






A卷题目背景及要求
一、 背景
档案数字化是随着扫描、OCR 、数字摄影、数据库、多媒体、存储等技术的发展而产生的一种新型档案信息处理技术,它把各种载体的档案资源转化为数字化档案信息,以数字化的形式存储,网络化的形式互相连接,利用计算机系统进行管理,形成一个有序结构的档案信息库。我国档案工作采取“存量数字化、增量电子化”的信息化战略。当前我国各行业的存量档案数量巨大,档案数字化的需求不断增加,档案数字化加工行业的市场规模呈现逐年增长的趋势 。
二、 目标
对加工流程数据 进行统计分析,并作可视化展示 ,便于管理人员及时了解档案加工处理动态
1.统计档案数字化流程的耗时和进度情况。
2.统计操作人员的工作量和工作效率情况。
三、 案卷加工流程说明
1. 加工流程按先后顺序分为以下几个工序:扫描、图像处理、自检全检、 PDF 处理。
2.操作人员领取、提交案卷:一个操作人员可以胜任多个工序的工作。启动某个工序时,操作人员首先在系统上批量领取一定数量的加工任务,文件 data.xlsx 中的字段dUPDATE_TIME ”记录了每份案卷的领取时间;档案处理完成后,在系统上进行批量提交文件 data.xlsx 中的字段 “dNODE_TIME ”记录了每份案卷的提交时间。当领取的案卷数量较多时,通常会在中午休息前或下午下班前提交已完成的部分案卷。允许操作人员在未完成已领取的任务前领取新任务。
3. 工作效率按批进行计算,将同一批案卷的最后提交时间减去这批案卷的最早领取时间作为该批案卷的总耗时,以此计算该批案卷的平均耗时。所谓“批”是对同一个操作人员在同一个工序中,从领取第一份案卷开始,直到该操作人员在该工序中所有案卷都提交完成,在这段时间内处理的所有案卷。文件 data.xlsx 中的字段“ sBatch_number ”记录了批的编号。 4. 文件 data.xlsx 中的字段“ iNODE_STATUS ”(工序状态)为 2 ,表明 案卷已完成并提交 ,且不需要返工;该字段为 5 ,表明案卷经过 返工,已完成并 提交 。
5.工作时间为周一至周六上午 8:30 12:00 ,下午 1 3:00 18:00 ,案卷的处理时间和操作人员的工作时长应去掉非工作时间。注意:实际工作中,可能有 提前上岗或推迟下岗的情况。
四、任务1 数据预处理与统计-任务描述
data.xlsx记录了某档案数字化加工单位 2020 年 7 月加工处理过程中各个工序的管理数据。请 编程完成 以下任务并撰写报告, 在报告中 详细描述各项任务的 处理思路、过程及必要的结果。结果的模板文件在文件夹“ result 中。
任务1.1 统计完成四道工序的案卷数量,在报告中列出统计结果。汇总各案卷各工序的开始时间及各案卷的完成时长,以表 1 的格式将汇总结果保存到文件“result1_1.xlsx中,同时在报告中列出案卷完成时长最长的三个案卷的结果。
注1 、每个案卷的完成时长是扫描、图像处理、自检全检三个工序的耗时之和, PDF处理无需计算耗时,各工序的耗时是该工序的开始时间至结束时间的时长。
注2 、完成时长应去掉非工作时间(“三、案卷加工流程说明”第 5 条),单位: h保留 3 位小数。
任务1.2 统计需要返工的案卷数量及其占完工案卷总数的百分比,在报告中列出结果。汇总返工案卷的返工工序和返工开始时间,以表 2 的格式将汇总结果保存到文件“result1_2.xlsx ”中同时在报告中列出返工案卷号“托 40606 册六”“托 40606 册七”“托 5901_1 册三”的结果。
