







目录
tcp协议
介绍
传输层协议介绍(tcp,udp),可靠性和不可靠性_可靠传输服务和不可靠传输服务 udp tcp-CSDN博客
网络通信中字节流存在的问题,tcp协议特点,自定义协议(引入+介绍,序列化反序列化介绍,实现思路)_自定义tcp通信协议-CSDN博客
tcp协议的应用场景比udp要更广
- 大多数的应用层协议底层都使用的是tcp,比如http协议
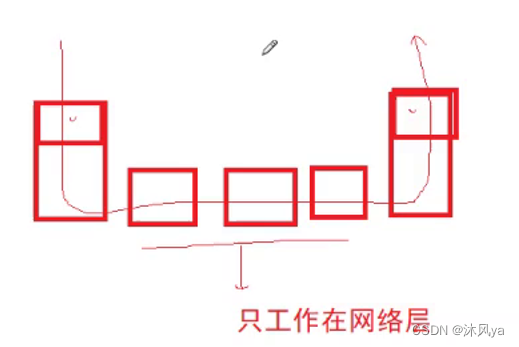
端到端
tcp协议维护的是端口信息,这个信息是只有双方主机才会直接读取到的
- 因为tcp协议只会出现在双方主机中,路由器是没有传输层的(当然也可以有,但我们不需要,因为路由器只工作在网络层 )
- 所以tcp被称为是端到端的
- 路由器看不到也不需要知道端口号信息
传输控制协议
图解
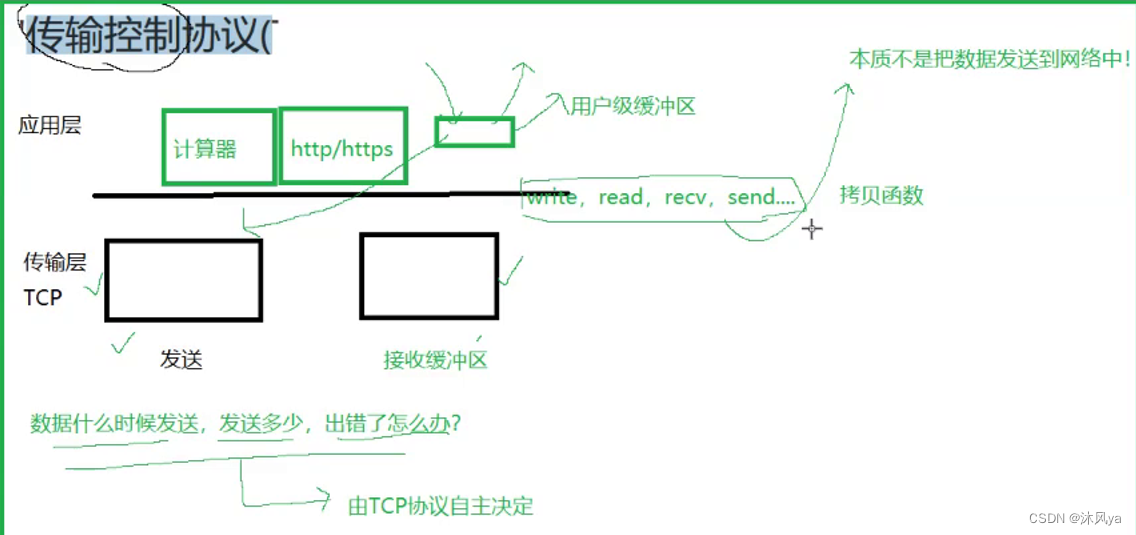
所以,我们把数据通过接口发送,其实就相当于把数据交给了内核(传输层在内核里)
- 就像我们使用文件接口将数据写入文件一样,都是交到了内核中的缓冲区
一个是tcp协议专用的发送缓冲区,一个是文件专用的io缓冲区
- 只不过经过的硬件设备不同,一个是网卡,一个是磁盘
- 所以,都属于io过程
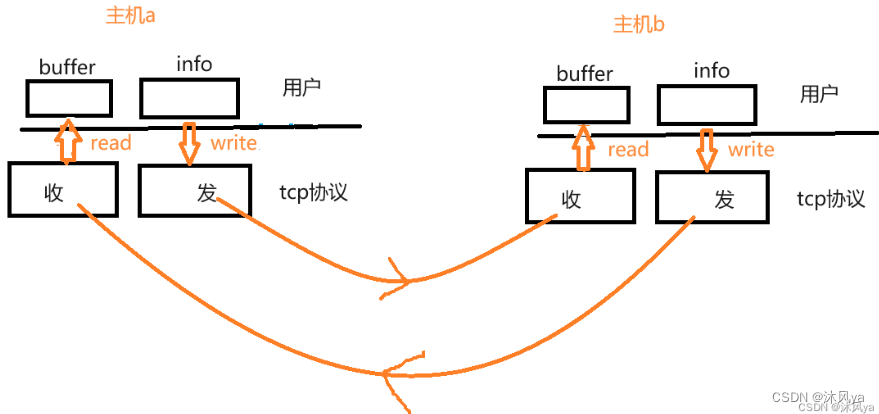
全双工
从tcp协议角度来看
- 发送的过程就是将自己发送缓冲区里的内容交到(拷贝到)对方的接收缓冲区里
当一方读取时
