






前言:
这里记录了我学python的过程,写这篇博客希望有更多的宝子们学习python,有什么疑问的话,我们可以一起解决,嘿嘿嘿
一,入门与基本语法
安装教程:
pycharm是一款开发python程序的神器,无论是初学者还是职场老手,都可以用,功能齐全、应有尽有,除了稍微占点内存外。。

支持系统:windows/mac/linux
文件获取关键字:jetbrains96
插件支持版本:2021.2.2及之前
插件支持所有的操作系统,pycharm2021.2.2及之前的版本,下面以pycharm2021.1.1 for windows为例进行演示操作,mac linux操作系统或其他版本操作类似,相关安装包从官网下载。
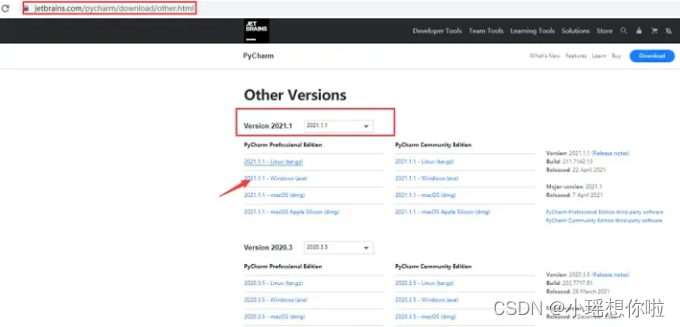
安装教程
1. 打开下载的安装包,设置pycharm安装路径,点击下一步
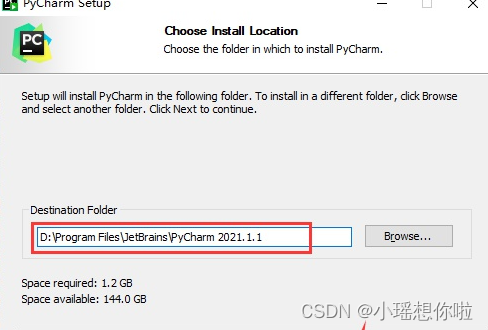
2. 按自己的情况设置即可。
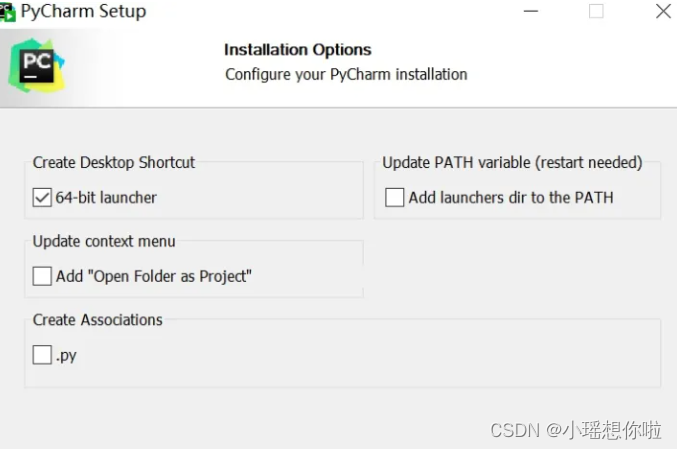
3. 安装后,勾选Run pycharm,点击Finish,软件会打开。
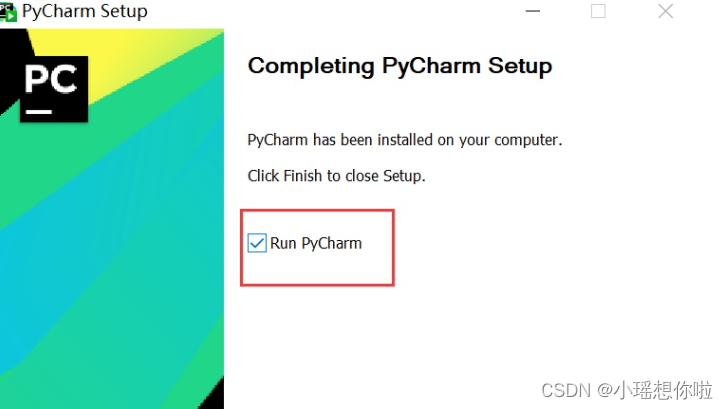
4. 按图片点击,进行软件的试用
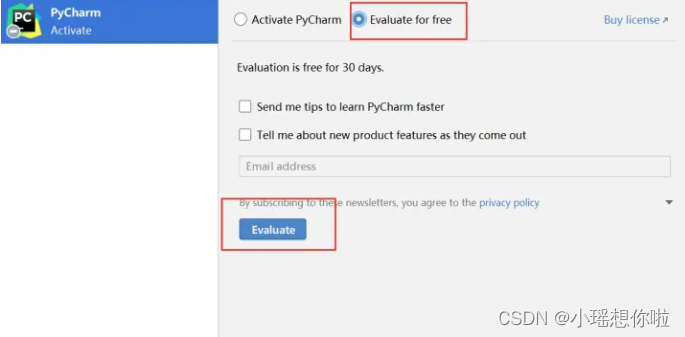
5. 点击 New Project 新建一个工程或者打开一个旧工程,进入软件的编辑页面中
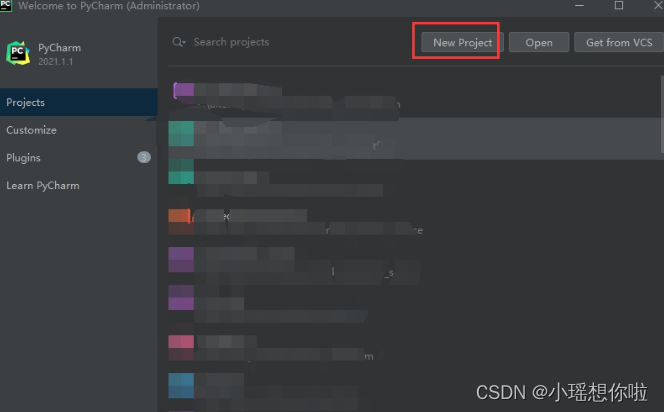
6. 从下载的jetbrains无限重置插件包(先解压)中,找到 ide-plugin-2.1.6.zip (这个注意不用解压),用鼠标左键直接拖到软件中去,进行插件的安装。(温馨提示:拖拽过程中,如果出现 invalid CEN header (bad entry name) 报错,把这个压缩包解压,拖拽里面的ide-eval-resetter-2.1.6.jar文件进去即可)
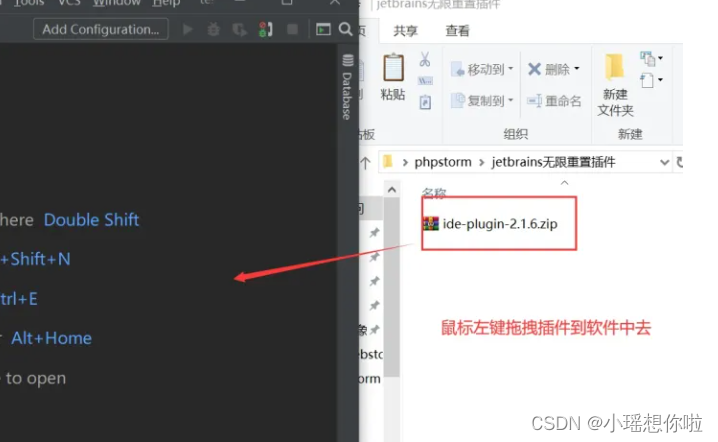
7.拖过来后右下角弹出下图信息证明插件安装成功
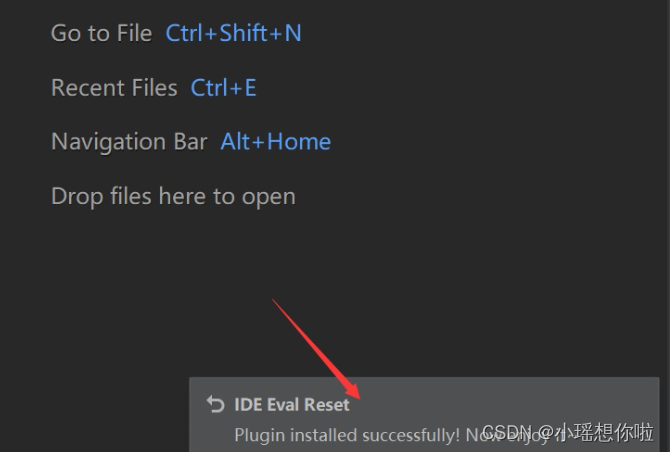
8. 之后点击 Help-->Eval Reset 进入插件设置
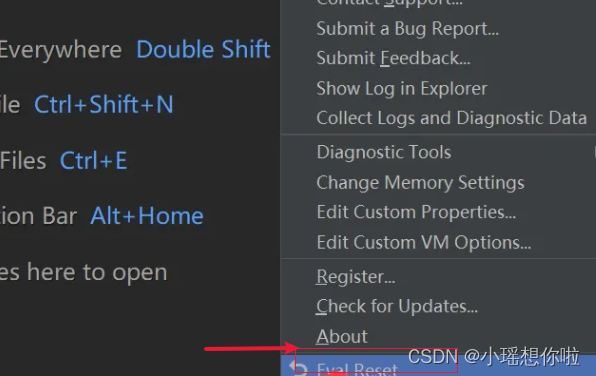
9. 勾选上Auto reset beforep per restart ,点击 Reset
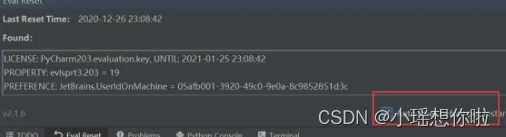
10. 弹出框中点击yes
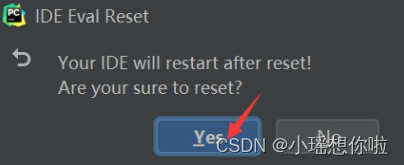
11. 如弹出退出确认框,点击 Exit即可
12. 之后软件会重启,这时pycharm已经设置好了插件,可以每次开启软件后自动去帮我们重置时间,让我们的试用时间一直是30天,相当于永久使用。
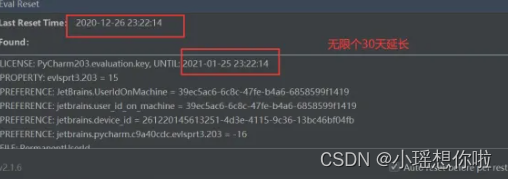
结语:pycharm2021安装激活教程到此结束,本文采用了一种全新的插件式方法来进行激活,方法亲测可行安全有效,过程简单易操作,祝大家早日安装插件,专注开发!
1.1 python简介
1.1.1简介
Python是著名的“龟叔”Guido van Rossum在1989年圣诞节期间,为了打发无聊的圣诞节而编写的一个编程语言。
Python 语言是在 ABC 语言的基础上发展而来,其设计的初衷是成为 ABC 语言的替代品。ABC 语言虽然是一款功能强大的高级语言,遗憾的是,由于 ABC 语言不开放的原因,导致它没有得到普及应用。基于这个考虑,Guido 在开发 Python 之初就决定将其开源。
Python为我们提供了非常完善的基础代码库,覆盖了网络、文件、GUI、数据库、文本等大量内容,被形象地称作“内置电池(batteries included)”。用Python开发,许多功能不必从零编写,直接使用现成的即可。
除了内置的库外,Python还有大量的第三方库,也就是别人开发的,供你直接使用的东西。当然,如果你开发的代码通过很好的封装,也可以作为第三方库给别人使用。
许多大型网站就是用Python开发的,例如YouTube、Instagram,还有国内的豆瓣。很多大公司,包括Google、Yahoo等,甚至NASA(美国航空航天局)都大量地使用Python。
龟叔给Python的定位是“优雅”、“明确”、“简单”,所以Python程序看上去总是简单易懂,初学者学Python,不但入门容易,而且将来深入下去,可以编写那些非常非常复杂的程序。
总的来说,Python的哲学就是简单优雅,尽量写容易看明白的代码,尽量写少的代码。如果一个资深程序员向你炫耀他写的晦涩难懂、动不动就几万行的代码,你可以尽情地嘲笑他。
1.2,打开CMD,输入命令查看Python版本:
python -V安装配置PyCharm工具,具体请见资料`pycharm-professional-2021.1.1.exe`
关于Python中```if __name__ == '__main__'```语句块的说明
在Python中,```if __name__ == 'main'```的作用区分模块是被导入还是被直接执行。当模块被直接执行时,该条件语句为真,执行其后面的代码块;当模块被导入时,该条件语句为假,不会执行其后面的代码块。
1.3,变量和数据类型
1.3.1.变量
- 变量名只能包含字母、数字和下划线。变量名可以字母或下划线打头,但不能以数字打头,例如:可将变量命名为message_1,但不能将其命名为1_message。
- 变量名不能包含空格,但可使用下划线来分隔其中的单词。例如:变量名greeting_message 可行,但变量名greeting message会引发错误。
- 不要将Python关键字和函数名用作变量名,即不要使用Python保留用于特殊用途的单词
- 变量名应既简短又具有描述性。例如:name比n好,student_name比s_n好,name_length 比length_of_persons_name好。
> 就目前而言,应使用小写的Python变量名。在变量名中使用大写字母虽然不会导致错误,但避免使用大写字母是个不错的主意。
1.3.2 注释
- **#行注释**
```python
# 这是Python中的行注释
```
**三单和三双块注释**
```python
'''
这是Python中三个单引号的块注释
'''
"""
这是Python中三个双引号的块注释
"""1.3.3 数据类型
*Python*是一门动态的*(dynamic)*且强类型*(strong)*语言
**动态/静态**
- 在静态类型语言(**statically typed languages**)中,类型检查发生在编译阶段(compile time)
- 在动态类型语言(**dynamically typed languages**)中,类型检查发生在运行阶段(run time)
- 静态类型(static): 所有的变量类型必须被显示地声明,因为这些信息在编译阶段就被需要。
- 动态(Dynamic): 显示声明不被要求,因为类型赋值发生在运行阶段。
**强类型/弱类型**
- 在强类型中,不管在编译时还是运行时,一旦某个类型赋值给某个变量,它会持有这个类型,并且不能同其他类型在计算某个表达式时混合计算。
- 在弱类型中,它是很容易与其他类型混合计算的。
> Java中的数据类型:String int/short/long/byte/double/float/boolean/char
> Python中的数据类型:str/int/float/bool
# python:是一门动态的强类型语言
a = "str"
b = 1.0
# java:是一门静态的强类型语言
int i =1
double d=2.0
# javascript:是一门动态的弱类型语言,运行时识别数据类型
let a=1;
let b="str";
```
字符串(str)
单引号和双引号
temp = 'hello python'
temp = "hello python"
print(temp)
temp = 'I say "hello world"'
print(temp)
# 转义符处理
temp="I say \"hello world\""
print(temp)
# 通过+拼接字符串
print(temp+"...")
