



一.什么是RocketMQ
RocketMQ是一款分布式消息中间件,专为高吞吐,高可靠,低延迟的场景设计,用于在不同系统或组件之间传递消息。
RocketMQ有什么作用?
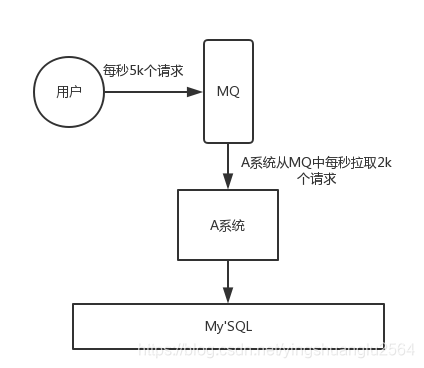
- 流量削峰:当处理高并发请求时,消息队列可以通过缓冲请求,平滑处理高峰期的流量,避免系统崩溃。例如:A系统在高峰期每秒接收5000个请求,但只能处理2000个请求,通过消息队列可以将多余的请求暂存,逐步处理
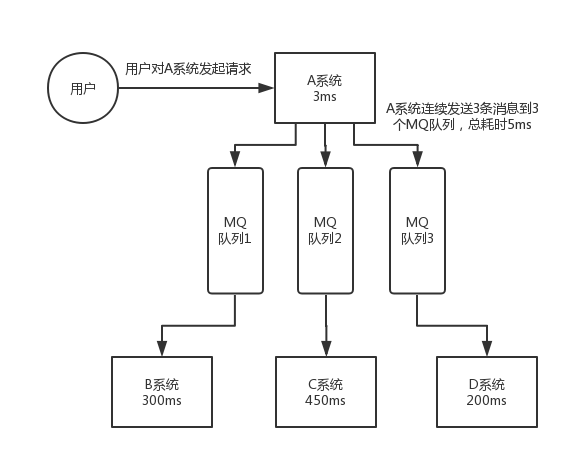
- 异步处理:可以将耗时的操作异步化,提高系统响应速度。例如:A系统接收请求后,需要在本地和BCD三个系统写库,直接同步处理会导致用户等待时间过长。通过消息队列,A系统可以快速返回响应,后续操作由其他系统异步处理。
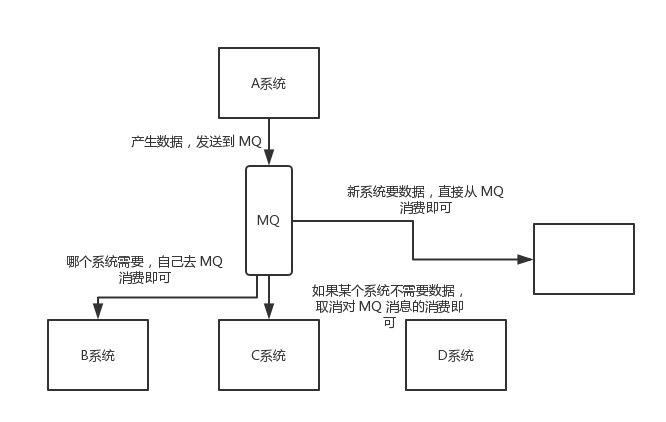
- 解耦:A系统需要将数据发送到BCD三个系统,如果再增加一个E系统,A系统的维护将变得非常复杂。通过引入消息队列,A系统只需将数据发送到MQ,其他系统根据需要从MQ中获取并处理数据,从而实现系统间的解耦。
-
- 提高系统稳定性:消息队列可以提高系统的稳定性,避免因某个模块故障导致整个系统崩溃。例如,电商系统下订单时,如果生产系统因维护暂停服务,通过消息队列可以暂存订单数据,待生产系统恢复后再处理。
具体参考:https://blog.csdn.net/yingshuanglu2564/article/details/99692405
二,系统架构
1.Producer
消息生产者,负责生产消息。Producer通过MQ的负载均衡模块选择相应的Boker集群队列进行消息投递。投递过程中支持快速失败并且低延迟。
例如:业务系统产生的日志写入到MQ的过程,都是消息生产的过程
再如,电商平台中用户提交的秒杀请求写入到MQ的过程,就是消息的生产过程
RocketMQ中的消息生产者都是以生产组的形式出现的。生产者组是一类生产者的集合,这类Producer发送相同Topic类型的消息。一个生产者组可以同时发送多个主题消息。
2.Consumer
消息消费者,负责消费(获取或处理)消息。一个消费者会从Broker服务器中获取消息,并对消息进行相关业务处理。
例如,Qos系统从MQ中读取日志,并对日志进行解析处理的过程就是消息消费的过程
再如,电商平台的业务系统从MQ中读取到秒杀请求,并对请求进行处理的过车就是消息消费的过程。
RocketMQ中的消息消费者都是以消费者组的形式出现的。消费者组是同一类消费者的集合,这类Consumer消费的是同一个Topic类型的消息。消费者组使得在消息消费方面,实现负载均衡和容错的目标变得非常容易。
负载均衡:将一个Topic中的不同的Queue平均分配给同一个Consumer Group的不同的Consumer,注意,并不是将消息负载均衡。
容错:一个consumer停止工作,改consumer group中的其他的consumer可以接着消费原=consumer消费的Queue
注意:一个Queue只允许同一个消费者组中的一个Consumer消费
3.NameServer
NameServer 是某些消息队列(如 RocketMQ)中的核心组件,主要负责 服务发现和路由管理,类似于分布式系统中的“注册中心”。它的核心作用是帮助生产者和消费者定位到正确的 Broker(消息存储和转发节点)。
NameServer 像电话簿:
Broker 是商店(服务提供者),生产者和消费者是顾客。NameServer 提供商店的地址和营业状态,顾客无需记住所有商店位置,只需查询电话簿即可。
为什么需要 NameServer?
