






1.前期准备:
(1)最好看看我之前写的一篇文章,
文章链接:spark的安装配置-CSDN博客
(2)scala-2.12.11.tgz下载链接:
Linux 安装 scala2.12.11-腾讯云开发者社区-腾讯云

2.配置Scala
(1)登录hadoop用户,并且切换Linux本地的/export/server日录下
su - hadoop
cd /export/server(2)上传安装包scala-2.12.11.tgz到Linux本地的/export/server日录下
rz(3)将安装包解压到/export/server下
tar -zxvf scala-2.12.11.tgz -C /export/server/
(4)先切换root用户然后,在/etc/profile末尾添加Scala路径
su - root输入密码后再依次输入以下代码
vi /etc/profileexport SCALA_HOME=/export/server/scala-2.12.11
export PATH=$PATH:$SCALA_HOME/binsource /etc/profile3.Scala体验
(1)登录hadoop用户,并且切换Linux本地的/export/server日录下
su - hadoop
cd /export/server(2)新建文件hello.scala并且在里面写入以下内容
vi hello.scalaobject HelloWorld {
def main(args: Array[String]): Unit = {
println("Hello, Scala!")
}
}(3)编译运行hello.scala
scala hello.scala对了还有一个命令,只编译不运行,一般都不用
scalac hello.scala4.参考文章
(1)Scala最基础入门教程_scala教程-CSDN博客
(4)Scala 第二篇 算子篇_scala算子-CSDN博客
5.补充笔记:
(1)scala-2.12.11.tgz和scala-2.12.11.zip有什么区别吗
`scala-2.12.11.tgz` 和 `scala-2.12.11.zip` 本质上是两个不同的压缩格式,分别是 `.tgz`(tar.gz 格式)和 `.zip` 格式,它们的区别主要体现在以下几个方面:
1. **压缩格式**:
- `.tgz` 是一个经过 `tar` 打包后,再使用 `gzip` 压缩的文件格式。通常这个格式在类 Unix 系统(如 Linux 和 macOS)中使用得更多。
- `.zip` 是一种广泛使用的压缩格式,适用于各种操作系统,包括 Windows 和类 Unix 系统。
2. **平台支持**:
- `.tgz` 文件更常见于类 Unix 系统(Linux、macOS)中,很多 Linux 用户或开发者习惯使用该格式。
- `.zip` 文件则广泛支持多种平台,特别是在 Windows 上,`.zip` 格式的文件更常见。
3. **解压工具**:
- `.tgz` 文件需要使用类似 `tar` 或 `gzip` 的工具来解压。例如,可以在命令行中使用 `tar -zxvf scala-2.12.11.tgz` 来解压。
- `.zip` 文件可以使用任何支持 ZIP 格式的工具来解压,包括 Windows 的默认文件管理器、macOS 上的 Archive Utility,或命令行中的 `unzip` 工具。
4. **内容一致性**:
- 无论是 `.tgz` 还是 `.zip` 文件,它们包含的内容是一样的,通常都是 Scala 编译器及其相关文件。因此,选择哪个格式并不会影响你使用 Scala 的功能。
5. **性能和效率**:
- `.tgz` 格式通常会有稍微更好的压缩效率,因为 `tar` 和 `gzip` 的组合通常能在保持高压缩比的同时提供较好的解压性能。
- `.zip` 格式的压缩效率可能略低,但解压速度和跨平台支持是它的优势。
总结来说,`scala-2.12.11.tgz` 和 `scala-2.12.11.zip` 的内容没有差异,区别主要是文件格式以及适用的操作系统和解压工具。如果你在 Linux 或 macOS 上工作,可能更倾向于使用 `.tgz` 格式;如果你在 Windows 上,`.zip` 格式可能更加方便。

(2)在linux虚拟机上面我的spark版本是3.4.4,请问我的scala版本为什么才不会和spark冲突呢
在使用 Apache Spark 时,确保 Scala 版本与 Spark 版本兼容非常重要,因为 Spark 是用 Scala 编写的,并且需要特定版本的 Scala 来与 Spark 正常工作。
对于 Spark 3.4.4 版本,官方推荐使用以下的 Scala 版本:
- Scala 2.12.x 或 Scala 2.13.x
具体来说,Spark 3.4.x 支持这两个 Scala 版本,但不能直接与 Scala 3 兼容,因为 Spark 3.x 并没有针对 Scala 3 进行优化和测试。
如何选择合适的 Scala 版本?
