






 本文介绍了人工智能、机器学习和深度学习的基本概念、它们之间的关系,以及机器学习在各个领域的应用历史。文章还详细讲述了机器学习的关键要素和常用术语,包括样本、特征、标签、数据集划分、算法分类和建模流程。
本文介绍了人工智能、机器学习和深度学习的基本概念、它们之间的关系,以及机器学习在各个领域的应用历史。文章还详细讲述了机器学习的关键要素和常用术语,包括样本、特征、标签、数据集划分、算法分类和建模流程。
◆ 人工智能三大概 人工智能(AI)、机器学习(ML)和深度学习(DL)
1.1 学习目标
1.2 人工智能的概念
1.2.1 什么是人工智能?
人工智能(Artificial Intelligence,简称AI)是一种模拟人类智能的技术。它涉及使计算机系统能够执行需要人类智能的任务,例如学习、推理、问题解决、感知、语言理解等。人工智能的目标是创建能够模仿人类思维方式和行为的系统,使它们能够自主地执行复杂的任务,甚至能够学习和改进自己的性能。AI 的应用领域非常广泛,包括自然语言处理、计算机视觉、机器人技术、专家系统、智能推荐系统等。
1.2.2 AI的期望
人工智能的期望是通过模拟人类智能的方式,使计算机系统具有更高的智能水平和自主性,从而能够执行更加复杂和高级的任务
1.3 机器学习
1.3.1 什么是机器学习?
机器学习(Machine Learning,简称ML)是人工智能(AI)的一个子领域,它专注于研究如何使计算机系统能够从数据中学习和改进,而无需进行明确的编程。机器学习的核心思想是通过算法让机器从数据中学习模式和规律,然后利用这些知识来做出预测或决策。
1.3.2 机器如何学习
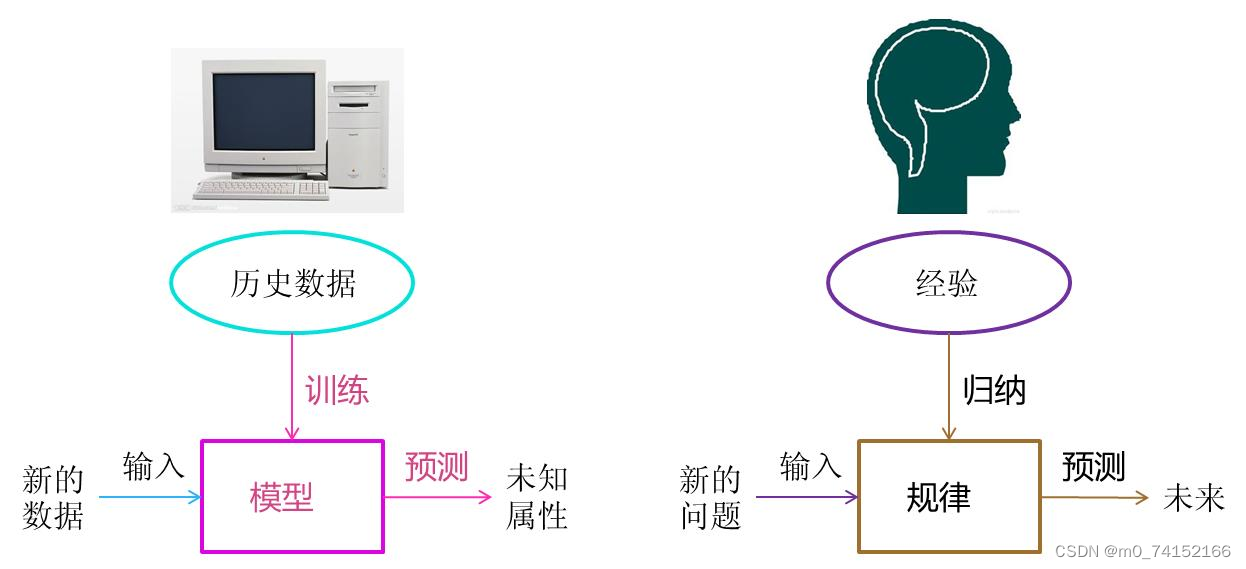
1.4 深度学习
1.5.1 什么是深度学习?