注:未返工工序的时间为空。

任务1.3 对自检全检工序,汇总每个操作人员的返工案卷数, 计算其占该操作人员该工序工作总量的百分比,按百分比降序排列,以表 3 的格式将结果保存到文件result1_3.xlsx ”中,同时在报告中列出前三位操作人员的结果。结果保留 3 位小数,例如:返工案卷占比为 1 %,在结果表中填写 1 .000 ”。

任务1.4 按工序分别统计完成案卷的数量、总耗时和平均耗时,以表 4 的格式将结果保存到文件“ result1_4.xlsx ”中,并在报告中列出结果。 结果保留 3 位小数。
注:按工序计算总耗时,是该工序各个批次的案卷集最早开始时间至案卷集最晚结束时间之和,而不是各个案卷完成时长的总和。
任务1.5 按操作人员、工序统计工作时长、完成案卷的数量和每个案卷的平均耗时( h/卷),以表 5 的格式将结果按操作人员 ID 升序排列保存到文件“ result1_5.xlsx ”中,同时在正文中列出操作人员 ID 10 33 48 ”的结果。 结果保留 3 位小数。
注:按操作人员、工序统计工作时长是按批进行的(“三、案卷加工流程说明”第 3条),应去除非工作时间(“三、案卷加工流程说明”第 5 条)。
五、任务2 数据分析与可视化
任务2.1 计算并绘制每天不同工序完成案卷数量的簇状柱形图: x 轴表示时间, y 轴表示完成案卷的数量,用不同颜色标记不同工序。
任务2.2 计算并绘制各工序每天投入工作量(单位:人·小时)的多重折线图: x 轴表示时间, y 轴表示每天投入的工作量,用不同颜色标记不同工序。
任务2.3 绘制每天各工序返工案卷数占当天返工案卷总数的百分比堆积面积图: x 轴表示时间, y 轴表示百分比,用不同颜色标记不同工序。
任务 2.4 对图像处理工序,汇总每个操作人员返工案卷数,计算其占该工序返工案卷对图像处理工序,并按百分比进行排序,绘制饼图,其中排名第10位及以后的合并成一个扇位及以后的合并成一个扇区。
六、任务3 领取提交模式分析
档案的数字化加工中,操作人员在某个工序中的正常领取提交模式是在相对集中的时间内领取若干案卷,全部加工完成后在相对集中的时间内按照领取的顺序提交该批案卷。但在现实中会出现更多类型的领取提交模式,例如操作人员有时会分多次领取案卷,处理完后一起集中提交;在未完全提交已领取案卷的情况下又领取了新的案卷。出现这种情况的可能原因是,在处理已领取的案卷时发现这些案卷的处理难度低于平均难度,操作人员出于提高个人工作效率的考虑通过多次领取的方式“囤积”易处理案卷。
可通过可视化的方法分析案卷领取提交时序,例如在图1 所示的桑基图中,每份案卷对应图中一条直线,左端点的纵坐标表示领取时间,右端点的纵坐标表示提交时间。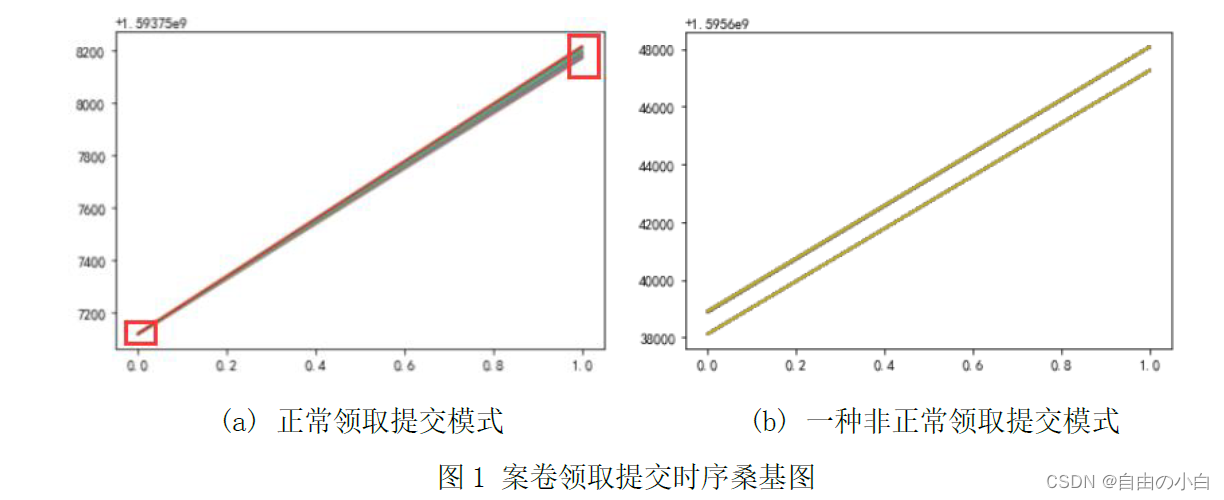
图1 b 对应于分两次领取、分两次提交,不同的案卷集在处理时序上出现交叉的领取提交模式。也可以使用图 2 中的模式示意图来表达。 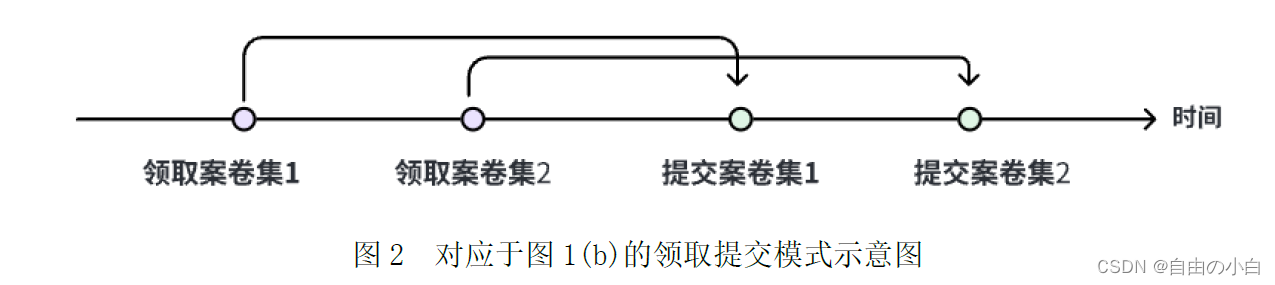
请根据文件data.xlsx 的批次数据,通过可视化的方法分析批次内案卷的领取提交时序,总结有哪几种领取提交模式。对每一种模式给出一个实际例子 ,以表 6 的格式保存到 文件”result3.xlsx ”中,同时在报告中参照图 1 和图 2 的方式分别绘制两种不同的示意图。 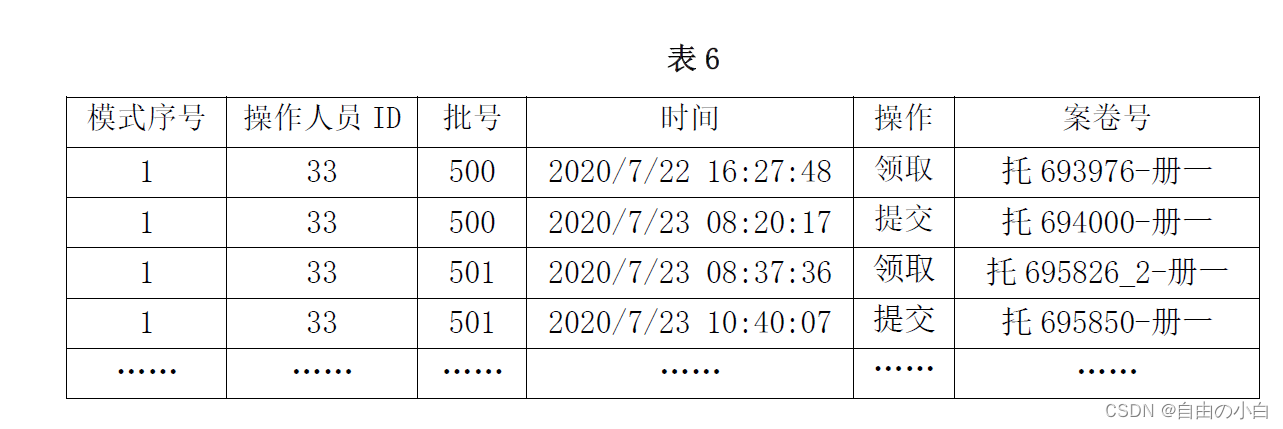