# 使用制表符\t和换行符\n
print("I say \thello \nworld")整数(int)
在Python中,可对整数执行加(+)减(-)乘(*)除(/)运算。
# 加(+)减(-)乘(*)除(/)运算
count = 8
print(count+1)
print(count-1)
print(count/2)
print(count*2)
# 使用两个乘号表示乘方运算
print(count ** 2) # 相当于count * count
# 符号*打印输出30次
print("*"*30)浮点型(float)
Python将带小数点的数字都称为浮点数。
salary=3000
print(salary);
print("我的工资是:"+str(salary))
# print('1'+3) X
# print(int('1')+3) √
# print('1'+str(3)) √
浮点型的缺陷:
a = 0.1
b = 0.2
print(b-a) # 0.1
print(a+b) # 0.30000000000000004
温馨提示:计算机系统底层采用二级制,而整数(1,2,3,4等)都能完美的转换成二进制,但是小数(浮点数)有可能变成无限二进制(**精度的丢失问题**)
所以说,只要是float类型的数据相加,无论在任何语言、任何数据库、任何中间件中进行加法(减法乘除法)运算,得到的数据,都不会精确。
解决方案:
- 数据库中使用decimal类型(字符小数,例如:'1.1111'),在Java中使用BigDecimal进行计算操作;
- 以最小单位存储,例如:1.236(一块二毛三分六厘),1236(以最小单位厘来存储);
布尔(bool)
Python提供了 bool 类型来表示真(对)或假(错),比如常见的`5 > 3`比较算式,这个是正确的,在程序世界里称之为真(对),Python 使用 **True** 来代表;再比如`4 > 20`比较算式,这个是错误的,在程序世界里称之为假(错),Python 使用 **False** 来代表。
配合运算符:`>=,<=,==,!=,and,or` 一起使用。
列表:
需要明确的是,Python中没有数组,但是加入了更加强大的列表。如果把数组看做是一个集装箱,那么 Python 的列表就是一个工厂的仓库。
从形式上看,列表会将所有元素都放在一对中括号`[ ]`里面,相邻元素之间用逗号`,`分隔,如下所示:
nums=[0,1,2,3,4,5,6,7,8,9]
# 1) 查看names的大小
print(len(nums))
# 2) 取值,从头到尾取值,索引从0开始
print(nums[0])
# 3) 取值,从尾到头取值,索引从-1开始
print(nums[-1])
# 4) 赋值
nums[0]="zhaoliu"
print(nums)
nums[-2]="wahaha"
print(nums)
# 5) 切片
print(nums[1:4])
# 6) 插入
nums.insert(2,10)
print(nums)
#追加append:在列表末尾添加元素
nums.append(100)
print(nums)
#插入insert:在列表中插入元素
nums.insert(0,666)
print(nums)
nums.insert(-2,777)
print(nums)
删除(del)
使用 `del` 可以删除列表中指定下标的元素,但是它不会返回被删除的元素
del nums[0]
print(nums)
#删除(出栈方式)pop:出栈|根据索引删除
# 默认从最后一个开始出栈
print(nums.pop())
# 通过指定索引下表出栈
print(nums.pop(0))
print(nums)
# remove删除
nums.remove(5)
print(nums)
# 判断元素是否存在
print(5 in nums)
print(5 not in nums)排序:
print(sorted(nums))
# 永久性排序
nums.sort()
print(nums)反转
nums.reverse()
print(nums)切片
start和stop的正值代表列表下标,负值代表列表从右往左数起,倒数第几个数据。方向由step确定,step为正时,从左往右切片,step为负时,从右往左切片;start和stop的空值分别代表列表的头尾的最后一个数据,至于start和stop空值的时候代表的是列;表的头还是尾,由step的正负值决定,即由step确定列表切片的方向后决定。
# start:起始下标
# stop:停止下标
# step:步长
# start和stop的正值代表列表下标
print(nums[::2])
print(nums[1::2])
print(nums[0:4:2])
# start和stop负值代表列表从右往左数起,不包含结束位置
print(nums[-1:-3:-1])
# 单独一个冒号,代表从头取到尾,步长默认为1
print(nums[:])
# 单独两个冒号一样代表从头取到尾,步长默认为1
print(nums[::])
# 两个冒号后面是步长。步长为1,从左到右;步长为-1,从右到左
print(nums[::1])
print(nums[::-1])
# 赋值操作
# nums[0:4]=[]
nums[0:4]=[1,2]
print(nums)元组:
元组(tuple)是Python中另一个重要的序列结构,和列表类似,元组也是由一系列按特定顺序排序的元素组成。
元组和列表(list)的不同之处在于:
- 列表的元素是可以更改的,包括修改元素值,删除和插入元素,所以列表是可变序列;
- 而元组一旦被创建,它的元素就不可更改了,所以元组是不可变序列。
元组也可以看做是不可变的列表,通常情况下,元组用于保存无需修改的内容。
从形式上看,元组的所有元素都放在一对小括号`( )`中,相邻元素之间用逗号`,`分隔,如下所示:
nums=(0,1,2)
a,b,c=nums
print(a)
print(b)
print(c)
print(len(nums))
print(nums)
# tuple类型一旦初始化就不能修改
# nums[0]=5
# print(nums)
# 元组作为返回值,可以方便返回多个值
def get_stu():
name = "zsa"
age = 18
return name, age
result = get_stu()
print(result)
# 元组具有不可变性,可以作为字典的key
my_dict = {
("Alice", 25): "alice@example.com",
("Bob", 30): "bob@example.com"
}
print(my_dict)集合
Python中的集合,和数学中的集合概念一样,用来保存不重复的元素,即集合中的元素都是唯一的,互不相同。
从形式上看,和字典类似,Python 集合会将所有元素放在一对大括号 {} 中,相邻元素之间用“,”分隔,如下所示:
# 创建一个空的set集合
# cities = set()
# 使用{}创建带有数据的set集合且不能重复
cities = {'hunan', 'shanghai', 'beijing','hunan'}
print(cities)
# 出栈,随机
print(cities.pop())
# 指定删除,remove删除不存在的元素则报错
# cities.remove("hunan")
# 判断元素是否存在
if "hunan" in cities:
cities.remove("hunan")
# discard删除不存在的元素不报错
cities.discard("beijing")
# clear代表清除
cities.clear()
print(cities)
# 集合运算
a = {1, 2, 3, 4}
b = {3, 4, 5, 6}
# a-b的差集
print('a-b的差集:'+str(a - b))
# b-a的差集
print('b-a的差集:'+str(b - a))
# a和b的并集
print('a | b的并集:'+str(a | b))
# a和b的交集
print('a & b的交集:'+str(a & b))
# a和b的对称差集
print('a ^ b的对称差集:'+str(a ^ b))字典
Python字典(dict)是一种无序的、可变的序列,它的元素以“键值对(key-value)”的形式存储。相对地,列表(list)和元组(tuple)都是有序的序列,它们的元素在底层是挨着存放的。
在Python中,字典用放在花括号{}中的一系列键—值对表示。(与JSON类似)
person={
"name":"张三",
"age":21,
"salary":3000
}
print(person["name"])
print(person["age"])
print(person["salary"])
person["score"]=90
print(person)二,语法进阶
运算符


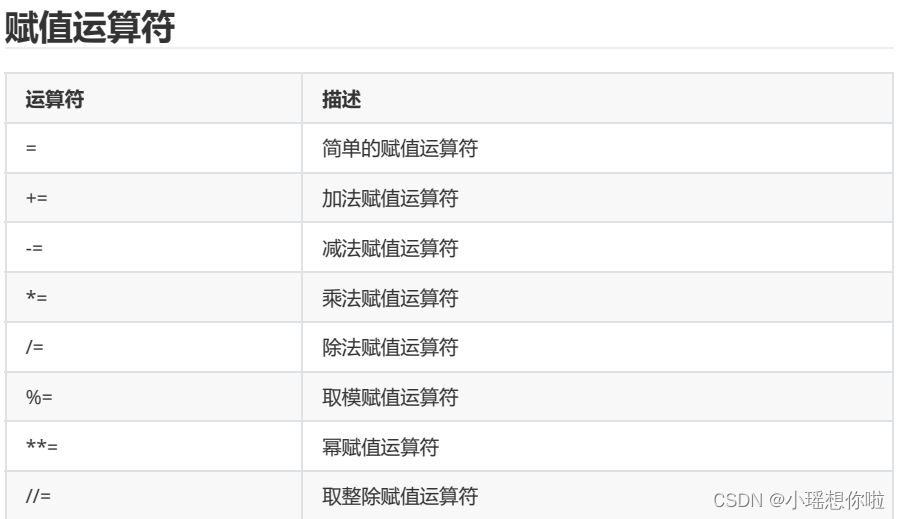
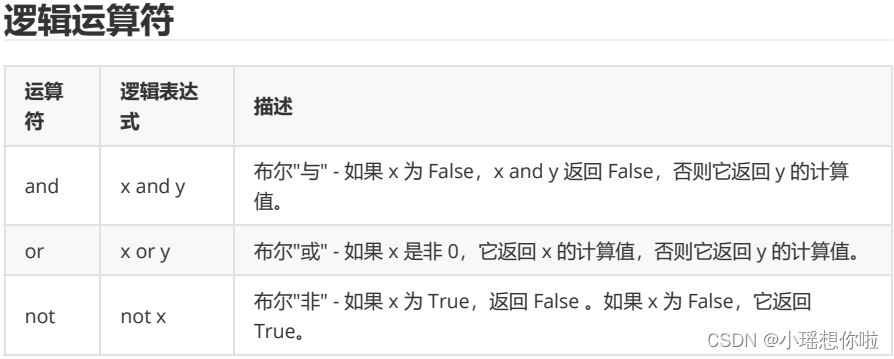
案例: 根据速度完成对等级的判断
假设对成长速度显示规定如下:
成长速度为5显示等级1;
成长速度为10显示等级2;
成长速度为12显示等级3;
成长速度为15显示等级4;
其他都显示都显示等级0;
speed = 15
level = \
(speed == 5 and 1) \
or \
(speed == 10 and 2) \
or \
(speed == 15 and 3) \
or \
(speed == 20 and 4) \
or 0
print('等级' + str(level))
speed = 5
level_obj = {
'5': 1,
'10': 2,
'15': 3,
'20': 4
}
print(level_obj.get(str(speed)) or 0)位运算符
按位运算符是把数字看作二进制来进行计算的。
使用位运算判断奇偶数的示例
def is_even(n):
return (n & 1) == 0
def is_odd(n):
return (n & 1) == 1
print(is_even(2))
print(is_even(3))
print(is_odd(2))
print(is_odd(3)) 按位异或交换变量的示例
a = 10
b = 5
print("交换前:a =", a, "b =", b)
# 交换变量值
a = a ^ b
b = a ^ b
a = a ^ b
print("交换后:a =", a, "b =", b)三元运算符
max = a if a>b else b
这是一种类似于其它编程语言中三目运算符`? :`的写法。Python 是一种极简主义的编程语言,它没有引入`? :`这个新的运算符,而是使用已有的 if else 关键字来实现相同的功能。
使用 if else 实现三目运算符(条件运算符)的格式如下:
exp1 if condition else exp2
condition 是判断条件,exp1 和 exp2 是两个表达式。如果 condition 成立(结果为真),就执行 exp1,并把 exp1 的结果作为整个表达式的结果;如果 condition 不成立(结果为假),就执行 exp2,并把 exp2 的结果作为整个表达式的结果。
# 2.条件判断
在Python中,可以使用 if else 语句对条件进行判断,然后根据不同的结果执行不同的代码,这称为选择结构或者分支结构。Python 中的 if else 语句可以细分为三种形式,分别是 if 语句、if else 语句和 if elif else 语句。
```python
# 0=剪刀 1=石头 2=布
nums = ["剪刀","石头","布"]
# 你出的
ops = int(input("请输入剪刀石头布:"))
# 电脑出的
cpu = random.randint(0,2)
# 计算必赢结果
win = ops + 1
win = 0 if ops == 3 else win
print("你出%s,电脑出%s,输赢结果:%s" %(nums[ops],nums[cpu],nums[win]))
if cpu==win:
print("电脑赢了")
elif ops == cpu:
print("平局")
else:
print("你赢了")
```
Python 提供了一种更加专业的做法,就是空语句 pass。**pass** 是 Python 中的关键字,用来让解释器跳过此处,什么都不做。
2.循环结构
2.1 for循环
Python中的循环语句有 2 种,分别是 while 循环和 for 循环,而for循环它常用于遍历字符串、列表、元组、字典、集合等序列类型,逐个获取序列中的各个元素。
示例一:通过for循环计算100以内的和
sum = 0
for i in range(100):
print(i)
sum+=i+1
print(sum)示例二:通过for循环计算100以内的奇数和
sum = 0
for i in range(100)[1::2]:
print(i)
sum+=i
print(sum)2.2 while循环
而while 循环和 if 条件分支语句类似,即在条件(表达式)为真的情况下,会执行相应的代码块。不同之处在于,只要条件为真,while 就会一直重复执行那段代码块。
while 语句的语法格式如下
sum = 0 # 求和
num = 0 # 当前数值
while num <= 100:
sum += num
num = num + 1
break
else:
print("OK")
print(sum)三,函数使用
3.1,什么是函数:
Python中函数的应用非常广泛,前面章节中我们已经接触过多个函数,比如 input() 、print()、range()、len() 函数等等,这些都是 Python 的内置函数,可以直接使用。
除了可以直接使用的内置函数外,Python 还支持自定义函数,将一段有规律的、可重复使用的代码定义成函数,从而达到一次编写、多次调用的目的。
Python 提供了一个功能,即允许我们将常用的代码以固定的格式封装(包装)成一个独立的模块,只要知道这个模块的名字就可以重复使用它,这个模块就叫做函数(Function)。
3.2 函数与方法的区别:
直接调用的是函数
通过对象点出来的是方法
nums = [1, 2, 3]
print(len(nums)) # 函数
nums.append(4) # 方法2.函数的定义
定义函数,也就是创建一个函数,可以理解为创建一个具有某些用途的工具。定义函数需要用 def 关键字实现,具体的语法格式如下:
def 函数名(参数列表):
#实现特定功能的多行代码
[return [返回值]]其中,用 [] 括起来的为可选择部分,即可以使用,也可以省略。
此格式中,各部分参数的含义如下:
函数名:其实就是一个符合 Python 语法的标识符,但不建议读者使用 a、b、c 这类简单的标识符作为函数名,函数名最好能够体现出该函数的功能。
形参列表:设置该函数可以接收多少个参数,多个参数之间用逗号( , )分隔。
[return [返回值] ]:整体作为函数的可选参参数,用于设置该函数的返回值。也就是说,一个函数,可以用返回值,也可以没有返回值,是否需要根据实际情况而定。
注意:在创建函数时,即使函数不需要参数,也必须保留一对空的“()”,否则 Python 解释器将提示“invaild syntax”错误。另外,如果想定义一个没有任何功能的空函数,可以使用 pass 语句作为占位符。
入门案列
def add():
"""函数方法注释"""
print("hello python")
add()
3.3.函数的参数传递
通常情况下,定义函数时都会选择有参数的函数形式,函数参数的作用是传递数据给函数,令其对接收的数据做具体的操作处理。
在使用函数时,经常会用到形式参数(简称“形参”)和实际参数(简称“实参”),二者都叫参数,之间的区别是:
形式参数:在定义函数时,函数名后面括号中的参数就是形式参数:
#定义函数时,这里的函数参数 obj 就是形式参数
def demo(obj):
print(obj)
实际参数:在调用函数时,函数名后面括号中的参数称为实际参数,也就是函数的调用者给函数的参数:
a = "Zking"
#调用已经定义好的 demo 函数,此时传入的函数参数 a 就是实际参数
demo(a)
实参和形参的区别,就如同剧本选主角,剧本中的角色相当于形参,而演角色的演员就相当于实参。
示例二:定义一个函数,传入一个名字xx,输出你好,xx**
# 注意:方法名称定义不要使用驼峰命名,请使用下划线方法
# 错误方式:getUser()
# 正确方式:get_user()
def get_user(name):
print(f"学员名称:{name}")
# 错误方式:get_user()
# 正确方式:get_user("张三")
get_user('张三')
```调用有参函数时,不传递参数,提示错误如下:
`TypeError: get_user() missing 1 required positional argument: 'name'`代码在编写之间不会出现报错,只有在运行期间才会出现错误。
示例三:定义一个函数,输出两个数字相加的结果
def add(a, b):
return a + bprint(add(1,2))
print(add('my name is',' zhangsan'))传递不同类型的参数:
python
print(add(1,'zhangsan'))运行提示错误: `TypeError: unsupported operand type(s) for +: 'int' and 'str'`
Python对于参数的传入是没有类型限制的,不过可以通过给参数添加类型,**提示调用时应传入的类型**
def res(a: int, b: int):
return a+b
3.4.传参的几种情况
**位置传参**
res(1, 2)- **关键字传参**
res(a=1, b=2)
res(b=10, c=5)
- **缺省参数**
def add(a: int, b: int = 10):
return a + b
print(add(1))
```参数具备默认值的时候可以不传,具备默认值的参数需要放在没有默认值的参数后面。
- **可变参数**
单个*号的可变参数方式,传入得到的是一个元组。
def my_max(*nums):
print(nums)
val = nums[0] # 获取第一个元素
for i in nums[1:]: # 通过切片的方式排除掉第一个元素
val = val if val > i else i # 通过三元运算符比较最大值
return valprint(my_max(1, 2, 3))
```两个**号的可变参数方式,传入得到的是一个字典。
def my_max(**nums):
print(nums)
val=0
# for i in nums.values(): # nums.values()获取字典中所有的值
# for i in nums.keys(): # nums.keys()获取字典中所有的键
# for i in nums.items(): # num.items()获取字典中的键值对,元组方式
# print(f'items:{i},key:{i[0]},value:{i[1]}')
for k,v in nums.items(): # num.items()获取字典中的键值对,分别获取k和v
print(f"key={k},value={v}")
# 错误方式:
# my_max(1,2,3,4,5)
# 正确方式:
my_max(a=1,b=2,c=3)
3.5.函数的返回值
Python中,用 def 语句创建函数时,可以用 return 语句指定应该返回的值,该返回值可以是任意类型。需要注意的是,return 语句在同一函数中可以出现多次,但只要有一个得到执行,就会直接结束函数的执行。
Python 函数可以返回多个值,多个值以元组的方式返回(也可以通过字典返回自定义结果):
def res(*nums: int):
max = nums[0]
min = nums[0]
sum = nums[0]
for i in nums[1:]:
max = max if max > i else i
min = min if min < i else i
sum += i
#return sum, min, max # 元组方式返回
return { # 字典方式返回
'总和': sum,
'最大值': max,
'最小值': min
}
print(res(1, 2, 3, 4, 5, 6, 7, 8, 9))3.6.函数的注释
其实,函数的注释(说明文档),本质就是一段字符串,只不过作为说明文档,字符串的放置位置是有讲究的,函数的说明文档通常位于函数内部、所有代码的最前面。
def add(a, b):
"""
返回两个数相加的和
:param a: 参数数字a
:param b: 参数数字b
:return: 和
"""
return a + b
查看python中关于函数的说明: help()
3.7.其他
def a(a, b):
return a + b
def b(c, d):
return a(c, d) / 2
print(b(4, 8))3.7.1,变量作用域
所谓作用域(Scope),就是变量的有效范围,就是变量可以在哪个范围以内使用。有些变量可以在整段代码的任意位置使用,有些变量只能在函数内部使用,有些变量只能在 for 循环内部使用。
变量的作用域由变量的定义位置决定,在不同位置定义的变量,它的作用域是不一样的。
- 在函数内部定义的变量,它的作用域也仅限于函数内部,出了函数就不能使用了,我们将这样的变量称为局部变量(Local Variable)。
def demo():
add = "zking"
print("函数内部 add =",add)
demo()
print("函数外部 add =",add)
除了在函数内部定义变量,Python 还允许在所有函数的外部定义变量,这样的变量称为全局变量(Global Variable)。
add = "zking"
def text():
print("函数体内访问:",add)
text()
print('函数体外访问:',add)3.7.2.递归调用
- **示例:计算n+1的和**
def res(target: int):
if target == 1:
return 1
return target + res(target - 1)
