






 本文介绍了KNN分类算法的基本原理,包括其基于邻近原则进行预测的方法,并详细讨论了常见的距离度量公式如曼哈顿、欧式、切比雪夫和闵氏距离。此外,文章还涵盖了特征预处理中的数据归一化和标准化方法,以及在Iris数据集上的实际应用示例。
本文介绍了KNN分类算法的基本原理,包括其基于邻近原则进行预测的方法,并详细讨论了常见的距离度量公式如曼哈顿、欧式、切比雪夫和闵氏距离。此外,文章还涵盖了特征预处理中的数据归一化和标准化方法,以及在Iris数据集上的实际应用示例。
KNN是最为常用的分类算法之一,属于有监督学习的一种。K-means算法属于无监督学习。
KNN的原理就是当预测一个新的值x的时候,根据它距离最近的K个点是什么类别来判断x属于哪个类别。
一.常见的距离公式:
1.曼哈顿距离公式:指两点在标准坐标系上的绝对轴距总和,也称为城市街区距离或L1范数。
d(x, y) = |x1 - y1| + |x2 - y2| + ... + |xn - yn|
2.欧式距离公式:指两点在标准坐标系上的直线距离,也称为L2范数。
d(x, y) = sqrt((x1 - y1)^2 + (x2 - y2)^2 + ... + (xn - yn)^2)
3.切比雪夫距离公式:指两点在标准坐标系上各坐标数值差的最大值。
d(x, y) = max(|x1 - y1|, |x2 - y2|, ..., |xn - yn|)
4.闵氏距离公式:一种通用的距离度量方法,可以根据具体情况调整参数来计算不同的距离。
d(x, y) = (|x1 - y1|^p + |x2 - y2|^p + ... + |xn - yn|^p)^(1/p),其中p为参数,可以是任意实数。