-
解耦:生产者和消费者无需直接感知 Broker 的 IP 或变更。
-
高可用:NameServer 集群可容忍部分节点故障。
-
动态扩展:新增 Broker 时,只需向 NameServer 注册,客户端自动发现。
路由注册:
NameServer通常以集群方式部署,但是NameServer中的各个节点是互不通信。
那各个节点中的数据是如何进行数据同步的?
在Borker节点启动时候,会轮询NameServer列表,与每个NameServer节点进行长连接,发起注册请求。NameServer中维护者一个Broker列表,用来动态存储Broker的信息。


路由发现:
RocketMQ的路由发现采用的是Pull模型。当Topic路由信息发生变化的时候,NameServer不会主动推送给客户端,而是客户端主动拉去最新的路由。默认客户端每30s会拉取一次最新的路由。

4.Broker
Broker 是消息队列(如 RocketMQ、Kafka)的核心组件,负责消息的接收、存储、路由和投递。你可以把它想象成一个邮局或快递中转站:
-
生产者(寄件人)把消息交给 Broker。
-
Broker 暂存消息并确保它被正确投递。
-
消费者(收件人)从 Broker 获取消息。
Broker的核心功能
| 功能 | 说明 |
|---|---|
| 消息接收 | 接收生产者发送的消息,返回确认(ACK)。 |
| 消息存储 | 将消息持久化到磁盘(防止丢失),支持高性能读写。 |
| 消息路由 | 根据 Topic 和 Queue 将消息分发给正确的消费者。 |
| 消息投递 | 推(Push)或拉(Pull)模式将消息传递给消费者。 |
| 高可用保障 | 主从复制(Master-Slave)、故障自动切换。 |
为了增强Broker性能与吞吐量,Broker一般是以集群的形式出现的。各个集群节点中可能存放着相同的Topic的不同的Queue。
如果某个Broker节点宕机,如何保证数据不丢失呢 ?(高可用机制)
-
主从复制(必须配置)
-
Master-Slave 架构:每个 Broker 主节点(Master)至少配 1 个从节点(Slave),Slave 实时同步 Master 数据。
-
同步复制(高可靠):Master 必须等 Slave 写入成功后才返回 ACK,确保数据不丢。
-
-
持久化刷盘(关键步骤)
-
同步刷盘:消息必须写入磁盘后才返回 ACK(避免内存数据丢失)。
-
-
自动故障转移(快速恢复)
-
Master 宕机后,Slave 自动切换为新 Master,继续提供服务。
-
-
