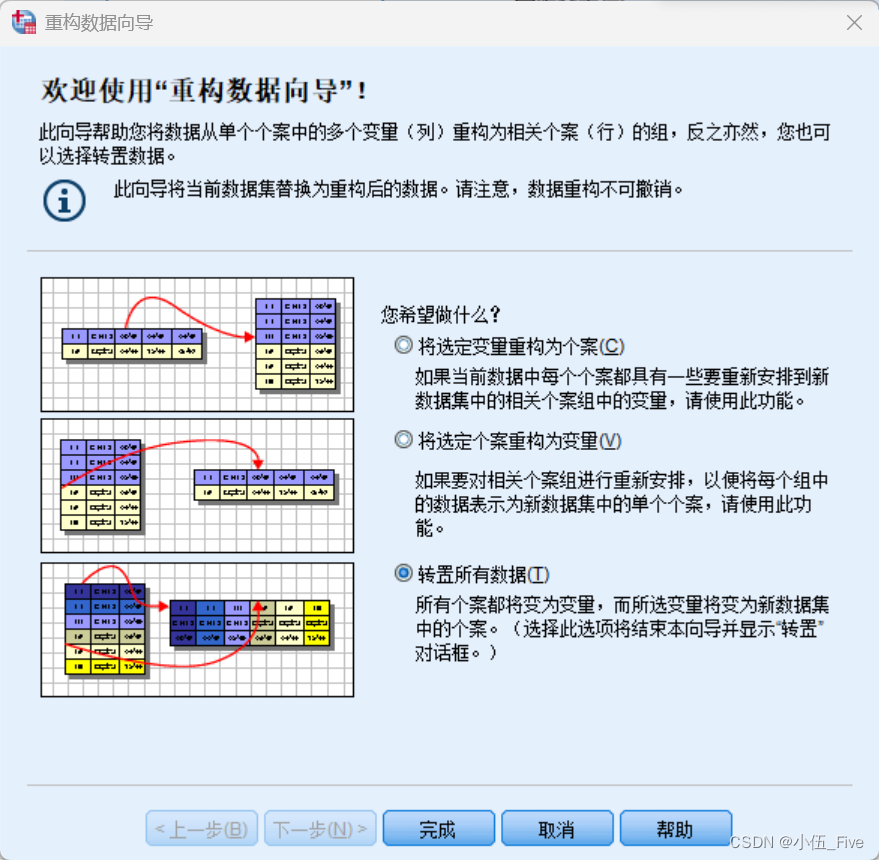
8、数据文件的重新排列与转置
1)长型格式转换为宽型格式
选择“数据"-->”重构"
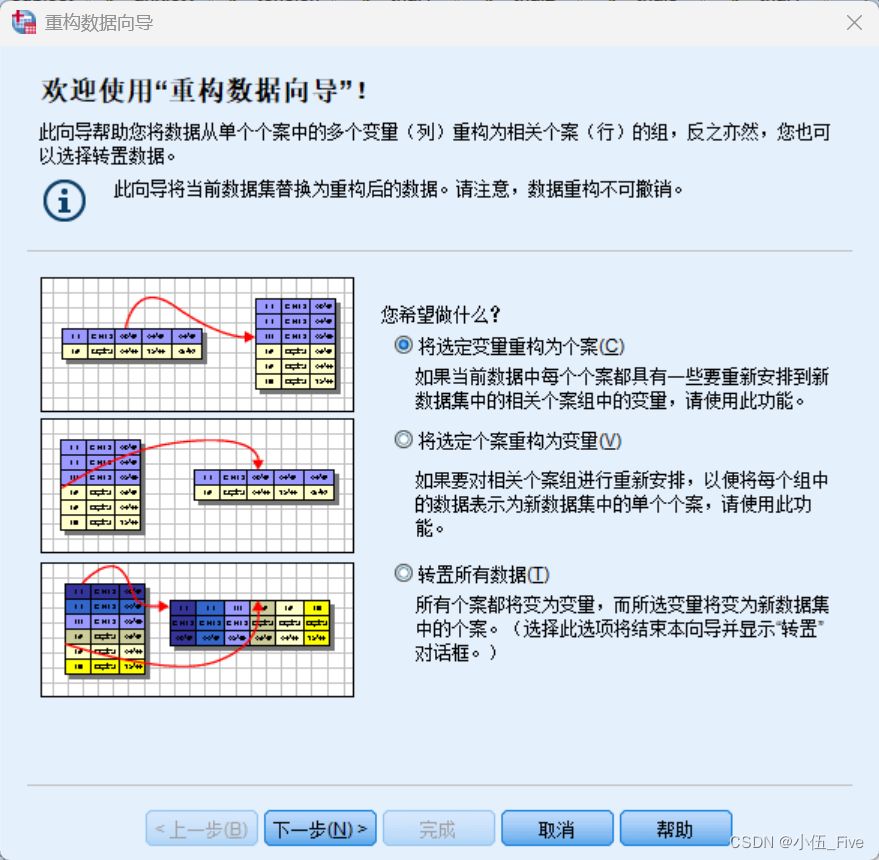
选择 将选定个案重构为变量
后面默认即可
2)宽型格式转换为长型格式
选择 将选定变量重构为个案
后面默认即可
3)数据转置
即数据重构向导的第3个功能
9、多个数据文件的合并
1)数据文件的纵向拼接
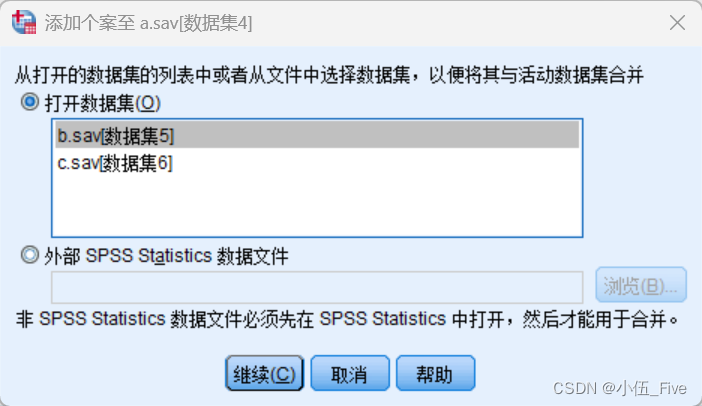
配对:在本例中h和height应当是同一个变量,因此可以将其同时选中,然后单击中部的“配对”按钮强行配对,表示它们具有相同的数据含义,从而将其选人新数据集变量列表框中。此时新变量默认会按照当前文件中相应变量的名称来设定