深度学习是机器学习的一个子领域,它基于神经网络的概念,特别是深度神经网络(Deep Neural Networks, DNNs)。深度学习模型通过模仿人脑的工作方式来处理数据,它们能够学习复杂的模式,并在许多任务中实现前所未有的性能,比如图像和语音识别、自然语言处理、自动驾驶汽车等。
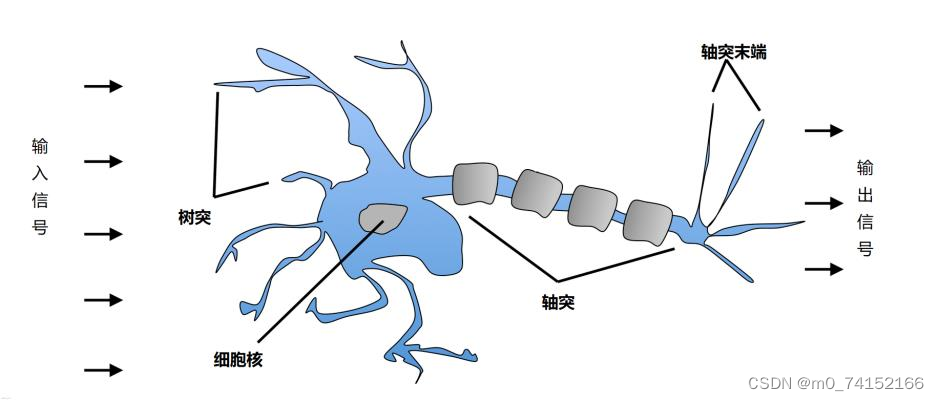
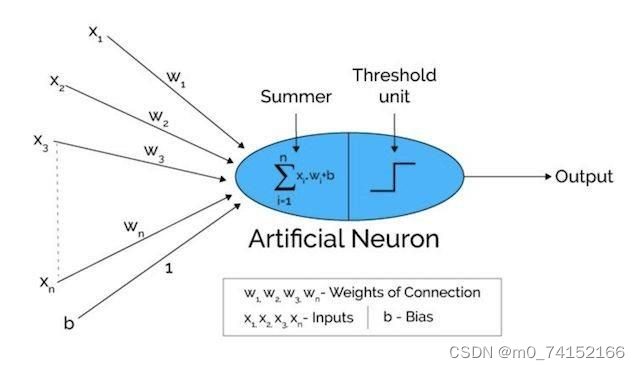
1.5 三者之间的关系
◆ 机器学习的应用领域和发展史
2.1 了解机器学习的应用领域
-
图像识别和分类:包括人脸识别、图像检索、物体识别等2。
-
自然语言处理:涉及机器翻译、文本分类、语音识别等24。
-
推荐系统:在电商、社交媒体等平台中用于商品推荐、内容推荐等2。
-
医疗诊断:应用于癌症诊断、疾病预测等2。
-
金融风控:包括欺诈检测、信用评估等2。
-
工业制造:用于质量控制、异常检测等2。
-
自动驾驶:涉及视觉感知、路况识别等24。
-
游戏智能:包括游戏AI、机器人足球等2。
-
网络安全:用于恶意代码检测、网络攻击识别等2。
-
环境保护:如气象预测、大气污染监测等2。
-
搜索引擎:机器学习用于提升搜索结果的相关性和准确性1。
-
军事决策:在战略规划和决策支持系统中发挥作用1。
-
数据挖掘:从大量数据中发现模式和知识1。
-
生物特征识别:用于个人身份验证,如指纹、虹膜扫描等1。
-
智能制造:在自动化生产线中进行预测性维护和优化生产流程2。
-
环境保护:用于气候模拟、生态系统分析等2。
-
人工智能助手:如智能手机中的虚拟助手,使用机器学习来更好地理解用户需求和提供个性化服务2。
-
文字识别(OCR):将图片或扫描件中的文字识别成可编辑的文本,提升业务效率
2.2 人工智能的发展史
人工智能(AI)的发展史是一个充满创新、挑战和不断进步的过程。从20世纪中叶到现在,AI经历了几个明显的阶段:
-
起步发展期(1943年—20世纪60年代):人工智能的概念首次在1956年的达特茅斯会议上被提出,这标志着人工智能学科的诞生。早期的研究集中在逻辑推理和问题解决上,出现了如“Logic Theorist”和“General Problem Solver”这样的程序123。
-
反思发展期(20世纪60年代—70年代初):在初期的乐观和投资之后,AI遭遇了第一次寒冬,因为一些宏伟的目标未能实现,导致了资金的减少和研究的停滞28。
-
应用发展期(20世纪70年代初—80年代中):专家系统的出现使得AI开始在特定领域得到应用,如医疗、地质等。这些系统能够模拟专家的决策过程,为AI的实际应用铺平了道路21。
-
低迷发展期(20世纪80年代中—90年代中):随着专家系统的限制逐渐显现,AI的发展进入了一段相对缓慢的时期,研究者开始探索新的方法和技术2。
-
稳步发展期(20世纪90年代中—2010年):互联网技术的发展推动了AI的创新研究,AI技术开始走向实用化。IBM的深蓝超级计算机在1997年战胜世界冠军棋手,成为AI发展的一个重要里程碑2。
-
蓬勃发展期(2011年至今):大数据、云计算、互联网和物联网的发展为AI提供了强大的数据和计算支持。深度学习技术的进步,特别是卷积神经网络(CNN)在图像识别和语音识别中的成功应用,推动了AI技术的飞速发展和广泛应用28。
-
当前和未来趋势:AI正从专用智能向通用智能发展,同时人机混合智能和自主智能系统也是研究的热点。AI与其他学科领域的交叉渗透日益加深,产业应用不断扩展,同时国际竞争也在加剧29。
2.3 机器学习发展三要素
机器学习的发展依赖于三个核心要素:算法(Algorithms)、数据(Data)和计算能力(Computation)。这三个要素共同推动了机器学习技术的进步和应用的广泛性。