print(res(100))**示例:斐波那契数列**
# 1,1,2,3,5,8,13,21,34,55,...
def fb(target: int):
if target == 1 or target == 2:
return 1
return fb(target - 1) + fb(target - 2)
print(fb(10))3.8.lambda表达式
lambda 表达式,又称匿名函数,常用来表示内部仅包含 1 行表达式的函数。如果一个函数的函数体仅有 1 行表达式,则该函数就可以用 lambda 表达式来代替。
lambda 表达式的语法格式如下:
```python
lambda 参数 : 执行操作/返回值
```# 未简写方式:
def res():
return 10
# 简写方式:
res1 = lambda: 10
def res(a):
return a+10
print(res(1))
res2=lambda a:a+10
print(res2(10))
def res(a,b):
return a if a>b else b
res3=lambda a,b: a if a>b else b
print(res3(10,5))使用 lambda 对字典数据进行排序
通过sort方法实现对列表的排序:
nums=[1,6,5,2,3,4]
nums.sort() #升序
nums.sort(reverse=False) #降序
print(nums)使用 lambda 对字典数据进行排序:
persons = [
{"name": "张三", "age": 20},
{"name": "李四", "age": 17},
{"name": "王麻子", "age": 21}
]
persons.sort(key=lambda p:p["age"],reverse=True)
print(persons)将一个元素中所有的值翻倍 map
nums=[1,2,3,4,5,6,7,8]
m=map(lambda a:a*2,nums)
for i in m:
print(i)让列表中的对应位置进行相加
nums1=[1,2,3,4,5,6,7,8]
nums2=[2,3,4,5,6,7,8,9]
m1=map(lambda a,b:a+b,nums1,nums2)
for i in m1:
print(i)对列表进行筛选
nums3=[1,2,3,4,5,6,7,8]
f=filter(lambda a:a>5,nums3)
for i in f:
print(i)四,函数进阶
4.1.多参数解析
使⽤ `*args` 和 `**kwargs` 来调⽤函数。
def res(arg1, arg2, arg3):
print("arg1:", arg1)
print("arg2:", arg2)
print("arg3:", arg3)使用普通参数方式:
res(1, 2, 3)使用`*args`非关键字可变参数方式:
# 以元祖方式传递
nums = (1, 2, 3)使用`**kwargs`关键字可变参数方式:
kwargs = {
"arg1": 1,
"arg2": 2,
"arg3": 3
}
res(**kwargs)4.2.闭包
如果在一个函数的内部定义了另一个函数,**外部的我们叫他外函数**,**内部的我们叫他内函数。
闭包函数:**声明在一个函数中的函数,叫做闭包函数。
def hello():
def say():
print("hello python")
hello()注意:hello代表方法本身;hello()代表方法的返回值。
有返回值情况
def hello():
a = 10
def say():
print("hello python")
return say注意:此时可以发现hello()方法的返回值是say方法,也就是它的内部函数。
闭包:在一个外函数中定义了一个内函数,内函数里运用了外函数中声明的参数和变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包。
为什么需要闭包
记忆化:闭包可以用于记忆化函数的执行结果,以避免重复计算,从而提高程序的执行效率
保护数据:闭包可以用于保护数据的安全性,例如将一些敏感的数据隐藏在闭包内部,防止其被外部访问和修改
实现装饰器:闭包可以用于实现装饰器,从而在不修改原函数的情况下增加新的功能,例如日志记录、性能分析等
编写代码库:闭包可以用于编写通用的代码库,以便在不同的项目中重复使用(闭包便于进行功能扩展)
实现函数工厂:闭包可以用于实现函数工厂,从而动态地创建函数
实现柯里化:闭包可以用于实现柯里化,从而将一个接受多个参数的函数转换为一系列接受单个参数的函数
def outer(a):
def inner(b):
return a+b
return inner函数inner就被包括在函数outer内部,这时outer内部的所有局部变量,对inner都是可见的。但是反过来就不行,inner内部的局部变量,对outer就是不可见的。所以,父对象的所有变量,对子对象都是可见的,反之则不成立。
# 获取最外层的outer方法的返回值:inner
# 外部函数接收一个参数,并返回一个函数,接着调用内层函数并传入了参数,并返回计算后的结果。也可以如下定义
'''
def add(a,b):
return a + b# 如果如上定义,则调用时需要传递两个参数,使用闭包可以将一个接受多个参数的函数转换为一系列接受单个参数的函数,这种情况叫做柯里化,是一种函数式编程技术
res = outer(5)
print(res(6))注意:外层函数的变量将持久地保存在内存中。
4.3.装饰器
装饰器是闭包的一种应用。装饰器就是用于拓展原来函数功能的一种函数,这个函数的特殊之处在于它的返回值也是一个函数,使 用装饰器的好处就是在不用更改原函数的代码前提下给函数增加新的功能。
# 开启事务
核心业务处理
# 提交/回滚事务可以理解为Spring中的AOP。
示例一:**初识装饰器
def Transaction(func):
def wrapper():
print("开启事务处理")
func()
print("提交事务处理")
return wrapper
@Transaction
def hello():
print("hello python")
hello()
print(hello.__name__) 注意:当使用装饰器@Transaction修饰方法时,`hello.__name__`返回的方法名称就不是当前hello方法了,而是被装饰器中的wrapper方法所取代。
@wraps(func)`的作用: 不改变使用装饰器原有函数的结构
@wraps(func)`的意义是什么:
* 保留被装饰函数的元信息
* 简化装饰器的调试和使用,如果没有使用 `@wraps` 装饰器,那么装饰器函数的名称和文档字符串将会被覆盖为装饰器函数本身的名称和文档字符串,从而可能使得调试和使用装饰器变得困难
* 提高代码可读性:使用 `@wraps` 装饰器可以使得装饰器函数和被装饰函数之间的关系更加明确,从而提高代码的可读性和可维护性
from functools import wraps
def Transaction(func):
@wraps(func)
def wrapper():
print("开启事务处理")
func()
print("提交事务处理")
return wrapper
@Transaction
def hello():
print("hello python")
hello()
print(hello.__name__)示例二:**带参数的装饰器
装饰器中可以传入参数,先形成一个完整的装饰器,然后再来装饰函数,当然函数如果需要传入参数也 是可以的,用不定长参数符号就可以接收。
def logging(level='debug'):
print(level)
def outer_wrapper(func):
def inner_wrapper(*args, **kwargs):
print(f"{level}: enter {func.__name__}()")
return func(*args, **kwargs)
return inner_wrapper
return outer_wrapper
@logging("info")
def hello():
print("hello python")
hello()注意:@logging装饰器带括号和不带括号的区别。
1) @logging不带括号,hello函数名作为参数传入,则在level参数接收到的是hello函数;
2) @logging()带括号,则使用logging中的level默认参数或者传入参数覆盖level默认参数;
def logging(logfile='out.txt'):
def decorator(func):
def wrapped_function(*args, **kwargs):
log_string = func.__name__ + "被调用了"
# 打开logfile,并写⼊内容
with open(logfile, 'a') as opened_file:
# 现在将⽇志打到指定的logfile
opened_file.write(log_string + '\n')
return wrapped_function
return decorator
@logging()
def hello():
pass
hello()4.4.实战案例:电影管理系统
movies = [{"no": "1292052", "name": "肖申克的救赎", "rating": 9.7, "inq": "希望让人自由。"},
{"no": "1291546", "name": "霸王别姬", "rating": 9.6, "inq": "风华绝代。"},
{"no": "1292720", "name": "阿甘正传", "rating": 9.5, "inq": "一部美国近现代史。"},
{"no": "1295644", "name": "这个杀手不太冷", "rating": 9.4, "inq": "怪蜀黍和小萝莉不得不说的故事。"},
{"no": "1292722", "name": "泰坦尼克号", "rating": 9.4, "inq": "失去的才是永恒的。"},
{"no": "1292063", "name": "美丽人生", "rating": 9.6, "inq": "最美的谎言。"},
{"no": "1291561", "name": "千与千寻", "rating": 9.4, "inq": "最好的宫崎骏,最好的久石让。"},
{"no": "1295124", "name": "辛德勒的名单", "rating": 9.5, "inq": "拯救一个人,就是拯救整个世界。"},
{"no": "3541415", "name": "盗梦空间", "rating": 9.3, "inq": "诺兰给了我们一场无法盗取的梦。"},
{"no": "3541416", "name": "风语者", "rating": 9.3, "inq": "二战影片。"},
{"no": "3011091", "name": "忠犬八公的故事", "rating": 9.4, "inq": "永远都不能忘记你所爱的人。"}]
查询显示所有的电影方法
- 增加电影的方法
* 单条加入
def movies_add(movie):
添加电影方法
:param movie: 待增加的电影,字典类型
:return:
movies.append(movie)
movie = {"no": "3541417", "name": "拯救大兵瑞恩", "rating": 9.3, "inq": "二战影片。"}
movies_add(movie)
批量增加
mvs = [
{"no": "3541418", "name": "最长的一天", "rating": 9.3, "inq": "二战影片。"},
{"no": "3541419", "name": "诺曼底登录", "rating": 9.3, "inq": "二战影片。"},
{"no": "3541420", "name": "偷袭珍珠港", "rating": 9.3, "inq": "二战影片。"}
]
def movies_lst_add(ms):
movies.extend(ms)
movies_lst_add(mvs)
for m in movies:
print(m)
- 电影集合排序,默认根据评分排序
def movies_sort(sort_prop :str = "rating", reverse :bool = True):
对电影数据进行排序
:param sort_prop: 排序字段,如不指定默认为rating
:param reverse: 排序类型,如不指定默认为True,即降序排序
:return:
movies.sort(key = lambda p:p[sort_prop], reverse=reverse)
movies_sort("no", False)
for m in movies:
print(m)删除电影的方法,如果没有则默认删除最后一个
def movies_del_by_no(no :str=None):
删除指定编号的电影,如果没有指定则默认删除最后一个
:param no: 电影编号 字符串型,默认为None
:return: movies,删除指定电影之后的列表数据
if no is None:
del movies[-1]
return movies
else:
# 方式1 过滤出所有不等于指定条件的列表元素,然后返回
# return list(filter(lambda p: p['no'] != no, movies))
# 方式2 过滤出所有不等于指定条件的列表元素,然后返回
# return [mv for mv in movies if mv['no'] != no]
# 方式3
for mv in movies:
if mv['no'] == no:
movies.remove(mv)
return movies
temp = movies_del_by_no('1291546')
for m in temp:
print(m)
- 修改电影的方法
def up_movie(no:str=None, prop:str=None, val=None):
修改指定编号的电影信息
:param no: 需要修改的电影编号
:param prop: 需要修改的属性
:param val: 修改后的值
:return:
if no is None or prop is None or val is None:
print("电影编号no,需要修改的属性prop,修改的值val三个参数必须传入")
return
for m in movies:
if m["no"] == no:
m[prop] = val
return
up_movie('3541419','rating', 9.9)
- 查询分页的方法(可以完成评分筛选)
def movies_paging(rating, page :int=1, limit :int=10):
begin = page - 1
end = page * limit
if rating is None:
return movies[begin:end]
else:
tmp = [mv for mv in movies if mv['rating'] >= rating]
return tmp[begin:end]
tmp = movies_paging(9.3,1, 2)
``````python
# 采用闭包的方式实现
def movies_filter(rating: float = None):
根据指定的评分数据对电影进行过滤
:param rating: 评分,默认值为None
:return:
def paging(page: int = 1, limit: int = 10):
对已过滤的电影数据分页显示
:param page: 显示的页码
:param limit: 每页显示的行数
:return:
begin = page - 1
end = page * limit
if rating is None:
return [mv for mv in movies][begin:end]
else:
return [mv for mv in movies if mv['rating'] >= rating][begin:end]
return paging
tmp = movies_filter()(1, 2)
五,面向对象
5.1,面向对象
面向对象是把构成问题的事物分解成各个对象,每个对象都有自己独立的属性和行为, 对象可以将整个问题事务进行分工, 不同的对象做不同的事情, 这种面向对象的编程思想由于更加贴近实际生活, 所以被计算机语言广泛应用。
常见的面向对象编程语言:Java / C++ / Python等等;
面向过程就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了。
面向过程:C
总之,Python中万事万物皆对象,而面向对象的三大特性:封装、继承和多态。
5.2.类的定义
Python 中定义一个类使用 class 关键字实现,其基本语法格式如下:
class 类名:
多个(≥0)类属性...
多个(≥0)类方法...
注意,无论是类属性还是类方法,对于类来说,它们都不是必需的,可以有也可以没有。另外,Python 类中属性和方法所在的位置是任意的,即它们之间并没有固定的前后次序。
和变量名一样,类名本质上就是一个标识符,因此我们在给类起名字时,必须让其符合 Python 的语法。有读者可能会问,用 a、b、c 作为类的类名可以吗?从 Python 语法上讲,是完全没有问题的,但作为一名合格的程序员,我们必须还要考虑程序的可读性。
因此,在给类起名字时,最好使用能代表该类功能的单词,例如用`Student`作为学生类的类名;甚至如果必要,可以使用多个单词组合而成。
class Dog:
name: str = "小黑"
age: int = 2注意,如果由单词构成类名,建议每个单词的首字母大写,其它字母小写;同属一个类的所有类属性和类方法,要保持统一的缩进格式,通常统一缩进 4 个空格
5.2.1.实例化对象
对已定义好的类进行实例化,其语法格式如下:
类名(参数)
定义类时,如果没有手动添加 `__init__()` 构造方法,又或者添加的 `__init__()` 中仅有一个 self 参数,则创建类对象时的参数可以省略不写。
# java方式:Dog d1=new Dog();
d1 = Dog()
d2 = Dog()
print(d1)
print(d2)5.2.2.类变量
类变量指的是在类中,但在各个类方法外定义的变量。举个例子:
class Dog:
name: str="小花"
type: str="金毛"
age: int = 3上述代码中,name和age都是类变量。
类变量的特点是,所有类的实例化对象都同时共享类变量,也就是说,类变量在所有实例化对象中是作为公用资源存在的。类方法的调用方式有 2 种,既可以使用类名直接调用,也可以使用类的实例化对象调用。
通过类名调用类变量和修改类变量的值:
# 使用类名直接调用
print(f"name={Dog.name},type={Dog.type},age={Dog.age}")
# 修改类变量的值
Dog.name="钱多多"
print(Dog.name)所有类的实例化对象都同时共享类变量:
class Dog:
name: str = "小黑"
age: int = 3
d2 = Dog()
d3 = Dog()
print(d2.name)
print(d3.name)
Dog.name="小白"
print(d2.name)
print(d3.name)显然,通过类名修改类变量,会作用到所有的实例化对象
5.2.3.函数和实例变量
实例变量指的是在任意类方法内部,以“self.变量名”的方式定义的变量,其特点是只作用于调用方法的对象。另外,实例变量只能通过对象名访问,无法通过类名访问。
class Dog:
name: str="小花"
type: str="金毛"
age: int = 3
def say(self):
pass每个与类相关联的方法调用都自动传递实参self,它是一个指向实例本身的引用,让实例能够访问类中的属性和方法。**相当于Java中的this**
def say(self):
print(f"你好,我是{self.name}")携带多个参数时,其他的参数放在 self 之后:
def say(self,food: str):
print(f"你好,我是{self.name}!我喜欢吃{food}")类中,实例变量和类变量可以同名,但这种情况下使用类对象将无法调用类变量,它会首选实例变量,这也是不推荐**类变量使用对象名调用**的原因。
5.3.__init__()构造函数
在创建类时,我们可以手动添加一个 `__init__()` 方法,该方法是一个特殊的类实例方法,称为构造方法(或构造函数)。
构造方法用于创建对象时使用,每当创建一个类的实例对象时,Python解释器都会自动调用它。Python类中,手动添加构造方法的语法格式如下:
def __init__(self,...):
代码块
注意,此方法的方法名中,开头和结尾各有 2 个下划线,且中间不能有空格。Python 中很多这种以双下划线开头、双下划线结尾的方法,都具有特殊的意义
- 定义类时,如果没有手动添加 `__init__()` 构造方法,又或者添加的 `__init__()` 中仅有一个 self 参数,则创建类对象时的参数可以省略不写,如下所示:
class Dog:
def __init__(self):
print("实例化")
d = Dog()__init__() 方法可以包含多个参数,但必须包含一个名为 self 的参数,且必须作为第一个参数。也就是说,类的构造方法最少也要有一个 self 参数。如下所示:
class Dog:
def __init__(self,sname: str,sage: int):
print("正在使用多参数的init函数进行实例化")
d = Dog("小白",2)在python没有重载一说,如果硬是要做,可以使用默认值方式:
class Dog:
def __init__(self,sname: str='',sage: int=0):
print("正在使用多参数的init函数进行实例化")
d = Dog(sname="小白")5.4.魔法函数
Python 类中,凡是以双下划线 "__" 开头和结尾命名的成员(属性和方法),都被称为类的特殊成员(特殊属性和特殊方法)。例如,类的 __init__(self) 构造方法就是典型的特殊方法。
示例一:`__str__()`
重载父类object中的`__str__()`用于将值转化为字符串形式:
class Dog:
def __str__(self):
return f"name={self.name},age={self.age},sex={self.sex}"示例二:`__call__()`
Python类中一个非常特殊的实例方法,即 `__call__()`。该方法的功能类似于在类中重载 () 运算符,使得类实例对象可以像调用普通函数那样,以“对象名()”的形式使用。
class Dog:
# 定义__call__方法
def __call__(self,name,age):
print("调用__call__()方法",name,age)
d1 = Dog()
d1("小花",2)可以看到,通过在 Dog 类中实现 `__call__()` 方法,使的 d1实例对象变为了可调用对象。
函数缓存示例:
class FunCahce:
"""
函数缓存,可以将函数的执行结果进行缓存,以便于在下次调用时直接从缓存中获取结果。
如果函数需要缓存可以使用该类包装
"""
def __init__(self, func):
self.func = func
self.cache = {}
def __call__(self, *args):
if args not in self.cache:
self.cache[args] = self.func(*args)
print("use cache")
return self.cache[args]
def fibonacci(n):
"""
定义一个计算斐波那契额数列的函数
:param n:
:return:
"""
if n < 2:
return n
return fibonacci(n - 1) + fibonacci(n - 2)
# 使用函数缓存类包装,通过缓存提升性能,可以将该行注释对比使用缓存与不使用缓存的区别
fibonacci = FunCahce(fibonacci)
print(fibonacci(100))更多内容,请查看[Python中的魔法函数:https://zhuanlan.zhihu.com/p/344951719
5.5.三大特性
5.5.1.封装
简单的理解封装(Encapsulation),即在设计类时,刻意地将一些属性和方法隐藏在类的内部,这样在使用此类时,将无法直接以“类对象.属性名”(或者“类对象.方法名(参数)”)的形式调用这些属性(或方法),而只能用未隐藏的类方法间接操作这些隐藏的属性和方法。
property()函数:
我们一直在用“类对象.属性”的方式访问类中定义的属性,其实这种做法是欠妥的,因为它破坏了类的封装原则。正常情况下,类包含的属性应该是隐藏的,只允许通过类提供的方法来间接实现对类属性的访问和操作。
因此,在不破坏类封装原则的基础上,为了能够有效操作类中的属性,类中应包含读(或写)类属性的多个 getter(或 setter)方法,这样就可以通过“类对象.方法(参数)”的方式操作属性,例如:
**通过添加 __ 修饰符将变量声明为私有化属性。**
class Dog:
name: str = '小黑'
age: int = 3
__sex: str = '公'被修饰的变量无法再类的外部被访问,但是可以通过 self 对象来调用。
# 提供getter/setter
def get_sex(self):
return self.__sex
def set_sex(self, sex: str):
self.__sex = sex类方法:
Python 类方法和实例方法相似,它最少也要包含一个参数,只不过类方法中通常将其命名为 cls,Python 会自动将类本身绑定给 cls 参数(注意,绑定的不是类对象)。也就是说,我们在调用类方法时,无需显式为 cls 参数传参。
和 self 一样,cls 参数的命名也不是规定的(可以随意命名),只是 Python 程序员约定俗称的习惯而已。
和实例方法最大的不同在于,类方法需要使用`@classmethod`修饰符进行修饰,例如:
class Dog:
# 类方法
@classmethod
def info(cls):
print(cls)注意,如果没有 `@classmethod`,则 Python 解释器会将 fly() 方法认定为实例方法,而不是类方法。
类方法推荐使用类名直接调用,当然也可以使用实例对象来调用(不推荐)。
d1 = Dog()
d1.info()
Dog.info()静态方法:
静态方法,其实就是我们学过的函数,和函数唯一的区别是,静态方法定义在类这个空间(类命名空间)中,而函数则定义在程序所在的空间(全局命名空间)中。
静态方法没有类似 self、cls 这样的特殊参数,因此 Python 解释器不会对它包含的参数做任何类或对象的绑定。也正因为如此,类的静态方法中无法调用任何类属性和类方法。
静态方法需要使用`@staticmethod`修饰,例如:
class Dog:
# 静态方法
@staticmethod
def say():
print("静态方法被调用了...")静态方法的调用,既可以使用类名,也可以使用类对象,例如:
d1 = Dog()
d1.say()
Dog.say()5.5.2.继承
Python 中,实现继承的类称为子类,被继承的类称为父类(也可称为基类、超类)。
子类继承父类时,只需在定义子类时,将父类(可以是多个)放在子类之后的圆括号里即可。语法格式如下:
class 类名(父类1, 父类2, ...):
#类定义部分
注意,如果该类没有显式指定继承自哪个类,则默认继承 object 类(object 类是 Python 中所有类的父类,即要么是直接父类,要么是间接父类)。另外,Python 的继承是多继承机制(和 C++一样),即一个子类可以同时拥有多个直接父类。
class Father(object):
height=180
money=100
def work(self):
print("会工作")
pass
class Mother(object):
fact='漂亮'
money=90
def cook(self):
print("会做饭")
pass
class Son(Father,Mother):
pass
# 创建son的实例
s=Son()
s.cook()
s.work()
print(s.fact)
print(s.height)
print(s.money)同时继承 Father类和 Mother类时,Father类在前,当属性和方法重复时,越往前优先级越高。
查看继承关系
print(Dog.__bases__)
print(Dog.__mro__)5.5.3.多态
class Animal(object):
def play(self):
pass
class Tiger(Animal):
def play(self):
print("正在表演老虎后脚直立行走")
class Lion(Animal):
def play(self):
print("正在表演狮子跳火圈")
class Person(object):
def show(self, a: Animal):
print("动物表演开始了")
a.play()
p = Person()
tiger = Tiger()
lion = Lion()
p.show(tiger)
p.show(lion)5.6.扩展
## 4.1.__slots__
每个类都有实例属性。默认情况下Python⽤⼀个字典来保存⼀个对象的实例属性。**所以我们在可以在运⾏时去设置任意的新属性**。
所以,动态给类或者实例对象添加属性或方法,是非常灵活的。但与此同时,如果胡乱地使用,也会给程序带来一定的隐患,即程序中已经定义好的类,如果不做任何限制,是可以做动态的修改的。
Python 提供了 `__slots__` 属性,通过它可以避免用户频繁的给实例对象动态地添加属性或方法。
class Dog(object):
