







引言
互联网高速发展,海量数据充斥着人们的生活,缓存在提升用户体验,提高系统稳定性上永远是一大神器。缓存也分为本地缓存和分布式缓存,本地缓存指的是在应用中的缓存组件,其最大的优点是缓存数据直接存储在应用内部,请求缓存非常快速,没有额外网络开销,而分布式缓存刚好相反,缓存数据跟本地应用在不同的服务器上,多个应用可以共享分布式缓存数据。两种缓存在不同的场景下各有利弊,本文旨在介绍本地缓存在业务中的实践。说到本地缓存,首选Caffeine,为什么是Caffeine,而不是Guava cache呢,可以看下图:
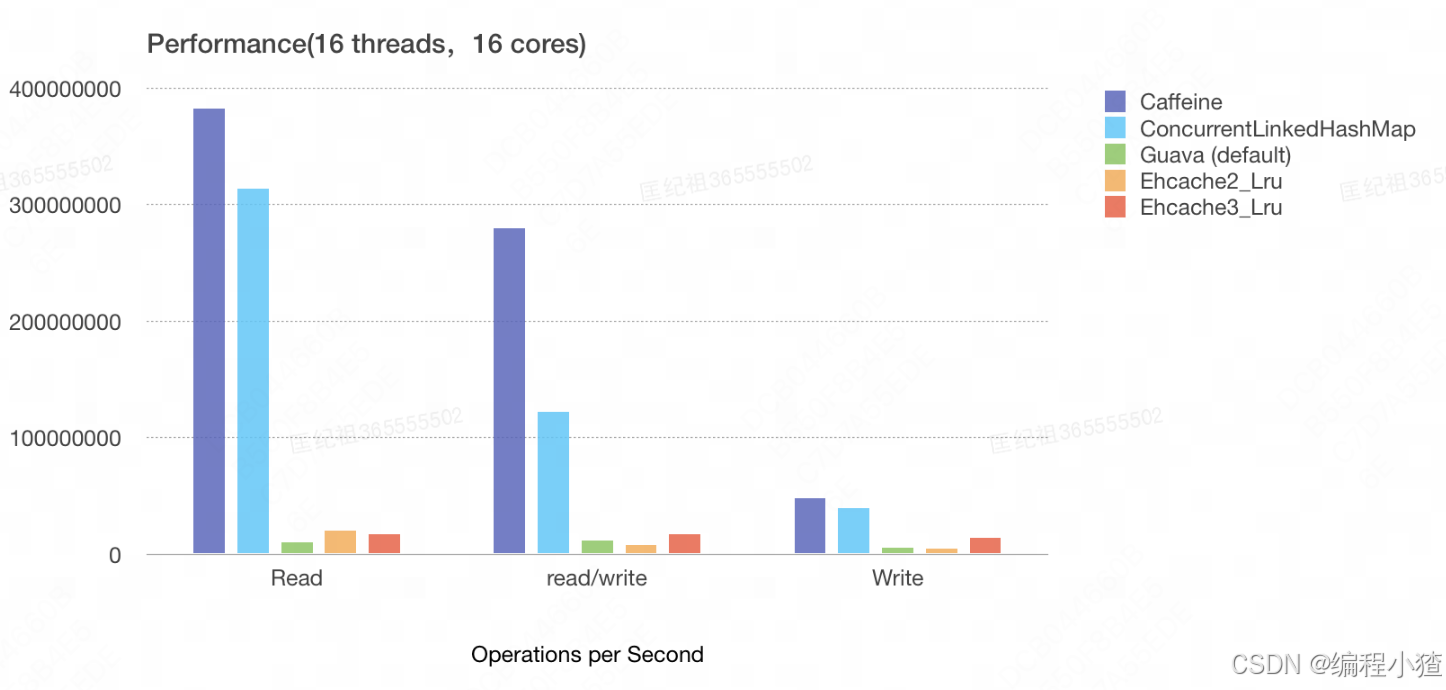
Caffeine官方基于16核的机器对常用缓存组件做了各个维度的测试,可以看到Caffeine无论是读还是写都优于其他缓存组件。可以说Caffeine是guava的升级版,无论是底层淘汰算法,还是读写并发能力,Caffeine都有了很大的提升,而且Caffeine在api上也是兼容guava的,支持guava低成本的迁移到Caffeine。Caffeine也是Spring 5默认支持的Cache,由此可见Caffeine是现阶段公认的“本地缓存之王”。
Caffeine使用
Caffeine的缓存属性
缓存初始容量
initialCapacity :整数,表示能存储多少个缓存对象。
为什么要设置初始容量呢?因为如果提前能预估缓存的使用大小,那么可以设置缓存的初始容量,以免缓存不断地进行扩容,致使效率不高。
最大容量 最大权重
maximumSize :最大容量,如果缓存中的数据量超过这个数值,Caffeine 会有一个异步线程来专门负责清除缓存,按照指定的清除策略来清除掉多余的缓存。注意:比如最大容量是 2,此时已经存入了2个数据了,此时存入第3个数据,触发异步线程清除缓存,在清除操作没有完成之前,缓存中仍然有3个数据,且 3 个数据均可读,缓存的大小也是 3,只有当缓存操作完成了,缓存中才只剩 2 个数据,至于清除掉了哪个数据,这就要看清除策略了。
maximumWeight:最大权重,存入缓存的每个元素都要有一个权重值,当缓存中所有元素的权重值超过最大权重时,就会触发异步清除。下面给个例子。
class Person{
Integer age;
String name;
}
Caffeine<String, Person> caffeine = Caffeine.newBuilder()
.maximumWeight(30)
.weigher((String key, Person value)-> value.getAge());
Cache<String, Person> cache = caffeine.build();
cache.put("one", new Person(12, "one"));
cache.put("two", new Person(18, "two"));
cache.put("three", new Person(1, "three"));
Thread.sleep(10);
System.out.println(cache.estimatedSize());
System.out.println(cache.getIfPresent("two"));
运行结果:
2
null
要使用权重来衡量的话,就要规定权重是什么,每个元素的权重怎么计算,weigher 方法就是设置权重规则的,它的参数是一个函数,函数的参数是 key 和 value,函数的返回值就是元素的权重,比如上述代码中,caffeine 设置了最大权重值为 30,然后将每个 Person 对象的 age 年龄作为权重值,所以整个意思就是:缓存中存储的是 Person 对象,但是限制所有对象的 age 总和不能超过 30,否则就触发异步清除缓存。
特别要注意一点:最大容量 和 最大权重 只能二选一作为缓存空间的限制。
缓存状态
默认的缓存状态收集器 CacheStats
默认情况下,缓存的状态会用一个 CacheStats 对象记录下来,通过访问 CacheStats 对象就可以知道当前缓存的各种状态指标,那究竟有哪些指标呢?