- 如果此时自己的接收缓冲区里没有数据(也就是资源不就绪),就会阻塞,直到有数据进来再唤醒
因为一个文件描述符配套了两个缓冲区
- 所以tcp协议也是可以既读又写的,也就是全双工
缓冲区
缓冲区其实就是由多个4kb大小的内存块组成的,并且每个内存块都有对应的struct page结构来管理
然后以某种数据结构将结构体组织起来
那么对内存的管理,就变成了对这一堆结构体做管理
虽然这些内存块都是4kb,但用处有不同
有的用来作为文件缓冲区,有的作为网络缓冲区
控制
而tcp协议之所以可以实现控制,就是因为它有发送缓冲区
- 它可以在对方接收缓冲区满时,先将数据存放着,等有位置了再发
而udp连发送缓冲区都没有,也就没有控制能力,除非有应用层帮它手动搞一个
tcp协议段格式
数据在不同层的名称
我们之前说过,数据在每一层都有自己的名字
- 应用层 -- 请求/响应
- 传输层 -- 数据段
- 网络层 -- 数据报
- 链路层 -- 数据帧
图解
大致分为三层:
- 标准报头(固定20字节)
- 选项(这里我们不介绍)
- 有效载荷
其中,标准报头+选项=报头
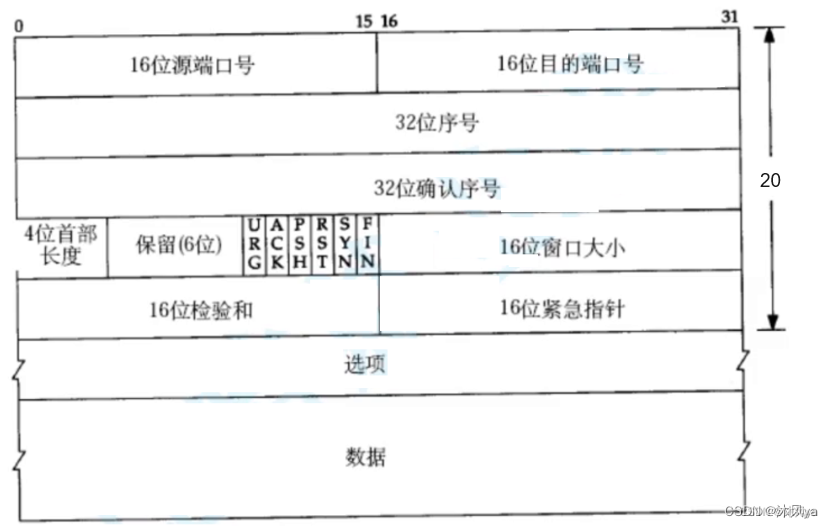
端口号
通过报头里的目的/源端口号,我们就可以定位上层服务
首部长度
我们该分离报头和有效载荷呢?
- 虽然标准报头的长度固定是20字节,但选项并不固定(可以有,可以没有)
而标准报头中的首部长度记录的就是整个报头的长度
- 首部长度-20=选项长度
因为是4位,所以最大长度为2^4-1=15字节?