七、附录数据说明
数据文件data.xlsx 中的每条记录对应于一个案卷某个工序的处理记录,其中的字段名及其含义如 表 7 所示。 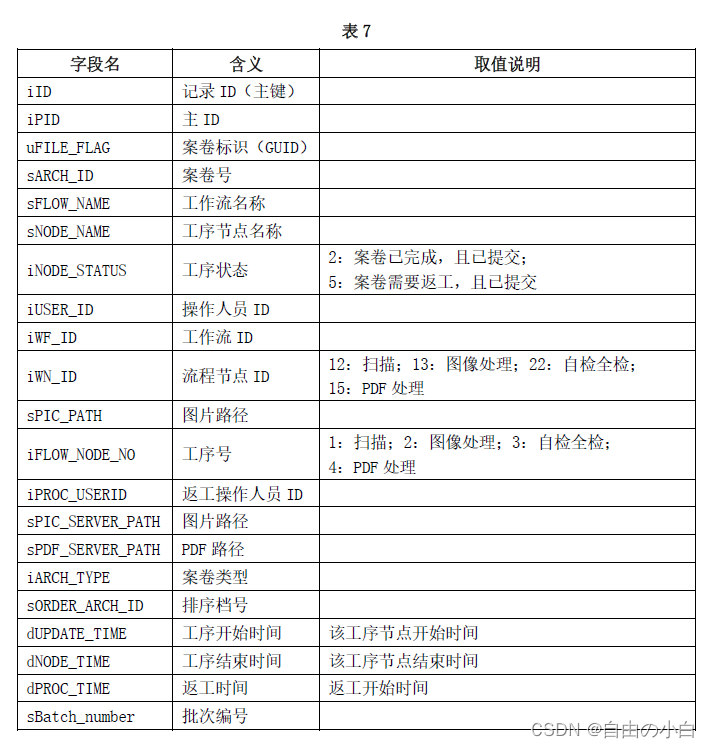
档案数字化加工流程数据详解完整代码
任务1 相关代码
导入相关库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
import seaborn as sns
import random
import re
import missingno as mg
from scipy.stats import zscore
from datetime import datetime
import datetime
import pytz
from pyecharts import options as opts
from pyecharts.charts import Line,Radar
from pyecharts.charts import *
from pyecharts.commons.utils import JsCode
# sns.set()全局风格设置 simhei显示中文
sns.set_style('whitegrid',rc = {'font.family': 'SimHei'})
plt.rcParams['font.family'] = 'SimHei' # 正常显示中文
plt.rcParams['axes.unicode_minus'] = False
import warnings
warnings.filterwarnings("ignore")数据导入&数据检测
- 导入相关数据
# 从 Excel 文件中读取数据到 DataFrame
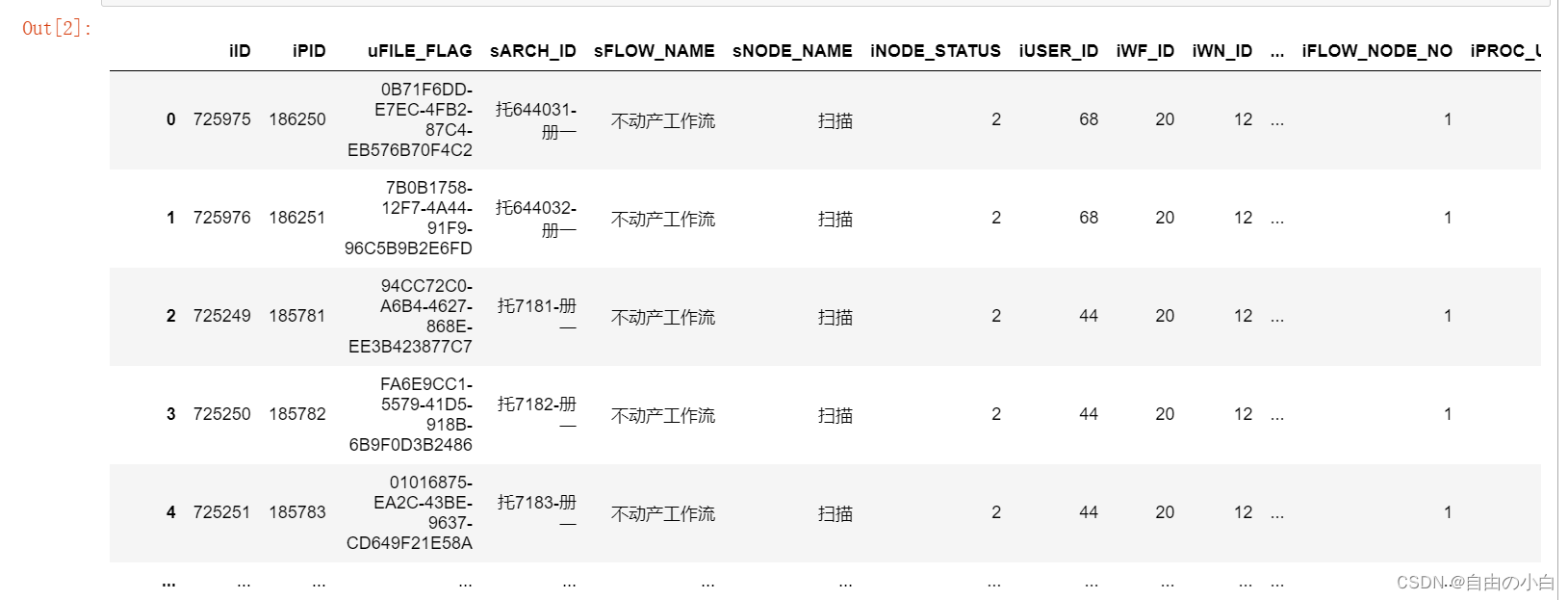
df = pd.read_excel('../Desktop/data.xlsx')
df运行结果如下:
- 为数据添加中文名称
df.columns = ['记录ID','主ID','案卷标识(GUID)','案卷号','工作流名称','工序节点名称','工序状态','操作人员ID','工作流ID','流程节点ID','图片路径','工序号','返工操作人员ID','图片路径','PDF路径','案卷类型','排序档号','工序开始时间','工序结束时间','返工时间','批次编号']- 查看数据类型
df.info() 运行结果如下: 
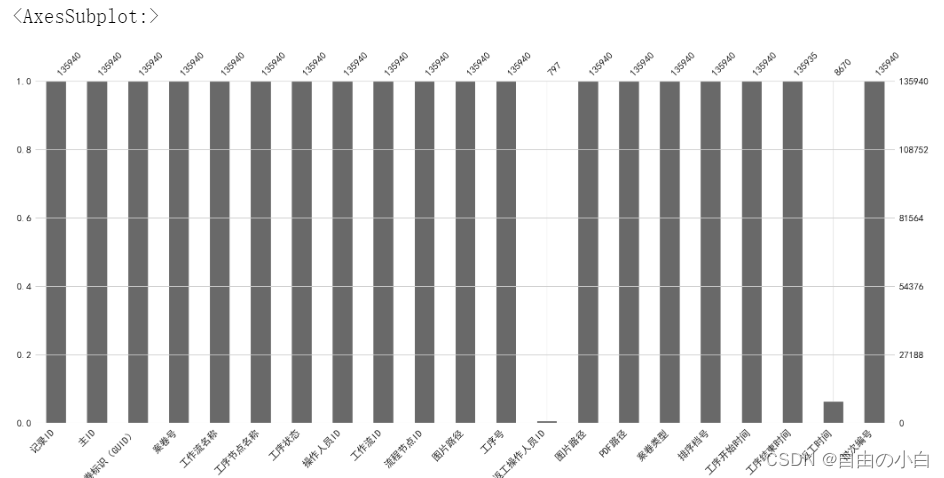
- 利用柱状图进行缺失值可视化
mg.bar(df,labels = 1)运行结果如下:
任务1.1统计完成四道工序的案卷数量,在报告中列出统计结果。汇总各案卷各工序
- 查找数据框(df)中重复的行
duplicate_rows = df[df.duplicated(subset=['工序节点名称', '案卷号'], keep=False)]
print(duplicate_rows) 运行结果如下:
- 查询每个工序节点的次数,以及唯一案卷号个数,最终绘制出扇形图
case_counts = df.groupby('工序节点名称').size()
# 打印结果
print(case_counts)
print('唯一的案卷号个数:', df['案卷号'].nunique())