生产者重试(额外保障)
-
生产者未收到 ACK 时自动重发消息(防止发送阶段丢失)
-
发送消息和消费完整工作流程
RocketMQ的工作流程大致如下:生产者和消费者启动时会向NameServer集群注册自己的信息并获取路由信息,而Broker集群在启动时也会向NameServer注册自己的Topic和队列等元数据。当生产者发送消息时,会先根据Topic查询本地缓存的路由信息(若没有则从NameServer获取),确定该Topic对应的Broker节点,然后将消息发送到指定的Broker主节点(或从节点,取决于配置)。消费者在拉取消息前同样会通过NameServer获取Topic路由信息,NameServer会返回包含该Topic的Broker物理地址列表,消费者根据负载均衡策略选择对应的Broker建立长连接,随后从指定的消息队列中消费消息。整个过程通过NameServer的动态路由协调,实现了生产者和消费者与Broker集群之间的解耦,确保消息的正确投递与消费。
各组件的协作细节
(1) NameServer 的作用
服务发现:
生产者和消费者通过 NameServer 动态感知 Broker 的存活状态和 Topic 分布。
无状态设计:
NameServer 节点间不通信,Broker 定时上报心跳(默认 30 秒一次)。
(2) Broker 的存储与投递
CommitLog:所有 Topic 的消息按顺序写入同一文件(高性能)。
ConsumeQueue:每个 Topic 的 Queue 对应一个索引文件(快速定位消息)。
投递模式:
Push:Broker 主动推送给消费者(RocketMQ 的默认模式)。
Pull:消费者主动从 Broker 拉取(如 Kafka)。
(3) Topic 与 Queue 的关系
Topic 是逻辑分类,Queue 是物理分片。
例如:
order_topic分成 4 个 Queue(Queue0~Queue3),消息均匀分布到不同 Queue。并行消费:
多个消费者可以同时消费同一个 Topic 的不同 Queue(提升吞吐量)。
(4) 高可用流程(Broker 宕机时)
NameServer 检测到 Broker 心跳超时(默认 120 秒),将其从路由表剔除。
生产者和消费者从 NameServer 获取新路由表,切换到其他 Broker。
若配置了主从同步,Slave Broker 自动升级为 Master。
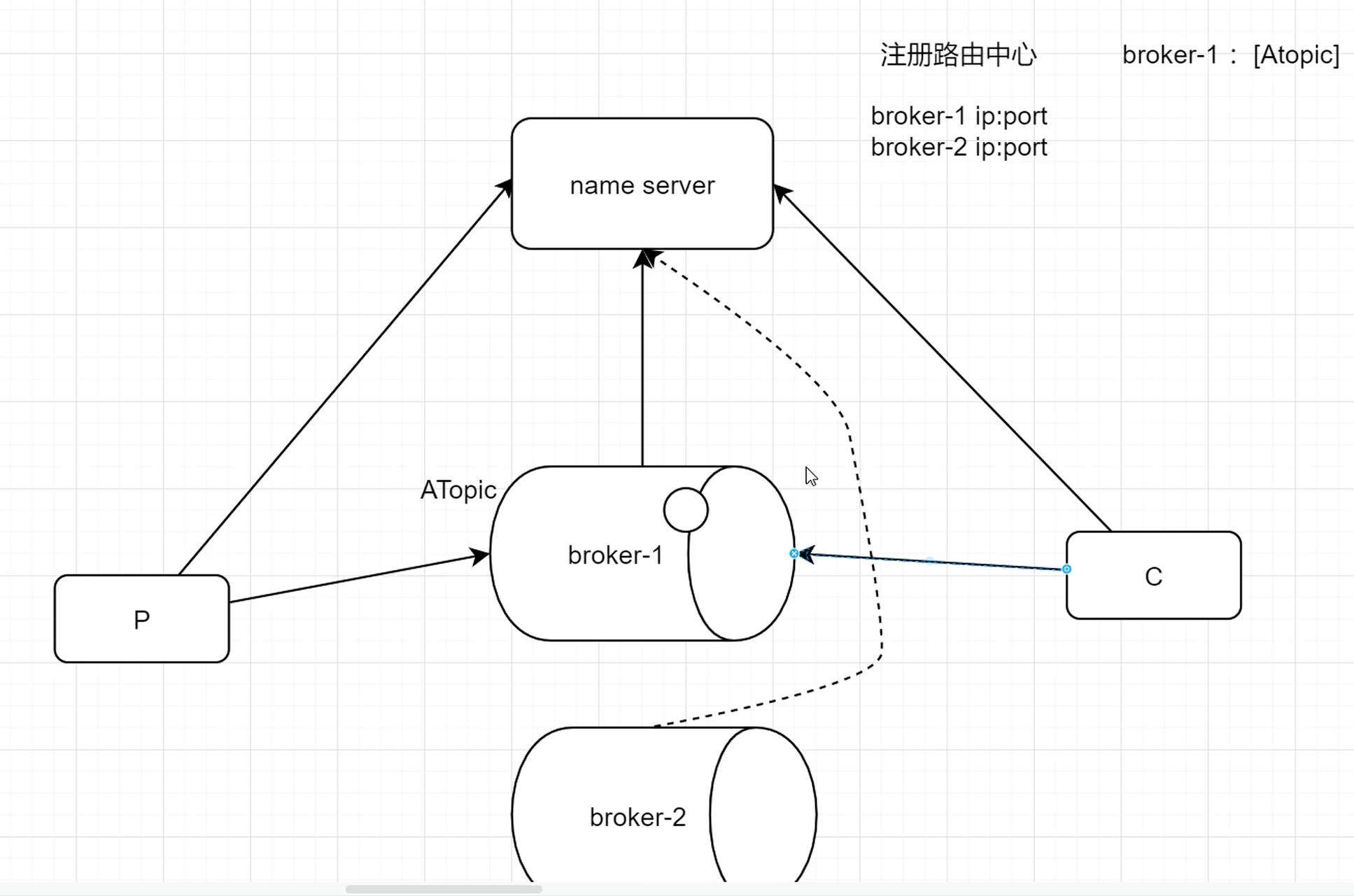
5.读写队列的问题
当读写队列数量设置不同时,总是有问题的。那么为什么要这样设计呢?