- 也就是[0000,1111]
- 但是光标准报头就有20字节了耶,肯定是放不下的
那它究竟是什么?
- 其实它是以4字节为单位的
打个比方
- 就像有些人说自己的工资是1500,有人说自己是1.5,其实就是单位不同
所以
- 报头最长是15*4=60字节,选项最长是40字节
- 这种固定长度+自描述字段,就可以知道其他部分的长度了
知道了每个部分的长度,咱们就来具体说说,如何分离报头和有效载荷
- 先读取20字节,拿到标准报头
- 再取出首部长度字段,换成10进制后*4->报头长度,-20=选项长度
- 再读取出选项,剩下的就是数据了
窗口大小 -- 引入
那报头里的窗口大小又是什么呢?
在介绍窗口大小之前,首先我们要明确一个前提
前提
一旦被发送了出去,在到达对方的传输层前,都是具有完整报头的数据
以及要介绍一下tcp的流量控制 :
流量控制
在这个场景下:
- 当应用层忙碌时,可能来不及进行读取,但另一方并不知道,还在持续发送
- 一旦那方的接收缓冲区满了,还继续发送,就会出现丢包
- 这样显然不可靠
而tcp协议的控制能力就体现在:
- 它可以在一方缓冲区满时,控制另一方的发送速度减慢/暂停发送
- 这种控制发送数据的速度的能力,从而规避大面积丢包的能力,就叫做流量控制
但我们之前也说过:
- tcp的可靠性还体现在它可以丢包重传
- 那是不是就没必要进行流量控制了呢?
- 确实是这样,但用了比不用好
想一想
- 一个数据历经多个设备来到目标主机,结果本身没出错,就因为对方缓冲区满了就要重传
- 这期间得浪费多少资源?效率自然就下降了
- 所以,流量控制是必要的
但是,仔细想想,tcp协议是如何让双方知道对方缓冲区情况的呢?
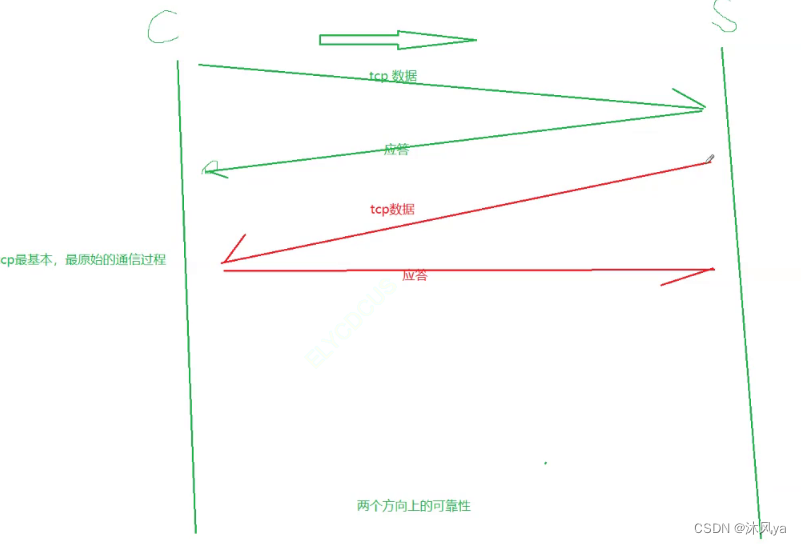
tcp保证可靠性的策略有很多,但其中最基本的是 -- 确认应答机制
确认应答机制
当客户端向服务器发送数据:
- 服务器都要给客户端返回响应,来确定自己已经收到了数据
- 反过来也是一样,这样就能知道对方收到了没
- 就像两个人打电话,一方会询问对方能不能听见,直到对方有回应才能确定对方听见了
所以,我们重新来梳理tcp协议的通信过程:
- 当客户端向服务器发送数据,服务器收到后会立即返回应答
- 如果客户端当前发送速度过快,对方来不及接收,就会调整自己的发送速度
如何调整呢?
- 自然是由服务器的接收能力(也就是服务器的接收缓冲区的剩余空间大小)决定
- 其实就很像生产消费者模型里,生产者和消费者的行为由对方资源数量决定
但是,cp模型里是由条件变量通知各个进程的,这里的客户端如何知道服务器的情况呢?