先说一下什么是“加载”,当查询缓存时,缓存未命中,那就需要去第三方数据库中查询,然后将查询出的数据先存入缓存,再返回给查询者,这个过程就是加载。
有兴趣的可以去看看CacheStats类的源码,下面是我读源码看到的一些属性:
- totalLoadTime:总共加载时间。
- loadFailureRate:加载失败率,= 总共加载失败次数 / 总共加载次数
- averageLoadPenalty :平均加载时间,单位-纳秒
- evictionCount:被淘汰出缓存的数据总个数
- evictionWeight:被淘汰出缓存的那些数据的总权重
- hitCount:命中缓存的次数
- hitRate:命中缓存率
- loadCount:加载次数
- loadFailureCount:加载失败次数
- loadSuccessCount:加载成功次数
- missCount:未命中次数
- missRate:未命中率
- requestCount:用户请求查询总次数
CacheStats 类包含了 2 个方法,了解一下:
CacheStats minus(@Nonnull CacheStats other):当前 CacheStats 对象的各项指标减去参数 other 的各项指标,差值形成一个新的 CacheStats 对象。
CacheStats plus(@Nonnull CacheStats other):当前 CacheStats 对象的各项指标加上参数 other 的各项指标,和值形成一个新的 CacheStats 对象。
举个例子说明:
Caffeine<String, Person> caffeine = Caffeine.newBuilder()
.maximumWeight(30)
.recordStats()
.weigher((String key, Person value)-> value.getAge());
Cache<String, Person> cache = caffeine.build();
cache.put("one", new Person(12, "one"));
cache.put("two", new Person(18, "two"));
cache.put("three", new Person(1, "three"));
CacheStats stats = cache.stats();
System.out.println(stats.hitCount());
自定义的缓存状态收集器
自定义的缓存状态收集器的作用:每当缓存有操作发生时,不管是查询,加载,存入,都会使得缓存的某些状态指标发生改变,哪些状态指标发生了改变,就会自动触发收集器中对应的方法执行,如果我们在方法中自定义的代码是收集代码,比如将指标数值发送到 kafka,那么其它程序从kafka读取到数值,再进行分析与可视化展示,就能实现对缓存的实时监控了。
收集器接口为 StatsCounter ,我们只需实现这个接口的所有抽象方法即可。下面举例说明。
public class MyStatsCounter implements StatsCounter {
@Override
public void recordHits(int i) {
System.out.println("命中次数:" + i);
}
@Override
public void recordMisses(int i) {
System.out.println("未命中次数:" + i);
}
@Override
public void recordLoadSuccess(long l) {
System.out.println("加载成功次数:" + l);
}
@Override
public void recordLoadFailure(long l) {
System.out.println("加载失败次数:" + l);
}
@Override
public void recordEviction() {
System.out.println("因为缓存大小限制,执行了一次缓存清除工作");
}
@Override
public void recordEviction(int weight) {
System.out.println("因为缓存权重限制,执行了一次缓存清除工作,清除的数据的权重为:" + weight);
}
@Override
public CacheStats snapshot() {
return null;
}
}
snapshot 方法的作用是创建当前统计数据的快照,即在某一个时间点上的统计数据的静态复制
特别需要注意的是:收集器中那些方法得到的状态值,只是当前缓存操作所产生的结果,比如当前 cache.getIfPresent() 查询一个值,查询到了,说明命中了,但是 recordHits(int i) 方法的参数 i = 1,因为本次操作命中了 1 次。再将收集器与某个缓存挂钩,如下:
MyStatsCounter myStatsCounter = new MyStatsCounter();
Caffeine<String, Person> caffeine = Caffeine.newBuilder()
.maximumWeight(30)
.recordStats(()->myStatsCounter)
.weigher((String key, Person value)-> value.getAge());
Cache<String, Person> cache = caffeine.build();
cache.put("one", new Person(12, "one"));
cache.put("two", new Person(18, "two"));
cache.put("three", new Person(1, "three"));
cache.getIfPresent("ww");
CacheStats stats = myStatsCounter.snapshot();
Thread.sleep(1000);
最后的执行结果为:
未命中次数:1
因为缓存权重限制,执行了一次缓存清除工作,清除的数据的权重为:18
线程池
