






进程的创建
我们知道fork()可以用来创建子进程
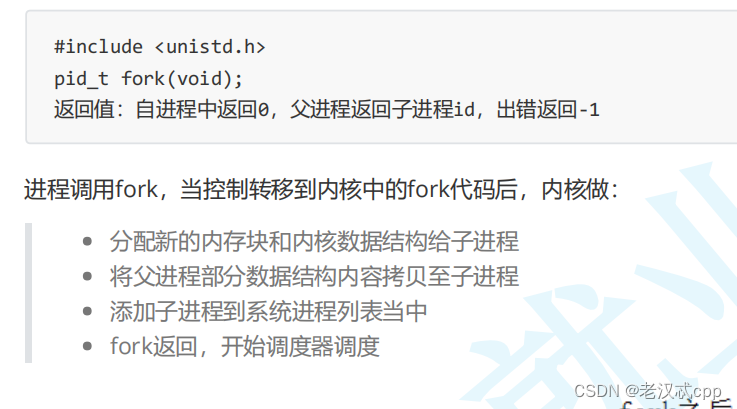
当我们执行fork()后,就会在内核空间帮我们申请内存,来创建子进程
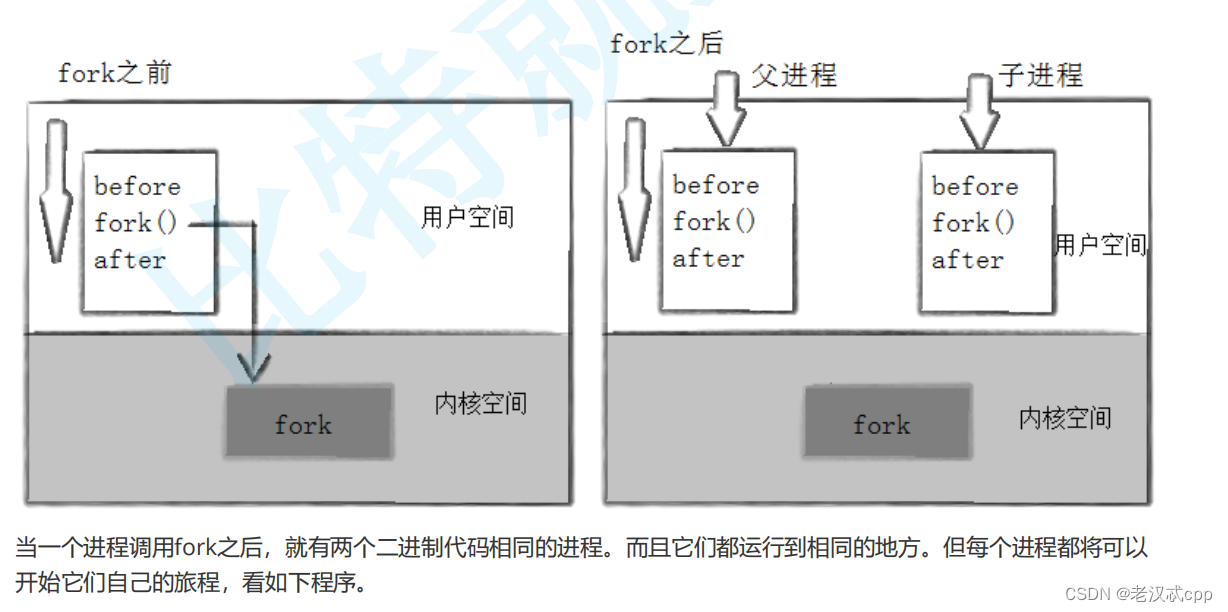
写时拷贝
当我们父进程创建完子进程后,页表中的内容会全部拷贝一份,但是父进程的页表中的物理地址的权限无论是读还是写,当拷贝进子进程的页表中后,都会变成只读权限。一般来说,当我们进行不被允许的权限操作时,操作系统会直接拦截,但是对于子进程要修改时,操作系统会先判断(缺页中断),然后再新分配一块内存空间给子进程进行重新映射,然后权限改为可读可写,这就是写时拷贝。
进程的退出(返回值和退出码)
我们知道,我们平常的main函数里总会返回一个0,这个返回值其实就是一个进程的结束码,0代表进程结果正确,非0代表结果不正确,不同的数字表示不同的错误原因。在Linux下,我们可以用echo $? 命令来查看上个进程的结束码。