__slots__ = ["name","age"]
def __init__(self,name,age):
print("实例化")
self.name=name
self.age=age
class Dog(object):
__slots__ = ["name","age"]
def __init__(self,name,age):
print("实例化")
self.name=name
self.age=age类装饰器
类装饰器在内部的装饰函数是用`__call__()` 方法实现的。
class Logger(object):
def __init__(self, path='out.txt'):
self.path = path
def __call__(self, func):
def inner():
log = func.__name__ + "执行"
with open(self.path, 'a') as opened_file:
opened_file.write(log + '\n')
self.notify()
return inner
def notify(self):
pass
@Logger()
def hello():
pass
hello()@Logger** 的在这里的作用实际就是实例化一个**fun**对象(fun=Logger(fun))
六,模块使用
6.1.模块和包
6.1.1.模块
简而言之,在python中,一个文件(以“.py”为后缀名的文件)就叫做一个模块,每一个模块在python里都被看做是一个独立的文件。模块可以被项目中的其他模块、一些脚本甚至是交互式的解析器所使用,它可以被其他程序引用,从而使用该模块里的函数等功能,使用Python中的标准库也是采用这种方法。
导入模块的三种方式:
方式一:import 模块名
# 导入整个demo模块
import demo
# 使用demo模块名作为前缀访问模块中的Tiger类
t = demo.Tiger()
# 使用demo模块名作为前缀访问模块中的函数
demo.say()导入整个模块时,也可以为模块指定别名:
# 导入整个demo模块,并更名为d的别名import demo as d t = d.Tiger() d.say()也可以一次导入多个模块,多个模块之间用逗号隔开:
# 导入demo,demo02两个模块
import demo,demo02
# 使用模块名访问模块中的成员
demo.say() demo02.hello()在导入多个模块的同时,也可以为模块指定别名:
import demo as d,demo as d1方式二:from 模块名 import 功能名**
使用了 from...import 最简单的语法来导入指定成员:
# 导入demo模块中的指定成员from demo import Tiger t = Tiger() print(Tiger.name)导入模块成员时,也可以为成员指定别名:
# 导入demo模块的Tiger成员,并为其指定别名tg
from demo import Tiger as tg
t = tg()方式三:from 模块名 import
在Python项目下创建fun包,并在`__init__.py`文件中配置包的导入行为。
# 导入fun包下中demo01模块下的Lion成员
from fun.demo01 import Lion__all__ = ["Lion"]
> 只有以“from 模块名 import *”形式导入的模块,当该模块设有 `__all__` 变量时,只能导入该变量指定的成员,未指定的成员是无法导入的。
```python
# 导入fun包
from fun import *
l = Lion()
包将有联系的模块组织在一起,放在同一个文件夹下,这个文件夹就称之为包。每个包下默认会有一个`__init__.py`文件。(**`__init__.py`控制着包的导入行为**)
`__init__.py` 文件定义了包的属性和方法。其实它可以什么也不定义;可以只是一个空文件,但是必须存在。如果 `__init__.py` 不存在,这个目录就仅仅是一个目录,而不是一个包,它就不能被导入或者包含其它的模块和嵌套包。
导入包的三种方式:
import 包名[.模块名 [as 别名]]
import my_package.module1
# 必须通过包名.模块名的方式访问模块中的成员
my_package.module1.hello()
通过此语法格式导入包中的指定模块后,在使用该模块中的成员(变量、函数、类)时,需添加“包名.模块名”为前缀
别名方式:
import my_package.module1 as module1
# 别名方式可直接通过别名访问模块中的成员
module1.hello()
当然,如果使用 as 给包名.模块名起一个别名的话,就使用直接使用这个别名作为前缀使用该模块中的方法可使用这个别名作为前缀使用该模块中的方法。
from 包名 import 模块名 [as 别名]
# 导入my_package包下的module1模块
from my_package import module1
module1.hello()
使用此语法格式导入包中模块后,在使用其成员时不需要带包名前缀,但需要带模块名前缀。
from 包名.模块名 import 成员名 [as 别名]
此语法格式用于向程序中导入“包.模块”中的指定成员(变量、函数或类)。通过该方式导入的变量(函数、类),在使用时可以直接使用变量名(函数名、类名)调用:
# 导入my_package包下的module1模块中的hello成员
from my_package.module1 import hello
hello()在使用此种语法格式加载指定包的指定模块时,可以使用 * 代替成员名,表示加载该模块下的所有成员。例如:
from my_package.module1 import *
只有以“from 模块名 import *”形式导入的模块,当该模块设有 `__all__` 变量时,只能导入该变量指定的成员,未指定的成员是无法导入的。
6.2.异常
程序运行时常会碰到一些错误,例如除数为 0、年龄为负数、数组下标越界等,这些错误如果不能发现并加以处理,很可能会导致程序崩溃。和 C++、Java 这些编程语言一样,Python 也提供了处理异常的机制,可以让我们捕获并处理这些错误,让程序继续沿着一条不会出错的路径执行。
6.2.1.异常处理
捕获指定异常类型
nums = []
nums[0]
try:
print(nums[0])
except IndexError:
print("异常了")捕获多个指定异常
#通过多 except 代码块,捕获不同类型的异常。
try:
print(1/0)
except IndexError:
print("下标越界")
except ZeroDivisionError:
print("除数不能为0")
except Exception:
print("未知错误")同时,每个 except 块都可以同时处理多种异常。
try:
print(1/0)
except (IndexError,ZeroDivisionError):
print("下标越界或除数不能为0")
except Exception:
print("未知错误")捕获所有异常
#所有异常的父类都是Exception,通过Exception即可捕获所有异常信息。
try:
print(10+"")
except Exception:
print("报错了")6.2.2.异常的else
在原本的`try except`结构的基础上,Python异常处理机制还提供了一个 else 块,也就是原有 try except 语句的基础上再添加一个 else 块,即`try except else`结构。
使用 else 包裹的代码,只有当 try 块没有捕获到任何异常时,才会得到执行;反之,如果 try 块捕获到异常,即便调用对应的 except 处理完异常,else 块中的代码也不会得到执行。
try:
print(str(10)+"10")
except Exception:
print("报错了")
else:
print("没有出现异常情况")6.2.3.异常的finally
Python异常处理机制还提供了一个 finally 语句,通常用来为 try 块中的程序做扫尾清理工作。
在整个异常处理机制中,finally 语句的功能是:无论 try 块是否发生异常,最终都要进入 finally 语句,并执行其中的代码块。
try:
print(str(10)+"10")
except Exception:
print("报错了")
else:
print("执行else中的代码")
finally:
print("执行finally中的代码")基于 finally 语句的这种特性,在某些情况下,当 try 块中的程序打开了一些物理资源(文件、数据库连接等)时,由于这些资源必须手动回收,而回收工作通常就放在 finally 块中。
6.2.4.自定义异常
创建自定义异常类:
class MyException(Exception):
def __init__(self, msg: str):
self.msg = msg
def __str__(self):
return self.msg模拟自定义异常引发场景:
try:
a: int = 2
if a < 5:
raise MyException("a的值不能小于5")
except Exception as ex:
print(ex)6.3.文件
和其它编程语言一样,Python 也具有操作文件(I/O)的能力,比如打开文件、读取和追加数据、插入和删除数据、关闭文件、删除文件等。
6.3.1.open()函数
在 Python 中,如果想要操作文件,首先需要创建或者打开指定的文件,并创建一个文件对象,而这些工作可以通过内置的 open() 函数实现。
open() 函数用于创建或打开指定文件,该函数的常用语法格式如下:
file = open(file_name [, mode='r' [ , buffering=-1 [ , encoding = None ]]])
此格式中,用 [] 括起来的部分为可选参数,即可以使用也可以省略。其中,各个参数所代表的含义如下:
- file:表示要创建的文件对象。
- file_name:要创建或打开文件的文件名称,该名称要用引号(单引号或双引号都可以)括起来。需要注意的是,如果要打开的文件和当前执行的代码文件位于同一目录,则直接写文件名即可;否则,此参数需要指定打开文件所在的完整路径。
- mode:可选参数,用于指定文件的打开模式。如果不写,则默认以只读(r)模式打开文件。
- buffering:可选参数,用于指定对文件做读写操作时,是否使用缓冲区(本节后续会详细介绍)。
- encoding:手动设定打开文件时所使用的编码格式,不同平台的 ecoding 参数值也不同,以 Windows 为例,其默认为 cp936(实际上就是 GBK 编码)。
open() 函数支持的文件打开模式:
<table border="1">
<tr style="font-weight:bold;">
<td>模式</td>
<td>说明</td>
<td>注意实现</td>
<tr>
<tr>
<td>r</td>
<td>只读模式打开文件,读文件内容的指针会放在文件的开头。</td>
<td rowspan="4">操作的文件必须存在。</td>
</tr>
<tr>
<td>rb</td>
<td>以二进制格式、采用只读模式打开文件,读文件内容的指针位于文件的开头,一般用于非文本文件,如图片文件、音频文件等。</td>
</tr>
<tr>
<td>r+</td>
<td>打开文件后,既可以从头读取文件内容,也可以从开头向文件中写入新的内容,写入的新内容会覆盖文件中等长度的原有内容。</td>
</tr>
<tr>
<td>rb+</td>
<td>以二进制格式、采用读写模式打开文件,读写文件的指针会放在文件的开头,通常针对非文本文件(如音频文件)。</td>
</tr>
<tr>
<td>w</td>
<td>以只写模式打开文件,若该文件存在,打开时会清空文件中原有的内容。</td>
<td rowspan="4">若文件存在,会清空其原有内容(覆盖文件);反之,则创建新文件。</td>
</tr>
<tr>
<td>wb</td>
<td>以二进制格式、只写模式打开文件,一般用于非文本文件(如音频文件)</td>
</tr>
<tr>
<td>w+</td>
<td>打开文件后,会对原有内容进行清空,并对该文件有读写权限。</td>
</tr>
<tr>
<td>wb+</td>
<td>以二进制格式、读写模式打开文件,一般用于非文本文件</td>
</tr>
<tr>
<td>a</td>
<td>以追加模式打开一个文件,对文件只有写入权限,如果文件已经存在,文件指针将放在文件的末尾(即新写入内容会位于已有内容之后);反之,则会创建新文件。</td>
<td rowspan="4"></td>
</tr>
<tr>
<td>ab</td>
<td>以二进制格式打开文件,并采用追加模式,对文件只有写权限。如果该文件已存在,文件指针位于文件末尾(新写入文件会位于已有内容之后);反之,则创建新文件。</td>
</tr>
<tr>
<td>a+</td>
<td>以读写模式打开文件;如果文件存在,文件指针放在文件的末尾(新写入文件会位于已有内容之后);反之,则创建新文件。</td>
</tr>
<tr>
<td>ab+</td>
<td>以二进制模式打开文件,并采用追加模式,对文件具有读写权限,如果文件存在,则文件指针位于文件的末尾(新写入文件会位于已有内容之后);反之,则创建新文件。</td>
</tr>
</table>6.4.高阶函数
高阶函数:一个函数可以作为参数传给另外一个函数,或者一个函数的返回值为另外一个函数(若返回值为该函数本身,则为递归),满足其一则为高阶函数。
6.4.1.filter()函数
filter(func,lst)`函数(又称之为过滤函数)用于过滤序列,过滤掉不符合条件的元素,返回一个filter对象,可将其转换成list。
nums = [1, 2, 3, 4, 5, 6, 7]
# 1.filter 过滤函数
f = filter(lambda a: a > 5, nums)6.4.2.map()函数
map(func,lst)`函数(又称之为遍历函数)将传入的函数变量func作用到lst变量的每个元素中,并将结果组成新的列表(Python2)或者迭代器对象(Python3)。
nums = [1, 2, 3, 4, 5, 6, 7]
# 2.map 遍历函数
m = map(lambda a: a * 2, nums)6.4.3.reduce()函数
`reduce(func,lst)`函数(又称之为规约函数),其中func必须有两个参数,每次func计算的结果继续和序列的下一个元素做累计计算处理。
通过reduce()函数计算总和
nums = [1, 2, 3, 4, 5, 6, 7]
r = reduce(lambda a, b: a + b, nums)
print(r)初始状态a和b分别代表nums列表中的第一个元素和第二个元素,然后计算a+b得到结果,再将结果与列表中的第三个元素进行累计计算,以此类推。
通过reduce()函数计算列表中的奇数:
nums = [1, 2, 3, 4, 5, 6, 7]
def func_sj(a, b):
if b % 2 == 1:
a.append(b)
return a
r1 = reduce(func_sj, nums, [])
print(r1)七,标准库
7.1,python标准库
标准库详情了解网址:https://docs.python.org/zh-cn/3.10/library/index.html
7.2,字符串
7.2.1.入门示例
循环打印字符串中的字符
temp: str="12345678"
h = 0
for i in temp:
print(i)
h+=int(i)
print(h)7.2.2.string之常见字符串操作
常量 | 说明
------------------------ | -----------------------------------------
`string.ascii_letters` 获取26个大小写字母
`string.ascii_lowercase` 小写字母 `abcdefghijklmnopqrstuvwxyz`
`string.ascii_uppercase` 大写字母 `ABCDEFGHIJKLMNOPQRSTUVWXYZ`
`string.digits` 字符串 `0123456789`,十进制
`string.hexdigits` 字符串 `0123456789abcdefABCDEF`,十六进制
`string.octdigits` 字符串 `01234567`,八进制
string模块中定义的常量为:
# 1) 获取26个大小写字母
print(string.ascii_letters)
# 2) 获取26个大写字母
print(string.ascii_uppercase)
# 3) 获取26个小写字母
print(string.ascii_lowercase)
# 4) 获取0-9的数字,十进制
print(string.digits)
# 5) 获取字符串 '0123456789abcdefABCDEF’。十六进制。
print(string.hexdigits)
# 6) 获取字符串 '01234567’。八进制。
print(string.octdigits)案例:如何获取4位数的验证码
yzm = ''
st = string.ascii_letters
for i in range(4):
temp = random.randint(0, len(st) - 1)
yzm += st[temp]
print(yzm)7.2.3.str之文本序列类型
# 1) index:类似于java中的indexOf,如果没有找到则报错
try:
print("hello python".index('h',2))
except ValueError:
print("报错了")
# 2) find:与index类似
print("hello python".find('py'))
# 3) split
nums="1a2a3"
print(nums.split('a'))
# 4) strip:类似于java中的trim()方法
text = " a s "
print(text.strip(' '))
# 5) capitalize
text = 'hello python'
print(text.capitalize())
# 6) join
print(','.join('12345'))
# 7) endswith
print("123.png".endswith(".png"))
# 8) startwith: 如果字符串以指定的 prefix 开始则返回 True,否则返回 False。
print("123.png".startswith("123"))
# 9) 大写、小写及首字母大写转换处理
print("HELLO".lower())
print("hello".upper())
print("hello".capitalize())案例:检查一个字符串中某个字符出现的次数
# 方式一:
temp = '123uiaudoa8uo1u3ouaosud9lkmlm2l34ml12asf'
index = temp.find('a')
count = 0
while index != -1:
count += 1
index = temp.find('a', index+1)
print("出现次数:", count)
# 方式二:
print("出现次数:", len(temp) - len(temp.replace('a', '')))
# 方式三: count:返回子字符串 sub 在 [start, end] 范围内非重叠出现的次数
text = 'hello python'
print("出现次数:", str.count(text, 'h'))7.3.日期操作
from datetime import datetime
# 日期格式化处理
d = datetime(2023, 5, 2)
print(d)
# 获取当前日期
now = datetime.now()
print(now)
# 获取日期中的年月日时分秒
print(now.year)
print(now.month)
print(now.day)
print(now.hour)
print(now.minute)
print(now.second)
print(now.microsecond)7.4.文件操作
# 1) 获取当前工作目录
print(Path.cwd())
# 2) 获取用户目录
print(Path.home())
# 3) 获取当前文件路径
print(Path(__file__))`pathlib`操作目录:
# 获取任意字符串路径(目录)
p = Path("E:\\images\\图片")
print(p)
# 是不是目录
print(p.is_dir())
# 是不是文件
print(p.is_file())
# 是不是绝对路径
print(p.is_absolute())
# 创建目录
p.mkdir()
# 删除目录
p.rmdir()pathlib`操作文件:
p = Path("E:\\images\\1.png")
# 获取目录名称或者文件名称
print(p.name)
# 获取文件名或者目录名
print(p.stem)
# 获取文件后缀
print(str(p.resolve()).endswith(".png"))
print(p.suffix)
# 获取父级目录
print(p.parent)
print(p.parents)
for i in p.parents:
print(i)
# 获取第二级
print(p.parents[1])
# 获取最后一级
print(list(p.parents)[-1])
# 获取锚,目录前面的部分 C:\ 或者 /
print(p.anchor)
# 新建文件
p = Path("E:\\images\\readme.txt")
p.touch()获取当前目录及当前目录下的文件:
p = Path("E:\\images")
# 获取当前目录及当前目录下的文件
for i in p.iterdir():
print(i)获取当前目录下的所有目录和文件:
def each(dir):
p = Path(dir)
for i in p.iterdir():
if i.is_file():
print(i)
else:
each(i)
each("E:\\images")获取目录下的指定文件:
p = Path("E:\\images")
print(list(p.glob("*.png")))
# 递归获取所有子目录下的文件
print(list(p.rglob("*.png")))对读取和写入进行了简单的封装:
p = Path("E:\\images\\readme.txt")
# 新建文件
p.touch()
# 写入内容并设置编码格式
p.write_text("你好,python",encoding="UTF-8")
# 读取内容并设置编码格式
print(p7.read_text(encoding="UTF-8"))移动文件:
p = Path("E:\\images\\readme.txt")
# 新建文件
p.touch()
# 通过replace返回一个新的指向目标路径的Path实例
p.replace("E:\\images\\xx.txt")重命名文件:
p = Path("E:\\images\\xx.txt")
# 返回一个带有修改后stem的新路径,只修改了对象名称,并没有影响本地存储文件的名称
filename=p.with_stem("read")
# 通过replace返回一个新的指向目标路径的Path实例
p.replace(str(filename.absolute()))修改后缀名:
p = Path("E:\\images\\read.txt")
# 修改文件的后缀并返回一个修改后的新路径
suffix = p.with_suffix(".jpg")
p.replace(str(suffix.absolute()))将所有的文件复制一个备份文件:
p = Path("E:\\images\\")
# 获取当前目录下的子目录
for f in p.iterdir():
# 判断是否是文件
if f.is_file():
# 实现文件重命名
f2 = Path(f.with_stem(f.stem + "_bk"))
# 创建新的文件
f2.touch()
# 实现新文件的读流写流
f2.write_bytes(f.read_bytes())八,数据库编程
8.1,sqlite

8.2.简介
SQLite是嵌入式关系数据库管理系统。 它是独立的,无服务器的,零配置和事务性SQL数据库引擎。
SQLite可以自由地用于商业或私有的任何目的。 换句话说,“SQLite是一种开源,零配置,独立的,独 立的,旨在嵌入到应用程序中的事务关系数据库引擎”。
SQLite与其他SQL数据库不同,SQLite没有单独的服务器进程。 它直接读取和写入普通磁盘文件。 具有 多个表,索引,触发器和视图的完整SQL数据库包含在单个磁盘**文件**中。
SQLite的本质就是一个**数据库文件**
8.2.2.为什么要使用SQLite
- 不需要一个单独的服务器进程或操作的系统(无服务器的)。
- SQLite 不需要配置,这意味着不需要安装或管理。
- 一个完整的 SQLite 数据库是存储在一个单一的**跨平台**的磁盘文件。
- SQLite 是非常小的,是轻量级的,完全配置时小于 400KiB,省略可选功能配置时小于250KiB。
- SQLite 是自给自足的,这意味着不需要任何外部的依赖。
- SQLite 事务是完全兼容 ACID 的,允许从多个进程或线程安全访问。
- SQLite 支持 SQL92(SQL2)标准的大多数查询语言的功能。
- SQLite 使用 ANSI-C 编写的,并提供了简单和易于使用的 API。
- SQLite 可在 UNIX(Linux, Mac OS-X, Android, iOS)和 Windows(Win32, WinCE, WinRT)中运行。
8.2.3.快速入门
8.2.3.1.入门案例
SQLite是python自带的数据库,不需要任何配置,使用`sqlite3`模块就可以驱动它。
`sqlite3`是内置模块,所以不需要安装的,直接import导入即可:
# 导入sqlite3的内置模块
import sqlite3
# 创建数据库连接对象。如果sqlite.db文件不存在,则创建;
connect = sqlite3.connect("sqlite.db")使用 `sqlite3.connect()` 函数连接数据库,返回一个 `Connection` 对象,我们就是通过这个对象与数据库进行交互。
数据库文件的格式是 `filename.db` ,如果该数据库文件不存在,那么它会被自动创建。该数据库文件是放在电脑硬盘里的,你可以自定义路径,后续操作产生的所有数据都会保存在该文件中。
还可以在内存中创建数据库,只要输入特殊参数值 :memory: 即可,该数据库只存在于内存中,不会生成本地数据库文件。
connect = sqlite3.connect(':memory:')
对于connect对象来说,具有以下操作:
commit() : 事务提交
rollback() : 事务回滚
close() : 关闭一个数据库链接
cursor() :创建一个游标
8.2.3.2.配置SQLite数据库
双击项目目录下的`sqlite.db`,可直接在`Pycharm`中打开内置的数据库管理工具。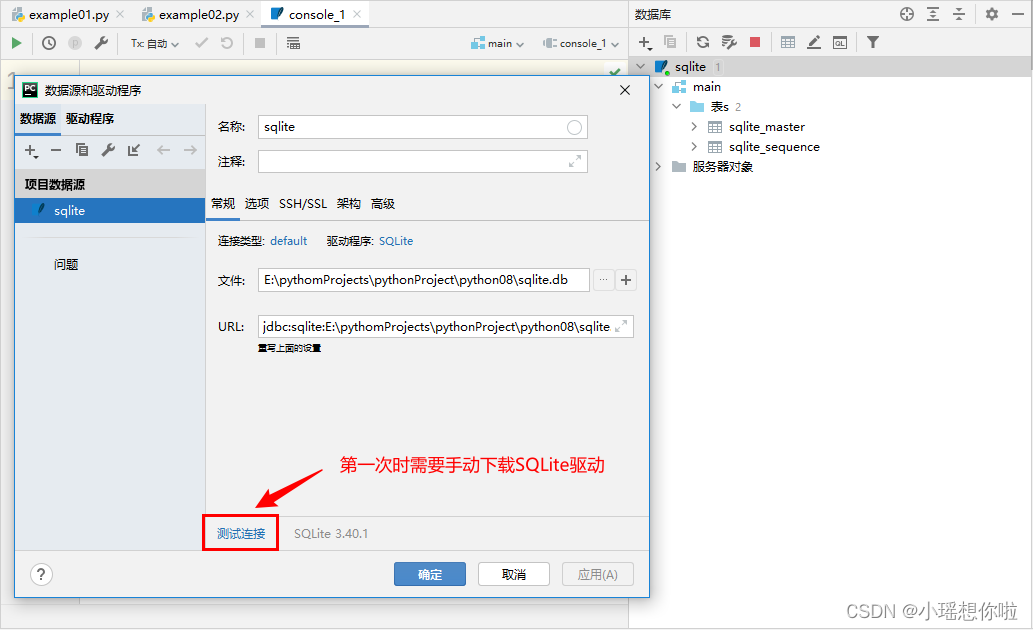
注意:第一次打开`Pycharm`内置数据库管理工具时,请先选中`sqlite`数据库右键,点击属性,手动完成SQLite驱动下载。
错误示范如下:
sql
create table t_student(
sid int primary key autoincrement,
sname varchar(50) not null,
sex varchar(1) default '男',
birthday datetime not null default current_date
);8.2.3.3.SQLite数据类型
SQLite 数据类型是一个用来指定任何对象的数据类型的属性。SQLite 中的每一列,每个变量和表达式都有相关的数据类型。可以在创建表的同时使用这些数据类型。SQLite 使用一个更普遍的**动态类型**(与Python一致)系统。在 SQLite 中,值的数据类型与值本身是相关的,而不是与它的容器相关。
NULL : 值是一个 NULL 值。
INTEGER : 值是一个带符号的整数,根据值的大小存储在 1、2、3、4、6 或 8 字节中。 |
REAL :值是一个浮点值,存储为 8 字节的 IEEE 浮点数字。
TEXT : 值是一个文本字符串,使用数据库编码(UTF-8、UTF-16BE 或 UTF-16LE)存储。
BLOB : 值是一个 blob 数据,完全根据它的输入存储。
8.2.3.4.综合案例
建立与数据库的连接后,需要创建一个游标 `cursor` 对象,该对象的 `.execute()` 方法可以执行 `sql` 命令,让我们能够进行数据操作。
# 创建游标cursor对象
cursor = connect.cursor()对于cursor对象来说,具有以下操作:
execute() :执行一条sql语句
executemany() | 执行多条sql语句
close() :游标关闭
fetchone() :从结果中取出一条记录
fetchmany() : 从结果中取出多条记录
fetchall() :从结果中取出所有记录
新增
# 方式一:
# 注意:虽然数据表中的数据列类型已经定义了,但是还是可以插入其他类型的数据值,与值有关
cursor.execute("insert into t_student values(2,3,4,5)")
# 方式二:
# 注意:请使用元组方式传递参数值
cursor.execute("insert into t_student(sname,sex,birthday) values(?,?,?)", ('张三', '女', datetime.datetime.now()))
# 方式三:批量新增
sql_text = """insert into t_student(sname,sex,birthday) values(?,?,?)"""
