






启动mysql服务命令
mysql -u root -P 3306;
一、数据库的创建和使用
1. 创建数据库
create database db_name;
2. 查看所有的数据库
show databases;
3. 查看创建的数据库的字符集及校验规则
show create database db_name;
默认的字符集为utf8,但也可以进行更换
create database db_name character set GBK;
4. 查看有哪些字符集
show character set;
5. 修改数据库
alter database ab_name [alter_specification];
比如说修改数据库的字符集及校验规则
alter database db character set utf8 colllate utf8_general_ci;
6. 删除数据库
drop database db_name;
7. 显示当前数据库
select database();
8. 选择数据库
use db_name;
二、创建和操纵表(1)
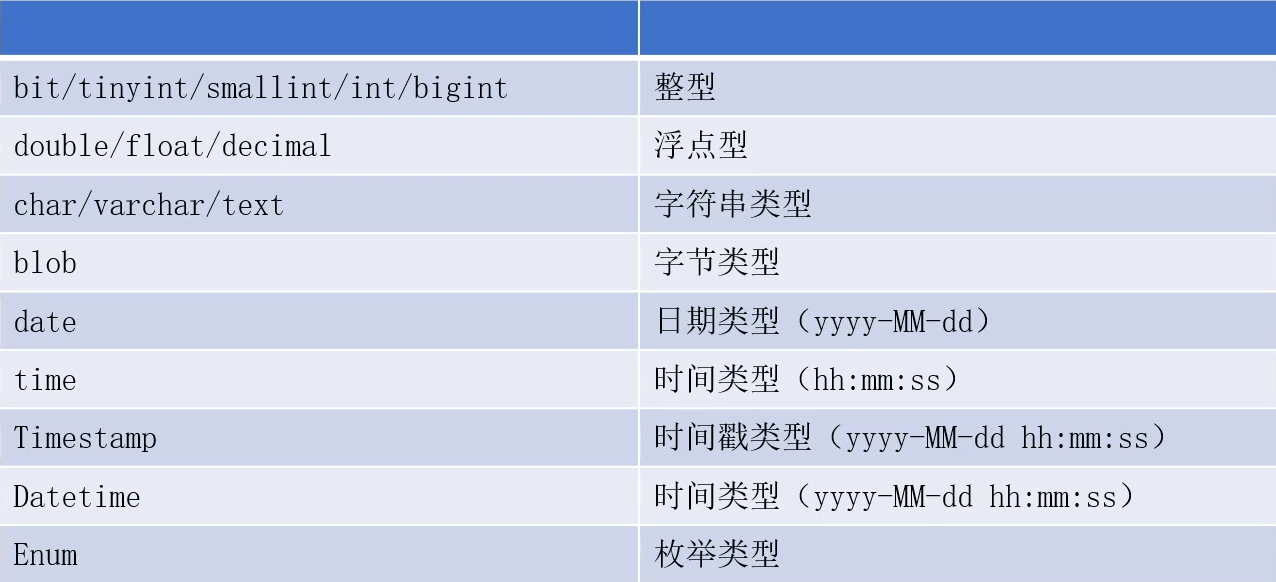
常用类型:
1. 表的创建(举例)
create table tablename(
name varchar(50),
age int,
gender varchar(10),
height int;
weight int
);
2. 查看表结构
desc tablename;
3. 查看建表语句
show create table tablename;
4. 查看当前库的所有表
show tables;
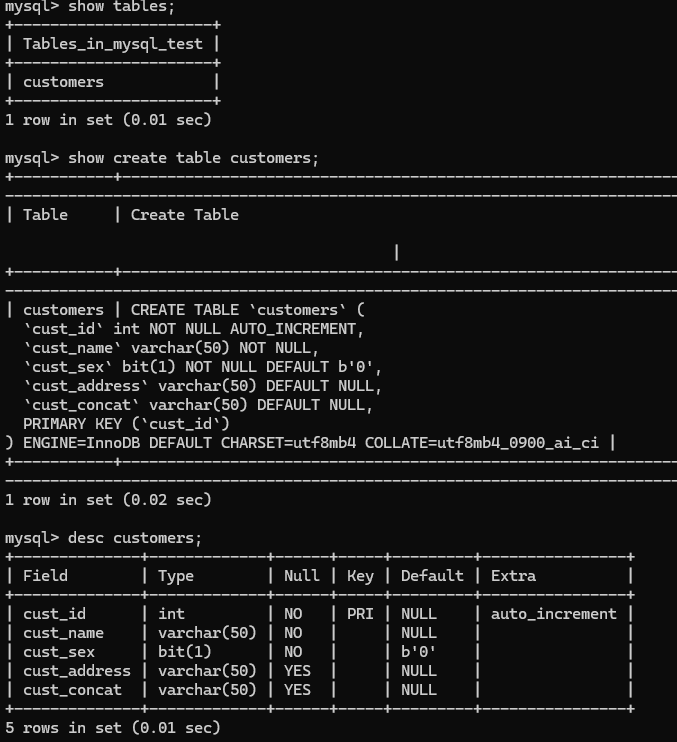
创建表案例:

1.create database mysql_test;
2.show databases;
3.use mysql_test;
4.select database();
5. create table customers(
-> cust_id int auto_increment primary key,
-> cust_name varchar(50) not null,
-> cust_sex bit not null default 0,
-> cust_address varchar(50),
-> cust_concat varchar(50)
-> )engine=innodb;
6.show tables;
7.desc customers;
8.show create table customers;
三、创建和操纵表(2)
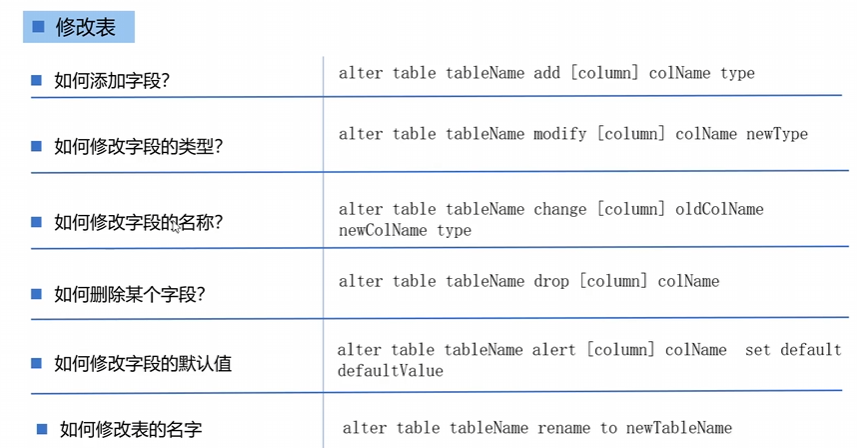
修改表
案例:


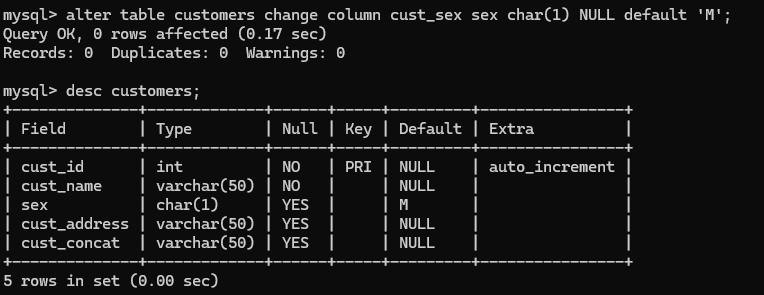
1.alter table customers change column cust_sex sex char(1) NULL default 'M';
2.alter table customers alter column cust_address set default 'BeiJing';
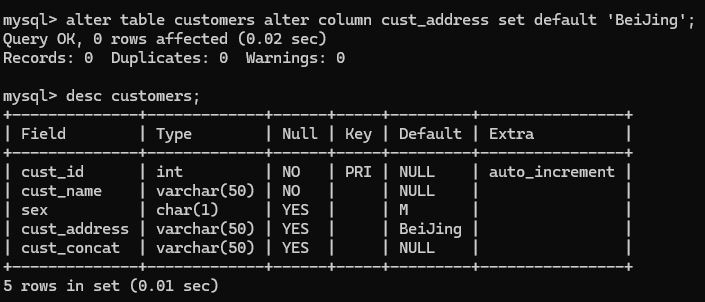
3.alter table customers modify column cust_name varchar(20) first;
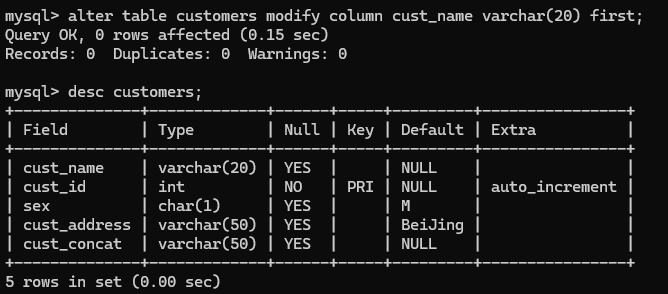
4.alter table customers drop column cust_concat;
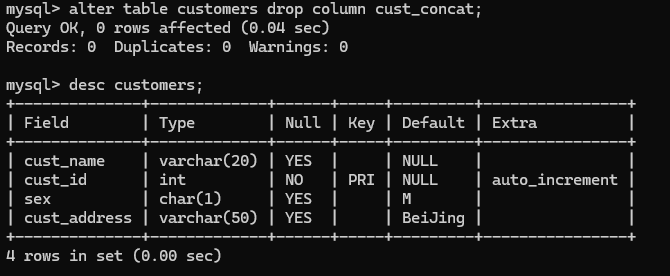
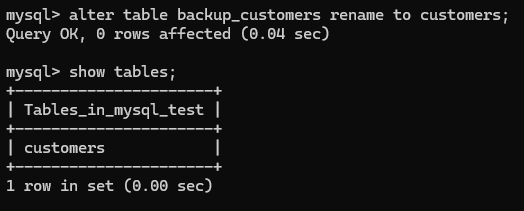
5.alter table customers rename to backup_customers;
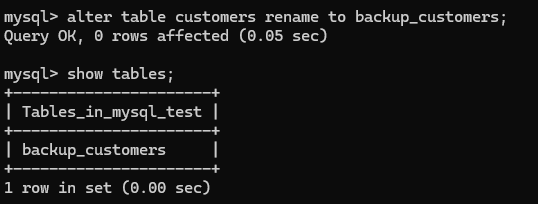
再次重新修改为原来的表名
1. 复制表
(1) 仅复制表的结构,不复制表的内容
create table tb_name like old_tb_name;
(2) 仅仅复制表的内容,不复制表的索引和完整性约束
create table tb_name as select_statement;
2. 删除表
drop table tb_name;