注:“指定个案源变量”:如果希望在合并后的数据文件中看出哪些记录来自合并前的哪个SPSS数据文件,可以选中该复选框,此时合并后的数据文件中将自动出现名为“source01”的变量,取值为0或1.
0表示该记录来自第1个数据文件,1表示该记录来自第2个数据文件。

2)数据文件的横向合并
选择“数据”→“合并文件”→“添加变量"
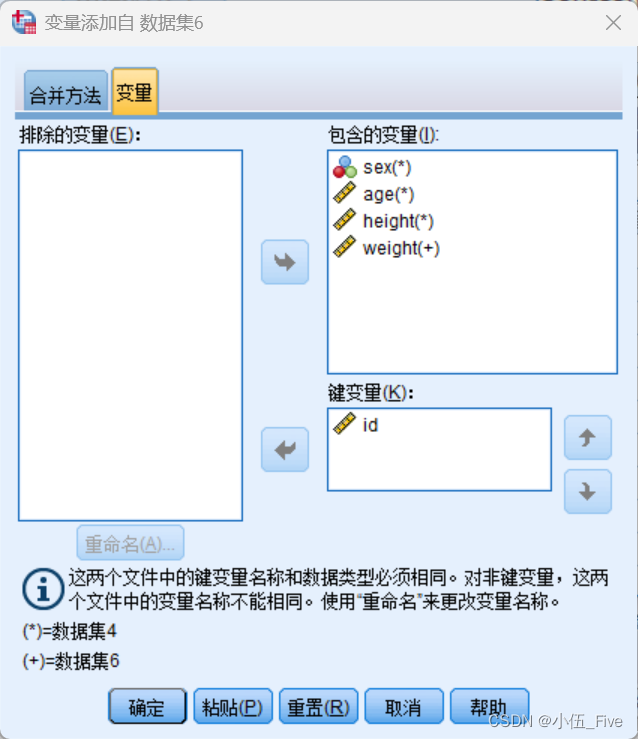
注:使用关键变量进行横向合并前,数据文件必须要按照关键变量排序,否则相应的合并操作将会失败。
总结
本章主要针对文件级别的数据管理
主要解决问题:
1)记录排序,拆分,筛选及加权
2)进行数据汇总,数据字典,数据文件的重新排列与转置及多个文件的合并



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