Caffeine 缓冲池总有一些异步任务要执行,所以它包含了一个线程池,用于执行这些异步任务,默认使用的是 ForkJoinPool.commonPool() 线程池,个人觉得没有必要去自定义线程池,或者使用其它的线程池,因为 Caffeine 的作者在设计的时候就考虑了线程池的选择,既然别人选择了,就有一定道理。
如果一定要用其它的线程池,可以通过 executor() 方法设置,方法参数是一个 线程池对象。
数据过期策略
expireAfterAccess
最后一次访问之后,隔多久没有被再次访问的话,就过期。访问包括了读和写。举个例子:
Caffeine<String, Person> caffeine = Caffeine.newBuilder()
.maximumWeight(30)
.expireAfterAccess(2, TimeUnit.SECONDS)
.weigher((String key, Person value)-> value.getAge());
Cache<String, Person> cache = caffeine.build();
cache.put("one", new Person(12, "one"));
cache.put("two", new Person(18, "two"));
Thread.sleep(3000);
System.out.println(cache.getIfPresent("one"));
System.out.println(cache.getIfPresent("two"));
运行结果:
null
null
expireAfterAccess 包含两个参数,第二个参数是时间单位,第一个参数是时间大小,比如上述代码中设置过期时间为 2 秒,在过了 3 秒之后,再次访问数据,发现数据不存在了,即触发过期清除了。
expireAfterWrite
某个数据在多久没有被更新后,就过期。举个例子
Caffeine<String, Person> caffeine = Caffeine.newBuilder()
.maximumWeight(30)
.expireAfterWrite(2, TimeUnit.SECONDS)
.weigher((String key, Person value)-> value.getAge());
Cache<String, Person> cache = caffeine.build();
cache.put("one", new Person(12, "one"));
cache.put("two", new Person(18, "two"));
Thread.sleep(1000);
System.out.println(cache.getIfPresent("one").getName());
Thread.sleep(2000);
System.out.println(cache.getIfPresent("one"));
运行结果:
one
null
只能是被更新,才能延续数据的生命,即便是数据被读取了,也不行,时间一到,也会过期。
expireAfter
实话实说,关于这个设置项,官网没有说明白,网上其它博客更是千篇一律,没有一个讲明白的。此处简单讲讲我个人的测试用例与理解,如果有误,欢迎评论指正。
Caffeine<String, Person> caffeine = Caffeine.newBuilder()
.maximumWeight(30)
.expireAfter(new Expiry<String, Person>() {
@Override
public long expireAfterCreate(String s, Person person, long l) {
if(person.getAge() > 60){ //首次存入缓存后,年龄大于 60 的,过期时间为 4 秒
return 4000000000L;
}
return 2000000000L; // 否则为 2 秒
}
@Override
public long expireAfterUpdate(String s, Person person, long l, long l1) {
if(person.getName().equals("one")){ // 更新 one 这个人之后,过期时间为 8 秒
return 8000000000L;
}
return 4000000000L; // 更新其它人后,过期时间为 4 秒
}
@Override
public long expireAfterRead(String s, Person person, long l, long l1) {
return 3000000000L; // 每次被读取后,过期时间为 3 秒
}
})
.weigher((String key, Person value)-> value.getAge());
Cache<String, Person> cache = caffeine.build();
expireAfter 方法的参数是一个 Expiry 对象,Expiry 是一个接口,上述代码用了匿名类。需要实现 Expiry 的三个方法。
expireAfterCreate(String s, Person person, long l) :此方法为数据<s , person> 创建之后,过期时间是多久(可以理解为生命周期),单位为纳秒,方法的返回值就是过期时间,这个时间设置为多久,怎么设置,可以自定义的,比如上述代码,60 岁以上的过期时间为 4 秒,如果 4 秒内数据没有被操作,就过期。另外还有一个参数 long l,l 表示创建时间的系统时间戳,单位为纳秒。
expireAfterUpdate(String s, Person person, long l, long l1):此方法表示更新某个数据后,过期时间是多久(刷新生命周期),个人认为:参数 l 表示更新前的系统时间戳,l1 表示更新成功后的系统时间戳,因为在多线程下,更新操作可能会阻塞。
expireAfterRead(String s, Person person, long l, long l1) : 与 expireAfterUpdate 同理。
写策略
refreshAfterWrite 延迟刷新
refreshAfterWrite(long duration, TimeUnit unit)
写操作完成后多久才将数据刷新进缓存中,两个参数只是用于设置时间长短的。