例子:
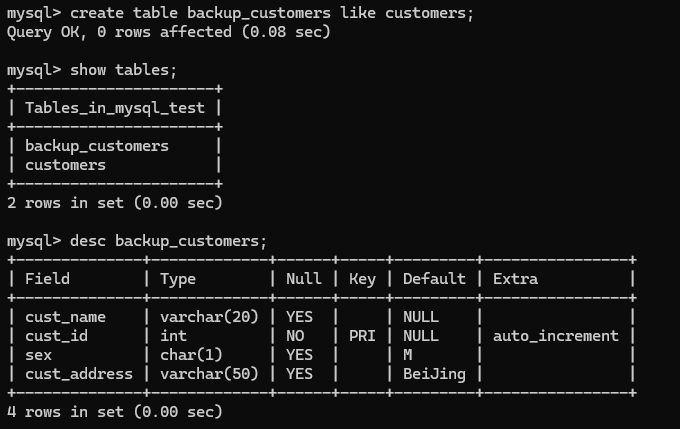
1.create table backup_customers like customers;
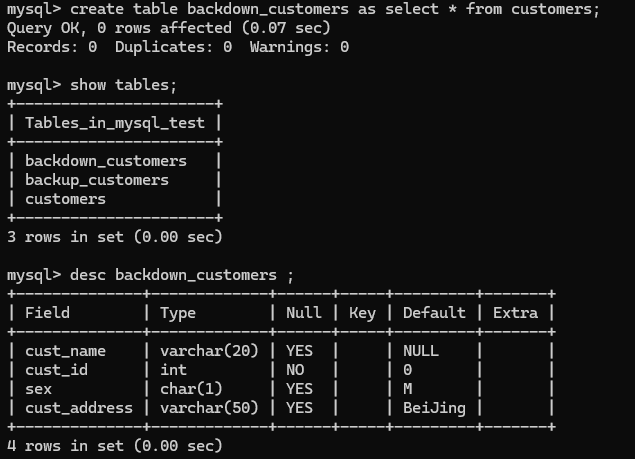
2.create table backdown_customers as select * from customers;
3.drop table backup_customers;
drop table backdown_customers;
四、插入表数据
1. 不指定表中插入一条数据值
insert into tablename values(value1,value2,value3,...valueN);
2. 指定表中插入一条数据值
insert into tablename (colname1,colname2,...colnameN) values(value1,value2,value3,...valueN);
3. 同时插入多条数据值
insert into tablename values(value1,value2,value3,...valueN),(value1,value2,value3,...valueN),(value1,value2,value3,...valueN);

案例:

1.插入一行元素值
insert into customer values(null,'李四',default,'武汉市',null);
查看当前表数据
select * from customer;

2.创建需要复制表的数值内容
create table customer_copy like customer;
show tables;
insert into customer_copy values(null,'赵四',default,'铁岭',null),(null,'王五',default,'北京','海淀区');
select * from customer_copy;

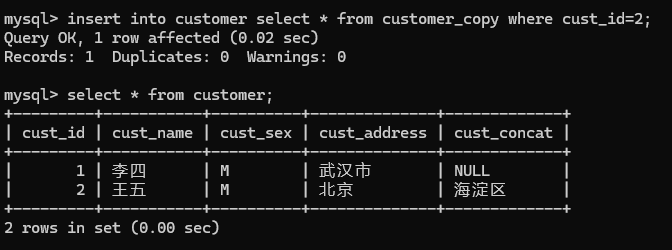
复制新的表中数据元素到customer表中
insert into customer select * from customer_copy where cust_id=2;
加上where cust_id=2是因为在customer_copy表中的第一行数据的id也为1,和customer表已有的id=1冲突,所以加上修饰条件
select * from customer;
3. 添加一行元素数据
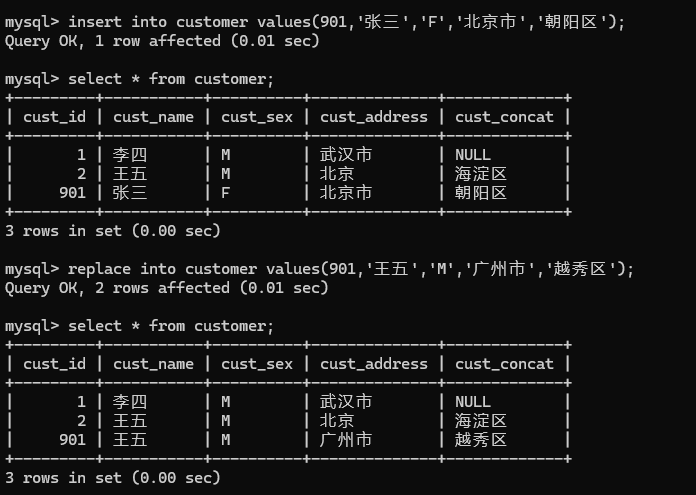
insert into customer values(901,'张三','F','北京市','朝阳区');
select * from customer;
这里使用replace into而不使用insert into,因为需要增加的cust_id是相同的,会导致冲突,从而无法进行增加插入操作
replace into customer values(901,'王五','M','广州市','越秀区');
select * from customer;
五、删除数据表

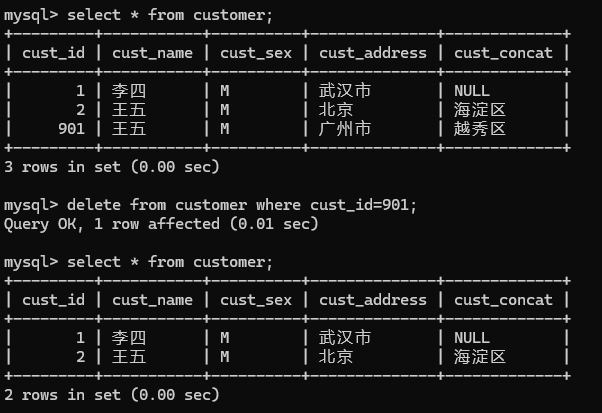
1. 删除表中所有记录(可恢复)
delete from tablename;
delete的删除记录在日志中的,是可以进行回滚的,即可以撤销删除操作
2. 删除满足条件的记录
delete from tablename where condition;
3. 删除表中所有记录(不可恢复)
truncate tablename;
六、修改表数据
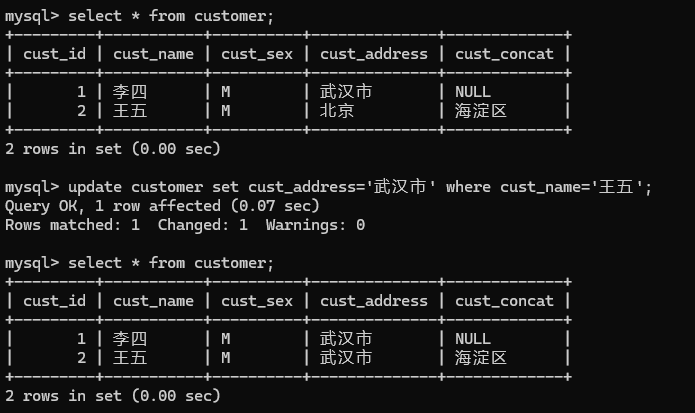
修改表中记录
update table set colname=newvalue[,colname=newvalue] [where condition];

案例:

update customer set cust_address='武汉市' where cust_name='张三';
七、select语句
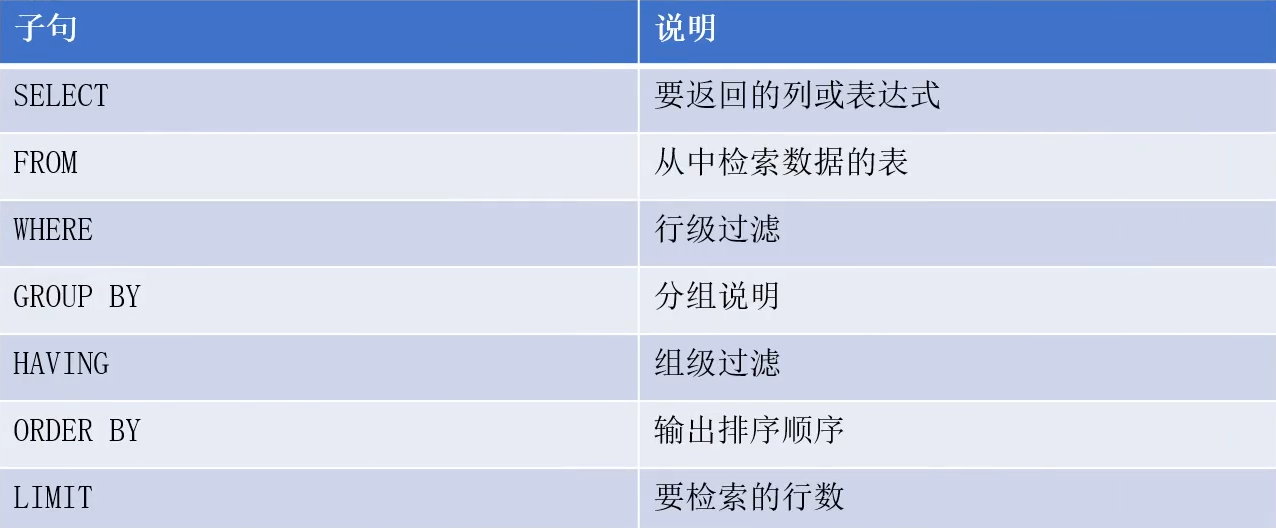
select语句的用法

select语句中各子句的说明
案例:


条件判断语句格式
case
when search_condition then statement_list else statement_list
end
1.select cust_name,cust_address as '地址',cust_concat from customer;

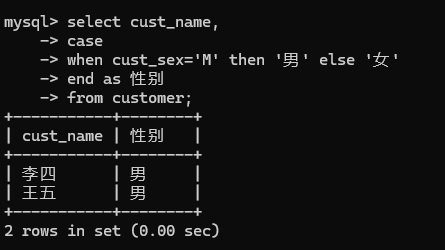
2. select cust_name,
-> case
-> when cust_sex='M' then '男' else '女'
-> end as 性别
-> from customer;
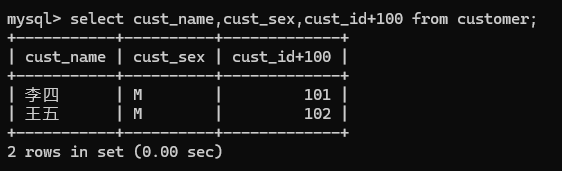
3.select cust_name,cust_sex,cust_id+100 from customer;
聚合函数

案例:
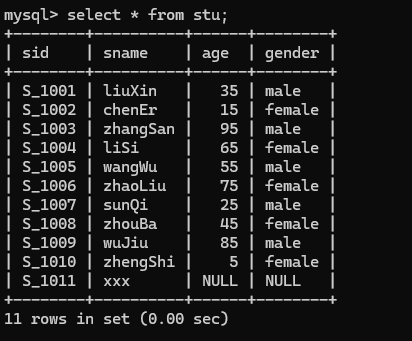
首先创建stu表
create table stu(
sid varchar(50) primary key,
sname varchar(50) not null,
age int ,
gender varchar(50)
);
其次就是添加表中数据
insert into stu values('S_1001','liuXin',35,'male'),
('S_1002','chenEr',15,'female'),
('S_1003','zhangSan',95,'male'),
('S_1004','liSi',65,'female'),
('S_1005','wangWu',55,'male'),
('S_1006','zhaoLiu',75,'female'),
('S_1007','sunQi',25,'male'),
('S_1008','zhouBa',45,'female'),
('S_1009','wuJiu',85,'male'),
('S_1010','zhengShi',5,'female'),
('S_1011','xxx',null,null);
最终表的查询结果如下
1.使用count函数
select count(age) from stu;
这里age中为NULL的这行记录是不被统计在内的(NULL的这行记录是不参与聚合函数的)
select count(*) from stu;
这个是查询表中所有的记录数的

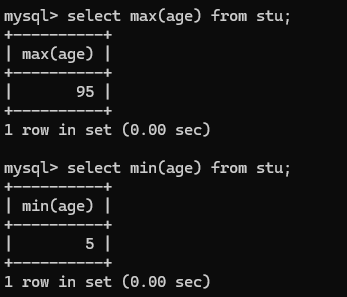
2.求最大最小值
select max(age) from stu;
select min(age) from stu;
3.求最大值
select sum(age) from stu;

4.求平均值
select avg(age) from stu;(NULL值不参与计算)
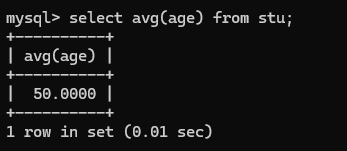
select avg(ifnull(age,0)) from stu;(NULL值参与计算)
八、where语句

案例:(stu表)
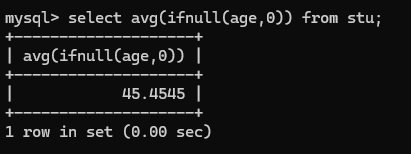
1.查询性别为女,并且年龄45的记录
select * from stu where gender='female' and age=45;
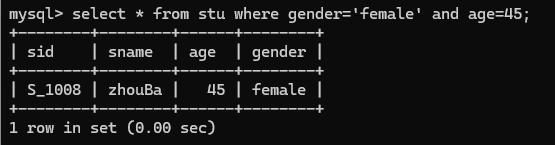
2.查询学号为S_1001,或者姓名为liSi的记录
select * from stu where sid='S_1001' or sname='liSi';
3.查询学号为S_1001,S_1002,S_1003的记录
select * from stu where sid='S_1001' or sid='S_1002' or sid='S_1003';
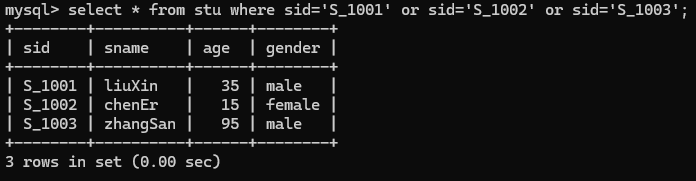
或者还有一种简单的写法
select * from stu where sid in('S_1001','S_1002','S_1003');
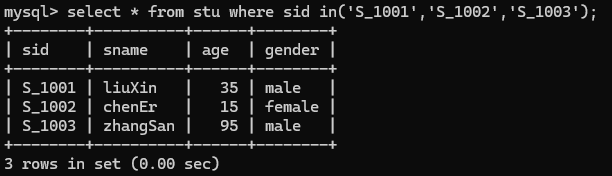
4.查询学号不是S_1001,S_1002,S_1003的记录
select * from stu where sid not in('S_1001','S_1002','S_1003');
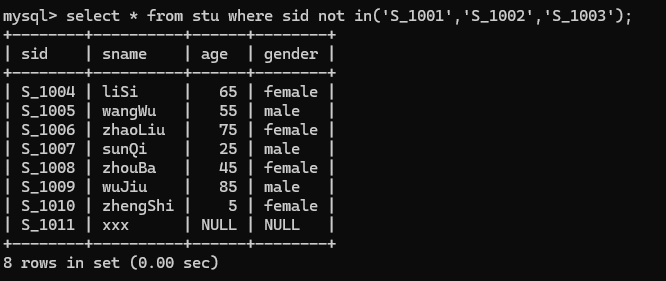
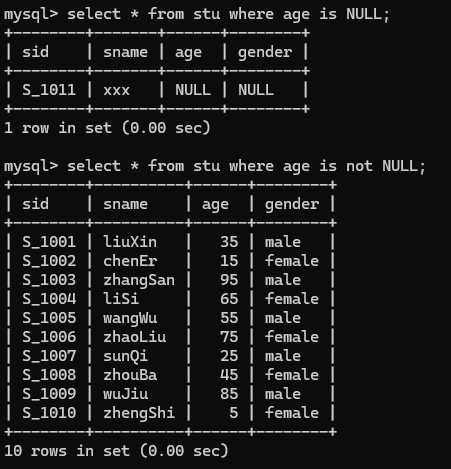
5.查询年龄为null的记录
select * from stu where age is NULL;(age为NULL)
select * from stu where age is not NULL;(age不为NULL)
6.查询年龄在20到40之间的学生记录
select * from stu where age between 20 and 40;
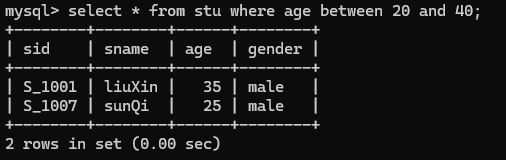
还有一种查询方法
select * from stu where age>=20 and age<=40;
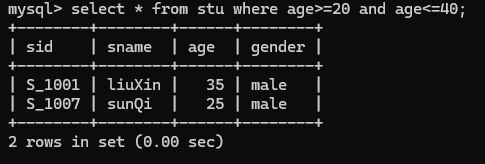
7.查询姓名由5个字母构成的学生记录
select * from stu where sname like '_____';
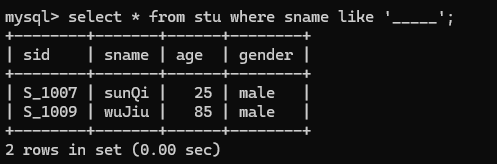
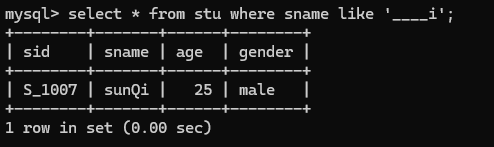
8.查询姓名由5个字母构成,并且第5个字母为"i"的学生记录
select * from stu where sname like '____i';
9.查询姓名以"z"开头的学生记录
select * from stu where sname like 'z%';
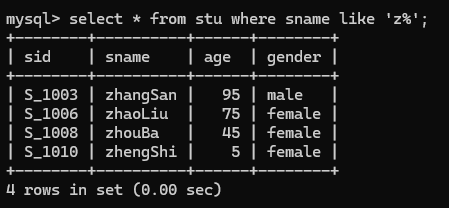
10.查询姓名中包含"a"字母的学生记录
select * from stu where sname like '%a%';