二.特征预处理
(1)数据归一化
from sklearn.preprocessing import MinMaxScaler
def dm01_MinMaxScaler():
# 1. 准备数据
data = [[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
# 2. 初始化归一化对象
transformer = MinMaxScaler()
# 3. 对原始特征进行变换
data = transformer.fit_transform(data)
# 4. 打印归一化后的结果
print(data)
dm01_MinMaxScaler()
[[1. 0. 0. 0. ]
[0. 1. 1. 0.83333333]
[0.5 0.5 0.6 1. ]]
进程已结束,退出代码为 0
(2) 数据标准化
from sklearn.preprocessing import StandardScaler
def dm03_StandardScaler(): # 对特征值进行标准化
#1. 准备数据
data = [[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
#2. 初始化标准化对象
transformer = StandardScaler()
#3. 对原始特征进行变换
data = transformer.fit_transform(data)
#4. 打印归一化后的结果
print(data)
#5 打印每1列数据的均值和标准差
#print('transfer.mean_-->', transfer.mean_)
#print('transfer.var_-->', transfer.var_)
dm03_StandardScaler()
[[ 1.22474487 -1.22474487 -1.29777137 -1.3970014 ]
[-1.22474487 1.22474487 1.13554995 0.50800051]
[ 0. 0. 0.16222142 0.88900089]]
进程已结束,退出代码为 0
(3)鸢尾花案例
实现流程:
①加载数据集
②数据展示
③特征处理
④实例化
⑤训练
⑥评估
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
#加载数据集
from sklearn.datasets import load_iris
iris_data = load_iris()
#print(data)
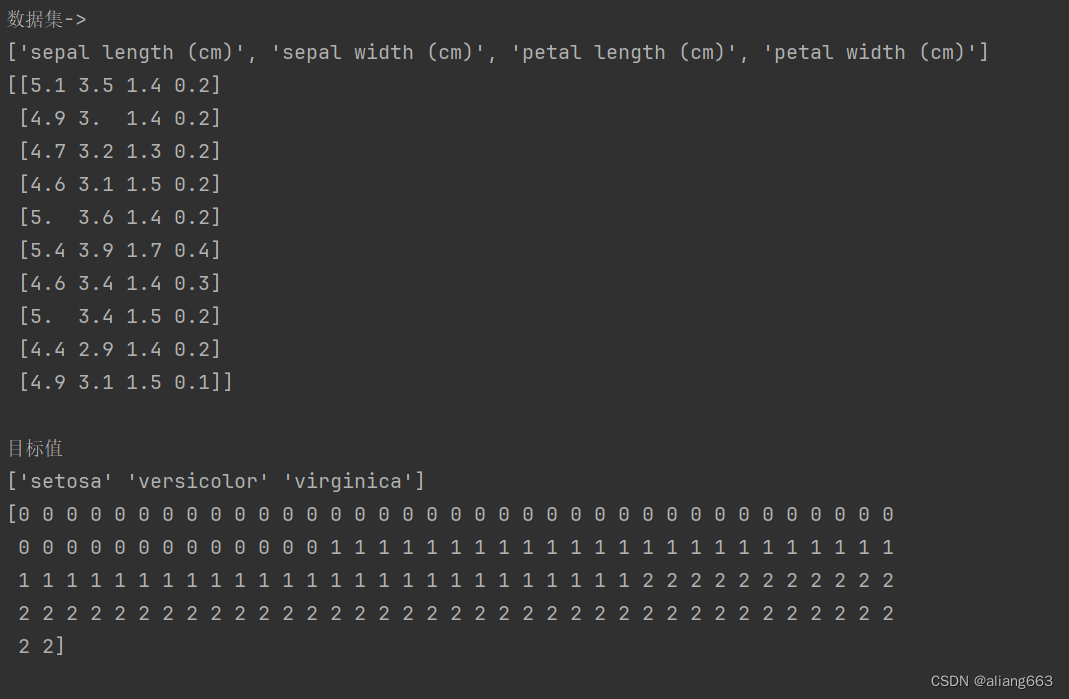
print(f'数据集->\n{iris_data.feature_names}\n{iris_data.data[:10]}')
print(f'\n目标值\n{iris_data.target_names}\n{iris_data.target}')
#数据展示
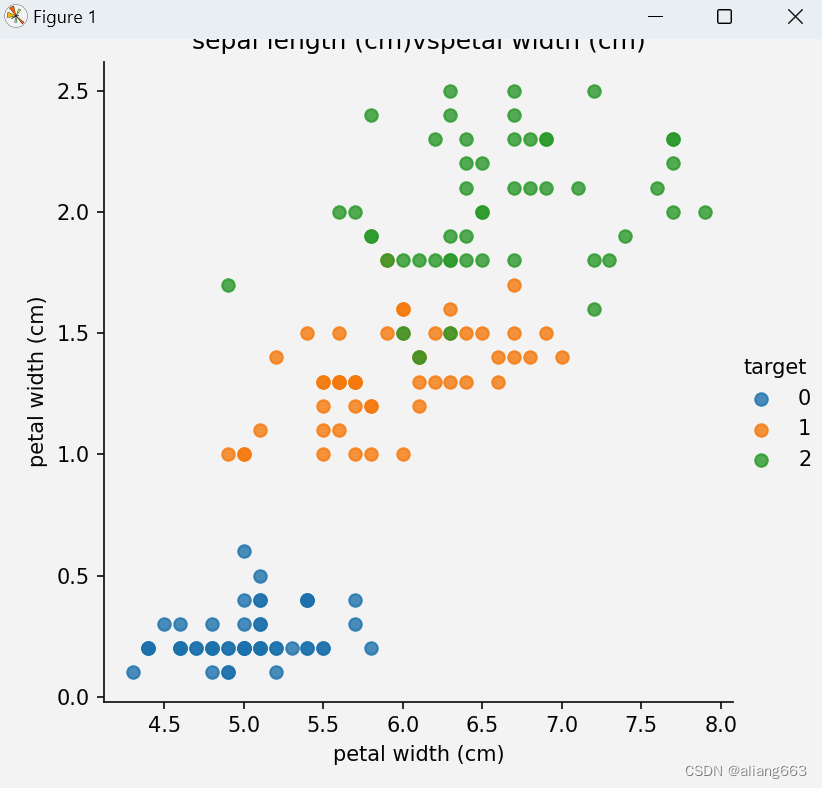
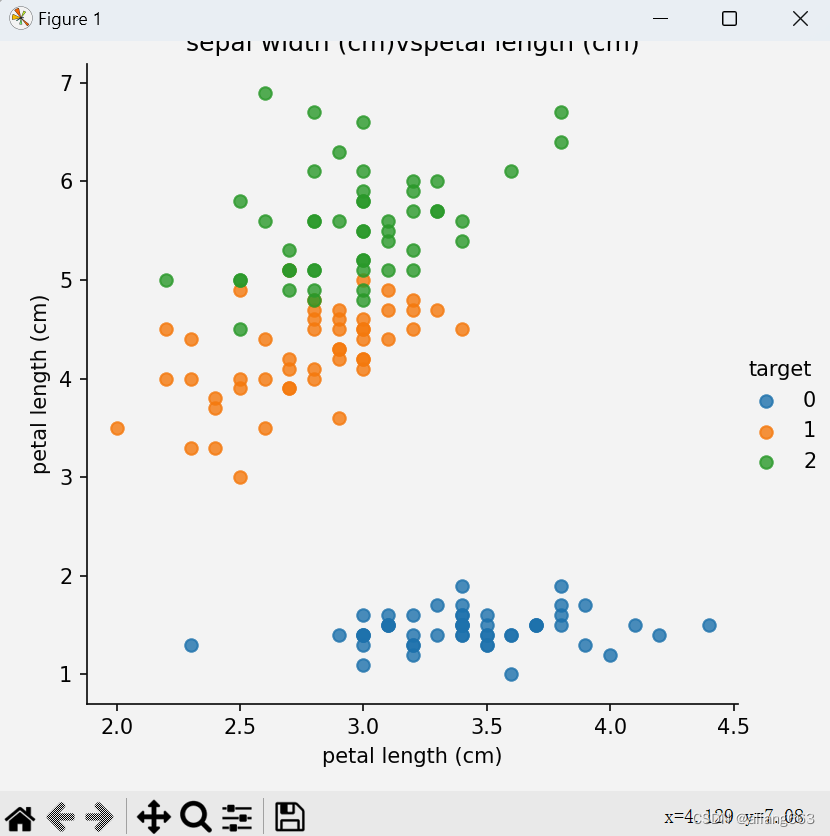
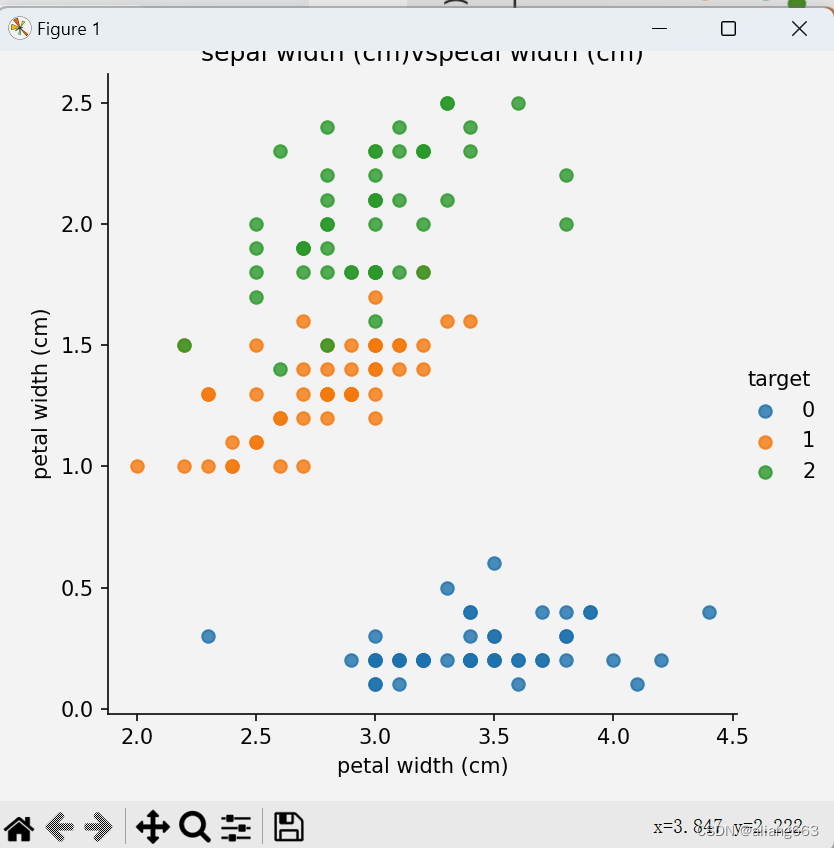
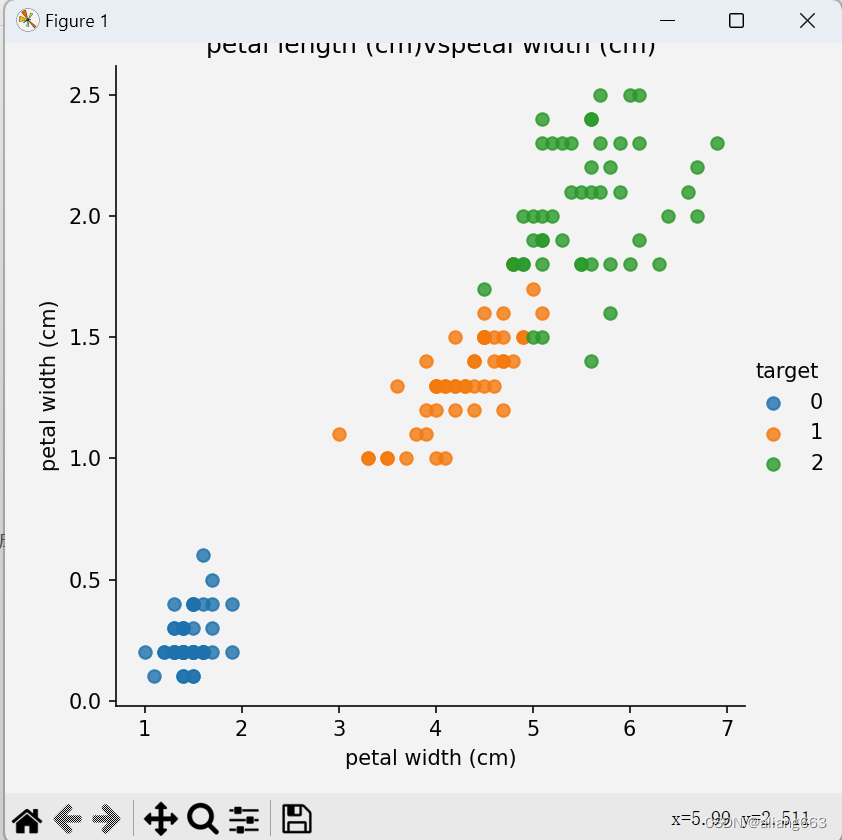
def dm02_irisdata_show():