只适用于 LoadingCache 和 AsyncLoadingCache,如果刷新操作没有完成,读取的数据只是旧数据。
Caffeine<String, Person> caffeine = Caffeine.newBuilder()
.maximumWeight(30)
.expireAfterWrite(2, TimeUnit.SECONDS)
.refreshAfterWrite(2,TimeUnit.SECONDS)
.weigher((String key, Person value)-> value.getAge());
Cache<String, Person> cache = caffeine.build();
cache.put("one", new Person(12, "one"));
cache.put("two", new Person(18, "two"));
Thread.sleep(1000);
System.out.println(cache.getIfPresent("one").getName());
Thread.sleep(2000);
System.out.println(cache.getIfPresent("one"));
removalListener 清除、更新监听
当缓存中的数据发送更新,或者被清除时,就会触发监听器,在监听器里可以自定义一些处理手段,比如打印出哪个数据被清除,原因是什么。这个触发和监听的过程是异步的,就是说可能数据都被删除一小会儿了,监听器才监听到。 举个例子:
MyStatsCounter myStatsCounter = new MyStatsCounter();
Caffeine<String, Person> caffeine = Caffeine.newBuilder()
.maximumWeight(30)
.removalListener((String key, Person value,
RemovalCause cause)->{
System.out.println("被清除人的年龄:"
+ value.getAge() + "; 清除的原因是:" + cause);
})
.weigher((String key, Person value)-> value.getAge());
Cache<String, Person> cache = caffeine.build();
cache.put("one", new Person(12, "one"));
cache.put("two", new Person(18, "two"));
cache.put("one", new Person(14, "one"));
cache.invalidate("one");
cache.put("three", new Person(31, "three"));
Thread.sleep(2000);
运行结果:
被清除人的年龄:12; 清除的原因是:REPLACED
被清除人的年龄:14; 清除的原因是:EXPLICIT
被清除人的年龄:18; 清除的原因是:SIZE
removalListener 方法的参数是一个 RemovalListener 对象,但是可以函数式传参,如上述代码,当数据被更新或者清除时,会给监听器提供三个内容,(键,值,原因)分别对应代码中的三个参数,(键,值)都是更新前,清除前的旧值, 这样可以了解到清除的详细了。
清除的原因有 5 个,存储在枚举类 RemovalCause 中:
- EXPLICIT : 表示显式地调用删除操作,直接将某个数据删除。
- REPLACED:表示某个数据被更新。
- EXPIRED:表示因为生命周期结束(过期时间到了),而被清除。
- SIZE:表示因为缓存空间大小受限,总权重受限,而被清除。
- COLLECTED : 这个不明白。
淘汰策略(驱逐策略)
缓存的数据使用弱引用,软引用
AsyncCache 缓存不支持软引用和弱引用。
- weakKeys():将缓存的 key 使用弱引用包装起来,只要 GC 的时候,就能被回收。
- weakValues():将缓存的 value 使用弱引用包装起来,只要 GC 的时候,就能被回收。
- softValues():将缓存的 value使用软引用包装起来,只要 GC 的时候,有必要,就能被回收。
关于软引用,弱引用,强引用,虚引用,可以参考:Java四大引用详解:强引用、软引用、弱引用、虚引用_java 引用-CSDN博客
因此,弱引用 ,软引用的设置,只是为了方便回收空间,节省空间,但是使用的时候注意一点,缓存查询时,是用 == 来判断两个 key 是否相等,比较的是地址,不是 key 本身的内容,很容易造成一种现象:命名 key 是对的,但就是无法命中,因为 key 的内容相等,但是地址却不同,会被认为是两个 key。
同步监听器
之前的 removalListener 是异步监听,此处的 writer 方法可以设置同步监听器,同步监听器一个实现了接口 CacheWriter 的实例化对象,我们需要自定义接口的实现类,比如:
public class MyCacheWriter implements CacheWriter<String, Application.Person> {
@Override
public void write(String s, Application.Person person) {
System.out.println("新增/更新了一个新数据:" + person.getName());
}
@Override
public void delete(String s, Application.Person person, RemovalCause removalCause) {
System.out.println("删除了一个数据:" + person.getName());
}
}
关键是要实现 CacheWriter 接口的两个方法,当新增,更新某个数据时,会同步触发 write 方法的执行。当删除某个数据时,会触发 delete 方法的执行。
Caffeine<String, Person> caffeine = Caffeine.newBuilder()
.maximumWeight(30)
.writer(new MyCacheWriter())
.weigher((String key, Person value)-> value.getAge());