系统提供的退出码包含头文件#include<string.h>,我们也可以不用系统提供的,可以自己定义一个字符串数组也可以。
所以进程结束后结果正不正确我们统一看进程结束的返回值。

在我们程序中,如果调用exit(),这个括号中的数字就是我们程序的退出码。
return和exit的区别
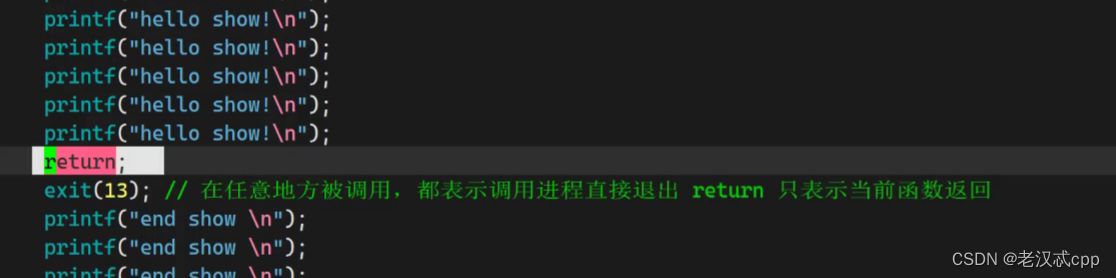
return只是表明该函数退出并返回,而exit则表示调用进程直接退出。
return只是在main函数中表示进程退出。
_exit和exit
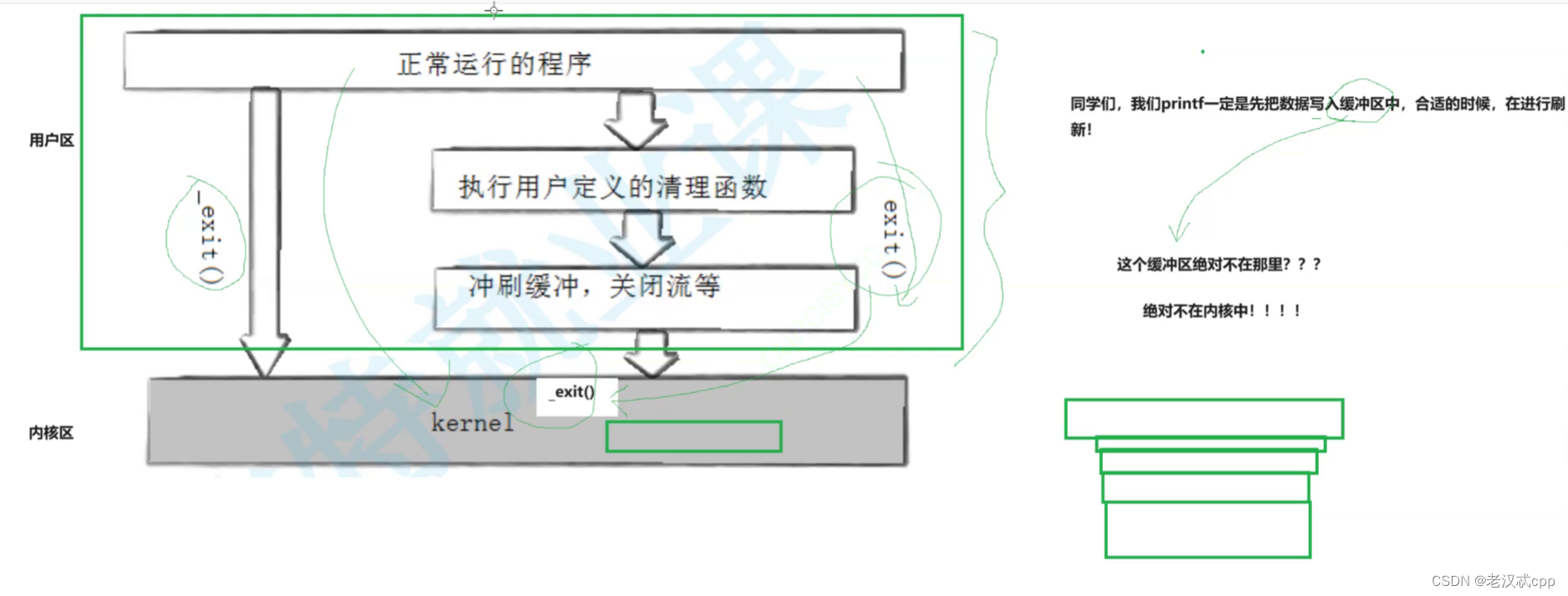
_exit()是系统调用,exit()是C提供的函数,它们的区别是,exit()会先刷新缓存区的数据,比如通过printf写入缓存区的数据,在合适的时期打印在屏幕上(比如用\n或这程序退出),将它刷新并打印在屏幕上,然后再终止程序;而_exit()则会直接终止程序,对缓冲区的数据不做处理。