iris_df = pd.DataFrame(iris_data['data'], columns=iris_data.feature_names)
iris_df['target'] = iris_data.target
print(iris_df)
feature_names = list(iris_data.feature_names)
#print(feature_names)
for i in range(len(feature_names)):
for j in range(i+1, len(feature_names)):
col1 = feature_names[i]
col2 = feature_names[j]
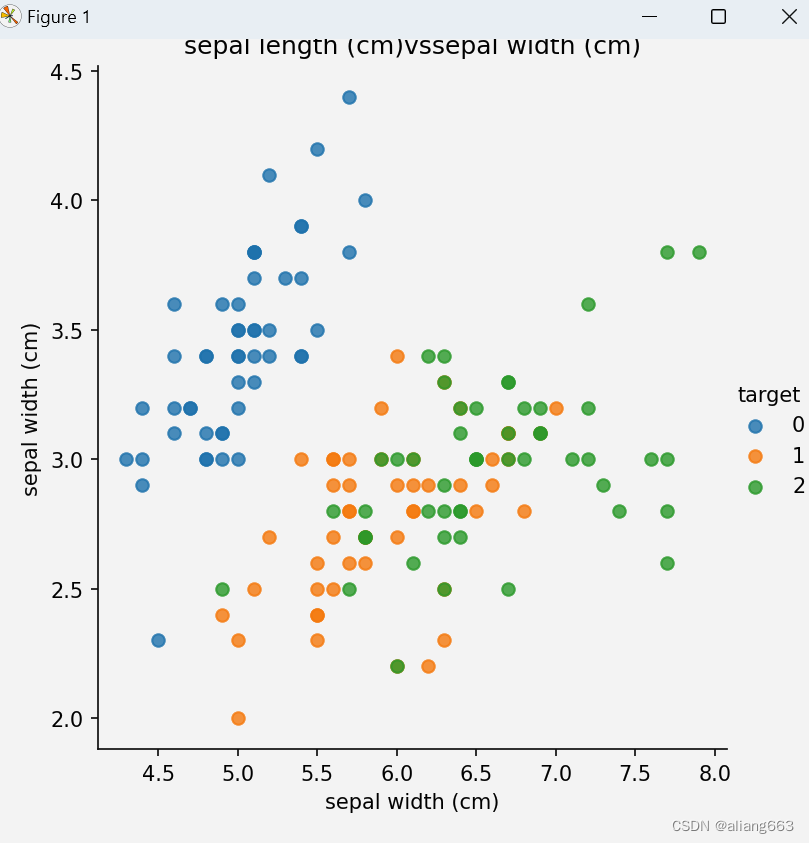
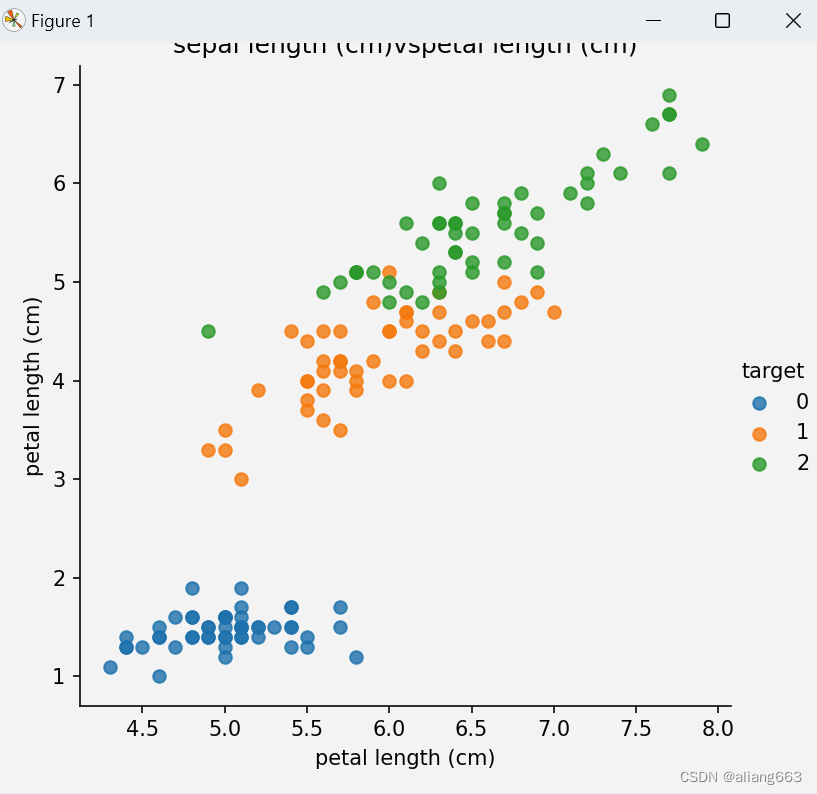
sns.lmplot(x=col1, y=col2, hue='target', data=iris_df, fit_reg=False)
plt.xlabel(col1)
plt.xlabel(col2)
plt.title(f'{col1}vs{col2}')
plt.show()
#sns.lmplot(x='sepal length(cm)', y='sepal width(cm)', hue='target', data=iris_df)
#plt.show()
dm02_irisdata_show()
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
#加载数据集