duplicate_rows = df[df.duplicated(subset=['工序节点名称', '案卷号'], keep=False)]
print('工序节点名称与案卷号相同行:',duplicate_rows)
# 绘制扇形图
plt.figure(figsize=(10,6))
plt.pie(case_counts, labels=case_counts.index, autopct='%1.1f%%')
plt.title('各工序案卷数量占比')
plt.show() 运行结果如下: 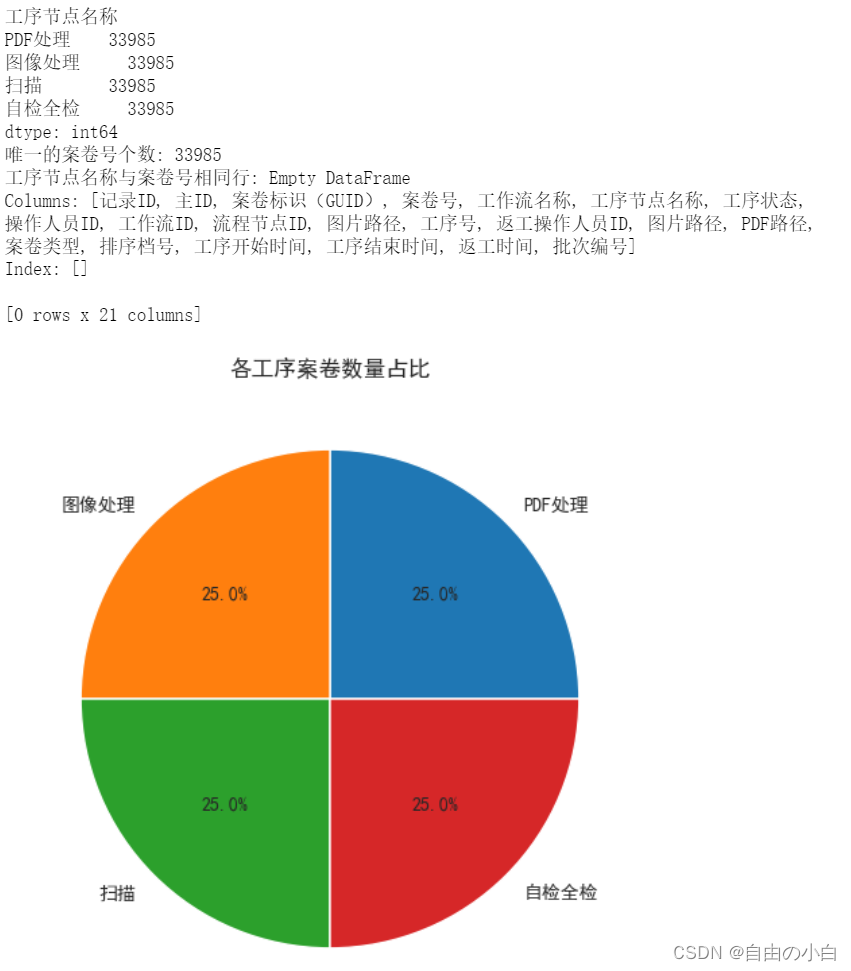
- 统计完成四道工序的案卷数量,在报告中列出统计结果。汇总各案卷各工序 的开始时间及各案卷的完成时长,以表 1 的格式将汇总结果保存到文件“ result1_1.xlsx 中,同时在报告中列出案卷完成时长最长的三个案卷的结果。
data = pd.read_excel('C:/Users/86186/Desktop/data.xlsx')
# 初始化字典来存储每个案卷的各个工序的开始和结束时间
dataset = {}
# 遍历数据
for index, row in data.iterrows():
case_id = row['sARCH_ID']
node_name = row['sNODE_NAME']
node_start = row['dUPDATE_TIME']
node_end = row['dNODE_TIME']
if node_end<node_start:
continue
if case_id not in dataset:
dataset[case_id] = {
"扫描开始时间": 0,
'扫描结束时间': 0,
'图像处理开始时间': 0,
'图像处理结束时间': 0,
'自检全检开始时间': 0,
'自检全检结束时间': 0,
'PDF处理开始时间': 0,
'PDF处理结束时间': 0
}
# 判断工序类型并更新字典中的数据
if node_name == '扫描':
dataset[case_id]['扫描结束时间'] = node_end
dataset[case_id]['扫描开始时间'] = node_start
elif node_name == '图像处理':
dataset[case_id]['图像处理结束时间'] = node_end
dataset[case_id]['图像处理开始时间'] = node_start
elif node_name == '自检全检':
dataset[case_id]['自检全检结束时间'] = node_end
dataset[case_id]['自检全检开始时间'] = node_start
elif node_name == 'PDF处理':
dataset[case_id]['PDF处理结束时间'] = node_end
dataset[case_id]['PDF处理开始时间'] = node_start
# 计算完成时长并添加到字典中
for case_id, times in dataset.items():
scan_duration = times['扫描结束时间'] - times['扫描开始时间']
image_processing_duration = times['图像处理结束时间'] - times['图像处理开始时间']