-
Scala 2.12.x:是 Spark 3.x 版本的默认推荐版本,许多 Spark 3.x 的发行版本和官方文档都会使用 Scala 2.12。
-
Scala 2.13.x:也是兼容的版本,但需要确保所使用的 Spark 3.x 版本是编译为 Scala 2.13 的。通常,在 Scala 2.13 中会有一些改动或性能改进,但大多数 Spark 的发布版本使用的是 Scala 2.12。

6.spark-shell使用教程:(好像是配好了spark和scala后就可以通过spark-shell来启动了)
(1)老师布置了一个任务要实现下图所示效果,就需要先启动spark和hadoop集群,然后通过spark-shell命令进入scala命令行
-
确保你在 Spark 环境中运行: 在正常的 Spark 应用程序中,你需要先创建一个
SparkContext对象。比如在使用 Spark Shell 时(即使用spark-shell而非普通的scalaREPL),sc会自动初始化。而在普通的 Scala REPL 中,你需要手动初始化一个 SparkContext。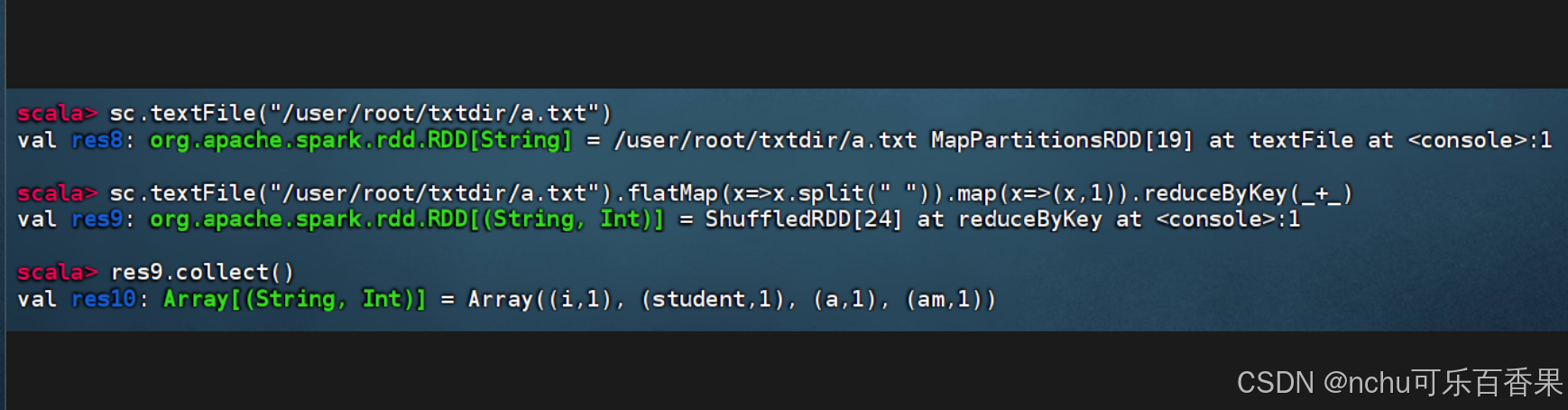
首先spark要配置好可以看看这篇文章
接着输入以下命令
su - hadoop
start-dfs.sh
start-yarn.sh
cd /export/server/spark-3.4.4-bin-hadoop3/sbin
./start-all.sh
spark-shell效果如下
Last login: Tue Dec 3 23:14:48 CST 2024 from 192.168.88.1 on pts/1
[root@node1 ~]# su - hadoop
Last login: Tue Dec 3 23:17:01 CST 2024 on pts/0
[hadoop@node1 ~]$ start-dfs.sh
Starting namenodes on [node1]
Starting datanodes
Starting secondary namenodes [node1]
[hadoop@node1 ~]$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
[hadoop@node1 ~]$ cd /export/server/spark-3.4.4-bin-hadoop3/sbin
[hadoop@node1 sbin]$ ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /export/server/spark-3.4.4-bin-hadoop3/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-node1.out
node3: starting org.apache.spark.deploy.worker.Worker, logging to /export/server/spark-3.4.4-bin-hadoop3/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node3.out
node2: starting org.apache.spark.deploy.worker.Worker, logging to /export/server/spark-3.4.4-bin-hadoop3/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node2.out
[hadoop@node1 sbin]$ spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
24/12/03 23:21:02 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://node1:4040
Spark context available as 'sc' (master = spark://node1:7077, app id = app-20241203232107-0000).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.4.4
/_/