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris_data = load_iris()
#print(data)
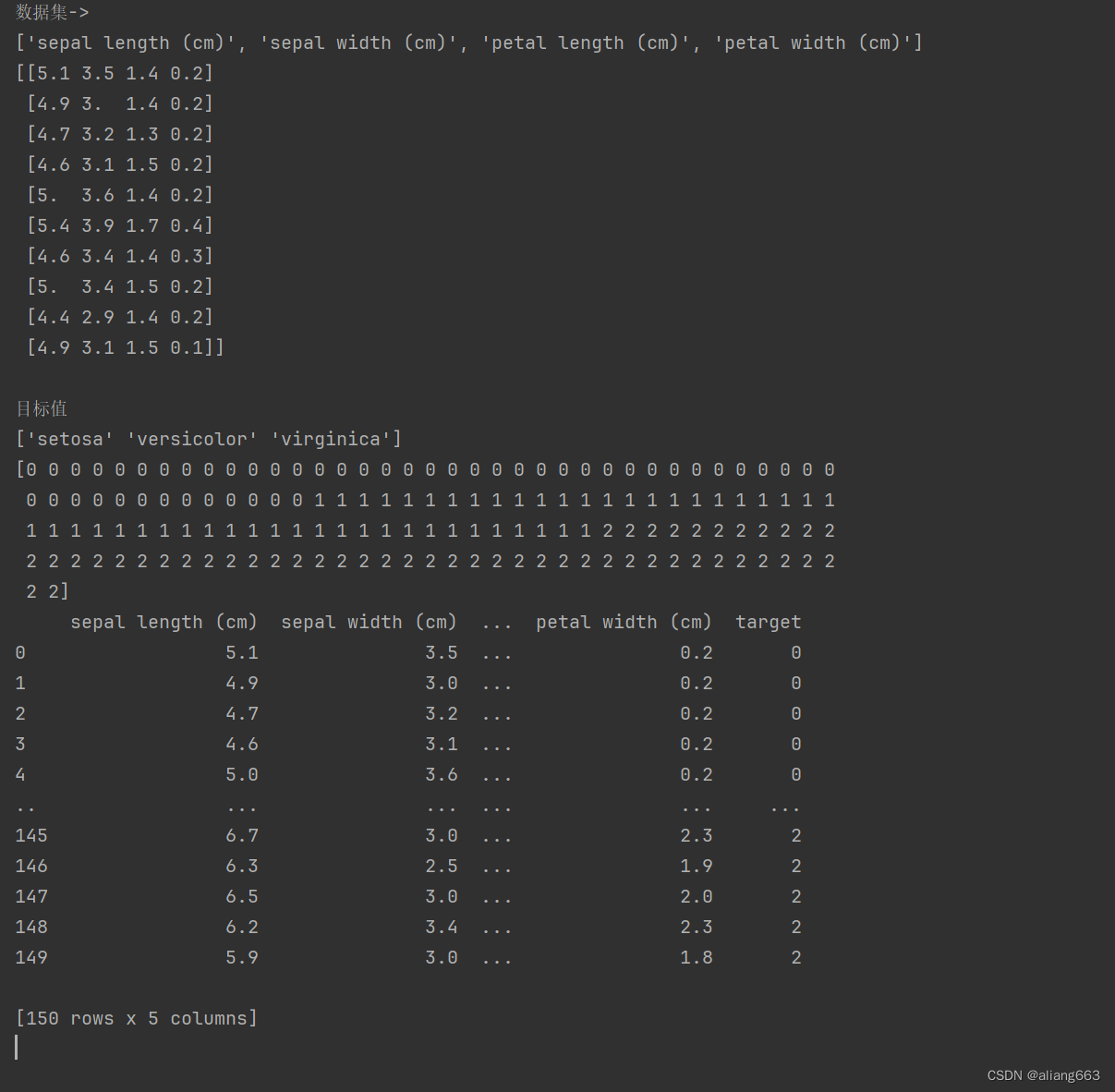
print(f'数据集->\n{iris_data.feature_names}\n{iris_data.data[:10]}')
print(f'\n目标值\n{iris_data.target_names}\n{iris_data.target}')
#数据展示
def dm02_irisdata_show():
iris_df = pd.DataFrame(iris_data['data'], columns=iris_data.feature_names)
iris_df['target'] = iris_data.target
print(iris_df)
feature_names = list(iris_data.feature_names)
#print(feature_names)
for i in range(len(feature_names)):
for j in range(i+1, len(feature_names)):
col1 = feature_names[i]
col2 = feature_names[j]
sns.lmplot(x=col1, y=col2, hue='target', data=iris_df, fit_reg=False)
plt.xlabel(col1)
plt.xlabel(col2)
plt.title(f'{col1}vs{col2}')
plt.show()
#sns.lmplot(x='sepal length(cm)', y='sepal width(cm)', hue='target', data=iris_df)
#plt.show()
dm02_irisdata_show()
#3数据基本处理
transfer = StandardScaler()
x_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.3)
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform((x_test))
#print(x_train)
#4特征处理
#5数据标准化
model = KNeighborsClassifier(n_neighbors=5)
#6训练
model.fit(x_train, y_train)
#7评估
#y_pre = model.predict(x_test)
#score = accuracy_scoer(y_test, y_pre)
#print(score)
score2 = model.score(x_test, y_test)
#8预测
mydata = [[5.1, 4.3, 3.2, 2.1],
[4.6, 3.1, 1.5, 0.2]]
mydata = transfer.fit_transfore(mydata)
predata = model.predict(mydata)
#print(predata)















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