- 结合上面说的,服务器会给客户端返回应答+基于tcp协议通信时,一定带有完整报头+这里准备要介绍的窗口大小
- 可以猜出,这个窗口大小的字段就是用来记录服务器剩余空间大小的
- 这样就可以动态调整自己的发送速度了
反过来也是一样的:
- 因为服务器也需要给客户端发送响应,也可能会出现客户端的接收缓冲区满的情况,也需要流量控制
窗口大小 -- 介绍
那么,总结一下
- 这个窗口大小,填写的就是自己接收缓冲区的剩余空间大小,用于流量控制
序号 -- 引入
确认应答机制的进一步探讨
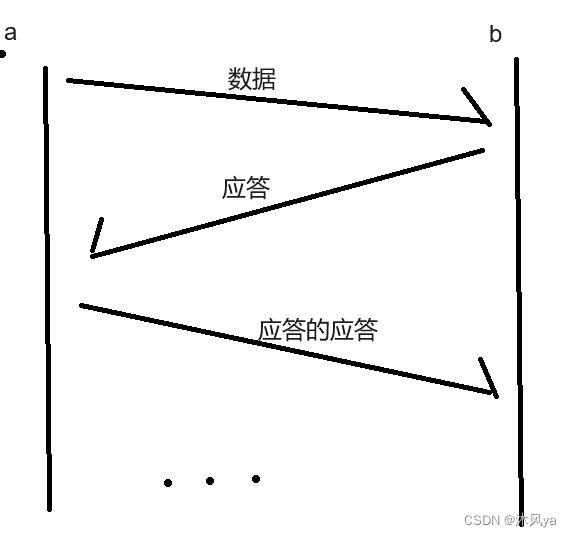
假设a给b发送数据
- 当b收到数据后,会返回a一个应答,来让a知道自己已经收到了
- 当a收到这个应答,就知道自己发的数据b已经收到了
- 然后a又给b发了应答,以此来表示自己收到了b的应答...
这样无穷无尽的...
但是可以看出:
- 只要一方收到了应答,就能知道对方收到了数据.也就能保证该条数据的可靠性
如果我们从某处截断这个过程
- 那么,此时最新的消息是无应答的,也就不能保证接收方收到了(至少发送方是无法知道的)
- 所以,无法保证发出的数据是百分百可靠的
但最新消息之前的消息都是 -- 数据,应答,应答的应答....
- 这些都是可以保证双方的可靠性的
所以:
- 其实,没有必要对[应答]再应答,我们只需要保证局部上的可靠性
- 因为我们无法保证每条消息都是可靠的,那么索性就简单一点,让那个不可靠的是第一个应答即可
比如:
- 只要客户端向服务器发数据后,收到了服务器的应答即可
- 这就已经能让客户端达成了通信的目的 -- 让服务器收到了数据
不需要再让服务器知道客户端收到了应答,跟它没关系了
- 我们只保证单方向的可靠性就行
- 反过来也是一样,服务器只要保证客户端收到数据了即可,不需要让客户端知道服务器收到了应答
如果应答丢失
但是,万一这个应答中途不小心丢了呢?
- 发送方不知道
- 而接收方以为对方没有发送应答,就代表对方没有收到我发送的消息
仔细想想,接收方如何知道对方有没有返回应答?
- 等待对方的消息
那就会有两种情况,等到了/没等到
- 但接收方难道会一直等吗?
- 要是就是应答丢包了/甚至自己的消息在中途丢失了怎么办,总不能因为这一条消息把接收方卡死在这了吧
- 所以,它只会等待一段时间,时间过后还没有收到,接收方就认为数据已丢失(无论是自己的或者对方的),就会进行重传
- 反之,对方也采取同样的策略对待发送的数据
上面的过程其实就像我们现实中打电话
- 当你询问对方是否能听见,如果对方有回应,你就知道对方听见了
- 如果没有,你就不确定对方到底听没听见,你会重复询问,直到有回应
- 而重复了几次依然没有,我就会挂电话了,另找个时间再打(对应tcp协议的重传,不一定一模一样哈,只是个例子)
捎带应答
按照我们上面说的,一方收到数据后会先给对方发送应答,再进行通信
- 这就可能会导致效率问题
就像:
你吃饭了没
收到
没吃呢
收到
我也没吃呢,要不咱一块去吃
收到
那走
收到
走
- 是不是这种通信方式明显是没有必要的?
