







标题
1.运行spark-shell --master local[N] 读取本地文件
单机模式:通过本地N个线程跑任务,只运行一个SparkSubmit进程。
创建本地文件,使用spark程序实现单词计数统计
1、准备本地文件
node01服务器执行以下命令准备数据文件
mkdir -p /export/servers/sparkdatas
cd /export/servers/sparkdatas/
vim wordcount.txt
hello me
hello you
hello her
2、通 --master启动本地模式
node01执行以下命令进入spark-shell
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/
bin/spark-shell --master local[2]
3、开发scala单词统计代码
使用这种方式
sc.textFile("file:///export/servers/sparkdatas/wordcount.txt")
.flatMap(x => x.split(" "))
.map(x => (x,1))
.reduceByKey((x,y) => x + y)
.collect
scala语法加简化:下划线来进行替代
sc.textFile("file:///export/servers/sparkdatas/wordcount.txt")
.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_ + _)
.collect
4、运行结果:
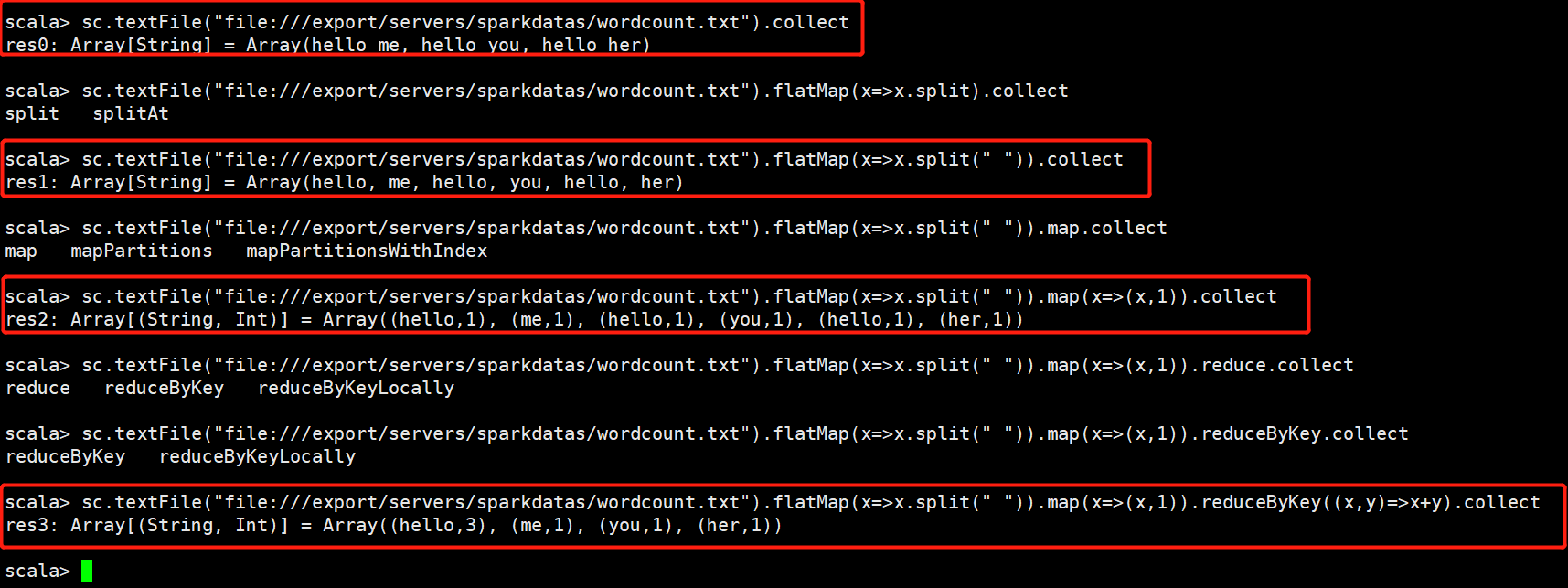
代码说明:
sc: Spark-Shell中已经默认将SparkContext类初始化为对象sc。用户代码如果需要用到,则直接应用sc即可。
textFile: 读取数据文件
flatMap: 对文件中的每一行数据进行压平切分,这里按照空格分隔。
map: 对出现的每一个单词记为1(word,1)
reduceByKey: 对相同的单词出现的次数进行累加
collect: 触发任务执行,收集结果数据。
2.运行spark-shell --master local[N] 读取hdfs上面的文件
1、将我们的数据文件上传hdfs
cd /export/servers/sparkdatas
hdfs dfs -mkdir -p /sparkwordcount
hdfs dfs -put wordcount.txt /sparkwordcountss
2、开发spark的程序
sc.textFile("hdfs://node01:8020/sparkwordcount/wordcount.txt")
.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_ + _)
.collect
3.运行spark-shell --master spark://node01:7077
1、重新进入spark-shell
退出之前的本地spark-shell模式:quit,然后执行以下命令重新进入spark-shell客户端
bin/spark-shell --master spark://node01:7077,node02:7077 \
--executor-memory 1g \
--total-executor-cores 2
2、开发spark程序
开发我们的spark程序,读取hdfs上面的数据,进行wordcount单词统计
sc.textFile("hdfs://node01:8020/sparkwordcount/wordcount.txt")
.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_ + _)
.collect
运行流程图解:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