Cache<String, Person> cache = caffeine.build();
cache.put("one", new Person(12, "one"));
cache.put("two", new Person(18, "two"));
cache.invalidate("two");
运行结果:
新增/更新了一个新数据:one
新增/更新了一个新数据:two
删除了一个数据:two
本地缓存实例Cache常用api
V getIfPresent(K key) :如果缓存中 key 存在,则获取 value,否则返回 null。
void put( K key, V value):存入一对数据 <key, value>。
Map<K, V> getAllPresent(Iterable<?> var1) :参数是一个迭代器,表示可以批量查询缓存。
void putAll( Map<? extends K, ? extends V> var1); 批量存入缓存。
void invalidate(K var1):删除某个 key 对应的数据。
void invalidateAll(Iterable<?> var1):批量删除数据。
void invalidateAll():清空缓存。
long estimatedSize():返回缓存中数据的个数。
CacheStats stats():返回缓存当前的状态指标集。
ConcurrentMap<K, V> asMap():将缓存中所有的数据构成一个 map。
void cleanUp():会对缓存进行整体的清理,比如有一些数据过期了,但是并不会立马被清除,所以执行一次 cleanUp 方法,会对缓存进行一次检查,清除那些应该清除的数据。
V get( K var1, Function<? super K, ? extends V> var2):第一个参数是想要获取的 key,第二个参数是函数,例子如下:
Caffeine<String, Person> caffeine = Caffeine.newBuilder()
.maximumWeight(30)
.weigher((String key, Person value)-> value.getAge());
Cache<String, Person> cache = caffeine.build();
cache.put("one", new Person(12, "one"));
cache.get("hello", (k)-> new Person(13, k));
System.out.println(cache.getIfPresent("hello").getName());
可以着重考虑一下第二个参数的写法,如果写成从数据库查询的话,那就很完整了。
还有另外两种缓存:LoadingCache, AsyncLoadingCache。
本地缓存Caffeine中的LoadingCache, AsyncLoadingCache、cache有什么区别
在Caffeine中,LoadingCache、AsyncLoadingCache 和普通的 cache 之间的主要区别在于它们如何处理缓存未命中(cache miss)的情况:
1.LoadingCache:
LoadingCache是一个同步缓存,它在缓存未命中的时候可以自动加载值。- 当从
LoadingCache中请求一个键的值,如果这个键在缓存中不存在,LoadingCache会使用一个指定的加载函数(例如,从数据库或计算得到)来获取这个值,并将其存储在缓存中。 - 使用
LoadingCache可以确保每次请求一个键时总能得到一个值(除非加载函数失败或者没有指定)。
2.AsyncLoadingCache:
AsyncLoadingCache是一个异步缓存,它在缓存未命中的时候会异步加载值。- 当请求一个键的值时,如果这个键不在缓存中,
AsyncLoadingCache会返回一个CompletableFuture,这个CompletableFuture会在加载函数异步计算得到值后完成。 - 这种缓存适合于那些加载操作可能很耗时,而不希望阻塞调用线程的场景。
3.cache (普通的缓存):
- 一个普通的
cache是最基础的缓存类型,它在缓存未命中的时候不会自动加载值。 - 当请求一个键的值时,如果这个键不在缓存中,那么会直接返回
null或者抛出一个异常(取决于配置)。 - 使用普通的
cache需要手动处理缓存未命中的情况,比如手动从数据源加载数据并放入缓存。
Caffeine原理剖析
Caffeine是一种高性能,近似最优命中的本地缓存,简单点说类似于ConcurrentMap,但不完全相同。最基本的区别是,ConcurrentMap将保留添加到它的所有元素,直到显式地删除它们。另一方面,缓存通常配置为自动删除数据,以限制其内存占用。大家在选用本地缓存开发框架时,最关心的是缓存的容量管理、命中率以及性能。因此,本文接下来将从淘汰算法、淘汰策略以及读写性能三个维度来介绍下Caffeine的实现原理。
W-TinyLFU
传统LFU受时间周期的影响比较大(LFU算法是基于对象访问频率来做出缓存决策的。随着时间的推移,如果一个数据项在较长时间内没有被访问,即使它之前被频繁访问,它的使用频率也会降低,从而可能导致它被淘汰,即使它可能在将来再次变得活跃),所以各种LFU的变种出现了,基于时间周期进行衰减,或者在最近某个时间段内的频率。同样的LFU也会使用额外空间记录每一个数据访问的频率,即使数据没有在缓存中也需要记录,所以需要维护的额外空间很大。Caffeine的缓存淘汰是通过一种叫做W-TinyLFU的数据结构实现的,这是一种对LRU和LFU进行了组合优化的算法,以及结合了一些其他算法的特点,提供了一个近乎最佳的命中率。
Window TinyLFU主要结构如下:
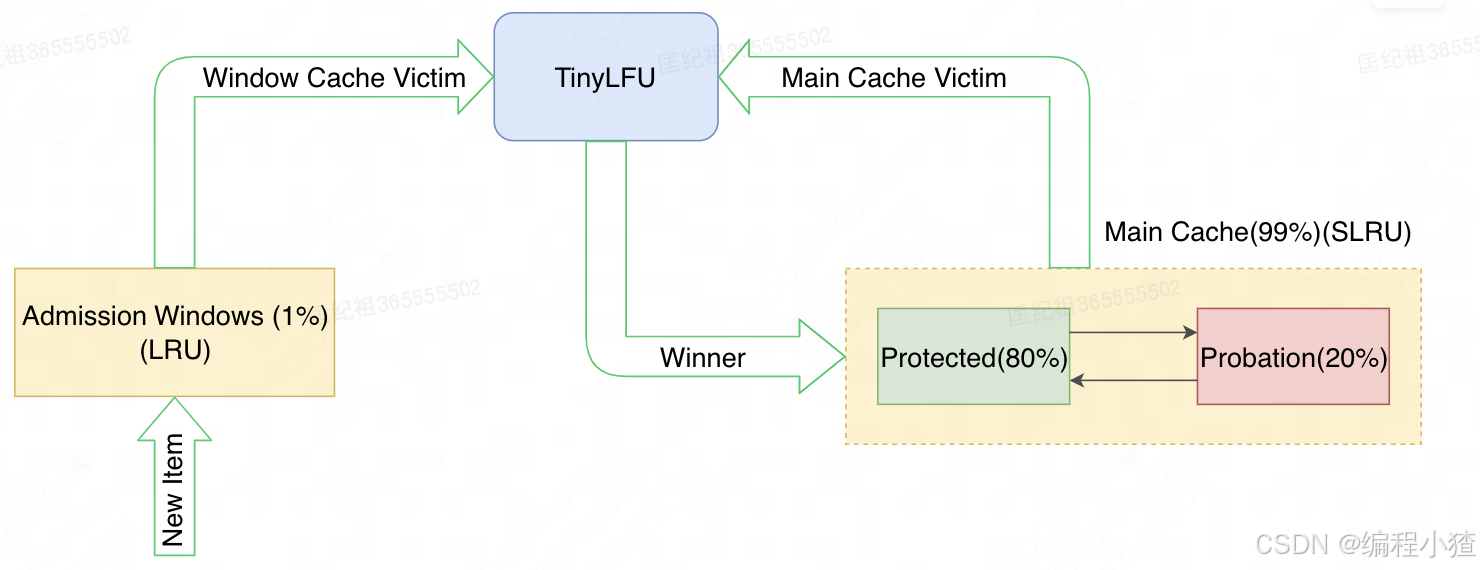
可以看到整个W-TinyLFU由三部分构成:
-
准入窗口(Admission Windows),由一个较小的LRU队列构成,其容量只有整个缓存大小的1%,这个窗口的作用主要是为了保护一些新进入缓存的数据,给他们一定的成长时间来积累自己的使用频率,避免被快速淘汰掉,而且LRU也能应对突发的流量。
-