self_check_duration = times['自检全检结束时间'] - times['自检全检开始时间']
pdf_processing_duration = times['PDF处理结束时间'] - times['PDF处理开始时间']
total_duration=scan_duration+image_processing_duration+self_check_duration
dataset[case_id]['完成时长'] = round(total_duration.total_seconds() / 3600, 3)
# 将结果转换为DataFrame
result_df = pd.DataFrame.from_dict(dataset, orient='index')
# 保存结果到Excel文件
result_df.reset_index(inplace=True)
result_df.rename(columns={'index': '案卷号'}, inplace=True)
result_df.to_excel("./result1_1.xlsx", index=False)- 列出案卷完成时长最长的三个案卷的结果。
print('找出案卷完成时长最长的三个案卷') top3_cases = result_df.nlargest(3, '完成时长') print("案卷完成时长最长的三个案卷:") print(top3_cases)运行结果如下:

任务1.2 统计需要返工的案卷数量及其占完工案卷总数的百分比,在报告中列出结果。
- 查看需要返工的案卷号,并统计出需返工的案卷号
print(df.query("工序状态==5")['案卷号'].nunique())
data1 = df.query("工序状态==5")运行结果如下:

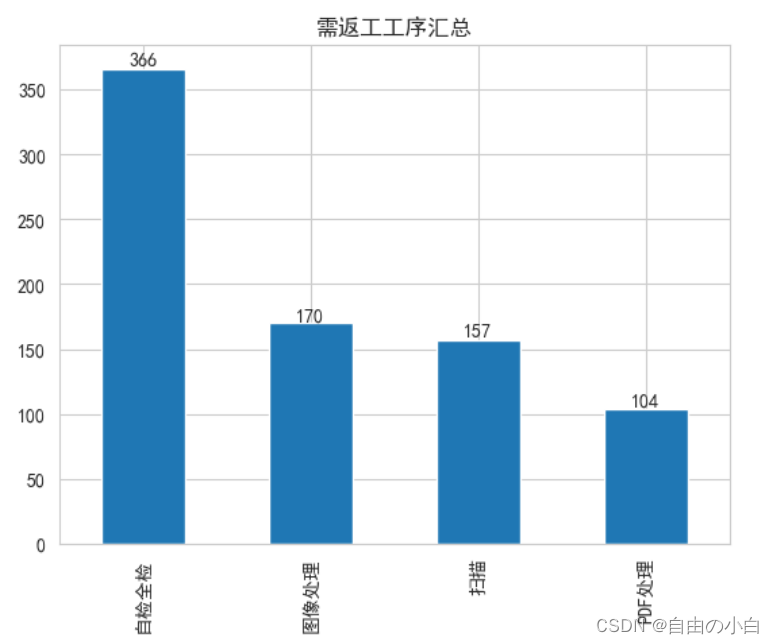
- 绘制需返工的案卷号直方图
bar = data1['工序节点名称'].value_counts().plot.bar()
plt.bar_label(bar.containers[0])
plt.title('需返工工序汇总')
plt.show()运行结果如下 :
- 统计需要返工的案卷数量及其占完工案卷总数的百分比
data1['案卷号'].nunique()/len(result_df)运行结果如下:

- 统计需要返工的案卷数量及其占完工案卷总数的百分比
def value(original_time):
# print(original_time.values[0])
original_time=original_time.values[0]
return str(original_time).split('.')[0]
return formatted_time
result1_2 = pd.crosstab(index = data1['案卷号'], columns = data1['工序节点名称'], values=data1['返工时间'],aggfunc=value)
result1_2[['扫描','图像处理','自检全检','PDF处理']] 运行结果如下: 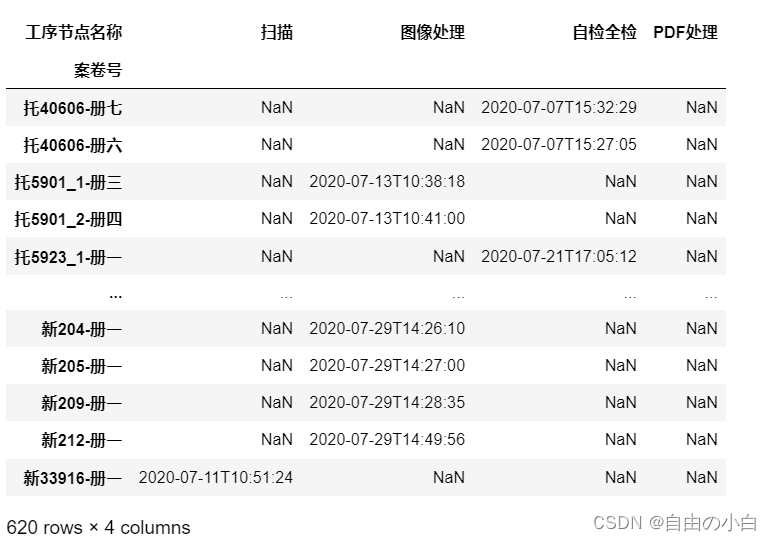
- 统计需要返工的案卷数量及其占完工案卷总数的百分比 ,以表 2 的格式将汇总结果保存到文件result1_2.xlsx ”中