另外,缓存区绝对不会在内核区中。因为我们知道,操作系统不会做任何浪费空间的事情,如果缓存区在内核区,那么_exit()也必须要把数据刷新,那跟exit()就没有什么区别了。
进程异常退出
进程出现异常,本质是进程收到了对应的信号。
进程等待
当一个进程变成僵尸进程后,那么就会导致内存泄漏,用kill都杀不掉,只能用进程等待来杀掉

wait
简单代码演示:
 在父进程中用wait函数,然后用pid_t类型的变量接收子进程的pid之后,就能把子进程杀掉。
在父进程中用wait函数,然后用pid_t类型的变量接收子进程的pid之后,就能把子进程杀掉。
其中如果有多个子进程,wait只等待任意一个。如果有多个子进程,我们也可以用for循环的方式等待掉所有子进程。
但是假设子进程还没有退出,父进程已经执行到了wait语句呢?那么子进程会照旧进行,而父进程会卡在wait语句,形成阻塞状态,之前我们知道硬件会造成阻塞状态,现在我们知道软件也能造成阻塞状态。
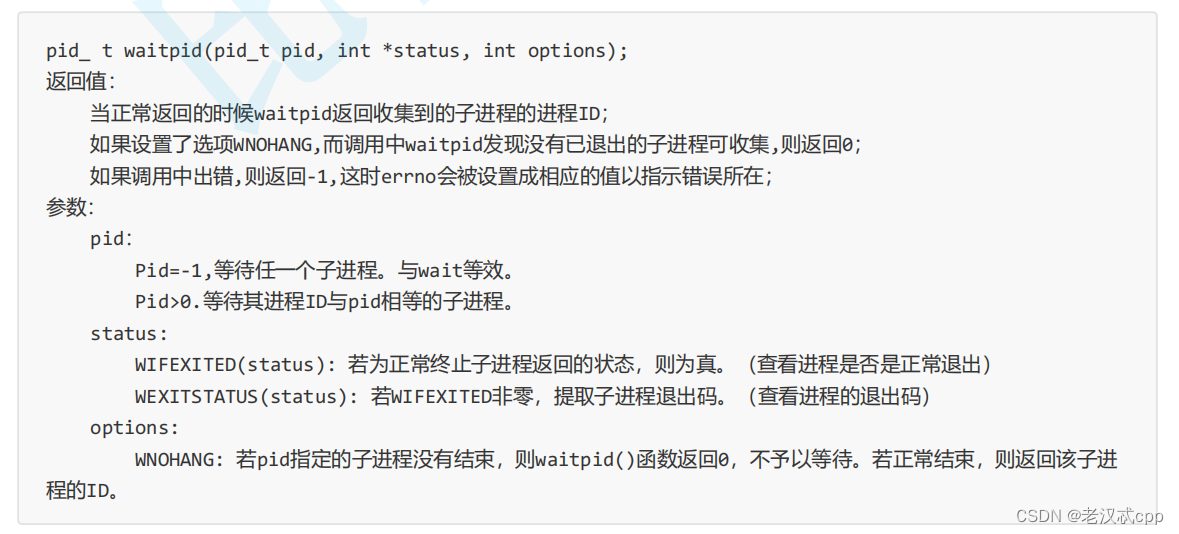
waitpid
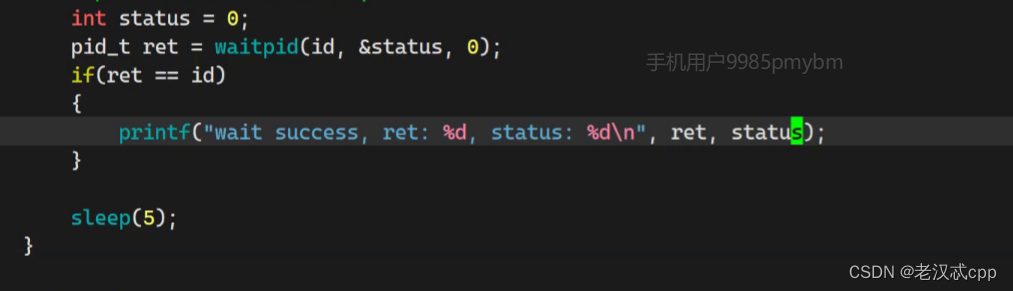 其中status是一个输出型参数,它是用来接收子进程的执行结果的。
其中status是一个输出型参数,它是用来接收子进程的执行结果的。
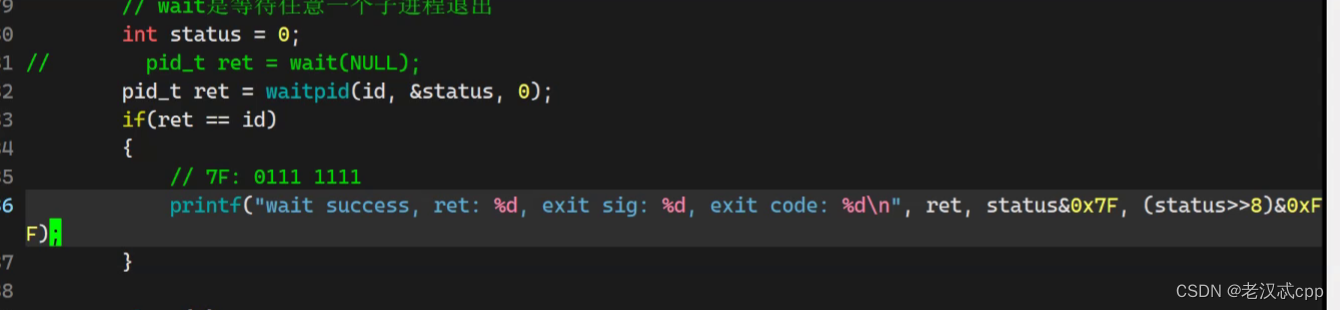
但是当我们执行这个代码打印出来的结果是这样的
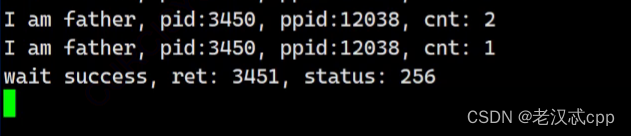
为什么这个status不是我们想象的那个结果呢?
这是因为 int被分成了好几个部分。
首先我们知道,子进程退出无外乎三个场景,我们把status分成好几个部分,不就能把所有情况全部考虑到吗?