九、group by子句
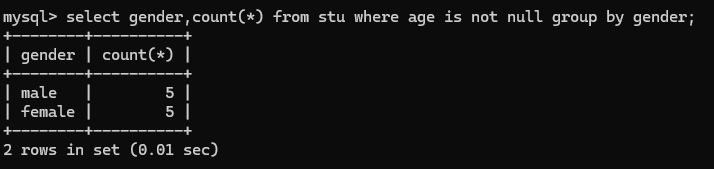
分别统计男女人数数量(需要先排除age为NULL的记录再进行统计)
select gender,count(*) from stu where age is not null group by gender;
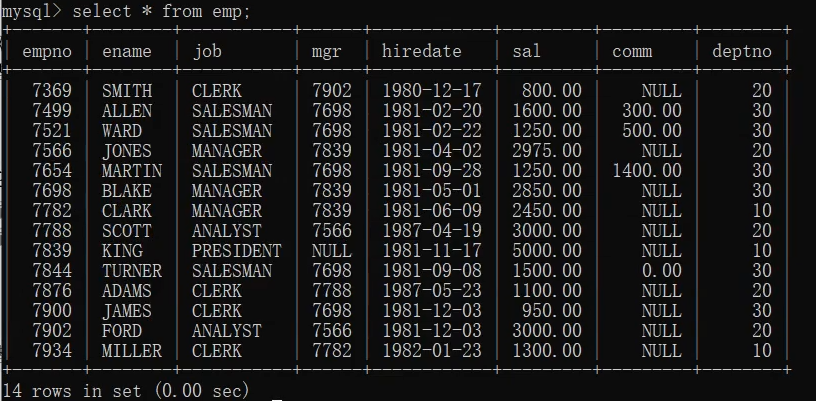
emp表:
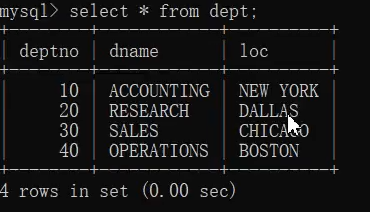
dept表:
案例:
1.查询每个部门的部门编号和每个部门的工资和
select deptno,sum(sal) from emp group by deptno;
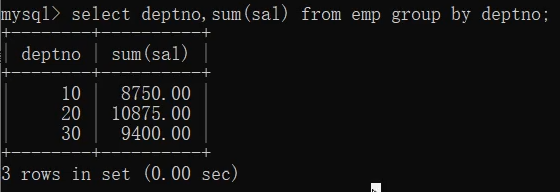
2.查询每个部门的部门编号以及每个部门的人数
select deptno,count(*) from emp group by deptno;
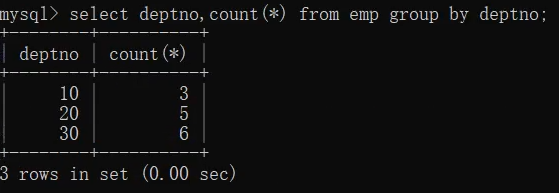
3.查询每个部门的部门编号以及每个部门工资大于1500的人数
select deptno,count(*) from emp where sal>1500 group by deptno;
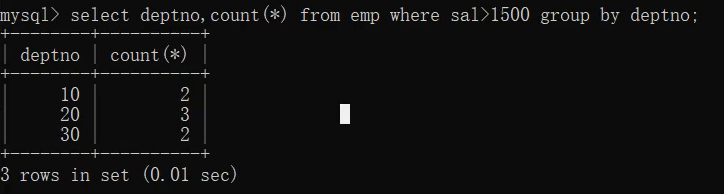
十、having语句
1.select deptno,avg(ifnull(sal,0)) from emp group by deptno having avg(ifnull(sal,0))>1000;

2.select job,max(ifnull(sal,0)),avg(ifnull(sal,0)),avg(ifnull(comm,0)) from emp group by job;
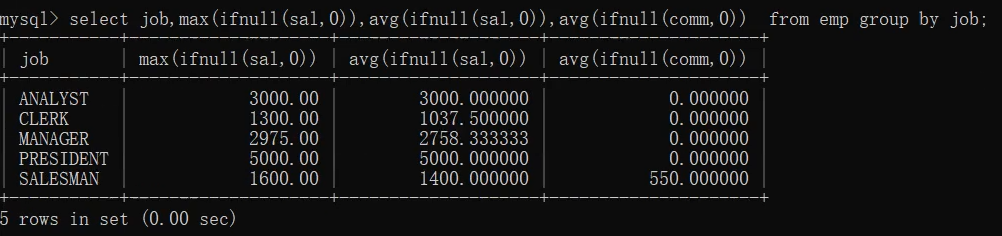
3.select job,max(ifnull(sal,0)),avg(ifnull(sal,0)),avg(ifnull(comm,0)) from emp group by job having max(ifnull(sal,0))>1500;


having和where的区别:
主要就是having是在分组后进行数据的过滤,而where是在分组前就将不满足条件的数据进行过滤
十一、order by语句
order by colname [asc|desc] [,colname [asc|desc]];
asc:升序,可以默认不写
desc:降序,必须要写

案例:

1.select * from emp order by sal desc;
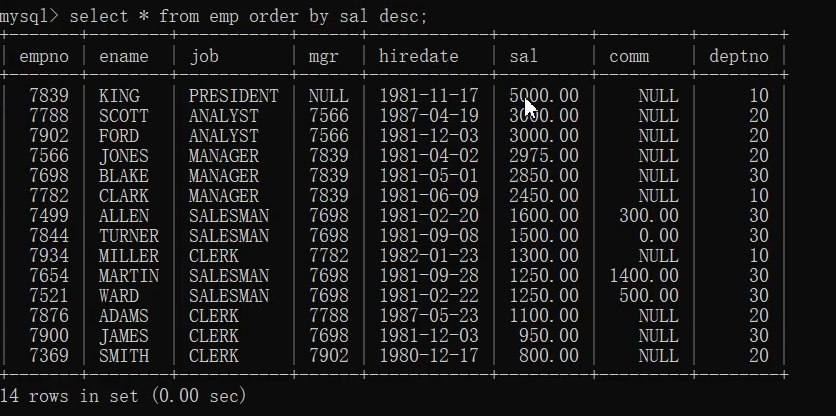
2.select * from emp order by sal desc,comm asc;
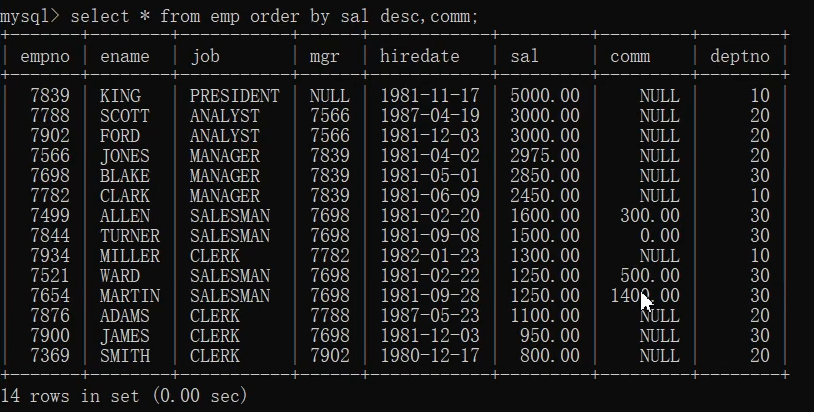
十二、limit语句
limit从索引为0开始取数据

案例:

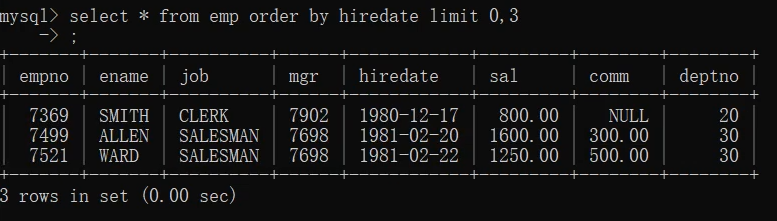
1.select * from emp order by hiredate;
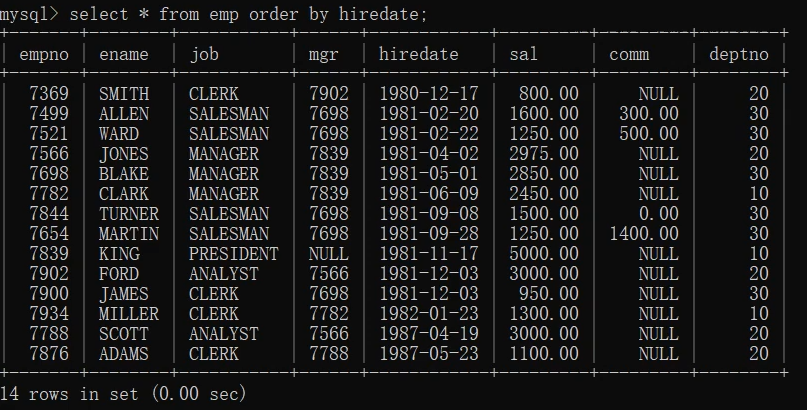
取前三条记录(即入职时间最早的)
select * from emp order by hiredate limit 3;
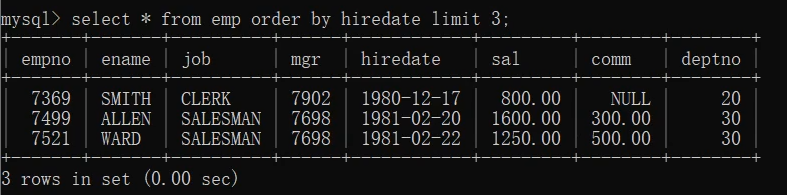
limit从索引为0开始取数据,结果一样
其中0,3 (0表示从索引为0开始,3为取出3条记录)
公式规律如下
limit (page-1)*pageSize,pageSize
十三、多表查询操作
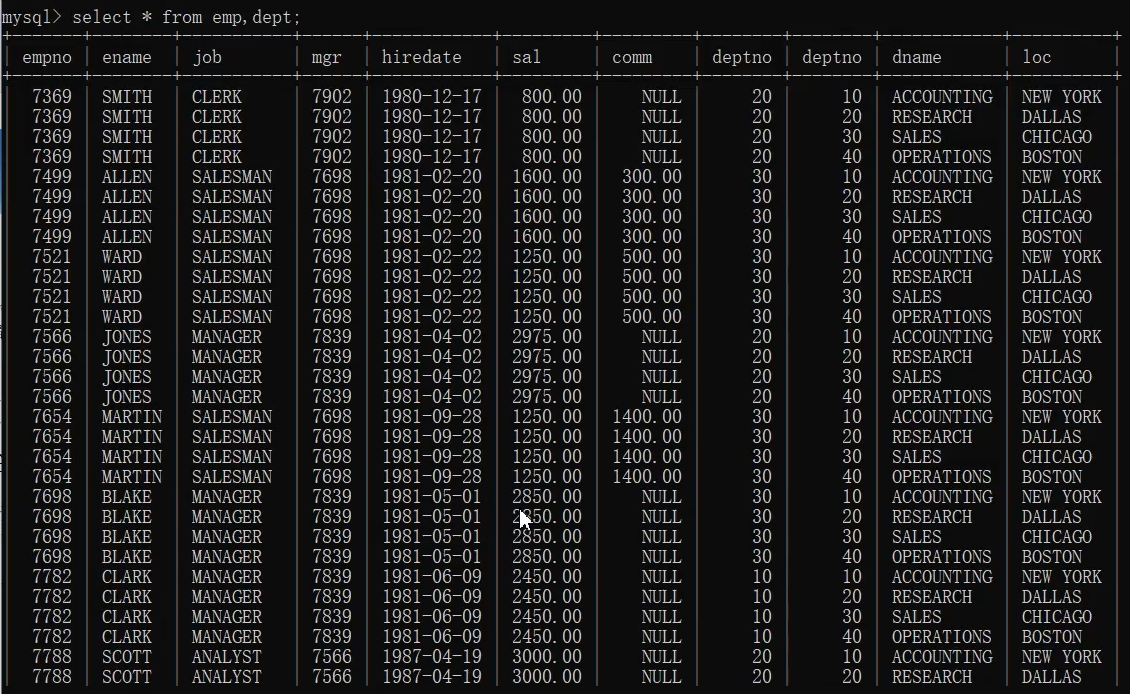
- select * from emp,dept;
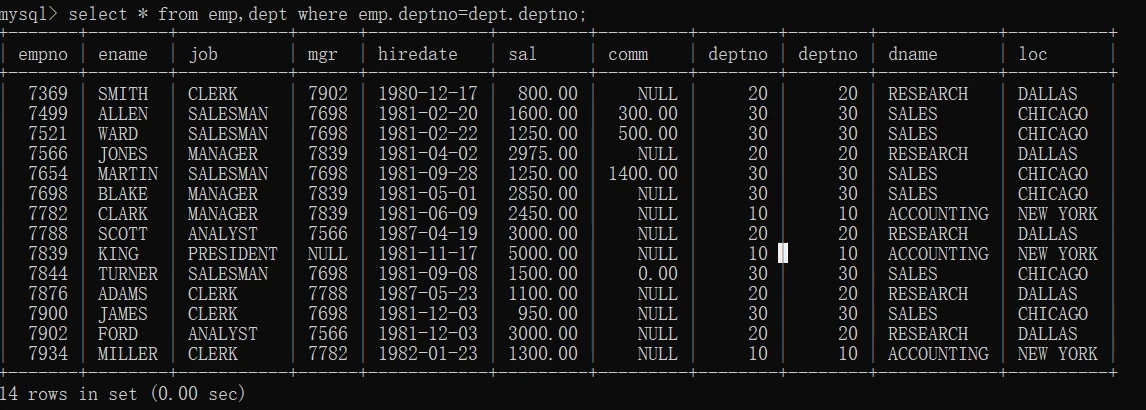
- select * from emp,dept where emp.deptno=dept.deptno;
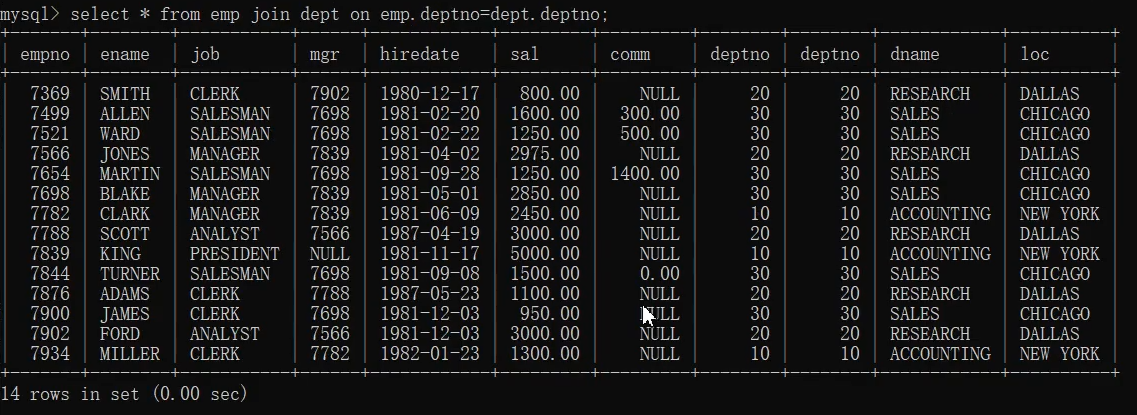
- select * from emp join dept on emp.deptno=dept.deptno;(这里的join是内连接)
十四、join内连接和外连接