Using Scala version 2.12.17 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_212)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
先另外开一个窗口,把a.txt创建好并且上传到hadoop集群输入以下命令
a.txt内容
Hello World Our World
Hello BigData Real BigData
Hello Hadoop Great Hadoop
Hadoop MapReduce[hadoop@node1 server]$ hadoop fs -put a.txt /
[hadoop@node1 server]$ hadoop fs -ls /
Found 11 items
-rw-r--r-- 3 hadoop supergroup 92 2024-12-03 23:28 /a.txt
drwxrwx--- - hadoop supergroup 0 2024-11-03 16:09 /data
drwxr-xr-x - hadoop supergroup 0 2024-11-14 15:49 /export
drwxr-xr-x - hadoop supergroup 0 2024-11-17 19:50 /hbase
drwxr-xr-x - hadoop supergroup 0 2024-11-13 14:39 /hdfs_api2
drwxr-xr-x - hadoop supergroup 0 2024-11-14 15:56 /myhive2
drwxrwxrwx - hadoop supergroup 0 2024-11-20 09:11 /output
drwxr-xr-x - hadoop supergroup 0 2024-12-03 23:29 /spark-logs
-rw-r--r-- 3 hadoop supergroup 92 2024-11-18 23:27 /test.txt
drwx-wx-wx - hadoop supergroup 0 2024-11-03 17:07 /tmp
drwxr-xr-x - hadoop supergroup 0 2024-11-03 17:05 /user
[hadoop@node1 server]$
接着就可以回到第一个窗口依次输入以下代码
sc.textFile("/a.txt") sc.textFile("/a.txt").flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey(_+_)第三行的res1是根据第二行代码的输出是res1得来的 (意思就是如果第二行代码的输出是res3,
那么第三行就写res3.collect())

res1.collect()
这个图里面的第二行估计是显示上的bug

scala> [hadoop@node1 server]$ spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
24/12/03 23:41:02 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://node1:4040
Spark context available as 'sc' (master = spark://node1:7077, app id = app-20241203234108-0002).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.4.4
/_/
Using Scala version 2.12.17 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_212)
Type in expressions to have them evaluated.
Type :help for more information.
scala> sc.textFile("/a.txt")
res0: org.apache.spark.rdd.RDD[String] = /a.txt MapPartitionsRDD[1] at textFile at <console>:24
(_+_)> sc.textFile("/a.txt").flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey
res1: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[6] at reduceByKey at <console>:24
#这里估计是显示上的bug
#第三行的res1是根据第二行代码的输出是res1得来的 (意思就是如果第二行代码的输出是res3,
#那么第三行就写res3.collect())
scala> res1.collect()
res2: Array[(String, Int)] = Array((Hello,3), (Real,1), (MapReduce,1), (World,2), (Our,1), (BigData,2), (Great,1), (Hadoop,3))
scala>
(2)如果在启动spark-shell时遇到这样的报错
[hadoop@node1 sbin]$ spark-shell
Exception in thread "main" scala.reflect.internal.FatalError: Error accessing /export/server/spark-3.4.4-bin-hadoop3/jars/mysql-connector-java-5.1.34.jar
at scala.tools.nsc.classpath.AggregateClassPath.$anonfun$list$3(AggregateClassPath.scala:113)
at scala.collection.Iterator.foreach(Iterator.scala:943)
at scala.collection.Iterator.foreach$(Iterator.scala:943)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1431)
at scala.collection.IterableLike.foreach(IterableLike.scala:74)
at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
at scala.collection.AbstractIterable.foreach(Iterable.scala:56)
at scala.tools.nsc.classpath.AggregateClassPath.list(AggregateClassPath.scala:101)
at scala.tools.nsc.util.ClassPath.list(ClassPath.scala:36)
at scala.tools.nsc.util.ClassPath.list$(ClassPath.scala:36)
at scala.tools.nsc.classpath.AggregateClassPath.list(AggregateClassPath.scala:30)
at scala.tools.nsc.symtab.SymbolLoaders$PackageLoader.doComplete(SymbolLoaders.scala:298)
at scala.tools.nsc.symtab.SymbolLoaders$SymbolLoader.complete(SymbolLoaders.scala:250)
at scala.reflect.internal.Symbols$Symbol.completeInfo(Symbols.scala:1542)
at scala.reflect.internal.Symbols$Symbol.info(Symbols.scala:1514)
at scala.reflect.internal.Mirrors$RootsBase.init(Mirrors.scala:258)
at scala.tools.nsc.Global.rootMirror$lzycompute(Global.scala:75)
at scala.tools.nsc.Global.rootMirror(Global.scala:73)
at scala.tools.nsc.Global.rootMirror(Global.scala:45)
at scala.reflect.internal.Definitions$DefinitionsClass.ObjectClass$lzycompute(Definitions.scala:294)
at scala.reflect.internal.Definitions$DefinitionsClass.ObjectClass(Definitions.scala:294)