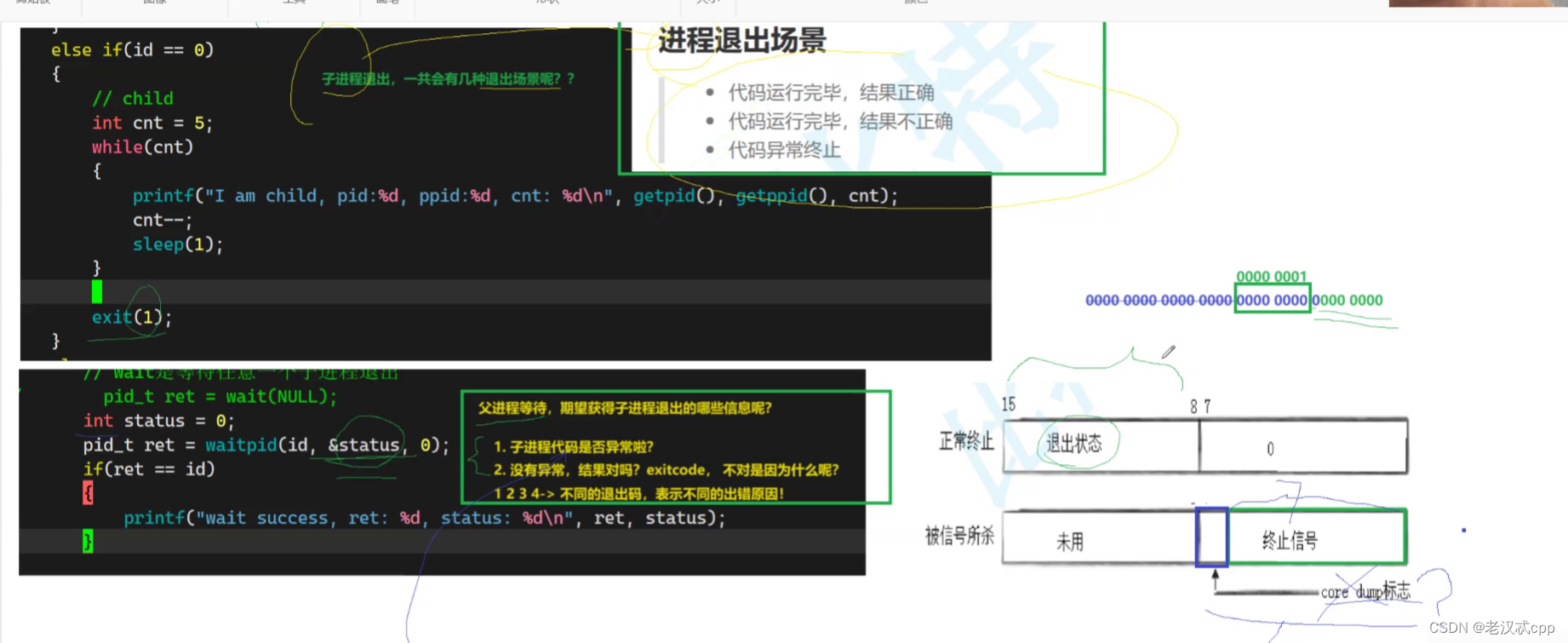
如上图,我们可以通过前七个bit位来 判断子进程的代码是否跑完(终止信号)。然后图中的八个bit位来表示返回码,这就解释了为什么是256
现在我们知道了这个返回值status是分了好几个部分的,那么我们可以用以下方法来打印部分信息
但是这样打印太麻烦了,系统给我们提供了两个宏来帮助我们打印。

使用如下
 总结:
总结:

操作系统的进程其实也是一个多叉树的关系,父进程只对子进程负责,爷孙之间没有任何关系。通过进程等待我们对以前写的main函数的return 0也有了些许理解,其实也是将这个返回值给父进程,让父进程接收这个信息来对后续操作决策方向。
之前我们了解到,如果父进程等待一个子进程,那么父进程会进入阻塞状态,这时waitpid的第三个参数如果传的是WNOHANG这个宏的话,如果子进程没有结束,则这个函数就返回0,并且不会再等待,父进程会直接做后边自己的事情。当然我们也可以用一个循环来反复等待,但是也能做循环里面的事情,这个叫做非阻塞轮询 。
父进程等待的时候可做的事情
在等待子进程退出的时候,我们可以安排父进程做一些轻量化的任务,并且通过封装函数的方式对代码进行解耦
如下,task1-3就是代表一些轻量化的任务。
程序替换
替换原理
程序替换与fork不同,fork是创建一个子进程,而程序替换就是直接将程序和数据在物理内存上进行了替换。因为这并不是创建一个新进程,所以这个进程的id不变。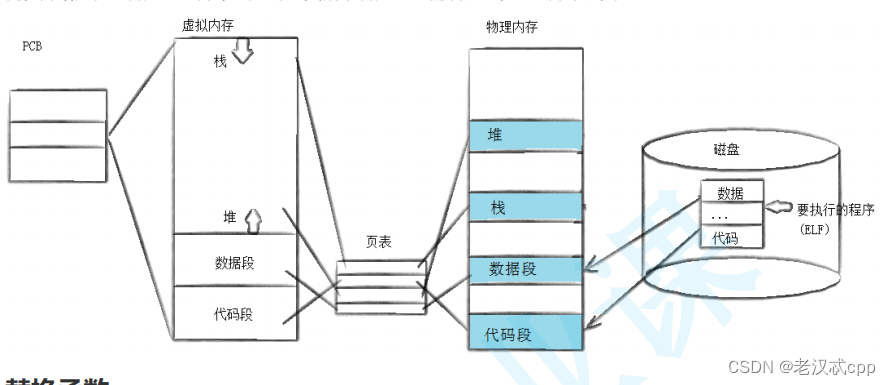
替换函数
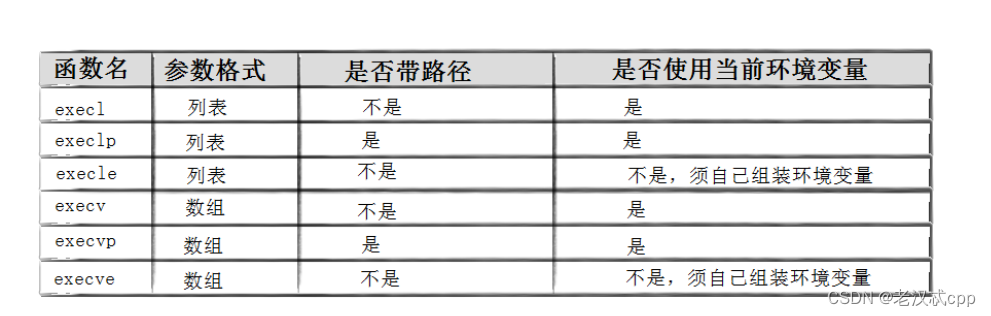
一共有六种替换函数 exec*()函数。
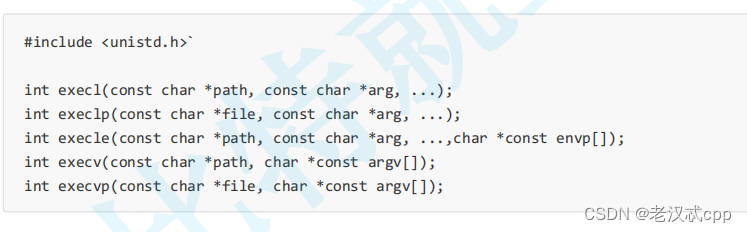
为方便理解记忆如下:
// 这类方法的标准写法
execl("/usr/bin/ls", "ls", "-a", "-l", NULL);
execlp("ls", "ls", "-a", "-l", NULL);
execl("/usr/bin/top", "top", NULL);
execv("/usr/bin/ls", myargv);
execvp("ls", myargv);l:可以理解为list,需要我们把调用的方式及参数都写出来。l表示参数用列表
p:可以理解为path,就是说这个exec可以直接到我们的环境变量中找这个命令。没有p就需要我们自己把这个程序的路径写上。有p就不用带路径,没有就要我们自己把路径写上。
v:理解为vector,数组,也就是我们可以提前先创建一个字符串指针数组,并把我们要传的都放在数组里,调用的时候就传这个数组就好了。v表示参数用数组。