create table stu_score(
id int auto_increment primary key,
sid varchar(50) not null,
score double(5,1) not null
);
double的使用方式:
在 DECIMAL 数据类型中,括号中的两个数字分别表示精度和标度。
- 精度 (precision):指的是数字的总位数,包括小数点前和小数点后的位数。
- 标度 (scale):指的是小数点后的位数。
所以在 DECIMAL(5, 1) 中,5 表示总共可以有的数字位数(包括小数点前后),1 表示小数点后的位数。这意味着这个字段可以存储总共 5 位数字,其中包括 1 位小数。
insert into stu_score values(null,'S_1001',66.0),
(null,'S_1002',90.5),
(null,'S_1003',85.0),
(null,'S_1004',80.0),
(null,'S_1005',70.0),
(null,'S_1006',99.0);
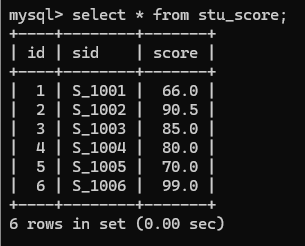
1.查询有sid学生的成绩
select stu.sid,stu.sname,stu_score.score from stu join stu_score on stu.sid=stu_score.sid;

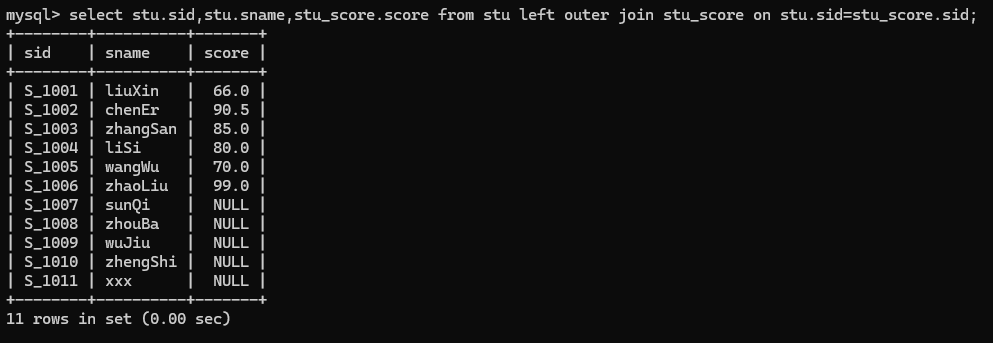
2.查询stu表(join的前表)所有学生的成绩(无论是否有成绩,即是否为NULL)
select stu.sid,stu.sname,stu_score.score from stu left outer join stu_score on stu.sid=stu_score.sid;
其中outer可写可不写
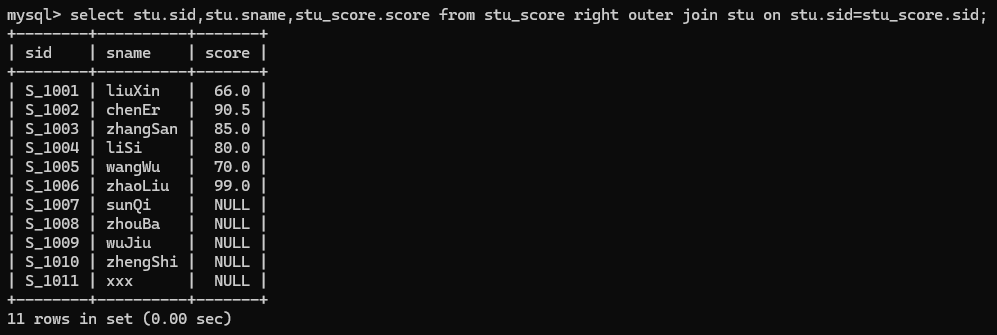
2.查询stu表(join的后表)所有学生的成绩(无论是否有成绩,即是否为NULL)
select stu.sid,stu.sname,stu_score.score from stu_score right outer join stu on stu.sid=stu_score.sid;
其中outer可写可不写
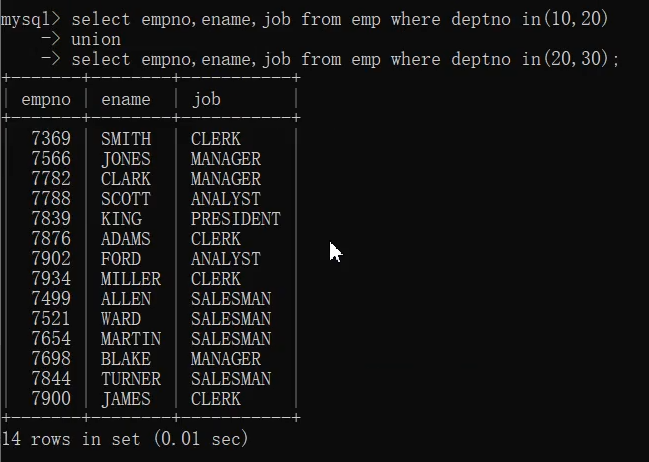
十五、union和union all
union会进行去重,而union all不会进行去重

案例:

- select empno,ename,job from emp where deptno in(10,20)
-> union
-> select empno,ename,job from emp where deptno in(20,30);
- select empno,ename,job from emp where deptno in(10,20)
-> union all
-> select empno,ename,job from emp where deptno in(20,30);

十六、索引的创建
1. 索引的创建规则


案例:
create index index_cust on customers(cust_name,cust_id);

2. 建表时建立索引

案例:
create table seller(
-> seller_id int not null auto_increment,
-> seller_name varchar(50) not null,
-> seller_address char(50),
-> seller_contact char(50),
-> product_type int(5),
-> sales int,
-> primary key(seller_id,product_type),
-> index index_seller(sales)
-> );