at scala.reflect.internal.Definitions$DefinitionsClass.init(Definitions.scala:1504)
at scala.tools.nsc.Global$Run.<init>(Global.scala:1214)
at scala.tools.nsc.interpreter.IMain._initialize(IMain.scala:124)
at scala.tools.nsc.interpreter.IMain.initializeSynchronous(IMain.scala:146)
at org.apache.spark.repl.SparkILoop.$anonfun$process$10(SparkILoop.scala:211)
at org.apache.spark.repl.SparkILoop.withSuppressedSettings$1(SparkILoop.scala:189)
at org.apache.spark.repl.SparkILoop.startup$1(SparkILoop.scala:201)
at org.apache.spark.repl.SparkILoop.process(SparkILoop.scala:236)
at org.apache.spark.repl.Main$.doMain(Main.scala:78)
at org.apache.spark.repl.Main$.main(Main.scala:58)
at org.apache.spark.repl.Main.main(Main.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:1020)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:192)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:215)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:91)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1111)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1120)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.io.IOException: Error accessing /export/server/spark-3.4.4-bin-hadoop3/jars/mysql-connector-java-5.1.34.jar
at scala.reflect.io.FileZipArchive.scala$reflect$io$FileZipArchive$$openZipFile(ZipArchive.scala:190)
at scala.reflect.io.FileZipArchive.root$lzycompute(ZipArchive.scala:238)
at scala.reflect.io.FileZipArchive.root(ZipArchive.scala:235)
at scala.reflect.io.FileZipArchive.allDirs$lzycompute(ZipArchive.scala:272)
at scala.reflect.io.FileZipArchive.allDirs(ZipArchive.scala:272)
at scala.tools.nsc.classpath.ZipArchiveFileLookup.findDirEntry(ZipArchiveFileLookup.scala:76)
at scala.tools.nsc.classpath.ZipArchiveFileLookup.list(ZipArchiveFileLookup.scala:63)
at scala.tools.nsc.classpath.ZipArchiveFileLookup.list$(ZipArchiveFileLookup.scala:62)