result1_2.to_excel('result1_2.xlsx')- 列出返工案卷号“托 40606 册六”“托 40606 册七”“托 5901_1 册三”的结果。
result1_2.query("index in ['托40606-册六','托40606-册七','托5901_1-册三']")任务1.3 对自检全检工序,汇总每个操作人员的返工案卷数, 计算其占该操作人员该工序工作总量的百分比,按百分比降序排列,以表 3 的格式将结果保存到文件result1_3.xlsx ”中,同时在报告中列出前三位操作人员的结果。结果保留 3 位小数,例如:返工案卷占比为 1 %,在结果表中填写 1 .000 ”。
- 筛选对自检全检工序的操作工人
data2 = df.query("工序节点名称=='自检全检'")
data2 运行结果如下:
- 查看操作工人ID
data2['操作人员ID'].unique()运行结果如下:

- 对自检全检工序,汇总每个操作人员的返工案卷数, 计算其占该操作人员该 工序工作总量的百分比,按百分比降序排列,以表 3 的格式将结果保存到文件 result1_3.xlsx ”中。
result1_3 = []
for i in data2['操作人员ID'].unique():
d_ = data2.query(f'操作人员ID=={i}')
rework_count = len(d_.query('工序状态==5'))
bili = '%.3f'%(rework_count/len(d_) * 100)
print('操作人员ID:', i, '返工案卷数:', rework_count, '返工案卷占比 (%):', bili)
result1_3.append({'操作人员ID':i, '返工案卷数': rework_count, '返工案卷占比 (%)':bili})
result1_3 = pd.DataFrame(result1_3)[['操作人员ID', '返工案卷占比 (%)']].sort_values('返工案卷占比 (%)',ascending = False)
result1_3 = result1_3.set_index('操作人员ID')
result1_3.to_excel('result1_3.xlsx')
- 列出前三位操作人员的结果
top3_rework_rate = result1_3.head(3)
print(top3_rework_rate) 运行结果如下:
任务1.4 按工序分别统计完成案卷的数量、总耗时和平均耗时,以表 4 的格式将结果保存到文件“ result1_4.xlsx ”中,并在报告中列出结果。 结果保留 3 位小数。
- 筛选出相关数据
data3 = df.groupby(['工序节点名称','批次编号'],as_index=False).agg({'工序开始时间':np.min,'工序结束时间':np.max})
data3运行结果如下:
- 定义时间差值函数
#定义差值函数
def compute_time(x):
try:
start,end = x
try:
start.date(), end.date()
except Exception as e:
print(e)
return np.nan
# 定义工作时间
work_start = pd.to_datetime('08:30').time()
