






特征(feature)是物品拥有的的属性。
如房子的位置,面积,楼层,朝向,价格等等。
特征工程是用专业的背景知识和技巧处理数据,让机器学习算法效果最好。
在机器学习中:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限。
由此看出,数据和特征在机器学习中十分重要。
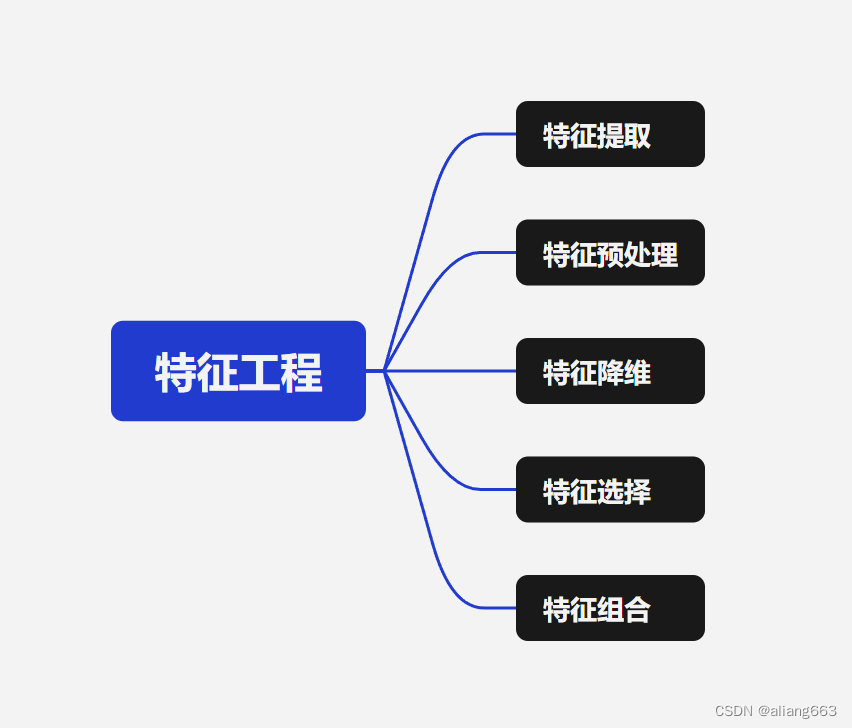
特征工程
特征工程指的是把原始数据转变为模型的训练数据的过程
特征工程五个步骤:
特征提取:从原始数据中提取与任务相关的特征,即各种相关的属性。
特征预处理:特征对模型会产生一定的影响。有些影响大,有些影响小。
特征降维:将原始数据中的特征降维。
特征选择:原始数据特征很多,但是对模型训练相关是其中一个特征集合子集。
特征组合:有时会将多种特征组合为一个特征从而增强模型水平。(一般用乘法和加法完成)
拟合和泛化
拟合:用在机器学习中模型对数据的拟合的现象。
过拟合:由于某些原因,模型出现在训练集上表现很好,而在测试集上表现很差的现象。
原因:训练次数过多,模型过于复杂,数据不纯,训练数据太少等。模型学习到的特征过多,导
致模型只能在训练样本上得到较好的预测结果,而在位置要本上的效果不好。
欠拟合:由于某些原因,模型出现在训练集和测试集上都表现很差的现象。
原因:模型过于简单,数据太单调,即样本特征值过少,无法对数据进行预测。
泛化:即模型在新数据上表现出的能力,如在新数据上表现很好,就称为这个模型泛化能力强,
反之则称这个模型的泛化能力弱。
conda基本命令
1.conda create -n name python==3.8 创建环境
2.conda activate name 激活进入环境
3.conda remove --name --all 删除环境
4.conda/pip install 库 (在激活环境的情况下)
sklearn使用
1.分类预测(聚类算法)
#1.导包
#2.导数据
#3.实例化对象
#4.训练
#5.预测
#1.导包
from sklearn.neighbors import KNeighborsClassifier
#2.导数据
x = [[0], [1], [2], [3]] #ba‘0’放在零类,‘1’放在1零类,‘2’,‘3’放在一类。
,y = [0, 0, 1, 1]
#3.实例化对象
model = KNeighborsClassifier(n_neighbors=3)
#4.训练
model.fit(x, y)
#5.预测
mypre = model.predict([[999]])
print(mypre)
输出:
[1]2.回归预测
from sklearn.neighbors import KNeighborsRegressor
def dm02_knnapi_回归():
estimator = KNeighborsRegressor(n_neighbors=2)
X = [[1, 0, 0],
[2, 1, 0],
[3, 2, 1],]
y = [1, 2, 3]
estimator.fit(X, y)
myret = estimator.predict([[4, 3, 2]])
print('myret-->', myret)
dm02_knnapi_回归()
输出:
myret--> [2.5]















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