3. 修改表时添加索引

案例:
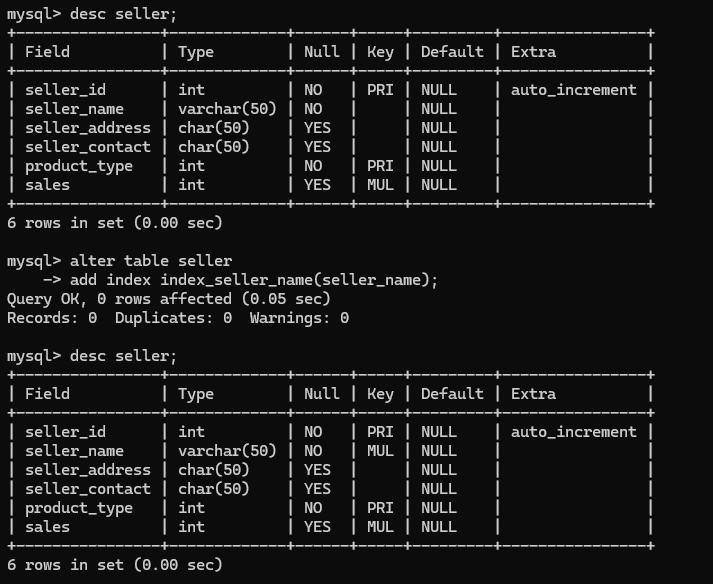
alter table seller
-> add index index_seller_name(seller_name);

十七、索引的查看


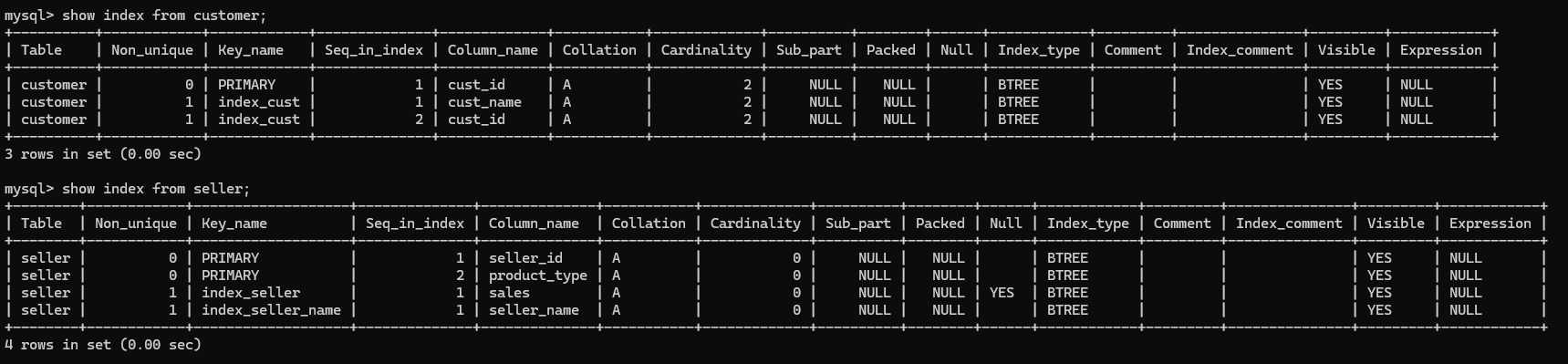
1.查看表中索引
show index from customer;
show index from seller;
十八、创建视图



案例:
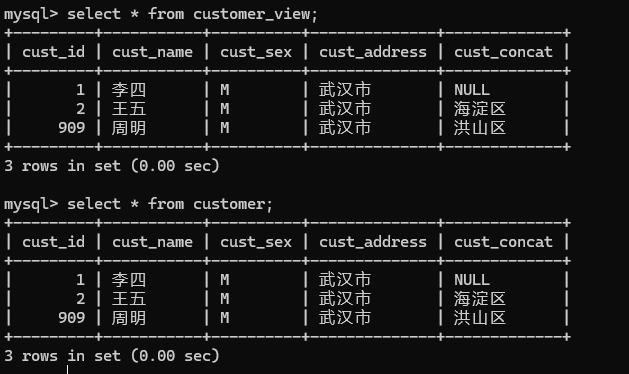
1. 创建视图
create or replace view customer_view
-> as
-> select * from customer where cust_sex='M'
-> with check option;

2. 查看创建的视图
show create view customer_view;

十九、删除视图&修改视图
1. 删除视图语法
drop view customer_view;


2. 修改视图
修改视图的语法和创建视图的语法类似,就是将create改为alter

二十、修改视图数据

案例:

1.insert into customer_view values(909,'周明','M','武汉市','洪山区');
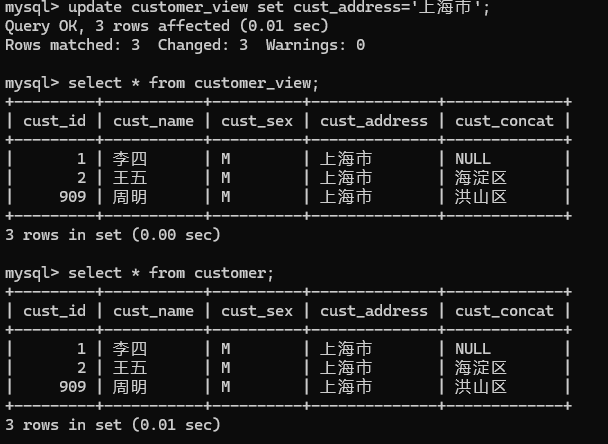
2.update customer_view set cust_address='上海市';
如果是update customer_view set cust_sex='F';将会报错,因为customer_view视图创建时就定义了select条件select * from customer where cust_sex='M',并且还有with check option,需要和原二维表格式相同
![]()
3.delete from customer_view where cust_name='周明';
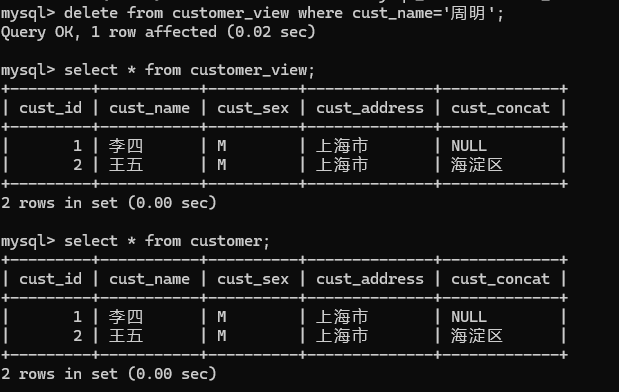
二十一、查询视图&对视图的说明

案例:

1.select * from customer_view where cust_id=901;
select cust_name cust_address from customer_view where cust_id=901;
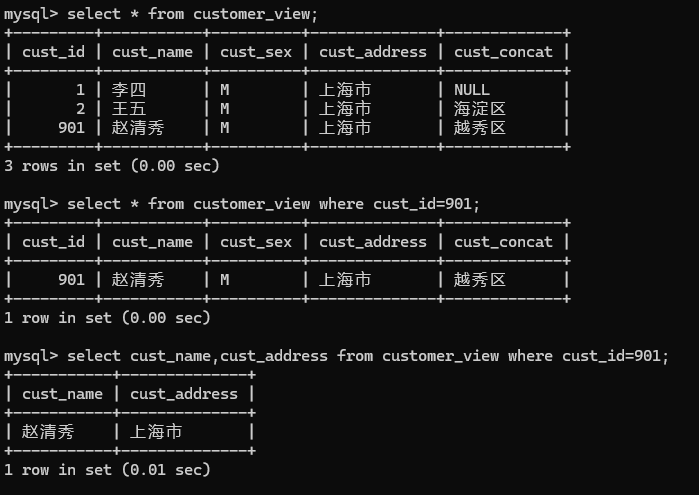
二十二、实体完整性



二十三、参照完整性(引用完整性)
create table stu_scores(
-> id int auto_increment primary key,
-> sid char(6),
-> score decimal(4,1),
-> foreign key(sid) references stu(sid));
也可以在修改表时添加外键:
alter table stu_scores add foreign key(sid) references stu(sid);
其中使用外键的那个属性(字段)必须是被引用表的主键才能进行参照完整性约束,否则创建失败
如果说这里stu表中的sid属性不是为primary key主键的话就先要将sid设置为primary key主键
alter table stu add primary key(sid);
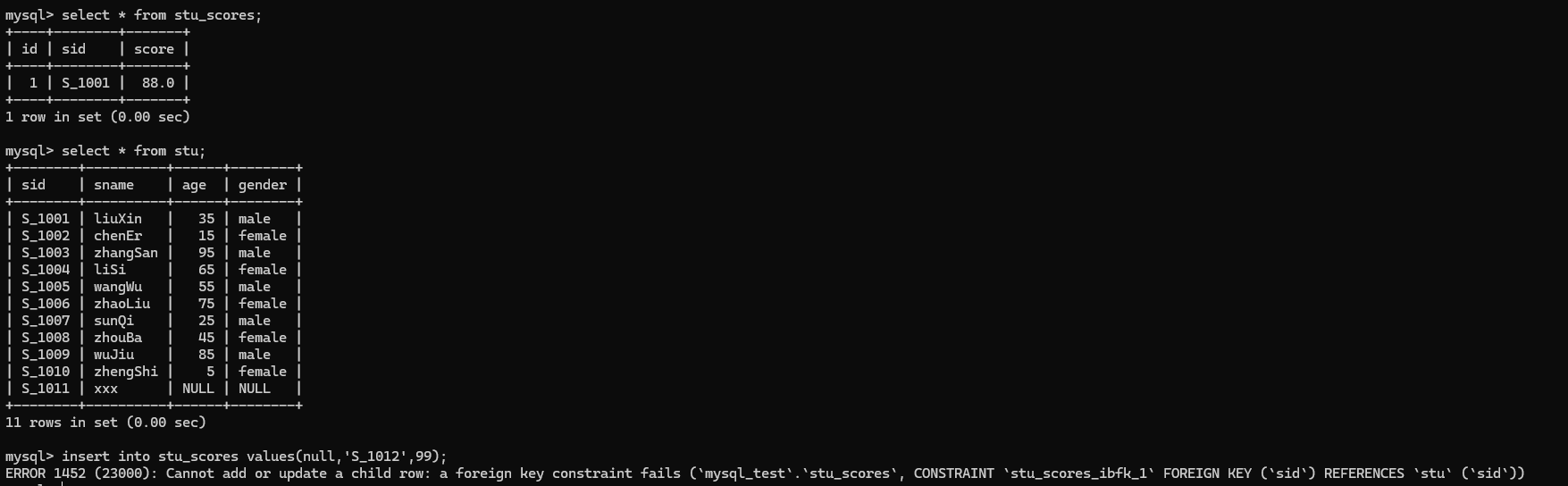
这里如果在stu_scores表中插入insert into stu_scores values(null,'S_1001',88);是可以插入成功的,因为在stu表中是有sid为S_1001的元素;但如果插入insert into stu_scores values(null,'S_1012',99);就会报错,ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`mysql_test`.`stu_scores`, CONSTRAINT `stu_scores_ibfk_1` FOREIGN KEY (`sid`) REFERENCES `stu` (`sid`)),因为在stu表中不含有sid为S_1012的元素
案例:
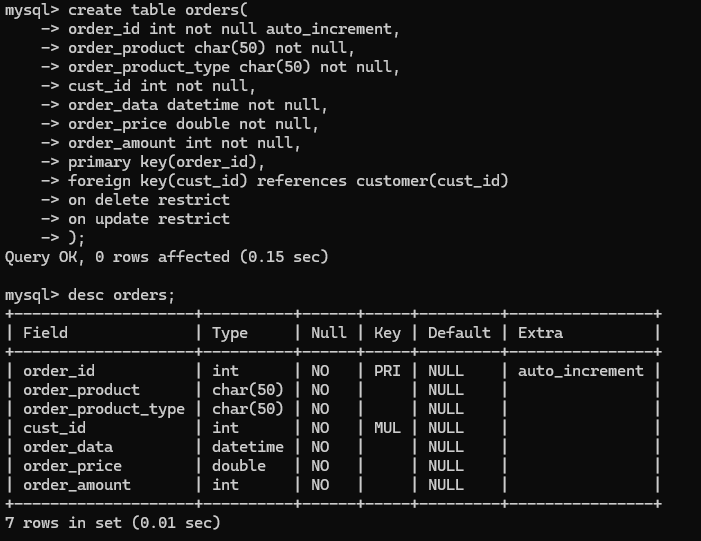
create table orders(
-> order_id int not null auto_increment,
-> order_product char(50) not null,
-> order_product_type char(50) not null,
-> cust_id int not null,
-> order_data datetime not null,
-> order_price double not null,
-> order_amount int not null,
-> primary key(order_id),
-> foreign key(cust_id) references customer(cust_id)
-> on delete restrict
-> on update restrict
-> );
on delete restrict 保证被引用表customer的元素不可被删除
on update restrict 保证被引用表customer的元素不可被更改