cursor.executemany(sql_text, [
('小明1', '男', datetime.datetime.now()),
('小明2', '男', datetime.datetime.now()),
('小明3', '男', datetime.datetime.now())
])
修改
cursor.execute("update t_student set sname=?,sex=?,birthday=? where sid=?",('王五','男',datetime.datetime.now(),2))
删除
cursor.execute("delete from t_student where sid=?",(1,))
注意:在删除时的传递单个参数需要以元组方式,也就是(1,)
查询
# 从查询结果中取出单条记录
cursor.execute("select * from t_student where sid=?",(3,))
print(cursor.fetchone())
# 从查询结果中取出多条记录
cursor.execute("select * from t_student")
print(cursor.fetchmany(3))
# 从查询结果中取出所有记录
cursor.execute("select * from t_student")
print(cursor.fetchall())
# 分页查询
# 方式一:
cursor.execute("select * from t_student limit ?,?",(0,2))
print(cursor.fetchall())
# 方式二:基于切片方式,内存分页(不推荐)
cursor.execute("select * from t_student")
print(cursor.fetchall()[0:2])最后,请关闭游标和连接对象:
# 关闭游标
cursor.close()
# 提交事务
connect.commit()
# 关闭连接
connect.close()
8.3.MySQL
使用 `pymysql` 模块,使用前需要先进行安装。`PyMySQL` 是在`Python3.x`版本中用于连接 `MySQL` 服务器的一个库,`Python2`中则使用 `mysqldb` 。
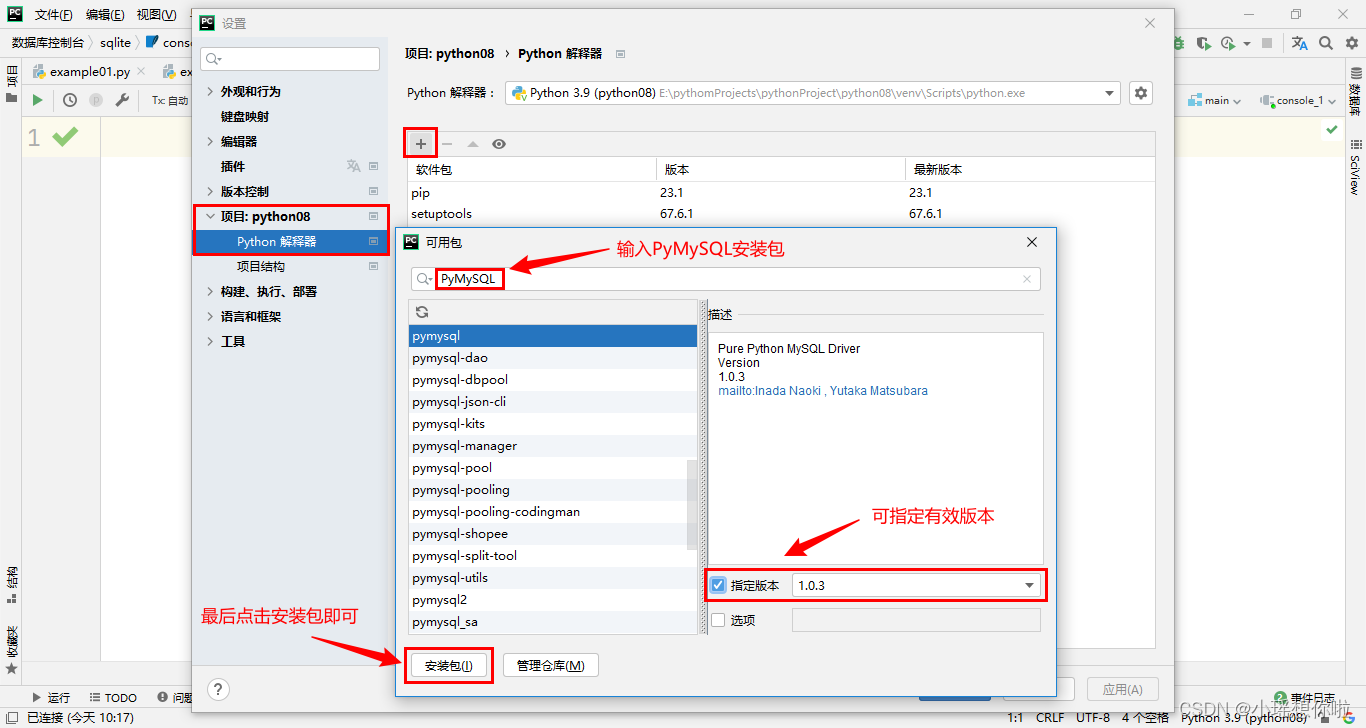
基于`PyCharm`配置安装`PyMySQL`模块,首先点击文件 -> 设置,找到项目:`python08`(**注意:`python08`只是示例项目名,请以自己创建的项目名为准**) -> Python 解析器,最后点击+按钮,输入`PyMySQL`的安装包,选择指定版本,点击`安装包(I)`按钮。
配置数据库连接:
from pymysql import connect
# 创建connection连接对象
connection = connect(user="root", password="1234",
host="localhost", port=3306,
database="vue", charset="utf8",
autocommit=True)基本使用:
# 创建游标对象
cursor = connection.cursor()
cursor.execute("select * from t_region_vue")
print(cursor.fetchone())
print(cursor.fetchall())
print(cursor.fetchmany(5))
# 关闭连接
connection.close()模糊查询:
# 创建游标对象
cursor = connection.cursor()
cursor.execute("select * from t_region_vue where region_name like %s",('%城%',))
print(cursor.fetchall())
# 关闭游标
cursor.close()
# 关闭连接
connection.close()删除操作:
sql_text = """DELETE FROM lay_employee WHERE dept_no =?"""
try:
cursor.execute(sql_text)
connection.commit()
except ProgrammingError as e:
print('sql执行失败了')
connection.rollback()
finally:
cursor.close()
connection.close()九,界面案例
界面代码
# 导入界面模块
from tkinter import *
# 导入表格模具哎
from tkinter.ttk import Treeview
# 导入dao层
from dao.bookdao import BookDao
# 导入弹框
from tkinter.simpledialog import *
# 导入提示框
from tkinter.messagebox import *
from pojo.book import Book
bd = BookDao()
# 新建界面
window = Tk()
# 调整页面的大小 widthxheight+x+y
window.geometry('500x500')
# 新建一个表格
table = Treeview(columns=('bid', 'bname', 'price'),
show="headings")
table.column('bid', width=100)
table.column('bname', width=100)
table.column('price', width=100)
table.heading('bid', text='书本编号')
table.heading('bname', text='书本名字')
table.heading('price', text='书本价格')
def load():
# 清除表格的数据
for i in table.get_children():
table.delete(i)
# 先读出数据库的数据
for i in bd.list_book():
# 将数据加入到表格中
table.insert('', END, value=i)
def add():
name = askstring('提示', '请输入书本名称')
price = askfloat('提示', '请输入书本价格')
if name is not None and price is not None:
r = bd.add_book(Book(bname=name, price=price))
messagebox.showerror(r)
def delete():
ids = []
# 制作多选删除
for i in table.selection():
# i是元素的id
# item 根据id拿对应的数据
ids.append(table.item(i)['values'][0])
if len(table.selection()) == 0:
bid = askinteger('提示', '请输入书本编号')
ids.append(bid)
for i in ids:
bd.del_book(Book(bid=i))
Button(text='加载', command=load).place(x=100, y=350)
Button(text='增加', command=add).place(x=200, y=350)
Button(text='删除', command=delete).place(x=300, y=350)
# 让表格显示
table.place(width=500, height=300)
# 让界面显示
window.mainloop()9.1.Tk图形用户界面(GUI)
Tkinter 是使用 python 进行窗口视窗设计的模块。Tkinter模块(“Tk 接口”)是Python的标准Tk GUI工具包的接口。作为 python 特定的GUI界面,是一个图像的窗口,tkinter是python自带的,可以编辑的GUI界面,用来入门,熟悉窗口视窗的使用,非常有必要。
9.1.1.Tkinter创建窗口
首先,我们导入tkinter的库。
# 导入tkinter库
from tkinter import *
# 创建一个窗口
window = Tk()
# 设置窗口标题
window.title("窗口标题栏")
# 设置窗口显示尺寸
window.geometry("500x400")
# 进入消息循环,显示窗口
top.mainloop()窗口居中显示:
screenwidth = window.winfo_screenwidth()
screenheight = window.winfo_screenheight()
x = int(screenwidth / 2 - 500 / 2)
y = int(screenheight / 2 - 400 / 2)
size = '{}x{}+{}+{}'.format(500, 400, x, y)
# 设置显示窗口大小
window.geometry(size)9.1.2.Tkinter基本控件
Tkinter的提供各种控件,如按钮,标签和文本框等,这些控件通常被称为控件或者部件。目前 Tkinter中常用的 15 个控件,如下所示:
Button : 按钮 |点击按钮时触发/执行一些事件(函数)
Canvas : 画布 | 提供绘制图,比如直线、矩形、多边形等
Checkbutton : 复选框 | 多项选择按钮,用于在程序中提供多项选择框
Entry : 文本框输入框 | 用于接收单行文本输入
Frame :框架(容器)控件 | 定义一个窗体(根窗口也是一个窗体),用于承载其他控件,即作为其他控件的容器 |
Label : 标签控件 | 用于显示单行文本或者图片
LabelFrame : 容器控件 | 一个简单的容器控件,常用于复杂的窗口布局。
Listbox :列表框控件 | 以列表的形式显示文本
Menu :菜单控件 | 菜单组件(下拉菜单和弹出菜单)Menubutton : 菜单按钮控件 | 用于显示菜单项
Message : 信息控件 | 用于显示多行不可编辑的文本,与 Label控件类似,增加了自动分行的功能
messageBox : 消息框控件 | 定义与用户交互的消息对话框
OptionMenu : 选项菜单 | 下拉菜单
PanedWindow : 窗口布局管理组件 | 为组件提供一个框架,允许用户自己划分窗口空间
Radiobutton :单选框 | 单项选择按钮,只允许从多个选项中选择一项
Scale : 进度条控件 | 定义一个线性“滑块”用来控制范围,可以设定起始值和结束值,并显示当前位置的精确值
Spinbox :高级输入框 | Entry 控件的升级版,可以通过该组件的上、下箭头选择不同的值
Scrollbar : 滚动条 | 默认垂直方向,鼠标拖动改变数值,可以和 Text、Listbox、Canvas等控件配合使用 |Text :多行文本框 | 接收或输出多行文本内容
Toplevel : 子窗口 | 在创建一个独立于主窗口之外的子窗口,位于主窗口的上一层,可作为其他控件的容器
9.1.2.1.标签
Python Tkinter 标签控件(Label)指定的窗口中显示的文本和图像。
anchor : 控制文本(或图像)在 Label 中显示的位置(方位),通过方位的英文字符串缩写(n、ne、e、se、s、sw、w、nw、center)实现定位,默认为居中(center)
bg : 用来设置背景色bd : 即 borderwidth 用来指定 Label 控件的边框宽度,单位为像素,默认为 2 个像素
bitmap :指定显示在 Label 控件上的位图,若指定了 image 参数,则参数会被忽略
compound :控制 Lable 中文本和图像的混合模式,若选项设置为 CENTER,则文本显示在图像上,如果将选项设置为 BOTTOM、LEFT、RIGHT、TOP,则图像显示在文本旁边。
cursor : 指定当鼠标在 Label 上掠过的时候,鼠标的的显示样式,参数值为 arrow、circle、cross、plus
disableforeground :指定当 Label 设置为不可用状态的时候前景色的颜色
font : 指定 Lable 中文本的 (字体,大小,样式)元组参数格式,一个 Lable 只能设置一种字体
fg : 设置 Label 的前景色
height/width : 设置 Lable 的高度/宽度,如果 Lable 显示的是文本,那么单位是文本单元,如果 Label 显示的是图像,那么单位就是像素,如果不设置,Label 会自动根据内容来计算出标签的高度
highlightbackground : 当 Label 没有获得焦点的时候高亮边框的颜色,系统的默认是标准背景色
highlightcolor :指定当 Lable 获得焦点的话时候高亮边框的颜色,系统默认为0,不带高亮边框
image : 指定 Label 显示的图片,一般是 PhotoImage、BitmapImage 的对象
justify :表示多行文本的对齐方式,参数值为 left、right、center,注意文本的位置取决于 anchor 选项
| padx/pady :padx 指定 Label 水平方向上的间距(即内容和边框间),pady 指定 Lable 水平方向上的间距(内容和边框间的距离)
relief 指定边框样式,默认值是 "flat",其他参数值有 "groove"、"raised"、"ridge"、"solid"或者"sunken"
state 该参数用来指定 Lable 的状态,默认值为"normal"(正常状态),其他可选参数值有"active"和"disabled"
takefocus 默认值为False,如果是 True,表示该标签接受输入焦点
text 用来指定 Lable 显示的文本,注意文本内可以包含换行符
underline : 给指定的字符添加下划线,默认值为 -1 表示不添加,当设置为 1 时,表示给第二个文本字符添加下划线。
wraplength : 将 Label 显示的文本分行,该参数指定了分行后每一行的长度,默认值为 0
基本案例:
# 创建一个标签
lb = Label(window, text="书本名称:", font=("宋体", 12))
# 设置标签在窗口的显示位置
lb.place(x=10, y=10)9.1.2.2.输入框
Entry 控件是 Tkinter GUI 编程中的基础控件之一,它的作用就是允许用户输入内容,从而实现 GUI 程序与用户的交互,比如当用户登录软件时,输入用户名和密码,此时就需要使用 Entry 控件。
基本属性:
exportselection :默认情况下,如果在输入框中选中文本会复制到粘贴板,如果要忽略这个功能,可以设置为 exportselection=0
selectbackground :选中文字时的背景颜色
selectforeground : 选中文字时的前景色
show : 指定文本框内容以何种样式的字符显示,比如密码可以将值设为 show="*"
textvariable : 输入框内值,也称动态字符串,使用 **StringVar()** 对象来设置,而 text 为静态字符串对象
xscrollcommand :设置输入框内容滚动条,当输入的内容大于输入框的宽度时使用户
常用方法:
delete() :根据索引值删除输入框内的值
get() :获取输入框内的值
set() : 设置输入框内的值
insert() : 在指定的位置插入字符串
index() : 返回指定的索引值
select_clear() : 取消选中状态
select_adujst() :确保输入框中选中的范围包含 index 参数所指定的字符,选中指定索引和光标所在位置之前的字符
select_from (index) : 设置一个新的选中范围,通过索引值 index 来设置
select_present() :返回输入框是否有处于选中状态的文本,如果有则返回 true,否则返回 false。
select_to() :选中指定索引与光标之间的所有值
select_range() :选中指定索引与光标之间的所有值,参数值为 start,end,要求 start 必须小于 end。
基本案例:
# 创建一个文本框
tx = Entry(window, width=20)
tx.place(x=100, y=10)9.1.2.3.按钮
Button 控件是 Tkinter 中常用的窗口部件之一,同时也是实现程序与用户交互的主要控件。通过用户点击按钮的行为来执行回调函数,是 Button 控件的主要功用。首先自定义一个函数或者方法,然后将函数与按钮关联起来,最后,当用户按下这个按钮时,Tkinter 就会自动调用相关函数。
anchor :控制文本所在的位置,默认为中心位置(CENTER)
activebackground : 当鼠标放在按钮上时候,按妞的背景颜色
activeforeground : 当鼠标放在按钮上时候,按钮的前景色
bd : 按钮边框的大小,默认为 2 个像素
bg :按钮的背景色
command : 用来执行按钮关联的回调函数。当按钮被点击时,执行该函数
fg :按钮的前景色
font :按钮文本的字体样样式
height :按钮的高度
highlightcolor :按钮控件高亮处要显示的颜色
image :按钮上要显示的图片
justify : 按钮显示多行文本时,用来指定文本的对齐方式,参数值有 LEFT/RIGHT/CENTER
padx/pady : padx 指定 x 轴(水平方向)的间距大小,pady 则表示 y轴(垂直方向)的间距大小
ipadx/ipady : ipadx 指标签文字与标签容器之间的横向距离;ipady 则表示标签文字与标签容器之间的纵向距离
state : 设置按钮的可用状态,可选参数有NORMAL/ACTIVE/DISABLED,默认为 NORMAL
text :按钮控件要显示的文本
基本案例:
# 导入tkinter模块
from tkinter import *
# 导入tkinter模型中的messagebox
from tkinter import messagebox
# 给按钮绑定点击事件
def do_click():
# 触发按钮点击事件之后,获取文本框输入的值
text = tx.get()
print(f"被点击了,text={text}")
messagebox.showinfo("提示", text)
# 创建一个按钮
btn_search = Button(window, text="点我试试", width=6, command=do_click)
btn_search.place(x=260, y=5)更多参考:http://c.biancheng.net/tkinter/what-is-gui.html
9.1.3.Treeview组件
[`ttk.Treeview`]:http://study.yali.edu.cn/pythonhelp/library/tkinter.ttk.html#treeview) 控件可将多项内容分层级显示。每个数据项抖带有一个文本标签、一张图片(可选)和一个数据列表(可选)。这些数据值将在树标签后面分列显示。
基本属性:
columns : 列标识的列表,定义了列的数量和名称。
displaycolumns : 列标识的列表(索引可为符号或整数),指定要显示的数据列及显示顺序,或为字符串 “#all”。
height :指定可见的行数。注意:所需宽度由各列宽度之和决定。
padding :指定控件内部的留白。为不超过四个元素的长度列表。
selectmode : 控制内部类如何进行选中项的管理。可为 extended、browse 或 none。若设为 extended(默认),则可选中多个项。若为 browse ,则每次只能选中一项。若为 none,则无法修改选中项。请注意,代码和 tag 绑定可自由进行选中操作,不受本属性的限制。
show : 由0个或下列值组成的列表,指定要显示树的哪些元素。tree :在 #0 列显示树的文本标签。headings :显示标题行。默认为“tree headings”,显示所有元素。<br />**注意** :第 #0 列一定是指 tree 列,即便未设置 show="tree" 也一样。
基本案例:
# 导入Treeview组件
from tkinter.ttk import Treeview
# 创建TreeView组件
# show="headings" 用于隐藏首列
tv = Treeview(window,
columns=("id", "bookname", "price", "booktype"),
show="headings")
# 设置Treeview显示位置
tv.place(x=10, y=40)常用方法:
bbox(item, column=None) : 返回指定item的框选范围,或者单元格的框选范围
column( cid, option=None, **kw) :设置或者查询某一列的属性