at scala.tools.nsc.classpath.ZipAndJarClassPathFactory$ZipArchiveClassPath.list(ZipAndJarFileLookupFactory.scala:58)
at scala.tools.nsc.classpath.AggregateClassPath.$anonfun$list$3(AggregateClassPath.scala:105)
... 43 more
Caused by: java.io.FileNotFoundException: /export/server/spark-3.4.4-bin-hadoop3/jars/mysql-connector-java-5.1.34.jar (Permission denied)
at java.util.zip.ZipFile.open(Native Method)
at java.util.zip.ZipFile.<init>(ZipFile.java:225)
at java.util.zip.ZipFile.<init>(ZipFile.java:155)
at java.util.zip.ZipFile.<init>(ZipFile.java:169)
at scala.reflect.io.FileZipArchive.scala$reflect$io$FileZipArchive$$openZipFile(ZipArchive.scala:187)
... 52 more
那么大概率就是因为mysql-connector-java-5.1.34.jar的权限不够,
node1,node2,node3都要修改权限(切换回root用户)
所以可以先查看权限
ls -l /export/server/spark-3.4.4-bin-hadoop3/jars/mysql-connector-java-5.1.34.jar
改权限
chmod 644 /export/server/spark-3.4.4-bin-hadoop3/jars/mysql-connector-java-5.1.34.jar
效果如下:
[hadoop@node1 sbin]$ ls -l /export/server/spark-3.4.4-bin-hadoop3/jars/mysql-connector-java-5.1.34.jar
-r-------- 1 root root 960372 Dec 4 20:36 /export/server/spark-3.4.4-bin-hadoop3/jars/mysql-connector-java-5.1.34.jar
[hadoop@node1 sbin]$ chmod 644 /export/server/spark-3.4.4-bin-hadoop3/jars/mysql-connector-java-5.1.34.jar
chmod: changing permissions of ‘/export/server/spark-3.4.4-bin-hadoop3/jars/mysql-connector-java-5.1.34.jar’: Operation not permitted
[hadoop@node1 sbin]$ su -
Password:
Last login: Tue Dec 10 22:38:30 CST 2024 from 192.168.88.1 on pts/1
[root@node1 ~]# chmod 644 /export/server/spark-3.4.4-bin-hadoop3/jars/mysql-connector-java-5.1.34.jar
[root@node1 ~]# ls -l /export/server/spark-3.4.4-bin-hadoop3/jars/mysql-connector-java-5.1.34.jar
-rw-r--r-- 1 root root 960372 Dec 4 20:36 /export/server/spark-3.4.4-bin-hadoop3/jars/mysql-connector-java-5.1.34.jar
再启动就能够成功了
[root@node1 ~]# su - hadoop
Last login: Tue Dec 10 22:38:56 CST 2024 on pts/0
[hadoop@node1 ~]$ spark-shell
24/12/10 22:47:54 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://node1:4040