这样设计是为了 方便Topic的Queue的缩容,当创建的Topic中包括16个Queue,如何能够使其Queue缩容为8个,还不会丢失消息呢?
可以动态修改写队列为8,读队列数量不变。此时新的消息只能写入到前8个队列,而消费都消费的却是16个队列中的数据。当发现后8个Queue中的消息消费完毕后,就可以再将读队列的数量动态设置为8。整个缩容过程中,没有消息的丢失。
perm用于设置对当前创建的Topic的操作权限:2表示只写,4表示只读,6表示读写。
6.延迟消息发送
为什么需要延迟消息发送呢?
| 问题 | 传统方案 | RocketMQ延时消息方案 |
|---|---|---|
| 支付超时检查 | 需要定时轮询数据库,高频查询压力大 | 精准触发,无冗余检查 |
| 系统解耦 | 订单服务和支付检查逻辑强耦合 | 订单服务只发消息,不关心后续处理 |
| 可靠性 | 服务重启可能导致定时任务丢失 | 消息持久化,即使系统崩溃也不丢失 |
| 扩展性 | 修改超时时间需要改代码 | 只需调整延时等级(如1h→2h) |
RocketMQ消息延迟发送流程举例
用户下单时(0分钟):
系统立即创建订单,用户马上能看到订单页面和支付倒计时(用户体验不受影响)
同时,系统向RocketMQ发送一条内部控制消息:"30分钟后检查此订单的支付状态"
等待期间(0~30分钟):
用户可以随时支付,支付后订单状态会实时更新(用户看到的页面是实时刷新的)
如果用户在30分钟内完成支付,系统会标记订单为已支付,后续的延时消息会被忽略
30分钟到期时:
系统消费那条"检查支付状态"的延时消息
发现订单仍未支付 → 系统自动取消订单 → 用户会收到通知(如APP推送/短信)
如果已支付 → 系统不做任何操作
代码实现:
下单时发送延时消息
Message msg = new Message("OrderTopic", "订单ID123".getBytes());
// 设置延时等级(对应30分钟)
msg.setDelayTimeLevel(16);
producer.send(msg);30分钟后Broker将消息投递到实际的Topic,消费者程序获取这条消息,消费者处理
consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {
for (MessageExt msg : msgs) {
// 检查订单支付状态
if(未支付){
// 执行取消订单逻辑
orderService.cancelOrder(msg.getKeys());
// 可能还会给用户发通知
notifyService.sendCancelNotice(msg.getKeys());
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});三,集群搭建理论
1.数据复制与刷盘策略
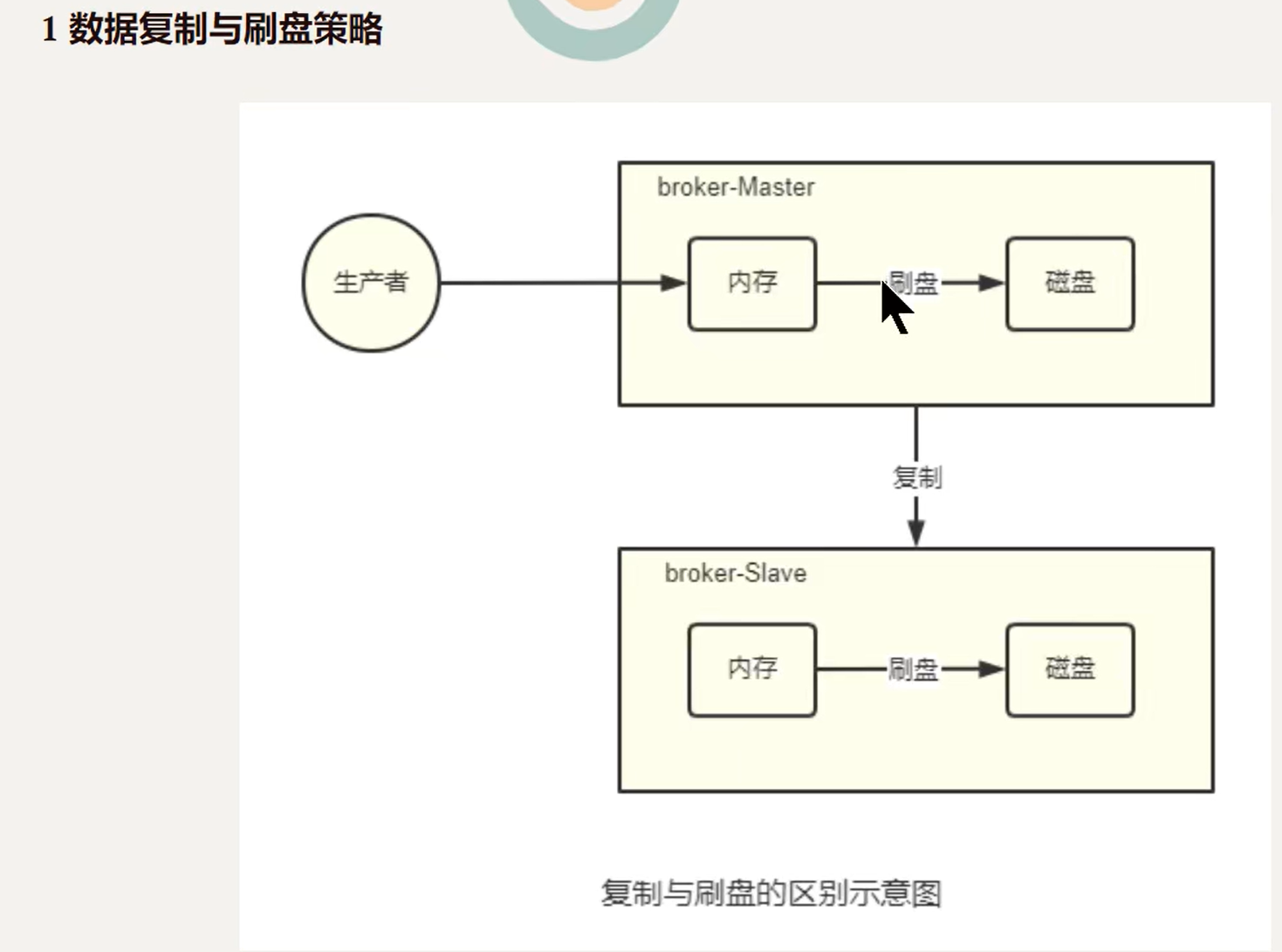
复制策略
复制策略是Broker的Master与Slave间的数据同步方式。分为同步复制和异步复制:
- 同步复制:消息写入master后,master会等待slave同步数据成功后才向producer返回成功ACK
- 异步复制:消息写入master后,master立即向producer返回成功ACK,无需等待slave同步数据成功
异步复制策略会降低系统写入延迟,RT变小,提高了系统的吞吐量
刷盘策略
刷盘策略指的是broker中的消息的落盘方式,即消息发送到broker内存后消息持久化到硬盘的方式。分为同步刷盘异步刷盘:
- 同步刷盘:当消息持久化到broker的磁盘后才算是消息写入成功。
- 异步刷盘:当消息写入到broker的内存后即表示消息写入成功,无需等待消息持久化到硬盘。
(1)异步复制策略会降低系统写入延迟,RT变小,提高了系统的吞吐量。