delete(*items) :删除指定行或者节点(含子节点)
vdetach(*items) : 与delete类似,不过不是真正删除,而是隐藏了相关内容。可以用move方法重新显示v
exists(item) :判断指定的item是否存在
focus(item=None):获得选定item的iid,或者选中指定item。
get_children(item=None) : 返回指定item的子节点
heading(column, option=None, **kw) : 设置或者查询表头行的配置参数
identify(component, x, y) :返回在坐标(x,y)处的部件信息。部件包括:region(heading,cell等), item, column, row, 和 element。
identify_element(x, y) :返回在(x,y)处的元素。
identify_region(x, y):返回坐标(x,y)处的Tree view组成部分
identify_row(y) :给定y坐标,返回指定item索引
index(item) :返回数字化的item索引,从0开始
set_children(item, *newchildren) :设置item的新子节点为newchildren,现有的子节点会被移除。一般用于树形结构中。
insert(parent, index, iid=None, **kw) : 插入一个新的item
item(item, option=None, **kw) :返回item节点的相关信息
move(item, parent, index) :move()方法有两种作用: (1)将detach的item重新显示(reattach) (2)移动item指定的节点到parent的子节点中,位置由index指定
next(item) : 返回item的下一个节点
parent(item) :返回item的父节点
prev(item) :返回item的前一个节点
see(item) : 保证item指定的节点在Treeview控件中可见
selection(items=None) :返回当前选定的节点的iid
selection_set(*items) : 选中items指定的节点
selection_remove(*items) :从当前选择中移除items指定的节点
selection_add(*items):将items指定的节点添加到当前的选择中
selection_toggle(*items) :选中的节点变为不选中,未选中的节点变为选中
set(item, column=None, value=None): 设置或者获得节点信息
tag_bind( tagname, sequence=None, callback=None) : 给tagname指定的tag绑定事件以及回调函数
tag_configure( tagname, option=None, **kw) : 配置或者获得tag的有关信息
tag_has(tagname, item=None) : 判断tag是否存在或者是tag与那些节点关联
column列选项:
column( cid, option=None, **kw)`查询或者修改指定列的配置。cid可以是整数,也可以列的别名。如果不输入option,则返回目前的配置选项字典。Treeview列的选项有:
anchor :对齐模式。取值有n,e,s,w,ne,nw,se,sw和center。
id :列的名称或者标识
minwidth : 列的最小宽度,调整列宽的时候,不会小于这个数值。默认值是20
stretch : 是否随着窗口大小的调整而拉伸Treeview。默认值是True
width : 定义列宽。默认值是200
基础案例:
# 设置列的宽度及对齐方式
# tv.column("#0",width=10)
tv.column("id", width=90, anchor=CENTER)
tv.column("bookname", width=200, anchor=CENTER)
tv.column("price", width=96, anchor=CENTER)
tv.column("booktype", width=90, anchor=CENTER)heading表头行:
heading(column, option=None, **kw)`设置或者查询表头行的配置参数。如果是表格形式的,column是列的位置(就是第几列,从0计数)或者列的别名。如果是树形结构的(比如文件目录),column的值为'#0'。
如果没有option参数,返回的是当前的配置数据。
heading的选项有:
anchor : 对齐模式。取值有n,e,s,w,ne,nw,se,sw和center。
command : 与指定列相关的回调函数
image : 在表头显示图片
text : 在表头显示文本
state : 当前列的状态
基本案例:
# 设置列的表头
# tv.heading("#0",text="")
tv.heading("id", text="书本编号")
tv.heading("bookname", text="书本名称")
tv.heading("price", text="书本价格")
tv.heading("booktype", text="书本类型")insert新增数据行:
insert(parent, index, iid=None, **kw)`插入一个新的item。
(1)parent
对于表格类型的Treeview,parent一般为空。对于树形类型的Treeview,parent为父节点。
(2)index
指明在何处插入新的item。可以是'end',也可以是数字。比如,如果要让新插入的item成为第一个子节点或者在第一行,index就设为0。如果是第二个子节点或者第二行,就是设置index=1。如果在最末端插入item,就设置index='end'
(3)iid
如果没有赋值,就使用系统自动生成的id。如果输入了id,必须保证与现有的id不重复。否则系统会自动生成id。
(4)**kw
设置插入item的属性。支持的属性有:image :显示图像
open :针对树形结构,确认插入的item是打开还是折叠状态。True打开,False为折叠。
tags :为新插入的item设置tag标签
text:显示文字
values : 在表格结构中,要显示的数值。这些数值是按照逻辑结构赋值的,也就是按照columns设定的列次序来赋值。如果输入的个数少于columns指定列数,则插入空白字符串
基本案例:
# 数据绑定
tv.insert('', END, values=(1, "山海经", 100, '玄幻'))
tv.insert('', END, values=(2, "金刚经", 110, '经书'))
tv.insert('', END, values=(3, "三字经", 120, '内功心法'))
tv.insert('', END, values=(4, "道德经", 100, '内功心法'))9.2.DBHelper
DBHelper只是对基本操作进行了简单封装处理:
from pymysql import *
from pymysql.cursors import Cursor
class DBHelper:
conn: Connection = None
curs: Cursor = None
def __init__(self):
self.conn = Connection(user="root", password="1234",
port=3306, host="localhost",
database="vue", charset="utf8",
autocommit=True)
self.curs = self.conn.cursor()
def close(self):
self.curs.close()
self.conn.close()
def execute(self, sql: str, params: tuple):
try:
self.curs.execute(sql, params)
except Exception as ex:
print(f"操作失败,提示:{ex}")
finally:
self.close()
def find(self, sql: str, params: tuple):
try:
self.curs.execute(sql, params)
return self.curs.fetchall()
except Exception as ex:
print(f"查询失败,提示:{ex}")
finally:
self.close()
return None9.3.dao层定义
from utils.DBHelper import *
class BookDao:
db = None
def __init__(self):
self.db = DBHelper()
def add(self,book: tuple=None):
sql = """insert into t_book_vue(bookname,price,booktype) values(%s,%s,%s)"""
self.db.execute(sql,book)
def query(self,book: tuple=None):
sql = "select * from t_book_vue where bookname like %s"
return self.db.find(sql,book)
def delete(self,bid: int=0):
sql = """delete from t_book_vue where id=%s"""
self.db.execute(sql,(bid,))
if __name__ == '__main__':
bd = BookDao()
# bd.add(("222",123,"22"))
# print(bd.query(('%%',)))
# bd.delete(56)9.4.综合案例
查询功能实现:
def do_click():
# 触发按钮点击事件之后,获取文本框输入的值
bookname = tx.get()
# print(f"被点击了,bookname={bookname}")
# messagebox.showinfo("提示", bookname)
book = BookDao()
res = book.query(("%"+bookname+"%",))
# 清空表格数据
for i in tv.get_children():
tv.delete(i)
# 绑定动态数据
for b in res:
tv.insert('',END,values=b)删除功能实现:
def do_delete():
# 如何获取当前Treeview选中行索引
index = tv.selection()
# 判断是否选中行
assert len(index) > 0
print(index)
# 根据行索引获取数据行
print(tv.item(index))
# 删除选中行
# tv.delete(index)
book = BookDao()
book.delete(tv.item(index)["values"][0])
# 调用刷新方法
do_click()新增功能实现:
from tkinter.simpledialog import *
def do_add():
bookname = askstring('提示', '请输入书本名称')
price = askfloat('提示', '请输入书本价格')
booktype = askstring('提示', '请输入书本类型')
print(f"bookname={bookname},price={price},booktype={booktype}")
# tv.insert('', END, values=(1,bookname, price, booktype))
book = BookDao()
book.add((bookname,price,booktype))
# 调用刷新方法
do_click()十,爬虫基本使用
10.1,网络爬虫
10.1.1.引言
我们平时都说Python爬虫,其实这里可能有个误解,爬虫并不是Python独有的,可以做爬虫的语言有很多例如:PHP、JAVA、C#、C++、Python。
**为什么Python的爬虫技术会异军突起呢?**
Python火并不是因为爬虫技术,而是AI人工智能、数据分析(**GoogleAlphaGo**)等等功能;这些Java其实也能做,而选择Python做爬虫是因为Python相对来说比较简单,而且功能比较齐全。
10.1.2.什么是网络爬虫
网络爬虫(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。通俗来讲,网络爬虫就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做。
10.1.3.应用场景
**数据展示**:将爬取的数据展示到网页或者APP上,比如:百度新闻、今日头条
**数据分析**:从数据中寻找一些规律,比如:慢慢买(价格对比)、TIOBE排行等
**自动化测试**:比如想要测试一个前端页面的兼容性、前端页面UI是否有bug,只需要模拟执行表单提交、键盘输入等页面操作
10.1.4.网络爬虫是否合法
爬虫作为一种计算机技术就决定了它的中立性,因此爬虫本身在法律上并不被禁止,但是利用爬虫技术获取数据这一行为是具有违法甚至是犯罪的风险的。所谓具体问题具体分析,正如水果刀本身在法律上并不被禁止使用,但是用来捅人,就不被法律所容忍了。
10.1.4.1.爬虫技术与反爬虫技术
爬虫目前能造成的技术上影响在于野蛮爬取,即`多线程爬取`,从而导致`网站瘫痪`或不能访问,这也是大多数网络攻击所使用的方法之一。
由于爬虫会批量访问网站,因此许多网站会采取反爬措施。例如:1.IP频率、流量限制;2.请求时间窗口过滤统计;3.识别爬虫等。
但这些手段都无法阻止爬虫开发人员优化代码、使用多IP池等方式规避反爬措施,实现大批量的数据抓取。由于网络爬虫会根据特定的条件访问页面,因而爬虫的使用将占用被访问网站的网络带宽并增加网络服务器的处理开销,甚至无法正常提供服务。
10.1.4.2.Robots协议
robots(也称为爬虫协议、机器人协议等)称是“**网络爬虫排除标准**”是网站跟爬虫间的一种协议(**国际互联网界通行的道德规范**),用简单直接的txt格式文本方式告诉对应的爬虫被允许的权限,也就是说robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。
参考地址:https://www.zhihu.com/robots.txt
以Allow开头的URL地址:允许某爬虫引擎访问
以Disallow开头的URL地址:不允许某爬虫引擎访问
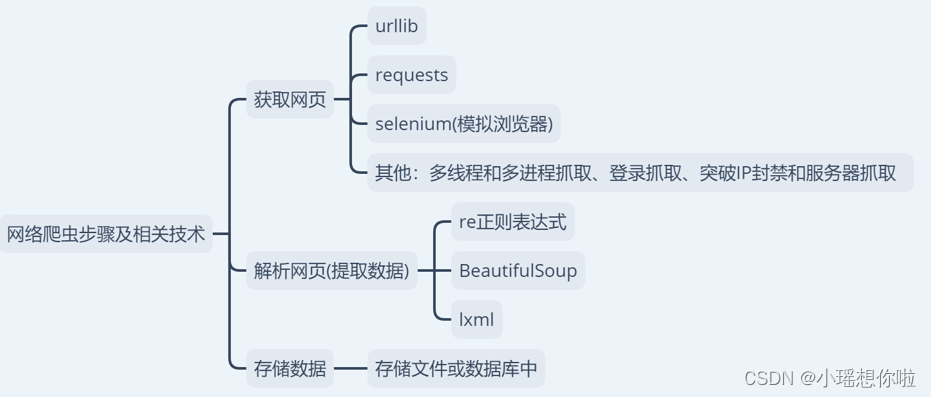
10.1.5.网络爬虫步骤及相关技术
10.2,抓包
浏览器抓包(**仅能抓取浏览器的数据包**)
抓包工具fiddler(**基本用于抓取HTTP**)
10.3.HTTP与HTTPS
HTTP 与 HTTPS 有哪些区别?
(1)HTTP 是超文本传输协议,信息是明文传输,存在安全风险的问题。HTTPS 则解决 HTTP 不安全的缺陷,在 TCP 和 HTTP 网络层之间加入了 SSL/TLS 安全协议,使得报文能够加密传输。
(2)HTTP 连接建立相对简单, TCP 三次握手之后便可进行 HTTP 的报文传输。而 HTTPS 在 TCP
三次握手之后,还需进行 SSL/TLS 的握手过程,才可进入加密报文传输。
(3) HTTP 的端口号是 80,HTTPS 的端口号是 443。
(4)HTTPS 协议需要向 CA(证书权威机构)申请数字证书,来保证服务器的身份是可信的。
HTTPS 解决了 HTTP 的哪些问题?
**窃听风险**,比如通信链路上可以获取通信内容,用户号容易没。
**篡改风险**,比如强制植入垃圾广告,视觉污染,用户眼容易瞎。
**冒充风险**,比如冒充淘宝网站,用户钱容易没。
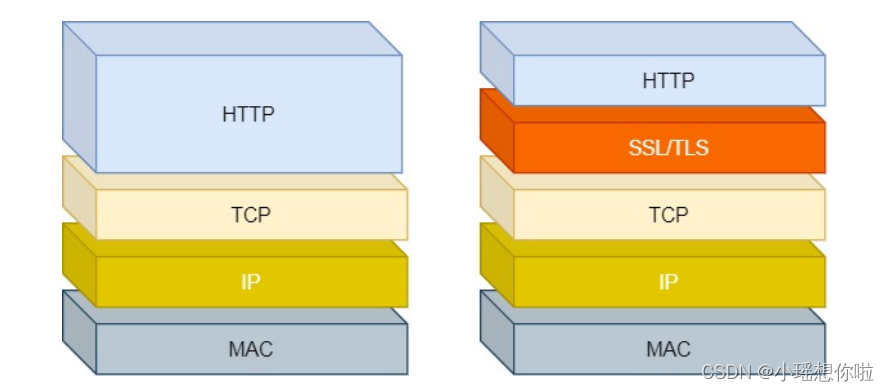
HTTPS 在 HTTP 与 TCP 层之间加入了 SSL/TLS 协议,可以很好的解决了上述的风险:
**信息加密**:交互信息无法被窃取,但你的号会因为「自身忘记」账号而没。
**校验机制**:无法篡改通信内容,篡改了就不能正常显示,但百度「竞价排名」依然可以搜索垃圾
广告。
**身份证书**:证明淘宝是真的淘宝网,但你的钱还是会因为「剁手」而没。
HTTPS 是如何解决上面的三个风险的?
**混合加密**的方式实现信息的**机密性**,解决了窃听的风险。
**摘要算法**的方式来实现**完整性**,它能够为数据生成独一无二的「指纹」,指纹用于校验数据的完
整性,解决了篡改的风险。
将服务器公钥放入到**数字证书**中,解决了冒充的风险。
10.4,快速入门;
10. 4.1.安装requests
pip 是 Python 包管理工具,该工具提供了对Python 包的查找、下载、安装和卸载的功能,现在大家用到的所有包不是自带的就是通过pip安装的。Python 2.7.9 + 或 Python 3.4+ 以上版本都自带 pip 工具。
显示版本和路径:
pip --version
安装指定版本的requests:
pip install requests # 最新版本
pip install requests==2.11.0 # 指定版本
pip install requests>=2.11.0 # 最小版本
由于所有请求都需要经过fiddler这个抓包软件进出。所以如果requests与fiddler一起使用,请不要使用requests最新版本,不然直接会卡死,降版本使用即可。**
也可以直接通过PyCharm来安装requests模块,点击`File -> Settings -> 项目: python10`,选择Python解释器,点击 `+` 号,输入选择requests模块并指定安装版本号(例如:2.11.0),最后点击 `安装包(I)` 按钮即可。
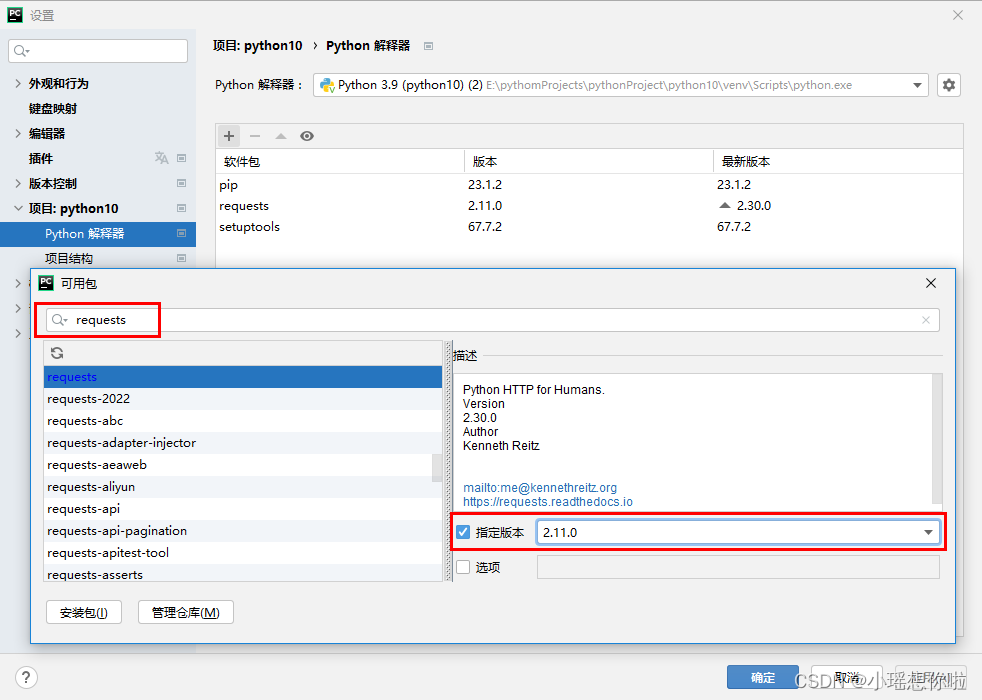
10.4.2.案例演示
创建纯python项目,新建demo.py并导入requests模块
# 导入模块
import requests
# 通过requests模块模拟发送get请求,并得到响应对象response
resp = requests.get(url)
response响应对象属性介绍:
encoding:文本编码。例如:resp.encoding="utf-8"
status_code:响应状态码。<br />200 -- 请求成功<br />4XX -- 客户端错误<br />5XX -- 服务端响应错误
text :响应体。
content : 字节方式响应体,会自动解码gzip和deflate编码的响应数据
url : 响应的URL地址。
案例一:快速入门,爬取百度官网并保存到本地
请结合fiddler抓包工具进行以下代码测试。
resp = requests.get("http://www.baidu.com/")定制请求头headers,请结合[知乎网](https://www.zhihu.com/robots.txt)的Robots协议进行设置。**伪装User-Agent
resp = requests.get("http://www.zhihu.com/signin?next=%2F",
headers={
"User-agent": "bingbot"
})定制请求头headers,模拟使用浏览器的User-Agent值。
resp = requests.get("http://www.baidu.com/",
headers={
"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
})保存文件的方式可使用**pathlib**和**open**等两种方式。
案例二:传递URL参数
爬取必应搜索“中国”之后的网页,保存为“中国.html”
resp = requests.get("https://cn.bing.com/search",
headers={
"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
},
params={
"q":"中国"
})requests缺点:不能爬取ajax动态加载的数据
十一,正则解析网页
概念:
正则表达式是由普通字符(如英文字母)以及特殊字符(也称为元字符)组成的文字模式。该模式对文本查找时需要匹配的一个或多个字符串描述,给出一个匹配模板(简单理解:通过指定的规则去匹配一类字符串)
作用:
操作文本的非常常用的技术,在很多的编程语言、文本编辑器、开发环境中都支持,可以看作是处理文本的专门的语言
基本语法:
普通字符:
字母、数字、汉字、下划线等,以及没有特殊含义的标点符号等。正则中使用普通字符时,就是匹配和它一样的字符,如:abc,匹配文本中的abc
转义字符:
\n:换行
\t:制表符
\\:\本身
\^:^
\$:$
\{,\}:{,}
\?:?