频次过滤器(TinyLFU)是W-TinyLFU核心部分,也是Caffeine精髓所在,使用了Count-Min Sketch记录我们的访问频率,而这个也是布隆过滤器的一种变种。根据数据的访问频率从而决定主缓存区数据的淘汰策略,下文中会详细讲到W-TinyLFU如何做到频率记录的。
-
主缓存区(Main Cache)用于存放大部分的缓存数据,数据结构为一个分段LRU队列(SLRU),占整个缓存容量的99%,Segmented LRU核心思想就是分段,所以整个主缓存区包括Protected和Probation两部分,其中Protected的大小占主缓存区容量的80%,Probation占20%,发生数据淘汰时,会从这部分缓存里获取数据进行淘汰,具体淘汰过程可以见下文的Caffeine淘汰策略。
频率记录
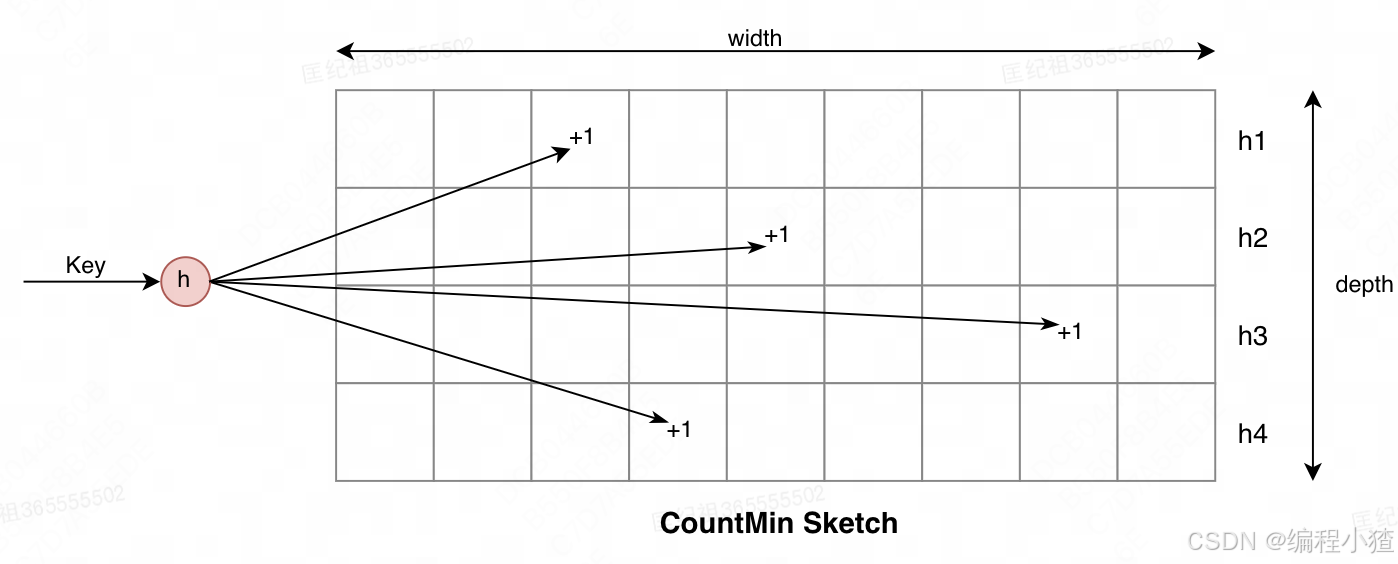
说到频率记录,就是需要利用有限的空间可以记录缓存数据随时间变化的访问频率。在W-TinyLFU中使用Count-Min Sketch记录我们的访问频率,借用了布隆过滤器的思想来实现。他是通过一个计数矩阵和多个哈希算法实现的,如图所示:
图中不同的row对应着不同的哈希算法,depth大小代表着哈希算法的数量,width则表示数据可哈希的范围。如果需要记录一个值,那我们需要通过多种Hash算法对其进行处理hash,然后在对应的hash算法的记录中+1。使用多个哈希算法可以降低哈希碰撞带来的数据不准确的概率,宽度上的增加可以提高key的哈希范围,减少碰撞的概率,所以合理的调整算法数量和哈希的范围,可以更好的平衡空间与哈希碰撞产生的错误率。Caffeine中的CountMin Sketch是通过四种哈希算法和一个long型数组实现的。具体怎么记录频率的呢,首先Caffeine会根据缓存大小生成一个long型数组,数组大小是缓存大小最接近2的幂的数。在Caffeine中规定频率最大为15,一个Long的结构,会分成A,B,C,D四段,每个段都给四种算法预留了保存频率的位置,如下图所示:
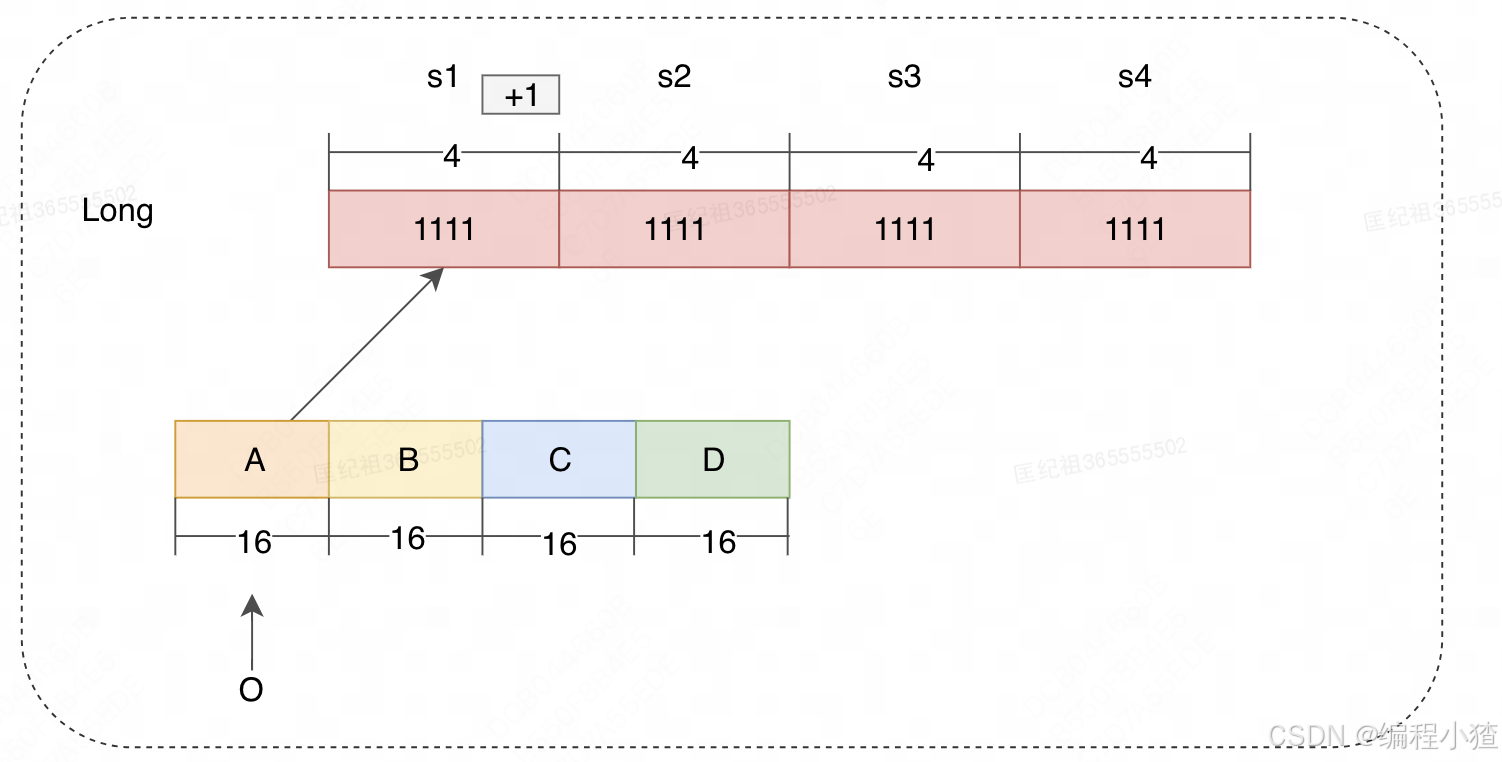
如果访问对象O,先确定O在整个数组的位置,最简单可以通过O的hash & 3,必定可以得到小于4的数,假设是0,那就在A段,也就意味着后续四种算法得到的数组中的位置,只会在响应位置的A段 + 1。
当需要获取对象O的访问频率时,只需要返回四个算法记录的频率数中最少的一个,这么做也是为了最大程度减小碰撞率,所以它的名字也才叫 Count-Min Sketch(统计最小的数)。
Caffeine淘汰策略
Caffeine数据淘汰过程如下图所示:
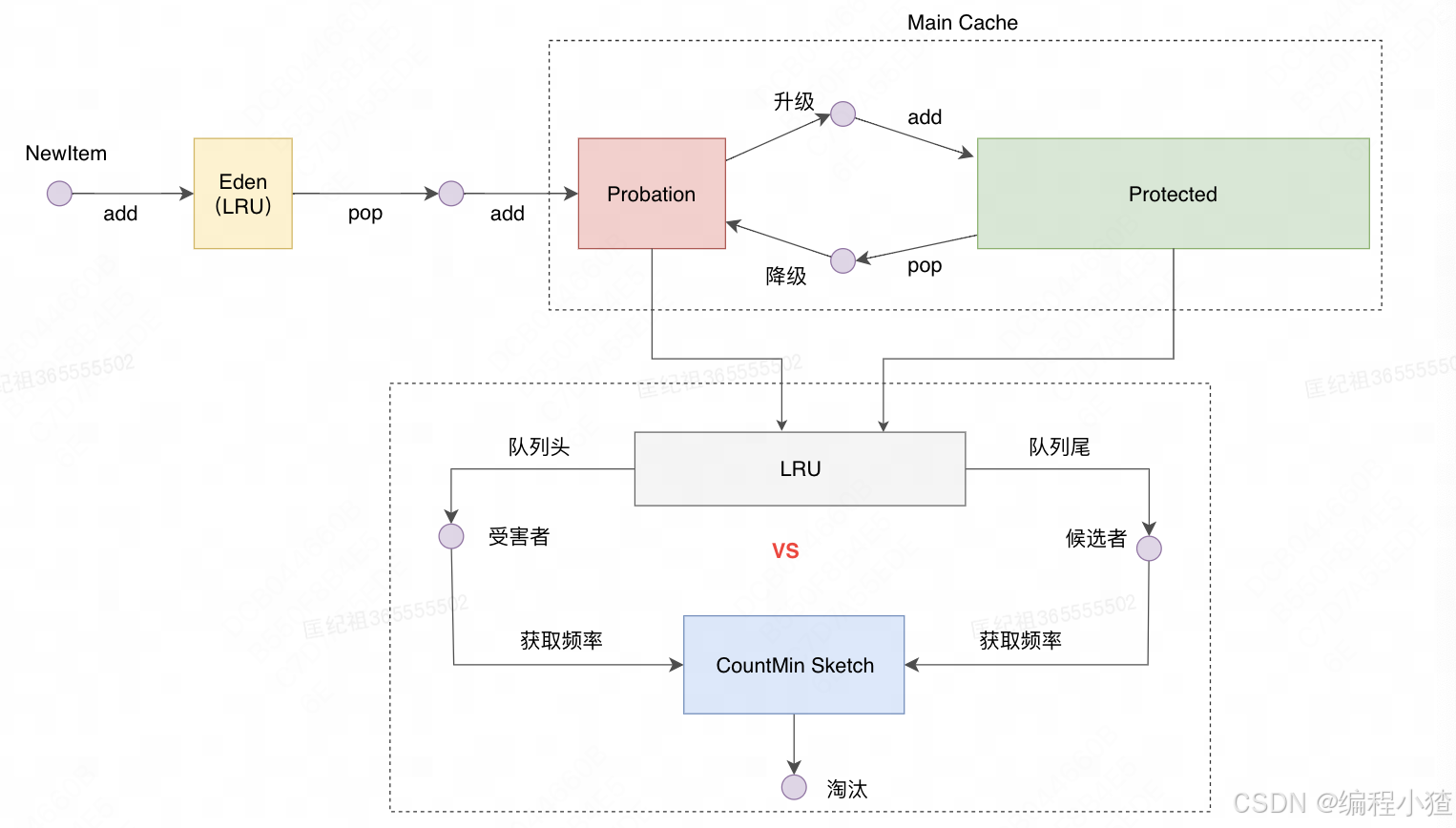
-
新的元素加入缓存,先会加入上文中的“准入窗口”,就是一个容量很小的LRU队列,我们称之为Eden区,当Eden区容量达到限制时,会把最早进入队列的元素放至Main cache 里面的Probation区,这些数据一般被叫做候选者。
-
进入Probation的元素如果被访问了一次,会升级到Protected区域。
-
如果Protected容量达到了限制,又会把最早进入Protected的元素降级到Probation区域。
-
主缓存区的大小(Probation的大小 + Protected的大小)达到了其容量限制会触发主缓存区的数据淘汰,Probation会被优先选择为淘汰队列,如果Probation为空,则选择Protected为淘汰队列。
-
会从淘汰队列中选出头部(受害者)和尾部的元素(攻击者)进行访问频率比较,访问频率从上文中讲到的CountMin Sketch中获取,然后通过一定的逻辑淘汰,逻辑如下:
-
如果攻击者大于受害者,那么受害者就直接被淘汰。
-
如果攻击者<=5,那么直接淘汰攻击者,开发者认为设置一个预热的门槛会让整体命中率更高。
-
其他情况,随机淘汰。
Caffeine读写性能
缓存的并发控制是一个比较棘手的问题,因为缓存的淘汰策略、过期策略等等都会涉及到了对同一块缓存区内容的修改,最简单的方法就是加锁,因为锁的存在就会影响缓存读写性能,相比于guava cache,Caffeine在读写模型上做了很多的优化。下面分别从读写两方面分别阐述Caffeine相比guava cache做了哪些优化。
读
在guava cache中我们说过其读写操作中夹杂着过期时间的处理,也就是你在一次get操作中有可能还会做淘汰操作,具体代码如下图所示:
V get(K key, int hash, CacheLoader<? super K, V> loader)
throws ExecutionException {
checkNotNull(key);
checkNotNull(loader);
try {
if (count != 0) { // read-volatile
// don't call getLiveEntry, which would ignore loading values
ReferenceEntry<K, V> e = getEntry(key, hash);
if (e != null) {
long now = map.ticker.read();
//我们发现在get方法中,有个getLiveValue(),
//这个方法是拿到当前可用的缓存值,那不可用的值何时清理呢?除的
V value = getLiveValue(e, now);
if (value != null) {
recordRead(e, now);
statsCounter.recordHits(1);
return scheduleRefresh(e, key, hash, value, now, loader);
}
ValueReference<K, V> valueReference = e.getValueReference();
if (valueReference.isLoading()) {
return waitForLoadingValue(e, key, valueReference);
}
}
}
//如果不存在或者过期,就通过loader方法进行加载
//(注意这里会加锁清清理GC遗留引用数据和超时数据);
return lockedGetOrLoad(key, hash, loader);
} catch (ExecutionException ee) {
......