(2)消息写入到Broker的内存,一般是写入到了PageCache
(3)对于异步刷盘策略,消息会写入到PageCache后立即返回成功ACK。但并不会立即做落盘操作,而是当PageCache到达一定量时会自动进行落盘
四,Broker的工作原理
1,消息的生产过程
- Producer发送消息之前,会先向NameServer发出获取消息Topic的路由信息的请求
- NameServer返回该Topic的路由表及broker列表
- Producer根据代码中指出的Queue选择策略,从Queue列表中选出一个队列,用于后续存储消息
- Producer对消息做一些特殊处理,例如,消息超过4M,则会对其进行压缩
- Producer向选择出的Queue所在的Broker发出RPC请求,将消息发送到选择出的Queue
路由表:
实际是一个Map,key为Topic名称,value是一个QueueData实例列表。
// 第一层映射:Topic → 该Topic下的所有QueueData(按Broker分组) HashMap<String/* Topic */, List<QueueData>> topicQueueTable;QueueData并不是一个Queue对应一个QueueData,而是一个Broker中该Topic的所有Queue对应一个QueueData。
即,只要涉及到该Topic的Broker,一个Broker对应一个QueueData。QueueData中包含brokerName。
简单来说,路由表的key为Topic名称,value则为所有涉及该Topic的BrokerName列表。
路由表本质:
Topic → List<QueueData>,其中QueueData描述 一个Broker组内该Topic的队列总量。
Broker列表:
实际也是一个Map。key为brokerName,value为BrokerData。
一个 BrokerData对象代表一个逻辑 Broker 组(如BrokerGroupA),包含其 Master 和 Slave 节点。BrokerData中包含brokerName及一个map。该map的key为brokerId,value为该broker对应的地址。
brokerId为 0 表示该broker为Master,非 0 表示Slave。
2.Queue选择算法
对于无序消息,其Queue选择算法,也称为消息投递算法,常见的有两种:
轮询算法
默认选择算法。该算法保证了每个Queue中可以均匀的获取消息。
问题:由于某些原因,在某些Broker上的Queue可能投递延迟严重。导致Producer的缓存队列中出现较大的消息堆积,影响消息投递性能
最小投递延迟算法
该算法会统计每次消息投递的时间延迟,然后根据统计出的结果将消息投递到时间延迟最小的Queue。如果延迟相同,则采用轮询算法投递。该算法可以有效提升消息投递性能
问题:消息在Queue上的分配不均。投递延迟小的Queue可能存在大量消息。而对该Queue的消费者压力增大,降低消息的消费能力,可能会导致MQ中的消息堆积
3.消息的存储
RocketMQ中的消息存储在本地文件系统中,这些相关文件默认在当前用户主目录下的store目录中。

- abort:该文件在Broker启动后会自动创建,正常关闭Broker,该文件会自动消失。
- 若在没有启动Broker的情况下,发现这个文件是存在的,则说明之前Broker的关闭是非正常关闭。
- checkpoint:其中存储着commitlog、consumequeue、index文件的最后刷盘时间戳
- commitlog:其中存放着commitlog文件,而消息是写在commitlog文件中的
- config:存放着Broker运行期间的一些配置数据
- consumequeue:其中存放着consumequeue文件,队列就存放在这个目录中