-
算法(Algorithms):
- 算法是机器学习的核心,它们定义了数据输入和输出之间的处理规则。
- 早期的算法包括决策树、最近邻算法、线性回归等,而现代算法则包括深度学习中的卷积神经网络(CNN)、循环神经网络(RNN)、生成对抗网络(GAN)等。
- 算法的设计和优化是机器学习研究的一个重要方向。
-
数据(Data):
- 数据是机器学习的基础,算法通过数据进行训练和学习。
- 随着互联网和物联网技术的发展,数据量呈现爆炸式增长,为机器学习提供了丰富的训练材料。
- 数据的质量和多样性直接影响到机器学习模型的性能。
-
计算能力(Computation):
- 计算能力是实现机器学习算法的关键,特别是在处理大规模数据集和复杂模型时。
- 近年来,图形处理器(GPU)和专用集成电路(ASICs)的发展极大地提高了并行计算能力,加速了机器学习模型的训练过程。
- 云计算平台的兴起也使得机器学习服务变得更加可访问和经济。
◆ 机器学习常用术语
3.1样本、特征、标签
3.2 数据集划分
◆ 机器学习算法分类
4.1 有监督学习
定义: 输入数据是由输入特征值和目标值所组成。
-函数的输出可以每一个连续的值(称为回归);
-或是输出是有限个离散值(称作分类)。
(1)回归问题
例如︰预测房价,根据样本集拟合出一条连续曲线。
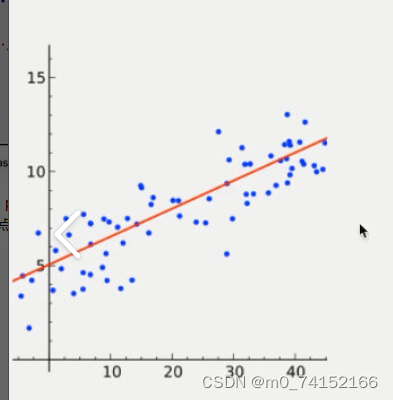
(2)分类问题
例如:根据肿瘤特征判断良性还是恶性,得到的是结果是“良性"或者“恶性”,是离散的。
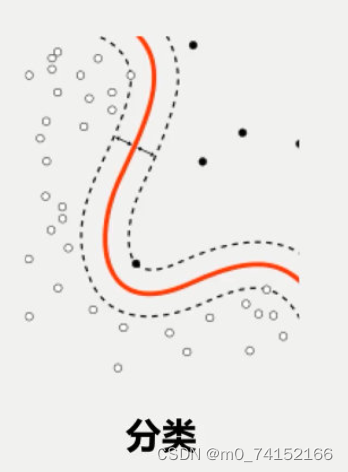
4.2 无监督学习
定义:输入数据是由输入特征值组成。
输入数据没有被标记,也没有确定的结果。样本数据类别未知,需要根据样本间的相似性对样本集进行分类(聚类,clustering)试图使类内差距最小化,类间差距最大化。

4.3 半监督学习
4.4 强化学习
4.5 小结
-
监督学习与非监督学习
- 监督学习:算法从标记的训练数据中学习,每个输入数据都有一个对应的输出标签。目标是学习到一个模型,能够对新的、未见过的数据做出预测。
- 非监督学习:算法处理未标记的数据,尝试找出数据的内在结构和模式。常用于聚类、关联规则学习和降维。
-
半监督学习与强化学习
- 半监督学习:介于监督学习和非监督学习之间,使用大量未标记数据和少量标记数据进行训练。
- 强化学习:算法通过与环境的交互来学习,目标是最大化累积奖励。
◆ 机器学习建模流程
5.1 机器学习建模一般流程
5.1.1 定义分析目标
明确目标任务是第一个需求,也是选择合适的机器学习算法的关键所在。通过阐明业务需求以及要解决的实际问题,才能根据现有的数据进行模型的设计以及算法的选择。
在监督学习中,分类算法用于定性问题,而回归方法用于定量分析。
在无监督学习中,如果存在样本分割,则可以应用聚类算法。如果需要找出各种数据项之间的内部联系,则可以应用关联分析。
5.1.2 收集数据
1.数据应具有代表性,并尽可能地覆盖区域,不然的话,可能出现过拟合和欠拟合的情况。
2.样本数据应平衡。在分类问题的范畴中,如果存在不同类别之间的样本比例较大的情况或者样本数据不平衡的现象,均会影响最终模型的性能。
3.评估数据的量级,包括特征的数量以及样本的数量。根据这些指标估计数据和分析对内存的消耗,并判断在训练过程中内存是否过大,如果内存过大则需要对算法进行优化、改进,或者通过对某些降维技术的使用实现内存消耗合理化,必要的话甚至还会采用一些分布式机器学习的技术。
5.1.3整理预处理
1.数据探索
首先通过对数据进行一定的探索,了解数据的基本结构,数据的统计信息,数据噪声和数据分布等相关信息。