\[,\]:[, ]
\b:退格,即将插入点向左以一个字符(不会删除字符)
标准字符集:
作用:
能够与多种字符匹配的表达式
常见表达式:
\d:0-9中任意一个数字
\w:A-Z,a-z,0-9,_ 中的任意一个
\s:空格,制表符,换行符等空白字符中的任意一个
.:英文小点,匹配任意字符,但换行符除外
[\s\S]:匹配任意字符,包括换行符
注意:以上的表达式区分大小写的,大写则取相反的意思
自定义集合:
作用:
使用 [ ] 来进行定义
匹配中括号中任意字符
示例:
[abc123@]:匹配a,b,c,1,2,3,@中的任意字符,(中括号中的字符是“或”的关系)
[^abc]:匹配a,b,c之外的任意字符,(^在中括号中有取相反的意思)
[a-z]:匹配从a到z的所有字符
[^a-z0-9]:匹配从a-z从0-9之外的其他字符
注意:
如果在中括号中包含了正则表达式的特殊符号(如:$ . ^ - 等),除了^, - 之外,其他的特殊符号将失去特殊意义,变为普通的字符
对于标准字符集,除了. (英文小点)之外,若放在中括号中,则自定义字符集会包含该集合。“.”(英文小点)会蜕变为普通字符
示例: [\d.$] 表示:包含数字,英文小点,$
量词:
作用:表示匹配次数
作用:表示匹配次数
{n}:匹配n次
{m,n}:最少匹配m次,最多匹配n次
{m,}:至少匹配m次,多了不限,注意:没有{, n}这种表示
?:匹配0次或1次,相当与{0,1}
+:至少要匹配1次,相当于{1, }
*:匹配0次或任意多次
示例: f\d{2}q 在f和q之间有两个数字,则匹配
匹配模式:
贪婪模式:
默认方式
匹配字符越多越好
示例:\d{3,6} 匹配数字最少3次,最多6次,但4,5次都会匹配
非贪婪模式:
匹配越少越好
示例:\d{3,6}? 只要匹配3个数字,就会重新开始匹配,实际上已退化为 \d{3}
字符边界(零宽)
特点: 自身不是字符,不占宽度(所以叫零宽),表示位置
符号:
^:字符串开头
$:字符串结尾
\b:匹配单词边界(前面的字符和后面的字符不全是\w)
匹配模式:
忽略大小写:
匹配时忽略大小写: (?i)[a-z]
单行模式:
将整个文本看成是一行,只有一个开头,一个结束
英文小点,可以匹配包含换行符在内的任意字符
多行模式:
每一行作为一个字符串,都有一个开头,一个结束 (?m)
该模式下,若仅匹配字符串开头或结束位置,则可以使用A或Z
\Aa:匹配文本最开始的a
a\Z:匹配文本最后的a
高级语法:
选择: |
两边表达式为“或”的关系
示例: abc|bcd
捕获分组:()
规则:
匹配时,小括号内的表达式作为整体对待
括号中表达式匹配的内容可单独获取
具有多个分组时,每对小括号会分配一个编号,从左至右,编号从1开始
示例:(abc) :
匹配字符串“abc”
此处要和 [abc] 区分清楚,[abc]是自定义集合,匹配的是a | b | c
注意:捕获分组的捕获的内容会被缓存在内存中,会占用一定的内存,如果不需要捕获,只是用 () 来组织表达式以使表达式结构更为清晰,可使用非捕获分组
反向引用:
可对 ( ) 匹配的内容进行引用 (使用编号引用,编号规则见上述分组部分)
示例: (ab)\1 匹配重复出现的“abab”,但“ab”不会匹配
非捕获分组:(?:表达式)
用于组织表达式使结构清晰,但不会将匹配的内容存入缓存,自然也就不能来用反向引用了
示例:(?:[1-9]{2}) 匹配从0到9的数字2次,这里的 () 只用于结构清楚,但不会捕获匹配的内容
零宽断言/预匹配/环视:
这几种叫法不同,意思相同
规则:
(?=expression):断言自身出现的位置后面能匹配表达式
(?!expression):断言自身出现的位置后面不能匹配表达式
(?<=expression):断言自身出现的位置前面能匹配表达式
(?<!expression):断言自身出现的位置的前面不能匹配表达式
常用正则表达式
中文:[\u4e00-\u9fa5]
空白行:\n\s*\r
html标记
首尾空白字符
url
国内电话号码
qq号
身份证
IP地址
案列:
案例一:电子邮箱验证
match = "\d{4,10}@qq\.com"
email = "529503476@qq.com"
m = re.match(match, email)
if m:
print("有效的QQ邮箱")
else:
print("无效的QQ邮箱")findall查找字符串中所有匹配的子串
st = "aa123asd123asd134ada123"
# 注意:这里需要使用()进行分组处理
all = re.findall('(\d+)', st)
print(all)search在字符串中查询第一个匹配的位置
st = "aa123asd123asd134ada123"
search = re.search('(\d+)', st)
print(search)
print("返回被re匹配的字符串:",search.group())
print("返回匹配的开始位置:",search.start())
print("返回匹配的结束位置:",search.end())
print("返回一个元组包含匹配(开始,结束)的位置:",search.span())使用sub实现正则替换
st = "aa123asd123asd134ada123"
sub = re.sub('(\d+)', 'HA', st, count=2)
print(sub)热词搜索
import requests,re
headers = {
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
# verify = false 表示不进行安全校验
resp = requests.get('https://www.bilibili.com/read/cv3352403', headers=headers, verify=False)
resp.encoding = "UTF-8"
findall = re.findall(r'<img data-src="(.+?)"', resp.text)
print(findall)词频统计jieba库
import jieba
st = "我在长沙洗脚按摩大保健"
words = jieba.cut(st)
print(list(words))加载自定义的词库:
import jieba
# 加载自定义的词库
jieba.load_userdict("cy.txt")
st = "我爱苏吴涛"
words = jieba.cut(st)
print(list(words))匹配模式(精准和全模式)
import jieba
st = "我在岳麓山洗澡,做头发"
# 精准模式
words = jieba.cut(st)
print(list(words))
# 全模式
words = jieba.cut(st,cut_all=True)
print(list(words))热搜词频统计
import requests,re,jieba
headers = {
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
# verify = false 表示不进行安全校验
resp = requests.get('https://tophub.today/n/KqndgxeLl9', headers=headers, verify=False)
resp.encoding = "UTF-8"
# # print(resp.text)
findall = re.findall(r'<a href="/l\?e=.+?" target="_blank" rel="nofollow" itemid="\d+">(.+?)</a>', resp.text)
print(findall)
# 使用逗号将匹配到的结果拼接起来,然后再使用全模式匹配
cs = jieba.lcut(",".join(findall), cut_all=True)
# 两个字才能算是词
cs = list(filter(lambda a: len(a)>1,cs))
print(cs)
# 词频统计
import collections
cn = collections.Counter(cs)
print(cn)十二,selenium爬取
12. 1.selenium
12.1.1.前言
使用python的requests模块还是存在很大的局限性,例如:只发一次请求;针对ajax动态加载的网页则无法获取数据等等问题。特此,本章节将通过selenium模拟浏览器来完成更高级的爬虫抓取任务。
12.1.2.什么是selenium
Selenium是一个用于自动化Web应用程序测试的开源工具集。它提供了一组API和工具,可以与多种编程语言一起使用,如Java、Python、C#等,用于模拟用户在浏览器中的行为,如点击、填写表单、提交数据等。Selenium可以运行在各种浏览器上,包括Chrome、Firefox、Safari等,它还可以与多个测试框架和开发工具集成,如JUnit、TestNG、Maven等。
12.1.3.组成
Selenium的核心组件是WebDriver,它可以直接与浏览器进行交互,并模拟用户操作。WebDriver提供了一系列的方法和命令,可以控制浏览器的打开、页面导航、元素查找、交互操作(JavaScript)等。使用Selenium,开发人员可以编写自动化测试脚本,以验证Web应用程序的功能和性能,并自动运行这些脚本进行回归测试。
除了WebDriver,Selenium还包含其他辅助工具,如Selenium IDE(集成开发环境)和Selenium Grid(分布式测试工具),它们提供了更多的功能和扩展性,以满足不同的测试需求。总之,Selenium是一个功能强大的自动化测试工具,可用于模拟用户在浏览器中的行为,以及验证和测试Web应用程序的功能和性能。
12.1.4.特点
- 开源、免费
- 多浏览器支持:FireFox、Chrome、IE、Opera、Edge;
- 多平台支持:Linux、Windows、MAC;
- 多语言支持:Java、Python、Ruby、C#、JavaScript、C++;
- 对Web页面有良好的支持;
- 简单(API 简单)、灵活(用开发语言驱动);
- 支持分布式测试用例执行。
12. 2.通过selenium模拟浏览器的抓取
12.2.1.下载与导入
点击 `File -> Settings -> 选择项目:python12中的Python解析器`,再点击 `+` 按钮,输入selenium,选择指定的版本,最后点击`安装包(I)`即可。
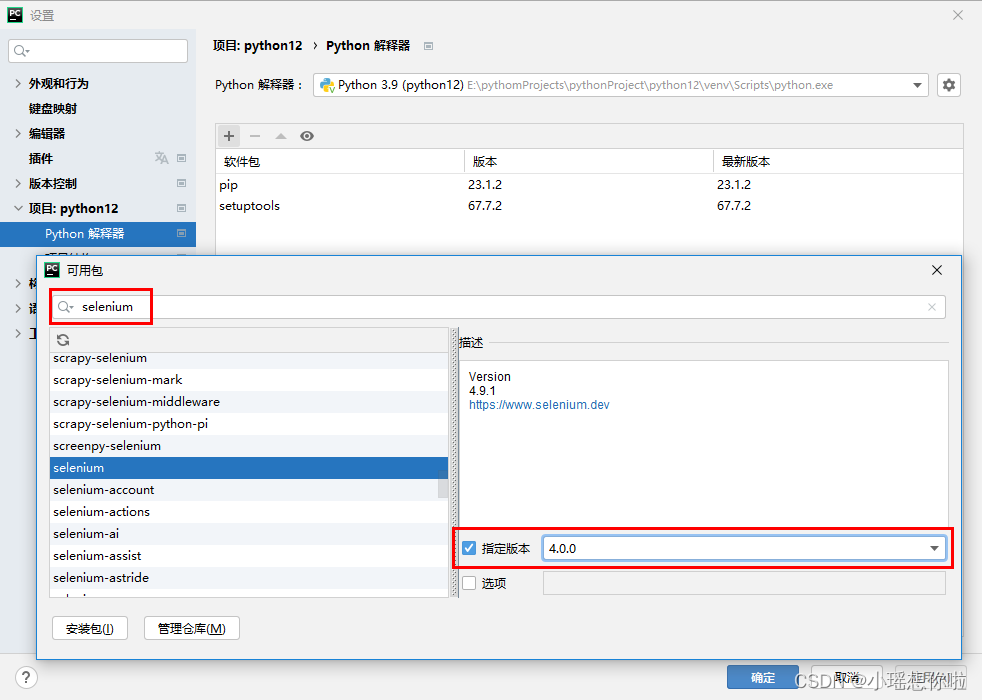
注意:这里下载的selenium 4.0.0,不要下载高版本,怕出问题,与4.0.0一致即可。**
新建python文件,导入selenium中的webdriver:
from selenium from webdriver12.2.2.下载webDriver
下载对应浏览器的webDriver,例如:Chrome浏览器对应的[webDriver](http://chromedriver.storage.googleapis.com/index.html)
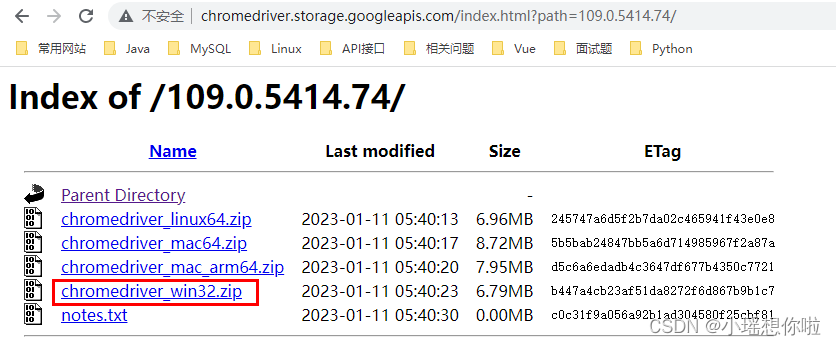
注意:一定要下载浏览器对应版本的webDriver,如果没有完全对应的,可以下载接近版本的webDriver。
将下载chromedriver_win32.zip解压,并将其内的chromedriver.exe复制到Python安装目录下的Scripts目录中。

12.2.3.基本使用
from selenium import webdriver
# 使用Chrome谷歌的webDriver
driver = webdriver.Chrome()
# 模拟get请求抓取jd网站
driver.get("https://www.jd.com")Firefox:
driver = webdriver.Firefox()
Safari:
driver = webdriver.Safari()
Safari:
driver = webdriver.Safari()
Edge:
driver = webdriver.Edge()
12.2.4.元素查找
find_element_by_id : 通过ID查找元素
find_element_by_xpath :通过XPath查找元素
find_element_by_tag_name : 通过标签名查找元素
find_element_by_class_name :通过类名查找元素
find_element_by_css_selector :通过CSS选择器查找元素注意:多个元素的查找只需要将element改为elements即可。
# 通过ID查找元素
element = driver.find_element_by_id("J_searchbg")
print(element.text)
# 通过标签名查找
element = driver.find_element_by_tag_name("input")
print(element.get_attribute("aria-label"))
# 通过css样式查找
elements = driver.find_element_by_class_name("button")
print(elements.get_attribute("aria-label"))注意:`element.text`用于获取元素的文本内容;`element.get_attribute()`用于获取元素的属性值。
12.2.5.模拟用户操作
clear :清楚元素内容
send_keys("值"):模拟按键输入
click : 单击元素,触发元素的点击事情
submit : 提交表单
案例演示:
如何模拟JD商城搜索指定商品信息
import time
from selenium import webdriver
driver = webdriver.Chrome();
driver.get("https://search.jd.com/Search?keyword=手机")
# 获取输入框
val = driver.find_element_by_id("key")
# 清空输入框的条件
val.clear()
# 重新设置查询条件
val.send_keys("电脑")
# 获取查询按钮并触发点击事件
btn = val.parent.find_element_by_css_selector("button.button.cw-icon")
btn.click()
# 睡眠3秒
time.sleep(3)
# 滚动到页面底部
# driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 睡眠3秒
# time.sleep(3)
# 循环获取网页中电脑的名称
names = driver.find_elements_by_css_selector("#J_goodsList > ul > li > div > div.p-name.p-name-type-2 > a > em")
for name in names:
print("【电脑】--",name.text)12.2.6.优化操作
无头模式:不打开浏览器
import time
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--headless")
driver = webdriver.Chrome(options=options)
driver.get("https://search.jd.com/Search?keyword=手机")案例演示:
模拟点击frame窗口中的按钮
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://search.jd.com/Search?keyword=手机")
# 点击用户图标
user = driver.find_element_by_class_name("tab-ico")
user.click()
# 睡眠2秒
time.sleep(2)
# 先要获取弹开的子窗口frame
frame = driver.find_element_by_id("dialogIframe")
# 切换到子窗口
driver.switch_to.frame(frame)
# 在获取子窗口中的QQ登录按钮
driver.find_element_by_css_selector("a.pdl").click()12.3,案例分析
1.抓取链家前十页的数据
计算均价和总价:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://cs.lianjia.com/zufang/rs岳麓区/")
# 总价
total = 0
# 记录房间个数
size = 0
for i in range(2):
elements = driver.find_elements(By.CSS_SELECTOR, '.content__list--item--main')
print(f"第{i+1}页的数据:")
for el in elements:
# 获取租房标题
name = el.find_element(By.CSS_SELECTOR, '.content__list--item--title a').text
# 判断是否包含独栋信息
if name.__contains__("独栋"):
continue
# 获取租房的价格
price = el.find_element(By.CSS_SELECTOR, '.content__list--item-price em').text
print(f"name={name},price={price}")
total += float(price)
# 记录房间的个数
size += len(elements)
# 点击下一页
driver.find_element(By.CSS_SELECTOR,'a.next').click()
# 模拟睡眠6秒
time.sleep(2)
print(f"总价:{total},岳麓区的租房均价为:{total/size}")计算的类型(整租,合租)
str = """
name=整租·万科里金域国际 4室2厅 南,price=4500
name=独栋·魔方公寓 长沙航天溪湖店 连锁公寓直租无中介费 1室1厅,price=1800
name=整租·潇湘奥林匹克花园 1室1厅 南,price=2200
name=合租·达美美立方 5居室 复式 南卧,price=999
name=整租·万科里金域国际 3室2厅 南,price=3400
"""
# 计算的类型(整租,合租)
print("整租:", str.count("整租"))
print("合租:", str.count("合租"))计算的房型
str = """
name=整租·万科里金域国际 4室2厅 南,price=4500
name=独栋·魔方公寓 长沙航天溪湖店 连锁公寓直租无中介费 1室1厅,price=1800
name=整租·潇湘奥林匹克花园 1室1厅 南,price=2200
name=合租·达美美立方 5居室 复式 南卧,price=999
name=整租·万科里金域国际 3室2厅 南,price=3400
"""
import re
import collections
st = str.replace('居室','室')
rs = re.findall(r'\d室',st)
print(rs)
print(collections.Counter(rs))抓取boss直聘前十页的数据
boss直聘网址:https://www.zhipin.com/
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
driver = webdriver.Chrome()
driver.get("https://www.zhipin.com/web/geek/job?query=java&city=101020100")
jobs = []
for i in range(3):
time.sleep(6)
elements = driver.find_elements(By.CSS_SELECTOR, ".job-card-wrapper")
for el in elements:
# 获取地区
area = el.find_element(By.CSS_SELECTOR,"span.job-area").text
# 获取薪酬
salary = el.find_element(By.CSS_SELECTOR,"span.salary").text
print(f"area={area},salary={salary}")
jobs.append({
'area':area,
'salary':salary
})
driver.find_element(By.CSS_SELECTOR,".selected+a").click()
print(jobs)将获取数据本地序列化
# 将获取到的结果保存到本地
p = Path("jobs.txt")
p.touch()
# 通过pickle.dump实现数据序列化
pickle.dump(jobs,p.open(mode="wb"))计算每个区的需求个数与均价
# 计算每个区的需求个数与均价
jobs = pickle.load(open('jobs.txt',mode="rb"))
print(jobs)
areas=list(map(lambda a: "".join(re.findall(r'.*?·(.*?)·.*?',a['area'])),jobs))
print(areas)
import collections
rs = collections.Counter(areas)
for k,v in rs.items():
print(f"【{k}】的工作岗位需求数:{v}")
# 获取该区的工作集合
ps = list(filter(lambda e: e['area'].count(k) > 0, jobs))
# 获取该区的薪酬总价
total = functools.reduce(lambda a,b:a+int(b['salary'].split('-')[0]),ps,0)
print(f"该区的工作入门平均薪酬:{total/len(ps)}")十三,解析网页
案例:
import time
from pathlib import Path
import bs4
import requests
resp = requests.get("http://book.zongheng.com/chapter/1172818/67327837.html")
time.sleep(3)
#p = Path('网络小说.txt')
#p.touch()
with open("网络小说.txt",mode='w+', encoding='utf-8') as f:
for i in range(10):
soup = bs4.BeautifulSoup(resp.text, 'lxml')
title = soup.select('.title_txtbox')[0].string
f.write(title+"\n")
div = soup.select('.content')[0]
for c in div:
f.write(c.string + '\n')
next = soup.select("#page_reader > div.reader-wrap > div.reader-main > div.reader-bottom > div.nav-btn-group > a:nth-child(5)")[0]
next_url = next.attrs["href"][:-1]
resp = requests.get('http://book.zongheng.com/' + next_url)
soup = bs4.BeautifulSoup(resp.text, 'lxml')import pathlib
import bs4
import requests
resp = requests.get('https://book.zongheng.com/chapter/1172818/67327837.html')
print(resp.text)
soup = bs4.BeautifulSoup(resp.text, 'lxml')
p = pathlib.Path('大汉皇城.txt')
p.touch()
with p.open(mode='w+', encoding='utf-8') as f:
for i in range(10):
print(f'爬了{i}页')
# 找到章节标题
title = soup.select('.title_txtbox')[0].string
f.write(title + '\n\n')
# 找到主体部分
div = soup.select('.content')[0]
# 读取里面的文字
for pg in div.strings:
f.write(pg + '\n')
# 找到下一章的连接
# soup.select('.nextchapter')[0]['href']
url = soup.select('.nextchapter')[0].attrs['href']
# 重新发起请求
resp = requests.get(url)
soup = bs4.BeautifulSoup(resp.text, 'lxml')
十四,解析网页(xpath)
解析流程:

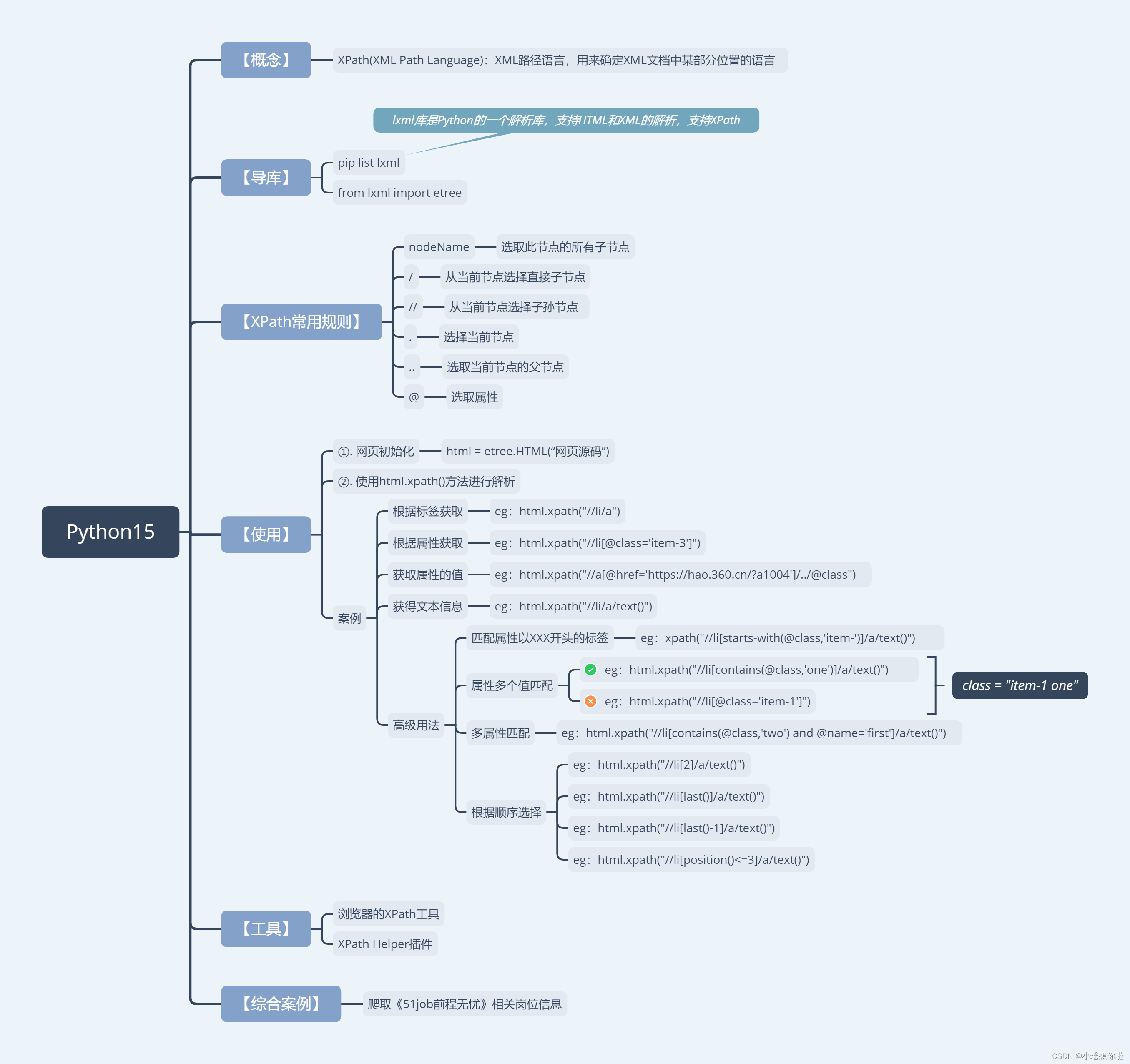
案例:
# requests 最开始用的
# selenium 模拟浏览器
# requests_html 这个爬虫速度比较快(完成动态渲染)
# 网页解析技术:
# re 正则模块
# bs4 BeautifulSoup
# xpath 定位
import pathlib
import lxml
from lxml import etree
p = pathlib.Path('index.html')