} finally {
postReadCleanup();
}
}在cache get数据的时候,如果链表上找不到entry,或者value已经过期,则调用lockedGetOrLoad()方法,这个方法会锁住整个segment,直到从数据源加载数据,更新缓存。在getLiveValue()方法里面也会同步的进行一些清理操作,所以guava cache读性能会受到很大的影响,甚至并发量高的情况还可能遇到线程block。但是在这方面Caffeine做了很大的优化,因为在Caffeine里面,对这些清理缓存的操作都是通过异步操作的,将事件提交到队列里面去,其队列底层的数据结构是一个striped ring buffer(是一种并发数据结构,用于实现无锁的、线程安全的、固定大小的环形缓冲区),当ring buffer满了之后并且调度状态满足一定的条件会触发异步的调度任务(清理缓存等)。如果当前ring buffer满之后,后续写入该队列的读操作会被直接被丢弃。
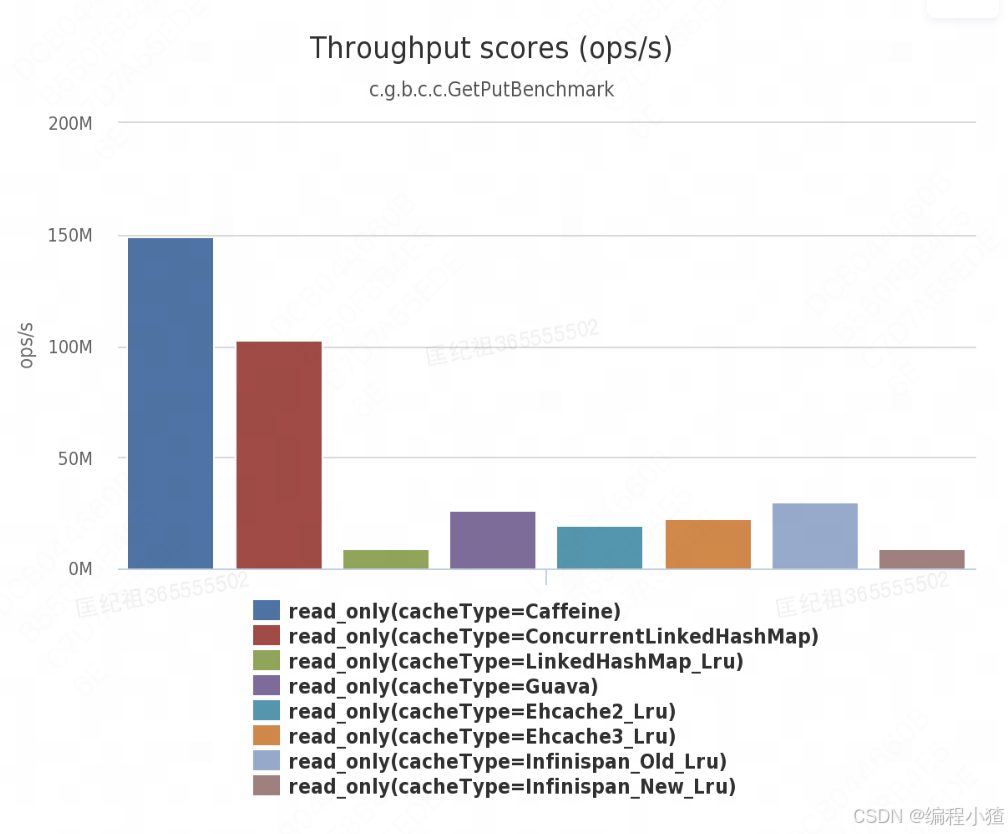
最后再来看一下,Caffeine官方在缓存达到最大容量下,各个缓存组件读性能对比,如下图所示,显然Caffeine读性能比guava高得多。
写
guava cache写核心源码如下:
V put(K key, int hash, V value, boolean onlyIfAbsent) {
//保证线程安全,加锁
lock();
try {
//获取当前的时间
long now = map.ticker.read();
//清除队列中的元素,Guava Cache为了支持弱引用和软引用,引入了引用清空队列
preWriteCleanup(now);
//localCache的Count+1
int newCount = this.count + 1;
//扩容操作
if (newCount > this.threshold) { // ensure capacity
expand();
newCount = this.count + 1;
}
//获取当前Entry中的HashTable的Entry数组
AtomicReferenceArray<ReferenceEntry<K, V>> table = this.table;
//定位
int index = hash & (table.length() - 1);
//获取第一个元素
ReferenceEntry<K, V> first = table.get(index);
//遍历整个Entry链表
// Look for an existing entry.
for (ReferenceEntry<K, V> e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash
&& entryKey != null
&& map.keyEquivalence.equivalent(key, entryKey)) {
// We found an existing entry.
//如果找到相应的元素
ValueReference<K, V> valueReference = e.getValueReference();
//获取value
V entryValue = valueReference.get();
//如果entry的value为null,可能被GC掉了
if (entryValue == null) {
++modCount;
if (valueReference.isActive()) {
enqueueNotification( //减小锁时间的开销
key, hash, entryValue, valueReference.getWeight(), RemovalCause.COLLECTED);
//利用原来的key并且刷新value
setValue(e, key, value, now);//存储数据,并且将新增加的元素写入两个队列中
newCount = this.count; // count remains unchanged
} else {
setValue(e, key, value, now);//存储数据,并且将新增加的元素写入两个队列中
newCount = this.count + 1;
}
this.count = newCount; // write-volatile,保证内存可见性
//淘汰缓存
evictEntries(e);
return null;
} else if (onlyIfAbsent) {//原来的Entry中包含指定key的元素,所以读取一次,读取操作需要更新Access队列
// Mimic
// "if (!map.containsKey(key)) ...
// else return map.get(key);
recordLockedRead(e, now);
return entryValue;
} else {
//如果value不为null,那么更新value
// clobber existing entry, count remains unchanged
++modCount;
//将replace的Cause添加到队列中
enqueueNotification(
key, hash, entryValue, valueReference.getWeight(), RemovalCause.REPLACED);
setValue(e, key, value, now);//存储数据,并且将新增加的元素写入两个队列中
//数据的淘汰
evictEntries(e);
return entryValue;
}
}
}
//如果目标的entry不存在,那么新建entry
// Create a new entry.
++modCount;