二十四、用户定义的完整性

二十五、更新完整性约束


二十六、表维护语句
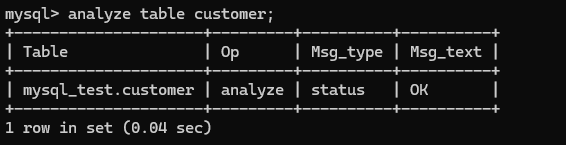
1. analyze table维护语句
analyze table tablename;

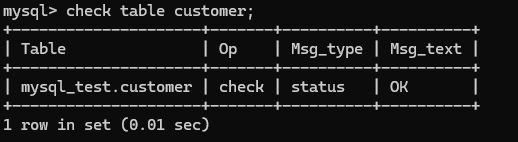
2. check table语句
check table tablename;

3. checksum table语句
checksum table tablename;


4. optimze table语句
optimize table tablename;


5. repair table语句
repair table tablename;


二十七、触发器概述及使用



案例:
1. 创建触发器
create trigger customer_insert_trigger after insert
-> on customer
-> for each row
-> set @str='one customer added!';
如果当前已经是mysql_test中就可以省略书写

2. 在创建好触发器后再次向customer表中插入数据
insert into customer values(null,'万华','F','长沙','芙蓉区');
3. 检验是否已经触发了触发器
select @str

4. 查看触发器
show triggers from mysql_test[db_name];

5. 删除触发器
drop trigger [if exists] [db_name.]trigger_name;

二十八、事件
事件和触发器的区别:
事件是基于特定时间周期触发来执行某些任务;
而触发器是基于某个表所产生的事件触发的
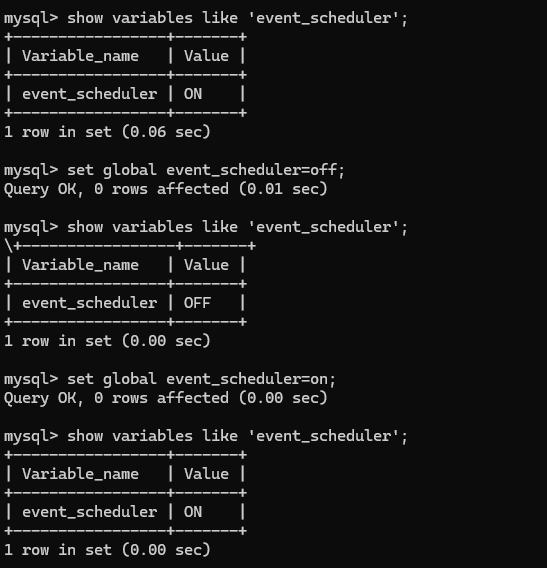
1. 查看EVENT_SCHEDULER的方法
show variables like 'EVENT_SCHEDULER' 或 select @@EVENT_SCHEDULER
2. 开启的方式
set global event_scheduler=1;
或set global event_scheduler=on;
创建事件


案例:
delimiter $$(意思是看到end $$才表示下面语句结束,而不是看到 ; 就结束)
create event if not exists event_insert
-> on schedule every 1 month
-> starts curdate()+interval 1 month
-> ends '2025-12-31'
-> do
-> begin
-> if year(curdate())=2024 then
-> insert into customer values(null,'周俊','M','北京市','海淀区');
-> end if;
-> end $$


二十九、创建存储过程

案例:
1. 创建存储过程
delimiter $$
create procedure sp_update_sex(in cid int,in csex char(1))
-> begin
-> update customer set cust_sex=csex where cust_id=cid;
-> end $$

2. 查看数据库中的存储过程
show procedure status;
3. 查看某个存储过程的具体信息
show create procedure sp_name;
三十、存储过程体




案例:

创建游标过程
create procedure sp_sumfrow(out total_rows int)
delimiter $$
begin
declare cid int;
declare found boolean default true;
declare cur_cid cursor for
select cust_id from customer;
declare continue handler for not found
set found=false;
set total_rows=0;
open cur_cid;
fetch cur_cid into cid;
while found do
set total_rows=total_rows+1;
fetch cur_cid into cid;
end while;
close cur_cid;
end $$
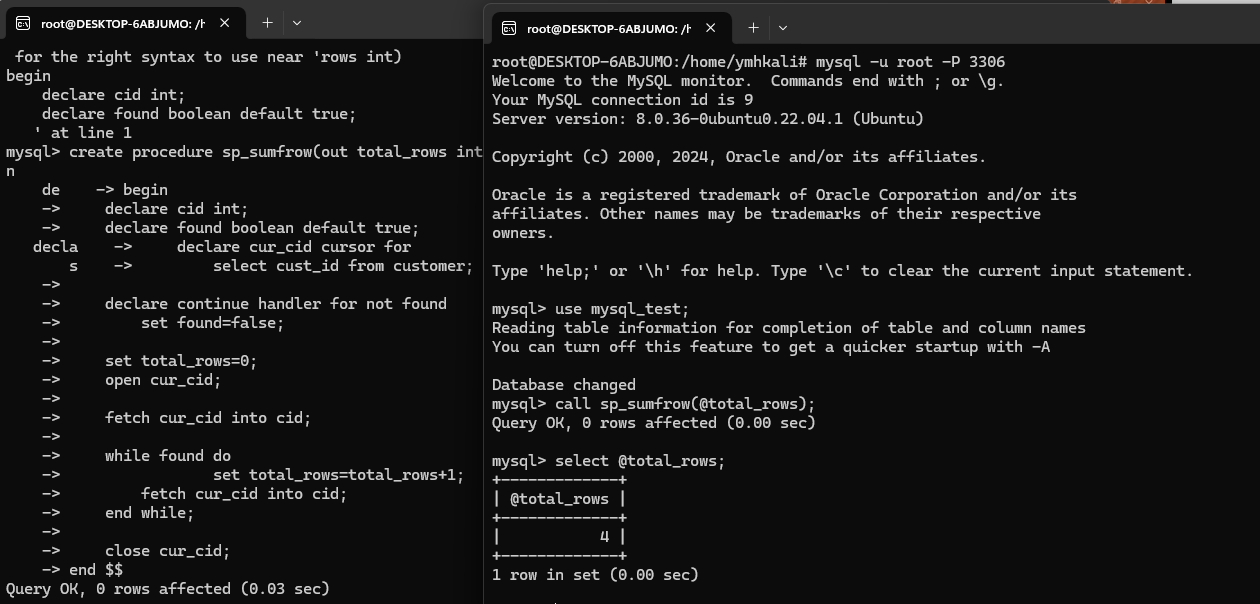
调用存储函数
call sp_sumfrow(@total_rows);
select @total_rows;
三十一、存储过程的调用、修改、删除

三十二、存储函数
1. 创建存储函数


案例:
delimiter $$
create function fu_search(cid int)
returns char(20)
deterministic
begin
declare sex char(2);
select cust_sex into sex from customer where cust_id=cid;
if sex is null then
return (select '没有该客户');
else if sex='F' then
return (select '女');
else
return (select '男');
end if;
end if;
end $$