work_end_morning = pd.to_datetime('12:00').time()
work_start_afternoon = pd.to_datetime('13:00').time()
work_end = pd.to_datetime('18:00').time()
# 初始化工作小时为 0
work_hours = 0
# 遍历日期范围内的每一天
for date in pd.date_range(start=start.date(), end=end.date()):
# 如果是周日或者周六则跳过
if date.weekday() >= 6:
continue
# 计算当天的工作开始和结束时间
curr_day_work_start = pd.Timestamp(date.year, date.month, date.day, work_start.hour, work_start.minute)
curr_day_work_end = pd.Timestamp(date.year, date.month, date.day, work_end.hour, work_end.minute)
# 如果开始或结束时间在工作时间内,调整它们
if start > curr_day_work_start:
curr_day_work_start = max(start, curr_day_work_start)
if end < curr_day_work_end:
curr_day_work_end = min(end, curr_day_work_end)
# 计算当天的工作小时,并减去午休时间
work_hours += max(0, (curr_day_work_end - curr_day_work_start).total_seconds() / 3600 - 1)
except Exception as e:
print(e)
print(start,end)
return work_hours
return float("%.3f"%total_hours)- 构建工序节点完成时间属性并展示
data3['工序开始时间'] = pd.to_datetime(data3['工序开始时间'])
data3['工序结束时间'] = pd.to_datetime(data3['工序结束时间'])
data3['完成时长'] = data3[['工序开始时间','工序结束时间']].apply(compute_time,axis =1)
result1_4 = data3.groupby('工序节点名称').agg({'完成时长':np.sum})
result1_4运行结果如下:

- 按工序分别统计完成案卷的数量、总耗时和平均耗时,以表 4 的格式将结果 保存到文件“ result1_4.xlsx ”中
result1_4['完成案卷的数量'] = df.groupby('工序节点名称').size()result1_4['平均耗时 (h/卷)'] = result1_4['完成时长']/result1_4['完成案卷的数量']
result1_4.columns = ['总耗时 (h)', '完成案卷的数量','平均耗时 (h/卷)']
result1_4 = result1_4.round(3).reindex(columns = ['完成案卷的数量', '总耗时 (h)', '平均耗时 (h/卷)'])