- index:其中存放着消息索引文件indexFile
- lock:运行期间使用到的全局资源锁
commitLog文件(所有的主题消息都在这)
在很多资料中commitlog目录中的文件简单就称为commitlog文件。
但在源码中,该文件被命名为mappedFile。
RocketMQ 的所有主题的消息都存在 CommitLog 中,单个 CommitLog 默认 1G,并且文件名以起始偏移量命名,固定 20 位,不足则前面补 0
比如 00000000000000000000 代表了第一个文件,第二个文件名就是 00000000001073741824,表明起始偏移量为 1073741824,以这样的方式命名用偏移量就能找到对应的文件。
所有消息都是顺序写入的,超过文件大小则开启下一个文件。
目录和文件
commitlog目录中存放着很多的mappedFile文件,当前Broker中的所有消息都是落盘到这些mappedFile文件中的
mappedFile文件大小为1G(小于等于1G),文件名由 20 位十进制数构成,表示当前文件的第一条消息的起始位移偏移量。
第一个文件名一定是 20 位 0 构成的。因为第一个文件的第一条消息的偏移量commitlog offset为 0,当第一个文件放满时,则会自动生成第二个文件继续存放消息。
假设第一个文件大小是 1073741820 字节(1G = 1073741824字节),则第二个文件名就是 00000000001073741824 。以此类推,第n个文件名应该是前n-1个文件大小之和。一个Broker中所有mappedFile文件的commitlog offset是连续的
需要注意的是,一个Broker中仅包含一个commitlog目录,所有的mappedFile文件都是存放在该目录中的。
无论当前Broker中存放着多少Topic的消息,这些消息都是被顺序写入到了mappedFile文件中的。
也就是说,这些消息在Broker中存放时并没有被按照Topic进行分类存放
mappedFile文件是顺序读写的文件,所以其访问效率很高。
无论是SSD磁盘还是SATA磁盘,通常情况下,顺序存取效率都会高于随机存取。
消息单元
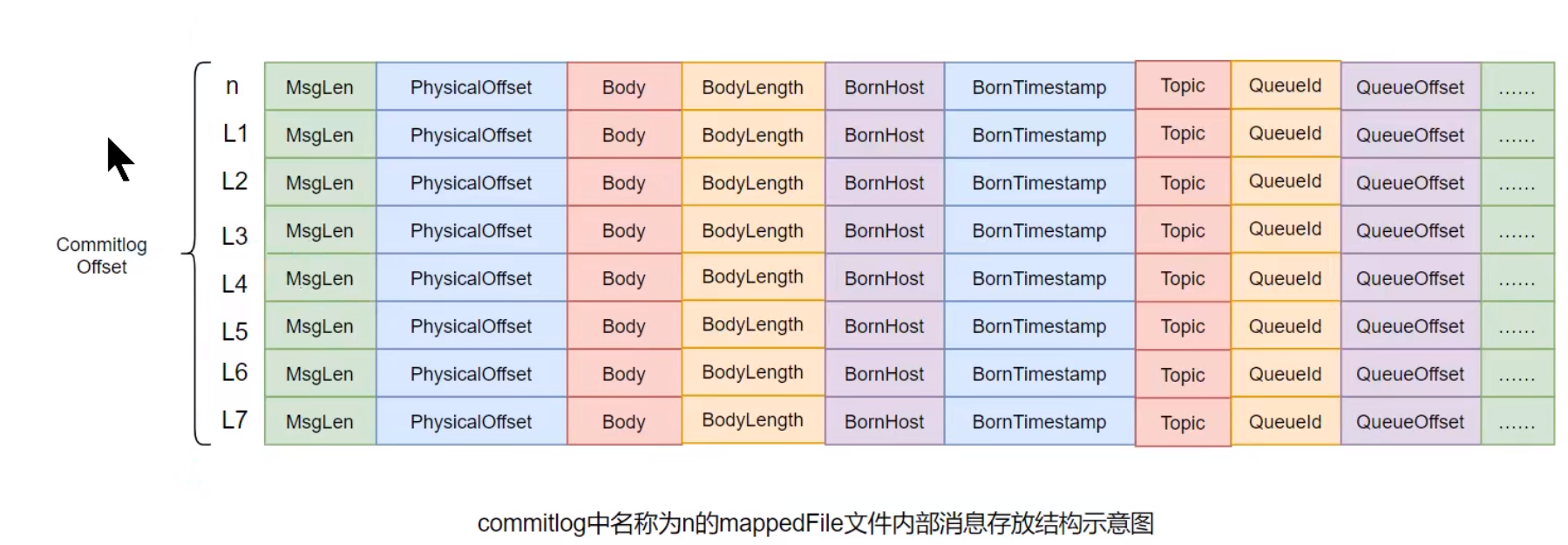
mappedFile文件内容由一个个的消息单元构成。每个消息单元中包含消息总长度MsgLen、消息的物理位置physicalOffset、消息体内容Body、消息体长度BodyLength、消息主题Topic、Topic长度 TopicLength、消息生产者BornHost、消息发送时间戳BornTimestamp、消息所在的队QueueId、消息在Queue中存储的偏移量QueueOffset等近 20 余项消息相关属性。
需要注意到,消息单元中是包含Queue相关属性的。
所以,需要十分留意commitlog与queue间的关系是什么?一个mappedFile文件中第m+1个消息单元的commitlog offset偏移量
L(m+1) = L(m) + MsgLen(m) (m >= 0)
对文件的读写
1.消息写入(生产的过程)
消息发送准备:Producer 首先创建一条消息,指定 Topic、Tag 和 Body 等信息。
NameServer 查询:Producer 通过 NameServer 获取 Topic 的路由信息,包括哪些 Broker 存在这个 Topic 的队列(Queue)。NameServer 起到了服务发现的作用。
选择队列:根据获取到的路由信息,Producer 会选择一个合适的队列来发送消息。默认情况下,会采用轮询的方式选择队列以达到负载均衡。
消息发送:Producer 将消息发送给选定的 Broker。这个过程中,Broker 会对消息进行一系列的校验,如权限校验、消息格式校验等。
