






一、安装Scrapy
命令:sudo apt-get intall scrapy 或 pip/pip3 install scrapy
二、Scrapy项目开发流程
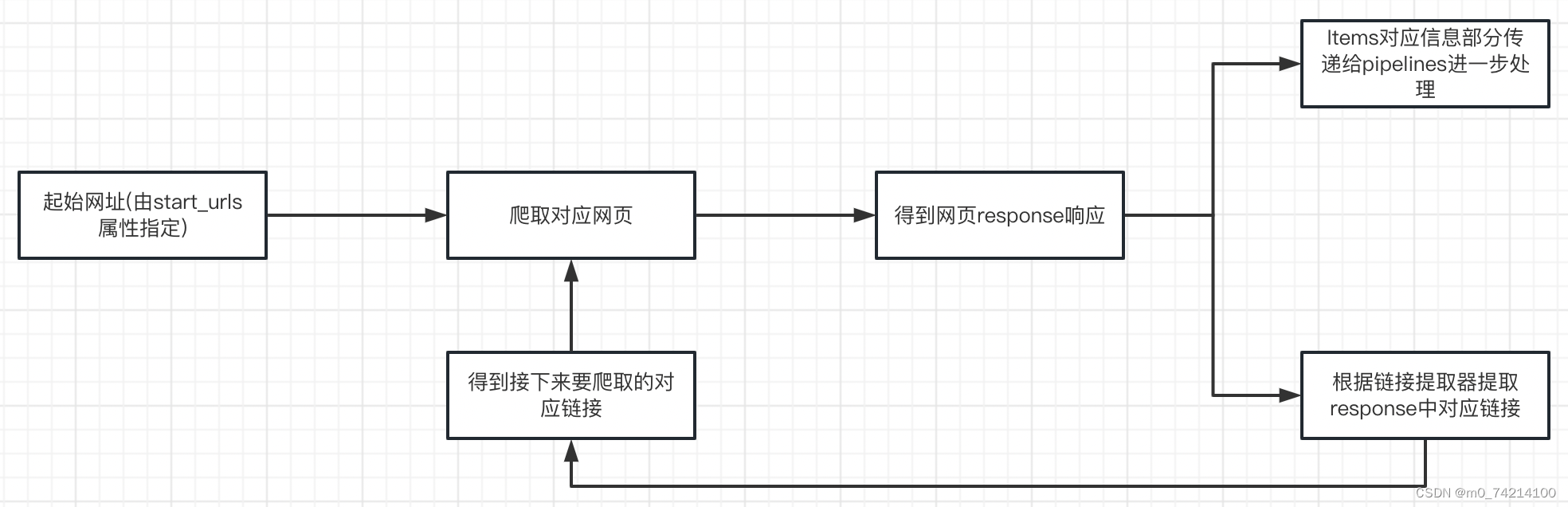
1.创建项目
scrapy startproject weibo2.创建爬虫
cd weibo
scrapy genspider weibo news.sina.com.cn3.完善爬虫
①修改起始url
②检查修改允许的域名

③定义Items类

④在parse方法中实现爬取逻辑
⑤使用xpath提取数据
安装 pip install lxml
使用xpath选择器提取HTML数据

⑥利用管道pipeline来处理(保存)数据
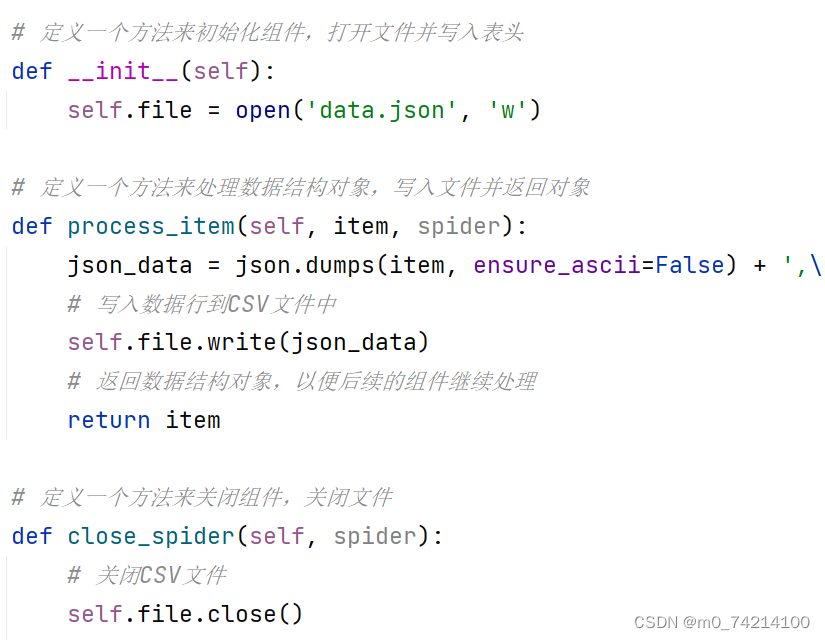
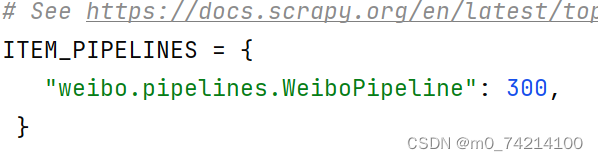
⑦在settings配置启用管道
三、scrapy实现反反爬技术
①在middlewares定义UA,随机ip代理


②在settings中开启自定义的下载中间件
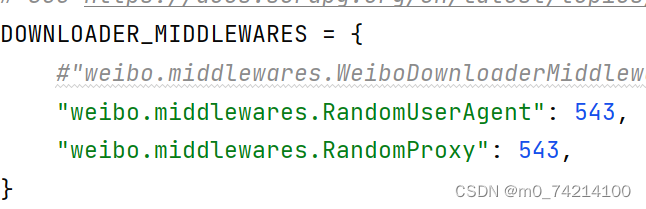
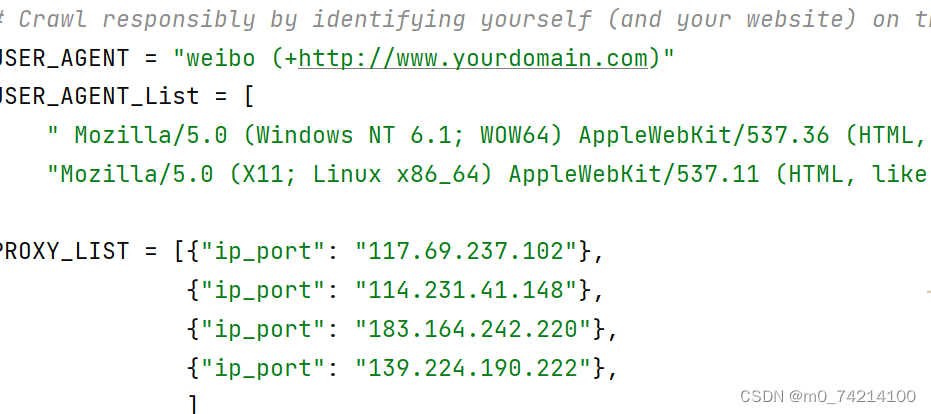
③在settings中添加UA列表,IP列表
四、启动爬虫
scrapy crawl weibo
















 1581
1581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