- 明明可以合并在一起说,非要把应答和响应拆开发两次
- 而把应答和响应结合起来,这种策略叫做捎带应答
发送多条数据
如果发送方连续给接收方发送多条消息怎么办?
- 注意,双方一定是并发(你发你的,我收我的)的,串行(直到收到对方的应答再发下一条数据)效率可太低了
首先,我们先明确一点,发送的顺序不一定就是到达的顺序
- 可能因为某种原因导致先发送的慢到达
而造成乱序,本身就是不可靠的一种体现
- 也许本身就需要这些数据保持原顺序呢?
- 也许打乱顺序会造成某些影响呢?
而tcp协议是具有可靠性的
- 所以,它需要对这些数据进行排序
序号 -- 介绍
tcp缓冲区其实就是char数组
这里我们把char就看作是一个字节,然后数据被填充进去都是以字节排列的,所以天然就存在序号(也就是数组下标)
- 而我们把每个报文的最后一个字节对应的下标,称为该条报文的序号
- 这个图也只是示意图,并不是实际情况
所以,根据序号,我们就可以对收到的数据进行排序

确认序号
引入
按照我们上面的过程,发送方和接收方是一来一回的
- 那么接收方收到多条消息时,同样也会发送多个应答
这里的应答并不一定会按照发送顺序返回
- 先发送的可能因为某个原因后到达,总之顺序是不一定的
- 但是!!!收到应答的发送方该如何知道对方是对哪条数据做的应答呢???
因为数据有可能会丢失
- 所以一来一回的数量不一定相等,那就存在数据没有发送+接收成功
发送方该如何定位呢?
- 也就是报头里的确认序号的作用
介绍
确认序号是对应报文序号+1
为什么呢?
- 它表示[确认序号]之前的字节我都已经收到了
- 下次你要发送的数据从[确认序号]开始
比如
- 一个报文里的序号是1000,当接收方收到后,返回的应答里的确认序号就是1001
这个设计有一个好处:
- 当应答丢失了,它可以根据最大的确认序号来知道自己该重发哪些内容
示例
比如: 发送的报文序号有1000,2000,3000
收到的应答的确认序号只有3001:
- 这说明1001,2001的应答都丢失了
- 但根据确认序号的特性,能发送3001的确认序号,就一定是前3000个字节已经处理了
- 所以不需要重传前2000个字节的数据,即使应答丢失
- 也就是说,它可以允许少部分的应答缺失
如果收到的是两个1001:
- 则说明序列号为2000的报文丢失
- 第一个1001:收到1000后发送的应答
- 第二个1001:收到3000后,但由于2000丢失,所以仍然发送1001,说明它仍然在期待1001字节开始的数据
- 所以系统将重传2000的数据
为什么要有两个序号
为什么一定要把这两个序号分开呢?不能只定义一个变量来接收吗
- 比如,发送方把它填充成序号,接受方填充成确认序号
但因为可能存在捎带应答,也就是--
- 既是对发送方的应答(填充确认序号)
- 又有接收方想要对发送方发送的数据(填充序号,因为这个数据也可能是连续发送,需要排序)
而又因为全双工
- 双方地位是对等的,随时可能互发消息
- 所以捎带应答的情况很普遍
所以,最好是把这两个序号分开
标志位
引入
tcp建立连接/正常通信/断开连接,客户端都需要和服务器交互,并且服务器的行为均不同
- 三次握手
- 分离数据做出处理
- 四次挥手
交互,也就是要发送tcp报文
- 一定包含报头,数据可以没有
但是,一个报文如何对应多种行为呢?