消息存储:如果消息校验通过,Broker 会将消息追加写入 CommitLog 文件中。RocketMQ 采用了顺序写的方式提高写入性能,并且为了提升读取消息的效率,还会异步地将消息从 CommitLog 复制到 ConsumeQueue 和 IndexFile 中。
响应 Producer:当消息成功写入后,Broker 会给 Producer 发送确认响应,告知消息是否发送成功。
2.消息拉取(消费)过程
消费者启动:Consumer 启动时也会向 NameServer 注册自己,并获取对应 Topic 的路由信息。
构建 Pull Request:Consumer 根据路由信息构建 Pull Request,其中包含了要拉取的消息所属的 Topic、队列、Offset 等信息。
消息拉取:Consumer 向 Broker 发起 Pull 请求,请求特定 Offset 开始的一批消息。RocketMQ 支持长轮询机制,即如果没有新消息到达,Broker 可以保持连接一段时间等待新消息到来,从而减少 Consumer 的空轮询次数。
消息过滤:在 Broker 端可以根据 Tag 或 SQL 表达式对消息进行过滤,只返回符合条件的消息给 Consumer,减少不必要的网络传输。
处理消息:Consumer 接收到消息后,按照业务逻辑处理消息。处理完成后,需要更新本地的消费进度(Offset),并定期同步给 Broker。
提交消费进度:为了避免重复消费,Consumer 定期将最新的消费进度同步给 Broker。一旦发生故障重启后,可以从上次记录的 Offset 继续消费,保证了至少一次的语义。
原理总结
- 高效的消息存储:RocketMQ 使用顺序写 CommitLog 来保证高效的写入性能;同时通过 ConsumeQueue 和 IndexFile 来优化消息的读取效率。
- 灵活的消费模型:支持 Push 和 Pull 两种模式,Pull 模式下可以更好地控制消费速率和失败重试策略。
- 可靠的消费进度管理:通过定时同步消费进度,确保在发生故障时能够准确恢复消费位置,避免数据丢失或重复消费。
注: ConsumeQueue、IndexFile、Offset ,CommitLog关键字的含义
一、Offset(偏移量)
定义
- Offset 表示消息在某个队列中的位置编号。
- 每条消息在写入 CommitLog 后都会有一个全局唯一的 Offset(即在整个 Broker 中是连续递增的)。
- 消费者通过记录 Offset 来知道它“已经消费到了哪一条消息”。
类比
想象你在图书馆借了一本很长的小说,每次看完一部分就夹一张书签,下一次继续从那里看。这个“书签的位置”就是 Offset。
示例
offset = 1024; // 当前消费到第1024字节处的消息二、CommitLog(提交日志文件)
定义
- 所有消息都顺序写入 CommitLog 文件中(不分 Topic 和 Queue),这是 RocketMQ 的物理存储结构。
- 写入方式为追加写入(append-only),保证高性能。
特点
- 一个 Broker 上只有一个 CommitLog 目录(默认
store/commitlog)。 - 每个文件大小通常是 1GB。
三、ConsumeQueue(消费队列)
定义
- ConsumeQueue 是 RocketMQ 的逻辑队列,它是对 CommitLog 的索引。
- 每个 Topic 下的每个 Queue(MessageQueue)都有一个对应的 ConsumeQueue。
- ConsumeQueue 存储的是指向 CommitLog 中某条消息的索引信息(比如 offset、size、tag hash)。
存储结构
store/
└── consumequeue/
└── [topic]/
└── [queueId]/
└── [file]类比
