






1.哈希表的定义
散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存存储位置的数据结构。
也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,
这加快了查找速度。这个映射函数 称做散列函数,存放记录的数组称做散列表。
称做散列函数,存放记录的数组称做散列表。
2.哈希表的本质
哈希表本质上是个数组,只能说它的底层实现是用到了数组,简单点说,在数组的这个基础上再
捯饬捯饬,加工加工,变得更加有特色了,然后人家就自立门户,叫哈希表。
3.哈希表的分析
一个通俗的例子是在电话薄中查找王二:
第一步:按人名的首字母弄一个表格
第二步:找W,找王二
取姓名的首字母做一个排序,那么通过一些特定的方法去得到一个特定的值,比如这里取人名的
首字母,那么如果是放到数学中,是不是就是类似一个函数似的,给你一个值,经过某些加工得到
另外一个值,就像这里的给你个人名,经过些许加工我们拿到首字母,那么这个函数或者是这个方
法在哈希表中就叫做散列函数,其中规定的一些操作就叫做函数法则。
模型抽象出来: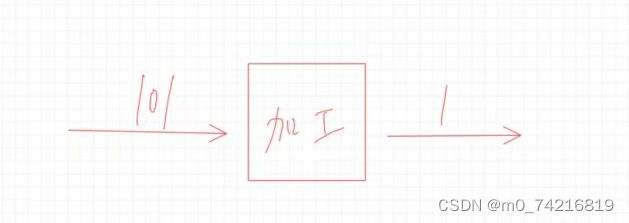
根据未加工之前的101的出来1,这个加工过程其实就是个散列函数,而给它的这个101就是这个关键值
4.哈希表的原理:
在哈希表中是通过哈希函数将一个值映射到另外一个值的,所以在哈希表中,a映射到b,a就叫做键值,而b就叫做a的哈希值,也就是hash值。
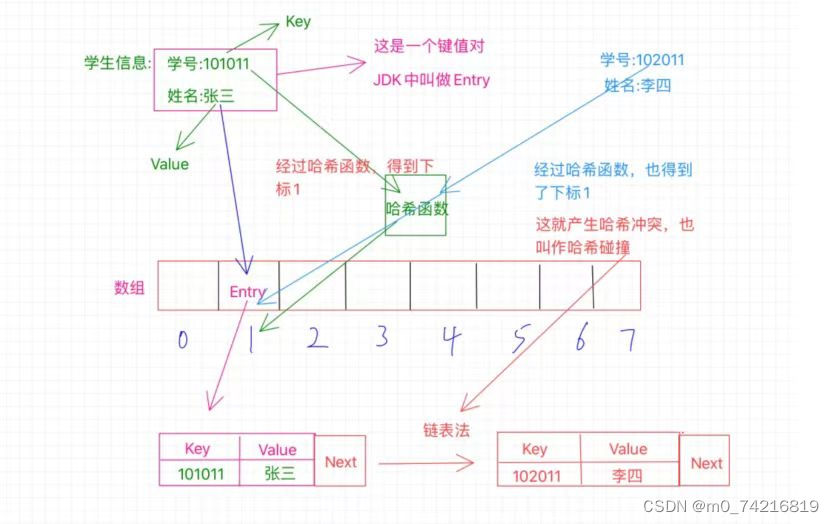
以学号和姓名为例: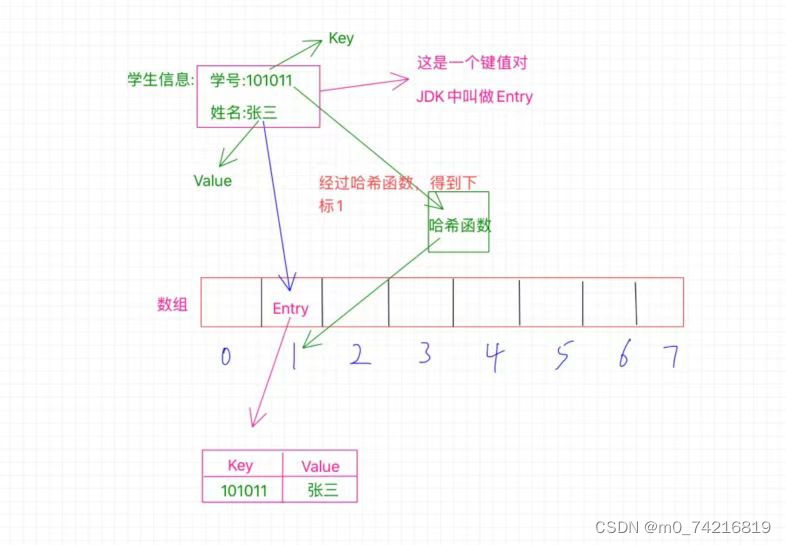
学生的学号和姓名就是一个键值对->Entry啊,根据这个学号就能找到这个学生的姓名
比如这里的学号是101011,那么经过哈希函数的计算之后得到了1,这个1就是告诉我们应该把这
个Entry放到哪个位置,这个1就是数组的确切位置的下标,也就是需要放在数组中下标为1的位
置,如图中所示。
数组中1的位置存放的是一个Entry,它不是一个简单的单个数值,而是一个键值对,也就是存放
了key和value,key就是学号101011,value就是张三,我们经过哈希函数计算得出的1只是为了确
定这个Entry该放在哪个位置而已。
5.哈希冲突
如果说下标1已经被占用了那么我们会发现出现了冲突,有了冲突就得解决冲突
解决办法主要介绍两种第一种开放寻址法
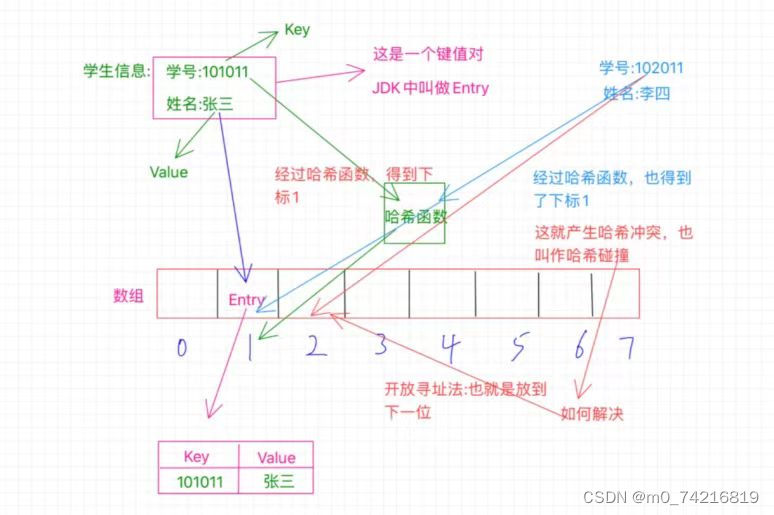
然既当前位置被占用了,我们就看看该位置的后一个位置是否可用,也就是1的位置被占用了,我
们就看看2的位置,如果没有被占用,那就放到这里呗,当然,也有可能2的位置也被占用了,那咱