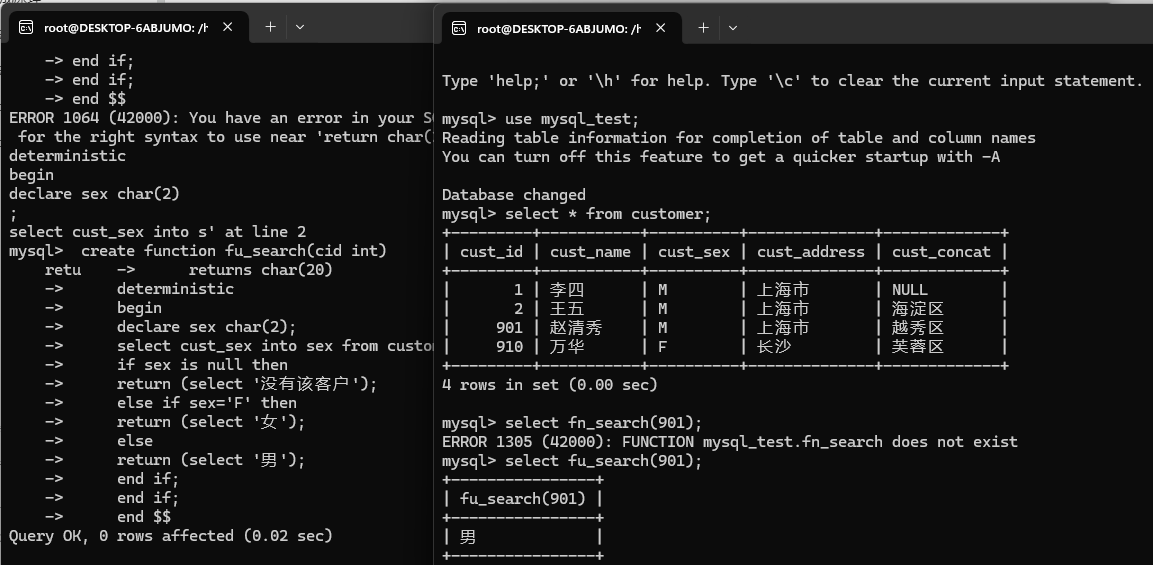
2. 查看数据库中有哪些存储函数
show function status;
3. 查看某个具体的存储函数
show create function sp_name;

4. 调用存储函数
select sp_name([func_paramater[,...]]);
5. 删除存储函数
drop function [if exists] sp_name;
6. 修改存储函数
alter function sp_name [characteristic];
三十三、用户账户管理

案例:
1. 添加用户及密码
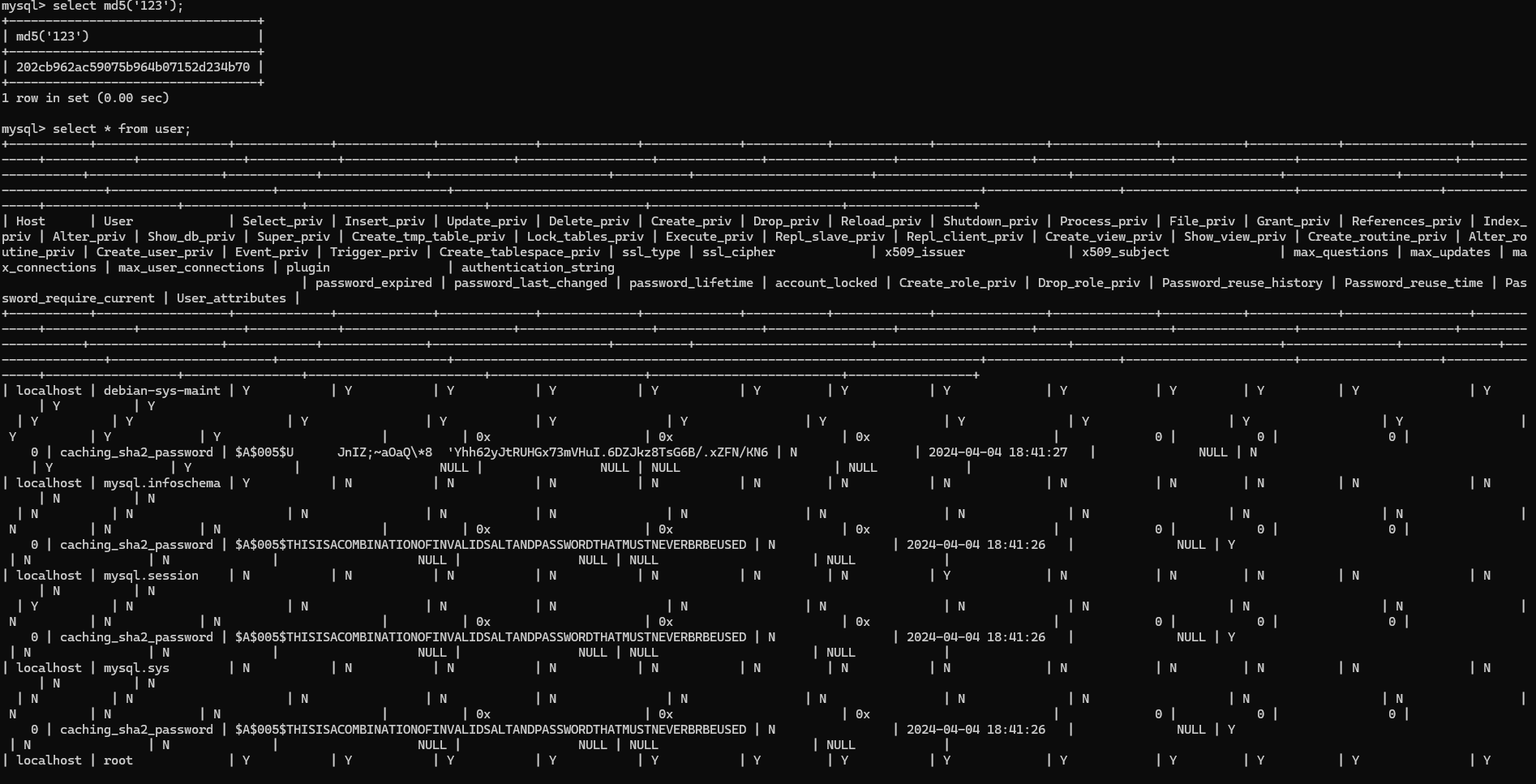
select md5('123');
create user 'zhangsan'@localhost identified by '123',
-> 'lisi'@localhost identified by '202cb962ac59075b964b07152d234b70';
select * from user;
2. 删除用户
drop user zhangsan@localhost;
select * from user;
3. 修改用户密码
修改用户的权限应该为@'%',而不是@localhost,否则无法进行修改
create user 'zhangsan'@'%' identified by '123';
rename user zhangsan to zhangfeng;
select * from user;
- 修改用户口令
select md5('hello');
set password for zhangfeng@'%'='5d41402abc4b2a76b9719d911017c592';
select * from user;

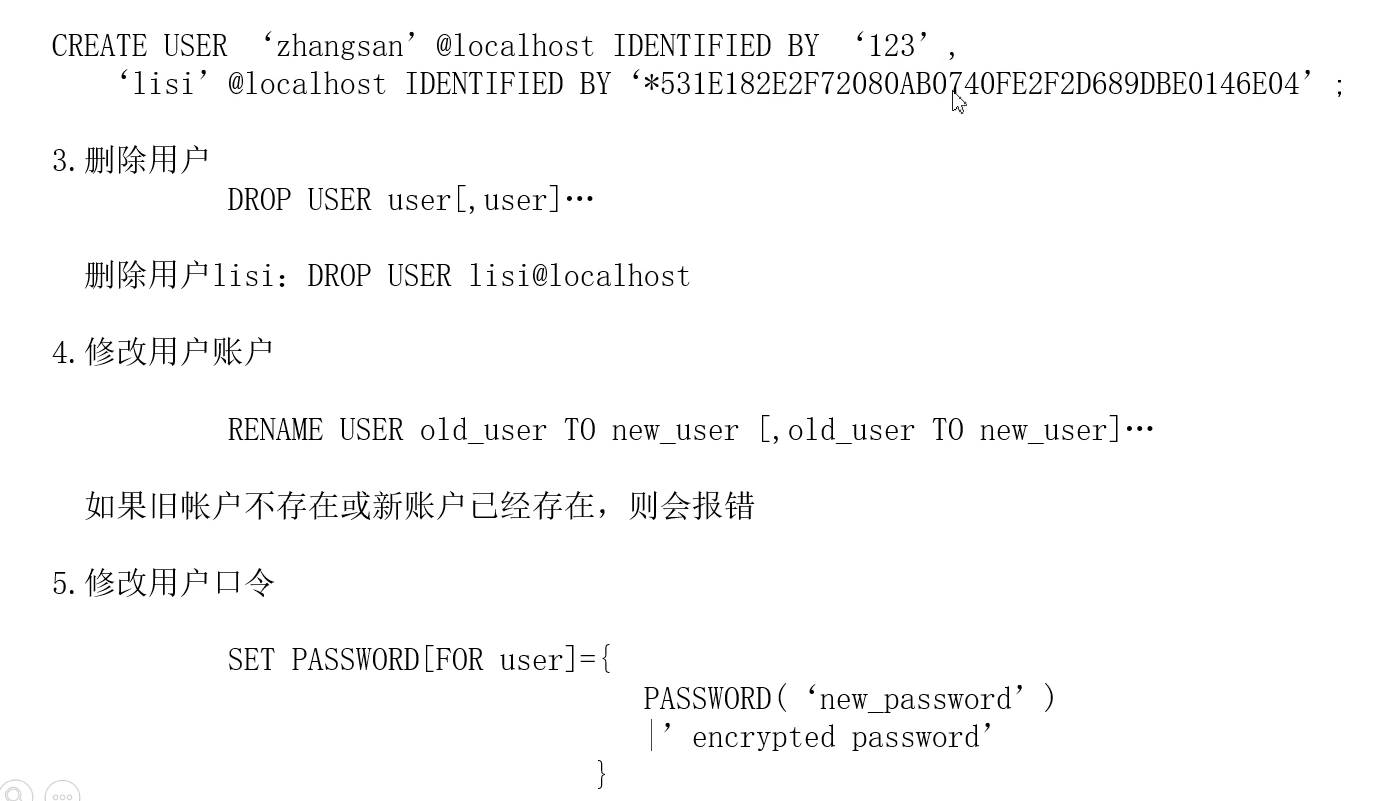
三十四、权限的授予



三十五、权限的转移与限制

三十六、权限的撤销


三十七、使用SQL语句实现数据备份与恢复
1. 数据的备份

2. 数据的恢复

案例:

















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