为了更好地对数据的状况进行查看以及数据模式的获取,可以采用数据质量评估以及数据可视化等相关方法来评估数据的质量。
2.数据处理
经过步骤1,可能会发现很多数据质量的问题,例如缺失值,不规则的数据,数据的分布不平衡,数据异常和数据冗余等问题。这些问题的存在将严重降低数据的质量。
数据预处理的操作也是非常重要,在生产环境中的机器学习中,数据通常是原始的,未经过加工以及处理的,而数据预处理的工作通常占据着整个机器学习过程中的绝大部分时间。
常见的数据预处理的方法:缺失值处理,离散化,归一化,去除共线性等方法是机器学习算法。整理预处理
5.1.4数据建模
采用特征选择的方法,可以实现从大量的数据中提取适当的特征,并将选择好的特征应用于模型的训练中,以获得更高精度的模型。
筛选出显著特征需要对业务有非常充分的了解并分析数据。特征选择是否合适通常会对模型的精度有非常直接的影响。选择好的特征,即使采用较为简单的算法,也可以获得较为稳定且良好的模型。
特征有效性分析的技术:相关系数、平均互信息、后验概率、卡方检验、条件熵、逻辑回归权重等方法。
在训练模型之前,通常将数据集分为训练集与测试集,有的时候,会将训练集继续细分为训练集和验证集,以评估模型的泛化能力。
模型本身不存在好坏之分。在进行模型的选择时,通常,没有哪一种算法在任何情况下都能够表现良好,在实际进行算法的选择时,通常,采用几种不同的算法同时进行模型的训练,之后再比较它们之间的性能,并选择其中表现最佳的算法。
不同的模型采用不同的性能指标。
5.1.5模型训练
在模型训练的过程中,需要调整模型的超参数。
在训练的过程中,对机器学习算法的原理以及其推导的过程的要求越高,对机器学习算法的了解越深,就越容易找到问题出现的原因,从而进行合理的模型调整。
5.1.6模型评估
利用测试集数据对模型的精度进行评估与测验,以便评估训练模型对新数据的泛化能力。
假如评估的效果不是很理想,那么就需要分析模型效果不理想的原因并对训练模型进行一定的优化与改进,例如手动调整参数等改进方法。
评估不理想,需要首先诊断模型以确定模型调整的正确思路与方向。过度拟合和欠拟合问题的判断是模型诊断中的重要步骤。
典型方法:绘制学习曲线和交叉验证。
如何解决:
出现过度拟合问题时,其模型的基本调整策略是在增加数据量的同时能够降低模型的复杂度,也可以采用正则化的方法来提高训练模型的泛化能力。
对于模型欠拟合的问题,其模型的基本调整策略是在增加特征数量和质量的同时也增加模型的复杂度。
误差分析是通过对产生误差的样本进行观察并且分析误差的原因。
误差分析的过程:由数据质量的验证,算法选择的验证,特征选择的验证,参数设置的验证等几部分。对数据质量的验证非常重要,通常对参数进行反复地调整,在调整了很长时间之后,才发现数据预处理效果不佳,数据的质量存在一定的问题。
调整模型后,需要对其进行重新训练以及模型评估。
建立机器学习模型的过程也是不断尝试的过程,直至最后模型达到最佳且最稳定的状态。
在工程实施方面,主要通过预处理、特征清理以及模型集成等方式来提高算法的精确度以及泛化能力。
通常,直接对参数进行调整的工作不是太多。因为当数据的量级达到一定的程度时,其训练的速度非常地缓慢,并且不能保证效果。
5.1.7模型应用
模型的应用主要和工程的实施有很大的关系。
工程以结果为导向的,模型在线执行的效果与模型的质量有着非常直接的关系,不仅简单地包括其准确性,误差等方面的信息,还包括其资源消耗的程度(空间复杂度)、运行速度(时间复杂度)以及稳定性是否可以接受等方面的问题。















 2519
2519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