就继续往下找,看看3的位置,一次类推,直到找到空位置。
第二种拉链法
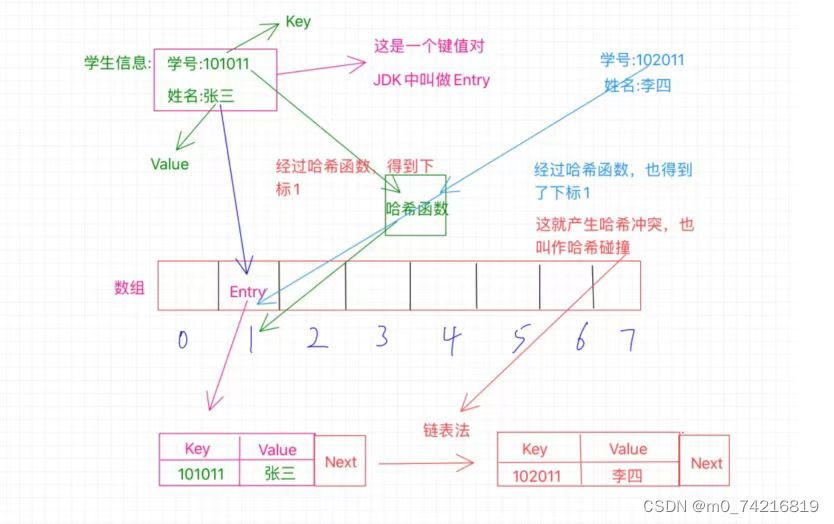
1的位置存放的不单单是之前的那个Entry了,此时的Entry还额外的保存了一个next指针,这个指
针指向数组外的另外一个位置,将李四安排在这里,然后张三那个Entry中的next指针就指向李四
的这个位置,也就是保存了这个位置的内存地址
6.读取数据
我们现在要通过学号102011来查找学生的姓名,怎么操作呢?我们首先通过学号利用哈希函数得
出位置1,然后我们就去位置1拿数据,拿到这个Entry之后我们得看看这个Entry的key是不是我们
的学号102011,一看是101011,什么鬼,一边去,这不是我们要的key啊,然后根据这Entry的next知道下一个位置,再比较key,好成功找到李四。
7.应用: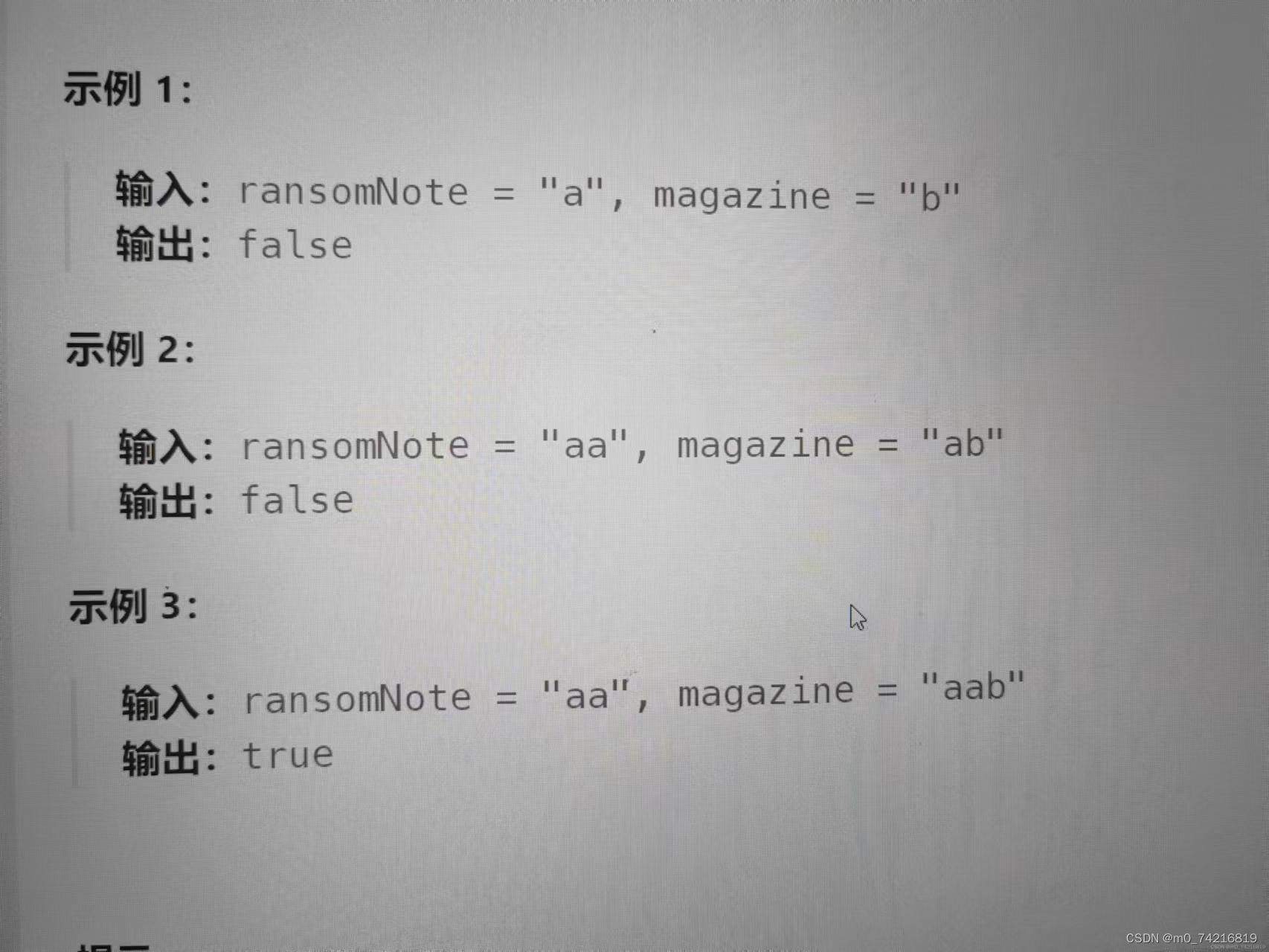 判断第一个能不能由第二个组成
判断第一个能不能由第二个组成
关键字:a
哈希函数:ransomNote[i]-'a'
下标:0
hash[ransomNote[i]-'a']++;
下标0存a的次数















 657
657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