ReferenceEntry<K, V> newEntry = newEntry(key, hash, first);
setValue(newEntry, key, value, now);
table.set(index, newEntry);
newCount = this.count + 1;
this.count = newCount; // write-volatile
//淘汰多余的entry
evictEntries(newEntry);
return null;
} finally {
//解锁
unlock();
//处理刚刚的remove Cause
postWriteCleanup();
}
}可以看到guava cache为了保证线程安全从put方法一开始就加锁了,这点和ConcurrentHashMap一致,而且在整个put过程中,会出现同步的缓存淘汰操作,如果写的并发量高起来,整个缓存的性能会大大下降。而Caffeine通过缓冲队列来解决这个问题。当然读写也是有不同的队列,在Caffeine中认为缓存读比写多很多,所以对于写操作是所有线程共享一个缓存队列。这里的队列是一个多生产者单消费者模型,具体的实现是用了JCtools里的无锁MPSC(Multi Producer Single Consumer)自动扩容队列,由于没有锁因此效率很高,核心流程如下图所示:

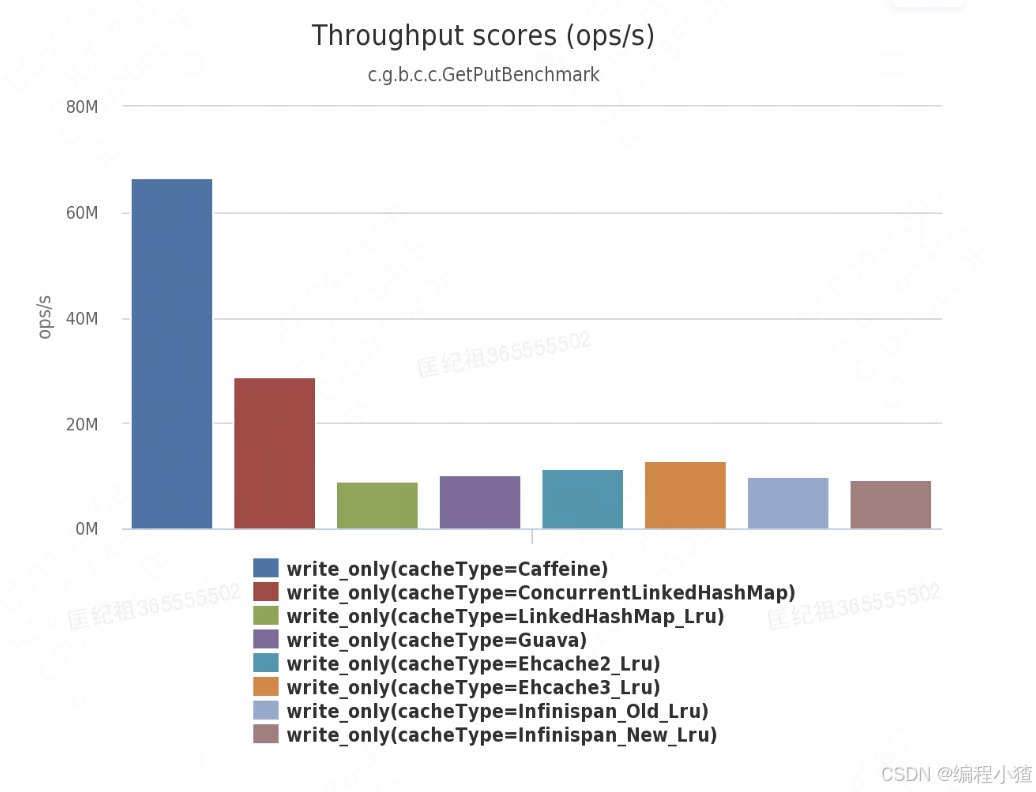
同样的,再来看一下在缓存容量达到最大场景下,Caffeine跟其他缓存组件写性能对比数据:
Caffeine在业务中的实践
Caffeine使用场景
说到Caffeine的使用场景,不得不先比较一下本地缓存与分布式缓存的优劣势了:
本地缓存
-
访问速度快,无法存储大量的数据
本地缓存相对于分布式缓存的好处是,由于数据不需要跨网络传输,故性能更好,但是由于占用了应用进程的内存空间,如 Java 进程的 JVM 内存空间,故不能进行大数据量的数据存储。
-
很难保证数据一致性问题
在分布式的环境下,本地缓存都在各自应用服务器上,缓存的更新一般都依赖应用内部代码的运行,很难保证缓存更新时机与内容跟其他服务器保持一致。
-
数据会随着进程的重启而丢失
应用和cache是在同一个进程内部,缓存跟应用程序耦合,多个应用程序无法直接的共享缓存,各应用或集群的各节点都需要维护自己的单独缓存,所以一旦进程重启缓存内数据就是丢失,在JVM中一次full gc可能也会导致缓存数据丢失。
分布式缓存
-
支持大数据量存储,不受应用进程重启影响
分布式缓存独立部署在其他服务器上,跟应用服务器完全隔离开,缓存内数据的大小不会影响本身应用进程的空间,而缓存内容也不会随着应用进程的重启而丢失。
-
数据集中存储,保证数据一致性
分布式缓存一般采用集群方式部署时,集群的每个部署节点都通过一个统一的方式进行数据存取操作,应用程序集群每个节点都是访问统一的分布式缓存集群,所以不会存在本地缓存中数据更新问题,而分布式缓存集群本身通过一些机制也保证了数据一致性。
-
集群读写分离,高可用,高性能
分布式缓存一般都以集群方式存在,有主库和从库之分,可以实现读写分离,故可以解决高并发场景中的数据读写性能问题。
-
数据跨网络传输,性能低于本地缓存
单论响应数据来说,分布式缓存不如本地缓存,本地缓存直接从应用进程内部获取数据,而分布式缓存需要应用进程请求远程分布式缓存集群来获取数据,会有网络io的开销。
由上可见,本地缓存主要适用缓存一些数据量较小,变更频率低,但是访问量特别高的情况,尤其是数据的获取依赖外部服务,高流量的情况下对热点数据的请求可能会压垮外部服务。所以我们就可以缓存这部分热点数据,提高访问效率,增加系统吞吐量。对于一致性问题,可以通过设置缓存失效时间,缓存下数据失效后,再次请求外部服务,再次把数据加进本地缓存,如下图所示:
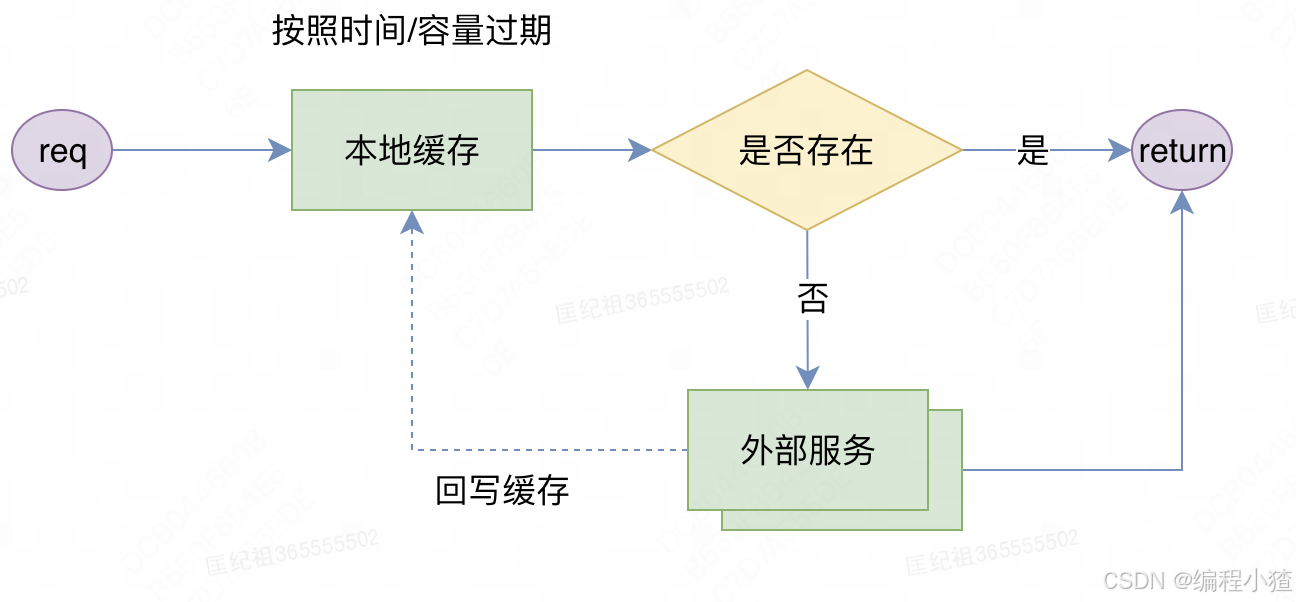
对于这种涉及到缓存失效算法,以及支持丰富的api的场景下,Caffeine就是本地缓存的不二之选了。
本地缓存带来的痛点
场景1:一次营销活动中,需要展示团购信息,团购id是预先配置好的,需要根据id调用多个团购服务获取团购详情信息,考虑到团购数据不多,页面流量高,对外部服务调用压力大,于是对团购信息做了本地缓存,但是后续配置团购id变更需要等到缓存失效才能加载最新的数据,或者需要重启应用。
场景2:提前配置好了缓存失效时间和缓存最大容量,但是上线后发现配置的值需要调整,没办法只能重新修改代码,重新发布应用。
场景3:上线之后对无法实时感知本地缓存命中率,容量,加载时间等指标,也无法实时查看缓存里面具体某个key的内容,无法第一时间确定数据不一致的原因是否是本地缓存导致的。
总结下来,我们在使用本地缓存开发的时候,可能会面对这些问题:
-
实时查看:看不到本地缓存存储数据内容,无法确定是本地缓存数据未更新带来的问题。
-
实时清理:知道本地缓存数据未及时更新,导致数据不一致,但是却无法及时清理。
-
数据可视化:无法直观的监控本地缓存使用情况(加载时间,缓存大小)。
-
配置热更新:本地缓存配置(容量大小,刷新时间等)无法根据线上实际监控情况动态变更配置。
为了解决使用本地缓存带来的痛点,我们团队沉淀了动态化本地缓存配置工具,旨在更便捷,更快速,更安全的接入本地缓存,所以工具命名为-Easyfast,希望它能够在实际开发中起到更好更快的作用,下文中会讲述它的具体实现,如果灵活利用Caffeine的能力与公司常用中间件结合,快速,稳定的实现Easyfast动态化本地缓存配置工具。具体可以看这篇文章:EasyFast—本地缓存动态化配置工具-CSDN博客


















 353
353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