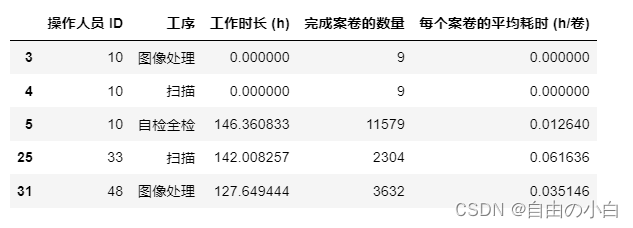
result1_4.to_excel('result1_4.xlsx')任务1.5 按操作人员、工序统计工作时长、完成案卷的数量和每个案卷的平均耗时( h/卷),以表 5 的格式将结果按操作人员 ID 升序排列保存到文件“ result1_5.xlsx ”中,同时在正文中列出操作人员 ID 10 33 48 ”的结果。 结果保留 3 位小数。
- 按照'操作人员ID'、'工序节点名称'和'批次编号'这三列进行分组,并对每个子数据框中的'工序开始时间'列取最小值,'工序结束时间'列取最大值。然后,通过自定义函数
compute_time计算每个子数据框中'工序开始时间'和'工序结束时间'之间的时间差,并将结果存储在新添加的'完成时长'列中。
data4 = df.groupby(['操作人员ID','工序节点名称','批次编号'],as_index=False).agg({'工序开始时间':np.min,'工序结束时间':np.max})
data4['完成时长'] = data4[['工序开始时间','工序结束时间']].apply(compute_time,axis =1)
data4运行结果如下:
- 是对数据框
data4进行进一步的分组聚合操作,并计算每个操作人员在每个工序节点上的总完成时长。
result1_5 = data4.groupby(['操作人员ID','工序节点名称'],as_index=False).agg({'完成时长':np.sum})
result1_5运行结果如下:
- 计算每个操作人员在每个工序节点上的记录数。
df.groupby(['操作人员ID','工序节点名称']).size()运行结果如下:

- 以表 5 的格式将结果按操作人员 ID 升序排列保存到文件“ result1_5.xlsx ”中
result1_5['完成案卷的数量'] = df.groupby(['操作人员ID','工序节点名称']).size().values
result1_5['每个案卷的平均耗时 (h/卷)'] = result1_5['完成时长'] / result1_5['完成案卷的数量']
result1_5 = result1_5.reindex(columns = ['操作人员ID','工序节点名称','完成时长','完成案卷的数量','每个案卷的平均耗时 (h/卷)'])
result1_5.columns = ['操作人员 ID', '工序', '工作时长 (h)','完成案卷的数量','每个案卷的平均耗时 (h/卷)']
result1_5.to_excel('result1_5.xlsx')- 列出操作人员 ID 10 33 48 ”的结果
result6 = result1_5[result1_5['操作人员 ID'].isin([10, 33, 48])]
result6运行结果如下:
任务2 相关代码
由于篇长限制,任务2相关代码无法展示,评论留言“太实用啦!”免费发送完整(源代码+源数据)
任务3 相关代码
由于篇长限制,任务3相关代码无法展示,评论留言“太实用啦!”免费发送完整(源代码+源数据)
喜欢本文章的记得收藏点赞哦~
代码遇到什么情况都可以私聊评论,我们一起探讨~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