Spark context available as 'sc' (master = spark://node1:7077, app id = app-20241210224802-0000).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.4.4
/_/
Using Scala version 2.12.17 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_212)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
scores.txt内容
math John 90
math Betty 88
math Mike 95
math Lily 92
chinese John 78
chinese Betty 80
chinese Mike 88
chinese Lily 85
english John 92
english Betty 84
english Mike 90
english Lily 85通过以下命令启动spark和hadoop三件套,
su - hadoop
start-dfs.sh
start-yarn.sh
cd /export/server/spark-3.4.4-bin-hadoop3/sbin
./start-all.sh接着新开一个窗口在/export/server目录新建文件scores.txt,并且上传到hadoop集群上面去。
cd /export/server
vi scores.txthdfs dfs -put /scores.txt /
hdfs dfs -ls /接着回到第一个窗口,输入spark-shell命令后进入如下页面
[hadoop@node1 ~]$ spark-shell
24/12/10 22:47:54 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://node1:4040
Spark context available as 'sc' (master = spark://node1:7077, app id = app-20241210224802-0000).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.4.4
/_/
Using Scala version 2.12.17 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_212)
Type in expressions to have them evaluated.
Type :help for more information.
scala> 直接鼠标右键粘贴如下命令
val scores=sc.textFile("/score.txt")
val scores1=scores.map(x=>x.split(" "))
val scores2=scores1.map(x=>(x(1),x(2)))
val scores3=scores2.map(x=>(x._1,(x._2.toInt,1)))
val scores4=scores3.reduceByKey((y1,y2)=>(y1._1+y2._1,y1._2+y2._2))
val scores5=scores4.mapValues(y=>y._1/y._2)
val scores6=scores3.reduceByKey((y1,y2)=>(math.max(y1._1,y2._1),math.max(y1._2,y2._2)))
val scores7=scores6.mapValues(y=>y._1/y._2)
scores7.join(scores5).collect
如果这个目录已经存在就要换一个才行。
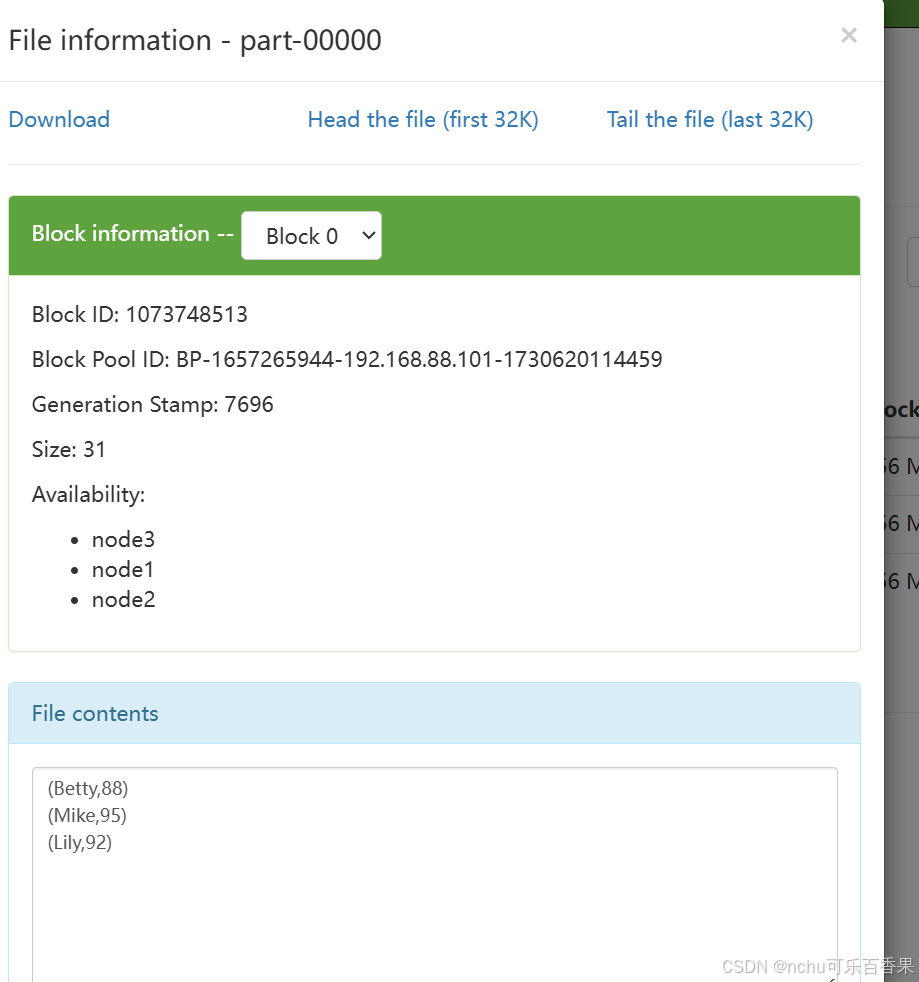
scores7.saveAsTextFile("/outfile1")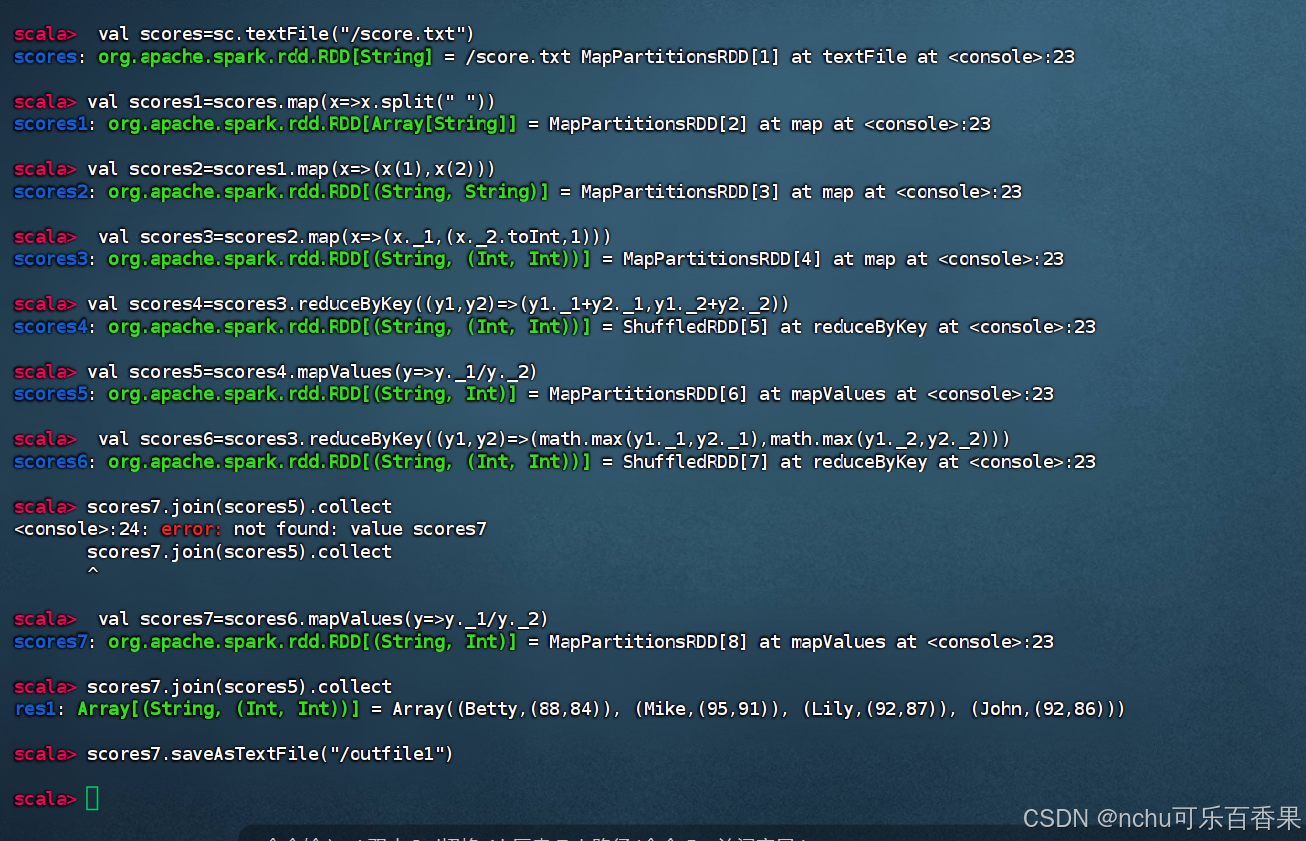
进入node1:9870查看
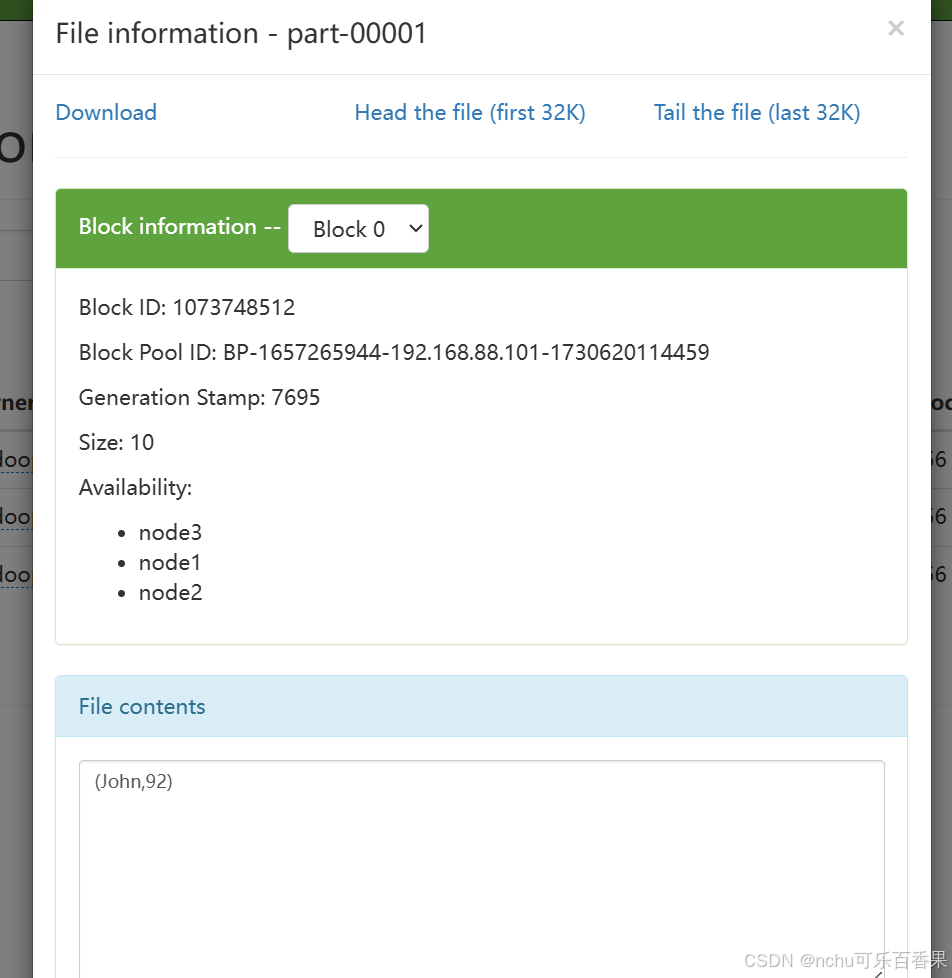

















 1259
1259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