char*const myargv[] = {
"otherExe",
"-a",
"-b",
"-c",
NULL
};这些都可以组合使用,达到组合的效果,但要注意顺序。
最后一个是e
e:就是env,也就是环境变量,如果有这个就说明我们需要自己组装环境变量。我们知道子进程会继承父进程的环境变量,我们可以自己创建一个环境变量表然后将其传入,这样我们可以使子进程拥有自己的环境变量。
char *const myenv[] = {
"MYVAL=1111",
"MYPATH=/usr/bin/XXX",
NULL
};记住 l与v不能同时存在。
以上六个函数都是在第三号手册上,都是库函数,它们的区别都是传参不同。
还有一个exec在第二号手册,他就是execve,它是由操作系统提供的。
它们之间的关系就是,以上六个exec函数都调用execve,来完成程序替换操作。
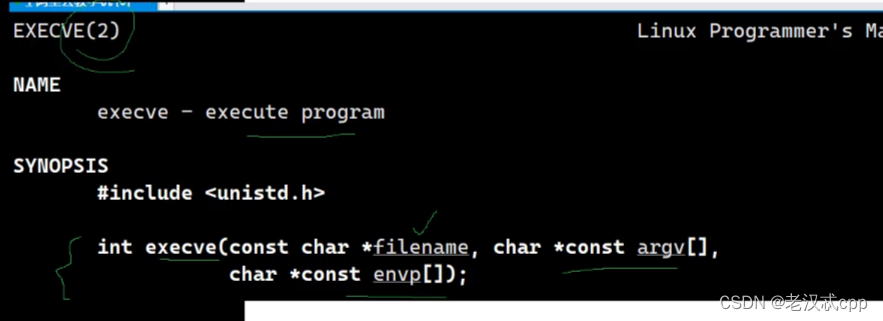
程序替换后的最后一个参数必须是NULL。NULL是程序替换的结束标志,不加NULL程序可能会出现未知错误。
函数解释
如果exec函数调用成功,则它会直接加载新的程序,没有返回值。
如果exec函数调用失败,如传入了错误的参数,那么就会失败且返回-1。
也就是exec成功没有返回值,只有失败才有返回值。

Shell的简单模拟
通过之前的学习,我们知道了,我们在linux下输入的指令都是在命令行上输入的,这个命令行是由bash这个父进程接收,然后创建子进程来执行我们的命令(内建命令除外)。
模拟实现
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <assert.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#define LEFT "["
#define RIGHT "]"
#define LABLE "#"
#define DELIM " \t"
#define LINE_SIZE 1024
#define ARGC_SIZE 32
#define EXIT_CODE 44
int lastcode = 0;
int quit = 0;
extern char **environ;
char commandline[LINE_SIZE];
char *argv[ARGC_SIZE];
char pwd[LINE_SIZE];
// 自定义环境变量表
char myenv[LINE_SIZE];
// 自定义本地变量表
const char *getusername()
{
return getenv("USER");