- 那么,tcp报文本身就得有不同的类型
- 结合上面,我们不难猜出,报头中一定有字段可以表示报文类型 -- 6个标志位
介绍
tcp协议和报头是由os决定的,标志位也不例外
- 这些标志位不能直接被用户改写,而是要通过os提供的系统调用来帮助修改 / 由系统自主决定
SYN
用于标识该报文是否用来建立连接
- 而我们建立连接使用的是connect函数
- 联系起来则可以知道,connect函数会构建一个设置了SYN(置1)的报文发给服务器
FIN
用来告诉对方,自己想要断开连接
- 比如,我们调用close来关闭套接字(用fd操作)
PSH
也就是push的缩写,从名字就可以知道,它用来催促对方交付数据
- 具体应用于什么场景呢?
引入
tcp协议有两个缓冲区,有人往里放,有人往外拿
- 如果用户不读取,接收缓冲区内就会堆积数据
- 一直不读取,接收缓冲区满了后,发送缓冲区就会堆积,从而导致写阻塞
是不是很像cp模型
- 生产者是系统 (将a主机发送缓冲区内的数据,发送到b主机的接收缓冲区内)
- 消费者是用户 (将数据从接收缓冲区拿到用户层)
只不过这里是系统级别的cp模型
前面说的流量控制,换个视角看就是:
- 在根据空间资源控制生产者的生产行为
- 也就是发送过程的同步控制
写阻塞问题
接着上面说的写阻塞继续
- 写阻塞后,写入方就得等待缓冲区腾出空间后再写入
等多久呢?腾出空间后又该如何得知呢?
有两种方式:
- 发送方会定期询问对方是否有剩余空间 (记得吗,tcp的确认应答机制 -- 收到报文后会返回应答,在应答中可以带上空间大小)
- 接收方如果剩余空间大小更新了也会通知发送方
这两种机制同时存在,哪个奏效了就算哪个
解决
如果多次询问无果,且没有收到空间更新的消息,自己的发送缓冲区又压力很大
- 发送方就会发送带有PSH标志位(置1)的报文给对方,让对方赶紧把数据交付给上层来腾出空间
- 这样可以宏观提高通信效率
说是压力很大,但这个机制会在还有一定空间时就触发,而不是满了再说
- 所以对方还是可以接收到的
但如果对方就是不读取呢?
- 毕竟读到应用层是需要客户端主动调用函数的
首先,我们先排除故意不读的情况
- 一旦是这样,这个代码就是错的,我们不讨论它
所以,只能是当前客户端太忙才没有读取,但这里就不多介绍了
ACK
标识我们的报文是否具有应答属性
我们大部分的报文都默认将该位置1
- 因为报文要么是单纯的应答/数据,要么是携带了数据的应答,是应答的可能性很高
而具体的类型就由是否有数据+ack是几来确认
- 如果ACK为0,则是单纯的数据
- 如果ACK为1,再看它是否携带数据
- 是,则为携带了数据的应答报文
- 否则为应答报文
RST
引入
建立连接一定会成功吗?
- 当然不是
- 通信过程中总会有各种问题出现
虽然tcp可靠,但也不是100%的可靠
- 如果是客户端的异常操作把连接弄挂了/出现其他不可抗力的异常,再可靠也没办法,我们必须依赖应用层的逻辑来处理
- 应用层可以实现逻辑来捕获这些错误并重试连接
应用场景1
引入 -- 连接结构体
服务端可以存在多个建立好的连接
- 毕竟服务肯定是面向大众的,一定会有多个客户端连接
- 也就会维护多份多份通信数据
要不要管理?
- 当然要,所以系统内会为了维护连接而创建结构体
- 该结构体内可能包括 : 连接的属性,起始序号,确认序号,建立连接的时间,双方的端口号,缓冲区的位置等等
所以,创建/维护连接都是有成本的
- 三次握手成功后,需要创建内核数据结构,并初始化,一直保存结构到断开连接
双方认知不一致
这样的话
- 有可能三次握手虽然成功了,但内核结构没有建立好/建立过程中出现了问题
那么就可能其中一方的内核数据结构没有正确初始化或建立
- 那么客户端,服务端对建立连接的结构认知是不一样的,这种情况下是无法正常通信的
- 所以就需要服务器给客户端发送一个设置好RST标志位的报文,强制断开连接,重新来过
应用场景2
三次握手
这是三次握手的情况
注意哈,虽然这里只写了标志位
- 但其实是设置好该标志位的tcp报文
至于为什么斜线呢?