你可以把 CommitLog 看作是一本厚厚的电话簿,里面按顺序记录了所有人的联系方式;而 ConsumeQueue 就像是这本电话簿的目录,告诉你“Topic A 队列0”的消息分别在电话簿的哪些页码上。
示例:
假设有一条消息:
- Topic: OrderSystem
- QueueId: 0
- 在 CommitLog 中的 offset: 100000
- size: 300 字节
- tagHash: 0x12345678
那么 ConsumeQueue 会记录一行这样的数据:
[phyOffset=100000, size=300, tagHash=0x12345678]消费者拉取消息时,先查 ConsumeQueue 获取这些索引,再根据索引去 CommitLog 中读取完整的消息内容。
四、IndexFile(索引文件)
定义
- IndexFile 是一种可选的辅助索引机制,用于通过 key 快速查找消息。
- 它允许你通过 key(如订单号、消息ID)快速定位到某条消息在 CommitLog 中的 offset。
存储结构:
store/
└── index/
└── [timestamp]类比:
还是用电话簿来比喻:如果你想找“张三”的电话号码,可以翻到最后的“按姓名排序”的索引页,找到“张三”所在的页码,再去正文里查。这就是 IndexFile 的作用。
示例:
发送消息时可以加上 key:
Message msg = new Message("OrderTopic", "ORDER_20250715_1001".getBytes());之后可以通过 key 查找这条消息:
mqadmin queryMsgByKey -n localhost:9876 -t OrderTopic -k ORDER_20250715_1001RocketMQ 就会利用 IndexFile 快速定位这条消息在 CommitLog 中的 offset。
🧩 总结对比表:
| 名称 | 类型 | 作用说明 |
|---|---|---|
| Offset | 数值 | 消息在 CommitLog 中的位置编号 |
| CommitLog | 物理文件 | 所有消息的原始存储地(按顺序写入) |
| ConsumeQueue | 逻辑索引文件 | 每个 Topic + Queue 对应一个,用来快速定位消息 |
| IndexFile | 辅助索引文件 | 支持通过 key(如订单号)快速查找消息 |
举个完整的流程例子:
假设现在正在开发一个电商系统,用户下单后会发送一条订单消息到 RocketMQ。
步骤如下:
-
Producer 发送消息:
Message msg = new Message("OrderTopic", "ORDER_20250715_1001".getBytes()); -
Broker 接收到消息后:
- 把消息追加写入 CommitLog 文件;
- 同时生成一条索引记录写入 OrderTopic 对应的 ConsumeQueue;
- 如果开启了 IndexFile 功能,还会将 key(ORDER_20250715_1001)写入 IndexFile。
-
Consumer 拉取消息:
- Consumer 根据 Topic 和 QueueId 查询对应的 ConsumeQueue;
- 得到一批 offset 列表;
- 然后根据 offset 从 CommitLog 中读取真实的消息内容进行处理;
- 处理完成后更新 offset 并提交给 Broker。
总结:
Offset 是消息的位置标记,CommitLog 是消息的物理存储,ConsumeQueue 是 Topic/Queue 的逻辑索引,IndexFile 是支持 Key 查询的辅助索引。

















 1702
1702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