}
const char *gethostname()
{
return getenv("HOSTNAME");
}
void getpwd()
{
getcwd(pwd, sizeof(pwd));
}
void interact(char *cline, int size)
{
getpwd();
printf(LEFT"%s@%s %s"RIGHT""LABLE" ", getusername(), gethostname(), pwd);
char *s = fgets(cline, size, stdin);
assert(s);
(void)s;
// "abcd\n\0"
cline[strlen(cline)-1] = '\0';
}
int splitstring(char cline[], char *_argv[])
{
int i = 0;
argv[i++] = strtok(cline, DELIM);
while(_argv[i++] = strtok(NULL, DELIM)); // 故意写的=
return i - 1;
}
void NormalExcute(char *_argv[])
{
pid_t id = fork();
if(id < 0){
perror("fork");
return;
}
else if(id == 0){
//让子进程执行命令
//execvpe(_argv[0], _argv, environ);
execvp(_argv[0], _argv);
exit(EXIT_CODE);
}
else{
int status = 0;
pid_t rid = waitpid(id, &status, 0);
if(rid == id)
{
lastcode = WEXITSTATUS(status);
}
}
}
int buildCommand(char *_argv[], int _argc)
{
if(_argc == 2 && strcmp(_argv[0], "cd") == 0){
chdir(argv[1]);
getpwd();
sprintf(getenv("PWD"), "%s", pwd);
return 1;
}
else if(_argc == 2 && strcmp(_argv[0], "export") == 0){
strcpy(myenv, _argv[1]);
putenv(myenv);
return 1;
}
else if(_argc == 2 && strcmp(_argv[0], "echo") == 0){
if(strcmp(_argv[1], "$?") == 0)
{