- 我们把纵轴看作是时间轴,而发送和接收肯定是具有时间差的
- 所以是斜线
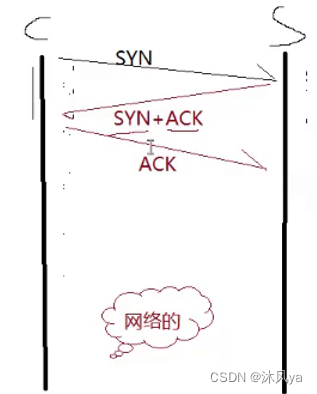
双方不一致
对于客户端来说
- 发送完应答就完成了三次握手(没办法,因为不能再为应答发应答了,不然就无限循环了)
- 然后就会建立连接结构体,准备之后的通信
对于服务端来说
- 收到了应答才算完成
基于这样的情况,就很可能出现双方认知不一致的结果:
- 在三次握手中,前两条报文都是有应答的,而第三条没有,客户端只能赌这条报文被服务端收到了
- 那万一就是丢失了呢?
- 那么服务端没有收到应答,就不认为连接建立好了
- 可客户端以为连接建立好了,它会从connect函数返回,进入通信流程
也就是发送数据给服务器
- 那服务器收到数据就懵啦,怎么还没建立好连接就开始通信了,咱们不是遵守的同一套协议吗
- 所以,服务端只能认为和客户端有误会,客户端以为已经建立好了,实际并没有
- 于是服务器发送带有RST标志位的报文给客户端,告诉对方:别通信啦,你连接都没建立好呢,赶紧重新建立一下
- 这样客户端收到后,就会意识到,原来我刚刚建立的连接是有问题的
- 于是就会重新开始三次握手流程
应用场景3
服务器内部出现异常,重启/其他什么的,把数据清空了
- 但客户端并不知情啊,依然对服务器发送数据
- 这时候肯定是无法通信的,客户端以为连接还在,实际上另一端早就没有了
- 也需要重新建立连接
总结
这个标识位用于 -- 在双方建立连接异常的情况下,对连接状态进行重置
- 在建立连接中/通信中,都有可能存在异常
就是我们经常在网页上看到的,"连接已重置"
URG(紧急指针字段)
引入
tcp协议的可靠性,保证了数据可以按序处理
但是,如果我们就是想让某个数据被优先处理该怎么办?
- 就只能引入新的机制了
介绍
- 当URG为0时,表示无效,紧急指针无意义
- 为1时,紧急指针有效
说了半天,紧急指针是个啥呢?
- 它也是tcp标准报头中的一个字段
- 存放的是紧急数据在该报文的数据部分的偏移量
但是,只有偏移量,我们怎么知道紧急数据有多少呢?
- 紧急数据默认是一个字节,并且无法修改这个上限
- 因为tcp要保证主体数据是有序的,可以插队,但不能太多
如何读写
send /recv函数中有一个参数flags
- 它可以被填充成 MSG_OOB
- 它用来表示,发送的数据是带外数据(也就是紧急数据)
应用
当一个服务本身没有问题,没有挂掉,只是响应很慢/没有响应时
- 也许是在执行周期性任务,比较吃资源
- 也许当前计算量太大
我们需要知道服务器此时处于什么情况,就会向服务器询问
- 不然只是单纯等待吗,那得等到啥时候,有问题就得解决问题,首先得知道到底是在干啥
所以,服务器需要支持这种不同于普通通信的询问机制 -- 可以读取紧急数据+定义多个服务器状态字段
- 并且,如果让询问也乖乖地和普通报文一样排序,就是本末倒置了
- 本来我们就是因为没有响应才去询问的,等轮到处理询问的时候肯定已经有响应返回了,还询问什么
- 所以,需要让他插队,也就是发送紧急数据(可以被优先处理)
然后服务器会专门有例程来读取紧急数据
- 又因为紧急数据很小,很快就可以处理完成
- 所以,可以立即返回当前服务器的状态编号
这样客户端就可以知道此时服务器处于什么状态了
虽然有如上的应用场景,但我们一般用不到















 4364
4364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