printf("%d\n", lastcode);
lastcode=0;
}
else if(*_argv[1] == '$'){
char *val = getenv(_argv[1]+1);
if(val) printf("%s\n", val);
}
else{
printf("%s\n", _argv[1]);
}
return 1;
}
// 特殊处理一下ls
if(strcmp(_argv[0], "ls") == 0)
{
_argv[_argc++] = "--color";
_argv[_argc] = NULL;
}
return 0;
}
int main()
{
while(!quit){
// 1.
// 2. 交互问题,获取命令行
interact(commandline, sizeof(commandline));
// commandline -> "ls -a -l -n\0" -> "ls" "-a" "-l" "-n"
// 3. 子串分割的问题,解析命令行
int argc = splitstring(commandline, argv);
if(argc == 0) continue;
// 4. 指令的判断
// debug
//for(int i = 0; argv[i]; i++) printf("[%d]: %s\n", i, argv[i]);
//内键命令,本质就是一个shell内部的一个函数
int n = buildCommand(argv, argc);
// 5. 普通命令的执行
if(!n) NormalExcute(argv);
}
return 0;
}
注意点:我们对内建命令和普通命令是分别进行了处理。
另外对于export导入环境变量,我们需要进行特殊处理,因为环境变量表是一个指针,它指向这个环境变量,而_argv数组一旦被修改,这个环境变量就乱套了,所以还需要再专门弄一个环境变量的数组,把它存到这里面。
到这里,我们其实就理解了我们bash就是一个进程,以这种原理对我们的命令行参数进行解析,对于普通命令,它只需要创建一个子进程,然后在子进程中进行程序替换来达到完成这个程序,而父进程也就是bash它只需要等待子进程结束就可以了。
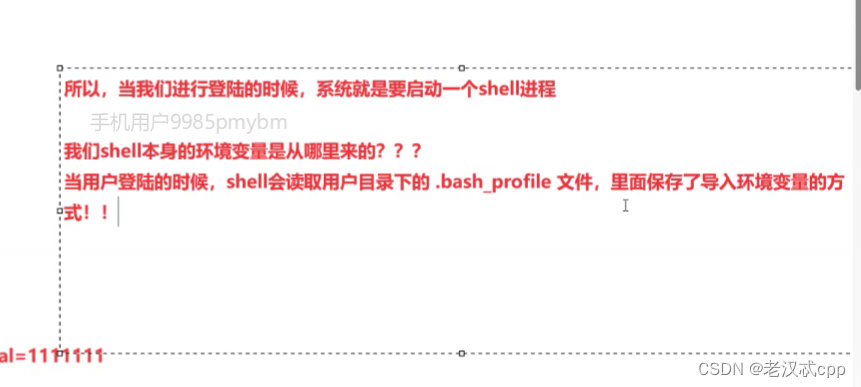
所以当我们进行登录的时候,系统就要启动一个shell进程。
shell本身的环境变量是在用户目录下的.bash_profile文件里,里面保存了导入环境变量的方式















 1911
1911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