html = etree.HTML(p.read_text(encoding='utf-8')) # type:lxml.etree._Element
# print(html.xpath('//div'))
# print(html.xpath('./body'))
# div = html.xpath('./body/div')[0] # type:lxml.etree._Element
# print(div.xpath('..'))
# print(html.xpath('//*[@class="aa"]'))
# print(html.xpath('//*[@class="aa"]/text()'))
# print(html.xpath('//*[@class="aa"]')[0].text)
# print(html.xpath('//*[@class="aa"]/@href'))
# print(html.xpath('//*[@class="aa"]')[0].get('href'))
import time
import urllib.request
import uuid
# 需要先安装,pip install requests_html
# 第一次使用会下载Chromium [INFO] Starting Chromium download.
# 使用说明:https://zhuanlan.zhihu.com/p/376399749
import requests_html
session = requests_html.HTMLSession()
resp = session.get('https://www.vcg.com/creative-image/dongwu/') # type:requests_html.HTMLResponse
r = resp.html # type: requests_html.Element
r.render()
# links = list(r.absolute_links)
# 留下 .jpg,.png,.jpeg
# ls = list(filter(lambda l: l.endswith(".jpg"), links))
# print(ls)
urls = r.xpath("""//a[@class='imgWaper']/img/@data-src""")
def show(a, b, c):
"""
:param a: 次数
:param b: 读取的大小
:param c: 总大小
"""
print(f'\t{round(a * b / c, 1) * 100}%')
time.sleep(0.1)
for url in urls:
print('正在下载...')
"""
urlretrieve(url, filename=None, reporthook=None, data=None)
参数 finename 指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据。)
参数 reporthook 是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度。
参数 data 指 post 到服务器的数据,该方法返回一个包含两个元素的(filename, headers)元组,filename 表示保存到本地的路径,header 表示服务器的响应头。
说明:images如果不存在,需要事先创建,否则报错:
FileNotFoundError: [Errno 2] No such file or directory
"""
urllib.request.urlretrieve('http:' + url, f'images/{uuid.uuid4()}.jpg', show)十五,自动化办公
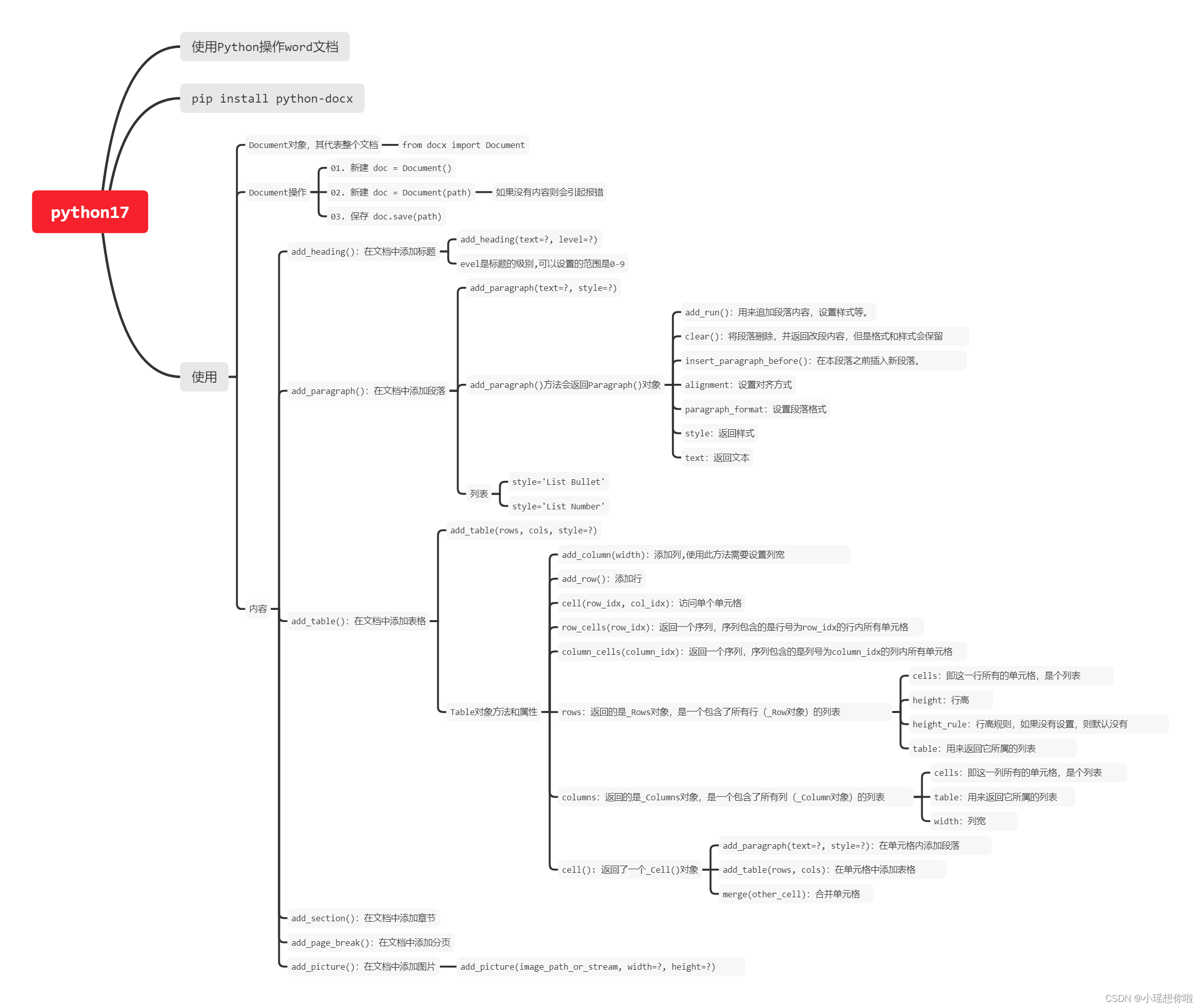
1,docx使用实例
开发示例:
"""从docx中导入Document模块。Document类是docx库中最重要的类之一,用于表示和操作Word文档对象,通过创建Document,你可以执行各种操作,如:创建,读取,编辑word。主要作用如下:1. 创建新文档2. 读取现有文档3. 编辑和修改文档4。 保存文档"""import docxfrom docx import Document'''从docx.shared(公共模块)导入Inches模块,该模块是用于指定文档中各种元素,如:段落,表格,图像的尺寸的单位。 除了Inches外,python中其他的尺寸单位还有:cm(厘米)、Mm(毫米)、Pt(榜)、Emu(英制单位,用与表示非常小的尺寸)换算:1 Inches = 2.54 cm 约 96px1 Inches = 72 Pt1 cm = 567 EmuRGBColor用于指定颜色值Pt用于指定字体的大小'''from docx.shared import Inches, RGBColor, Pt'''创建一个Document对象'''document = Document()'''在文档中添加标题,参数1: 标题的内容参数2: 指定标题级别,从0开始,最大到9,既在word中看到的一级标题,二级标题'''document.add_heading('Document Title', 0)'''增加段落。'A plain paragraph having some '为段落的内容'''p = document.add_paragraph('A plain paragraph having some ')'''向段落中加入新的内容”bold“,且新增的”bold“为加粗显示'''p.add_run('bold').bold = True'''继续向段落中加入 and some 文本,正常显示'''p.add_run(' and some ')'''向段落中加入”italic.“,且斜体显示'''p.add_run('italic.').italic = True'''向Document中加入一个新的标题,级别为1'''document.add_heading('Heading, level 1', level=1)'''在Document中加入新的段落,并将样式设定为Intense Quote(引用样式)其他的样式:Normal:普通段落样式,用于常规文本内容。Heading 1、Heading 2、Heading 3 等:用于创建标题级别的段落样式,级别逐渐减小。Title:用于文档标题的样式。Subtitle:用于文档副标题的样式。Quote、Block Quote:用于引用和特殊块的样式。List Bullet、List Number:用于创建项目符号和编号列表的样式。Caption:用于图表和表格标题的样式。Footnote Text、Endnote Text:用于脚注和尾注文本的样式。Hyperlink:用于超链接的样式。Table Normal:用于普通表格的样式。'''document.add_paragraph('Intense quote', style='Intense Quote')# 参考上面的说明document.add_paragraph('first item in unordered list', style='List Bullet')document.add_paragraph('first item in ordered list', style='List Number')'''用于插入一张图片到文档中,它接受两个参数:参数1: 是图片文件的路径,例如 'R-C.png'。请确保图片文件存在于指定路径。参数2: 可选的,用于设置图片的宽度。在示例中,使用 width=Inches(1.25) 设置图片的宽度为1.25英寸。设置图片的常见参数:height: 设置图片的高度。可以使用Inches、Cm、Mm等单位进行设置。left: 设置图片距离左边界的偏移量。可以使用Inches、Cm、Mm等单位进行设置。top: 设置图片距离上边界的偏移量。可以使用Inches、Cm、Mm等单位进行设置。right: 设置图片距离右边界的偏移量。可以使用Inches、Cm、Mm等单位进行设置。bottom: 设置图片距离下边界的偏移量。可以使用Inches、Cm、Mm等单位进行设置。参数使用示例:doc.add_picture('image.png', width=Inches(2), height=Inches(3))'''document.add_picture('R-C.png', width=Inches(1.25))document.add_paragraph('''In front of text In front of text In front of textIn front of text In front of text In front of text''')'''定义一个元组,用于指定表格的数据'''records = ((3, '101', 'Spam'),(7, '422', 'Eggs'),(4, '631', 'Spam, spam, eggs, and spam'))'''定义一个1行3列的表格,除指定行和列之外,还可以指定样式,如下:table = document.add_table(rows=3, cols=4, style='Table Grid')style参数值如下:'Table Grid':带有网格线的表格样式。'Light Shading':带有浅色底纹的表格样式。'Light Grid':带有浅色网格线的表格样式。'Light List':带有浅色列表样式的表格。'Light Grid Accent 1':带有浅色网格线和强调色1的表格样式。'Light Grid Accent 2':带有浅色网格线和强调色2的表格样式。'Light Grid Accent 3':带有浅色网格线和强调色3的表格样式。'Light Grid Accent 4':带有浅色网格线和强调色4的表格样式。'Light Grid Accent 5':带有浅色网格线和强调色5的表格样式。'Light Grid Accent 6':带有浅色网格线和强调色6的表格样式。以上为预置的网格线及背景颜色,如果需要自定义颜色可以使用:table_style = table.styletable_style.table_properties.borders.color.rgb = RGBColor(255, 0, 0)除了使用RGB的值来指定颜色外,还可以使用十六进制的数值来指定,如:table_style.table_properties.borders.color.rgb = RGBColor.from_string('#FF0000')'''table = document.add_table(rows=1, cols=3, style='Table Grid')'''指定第一行,既标题上的内容'''hdr_cells = table.rows[0].cellshdr_cells[0].text = 'Qty'hdr_cells[1].text = 'Id'hdr_cells[2].text = 'Desc''''设置表格的字体和字号'''style = table.style # type: docx.styles.style._TableStylestyle.font.name = '宋体'style.font.size = Pt(14)style.font.color.rgb = RGBColor(255, 0, 0)'''循环records元组,并将元组中的值依次赋给qty,id,desc变量,以便于给表格的每行数据赋值'''for qty, id, desc in records:'''调用add_row()为表格加一行数据,并获取这一行中的列元素在定义表格时已经设定一行中有3列'''row_cells = table.add_row().cells'''设置每列的内容和字体大小'''paragraph = row_cells[0].paragraphs[0]# 创建一个运行对象run = paragraph.add_run()print(run)# 设置运行对象的字体大小run.font.size = Pt(12) # 设置为12磅run.text = str(qty)# 设置内容row_cells[1].text = idrow_cells[2].text = desc# 插入分页符document.add_page_break()# 保存文件document.save('d:\\temp\demo.docx')
从网上爬取小说,并保存为word文档
import docx
import requests_html
session = requests_html.HTMLSession()
resp = session.get("https://www.81zw.com/book/14899/3850027.html")
html = resp.html
title = html.xpath("//div[@class='bookname']/h1/text()")[0]
print(title)
contents = html.xpath("//div[@id='content']/text()")
document = docx.Document()
document.add_heading(title, 1)
for c in contents:
run = document.add_paragraph().add_run(c)
document.save("小说.docx")从本地word文档中获取内容
import docx
document = docx.Document("小说.docx")
for p in document.paragraphs:
print(p.text)导成excel表
import openpyxl
from openpyxl.chart import BarChart, Reference
# 创建一个新的工作簿
from openpyxl.drawing.image import Image
workbook = openpyxl.Workbook()
# 获取默认的工作表
sheet = workbook.active
sheet.title = '工资表'
# 设置表格标题
sheet['A1'] = '姓名'
sheet['B1'] = '年龄'
sheet['C1'] = '性别'
sheet['D1'] = '收入'
# 填充数据
data = [
('张三', 25, '男', 3000),
('李四', 30, '女', 3500),
('王五', 28, '男', 4000),
('赵六', 28, '男', 4400),
('田七', 28, '男', 4500),
('曹操', 28, '男', 5000),
('徐玉', 28, '女', 6000),
('赵云', 28, '男', 9000),
('关羽', 38, '男', 7000),
('张飞', 35, '男', 6000),
('马超', 39, '男', 6800),
('黄忠', 73, '男', 7400),
('黄维', 34, '男', 6700),
('小龙女', 22, '女', 6200),
('玉面狐', 24, '女', 7000),
('玉兔', 25, '女', 4500)
]
# 将数据写入表格
for row in range(len(data)) :
for col in range(len(data[row])):
sheet.cell(row=row+2, column=col+1, value=data[row][col])
'''
创建创建统计图,常见的图形有:
1. 柱状图(Bar Chart): chart = BarChart()
1)用于比较不同类别或组之间的数据
2)显示离散数据的分布情况
3)可用于展示排名或排序结果
2. 折线图(Line Chart): chart = LineChart()
1) 显示随时间、连续变量或有序类别变量的趋势和变化
2) 可用于展示数据的增长、衰减或周期性模式
3. 散点图(Scatter Chart): chart = ScatterChart()
1) 用于显示两个连续变量之间的关系和相关性
2) 可用于检测变量之间的模式、趋势、异常值或聚类
注意:与上两个统计图不同,该图是展示两个变量之间的关系,所以需要定义两个变量的取值范围,如:
x_data = Reference(sheet, min_col=1, min_row=2, max_row=len(data))
y_data = Reference(sheet, min_col=2, min_row=2, max_row=len(data))
4. 饼图(Pie Chart): chart = PieChart()
1) 用于显示部分与整体的比例关系
2) 可用于展示数据的占比或组成成分
'''
chart = BarChart()
'''
设置数据范围,取第四列的值作为生成统计图的数据,行范围是1行到17行
注意此处的行范围是1行到17行,如果写成2行到17行,虽然不会缺少数据,但无法生成图例
'''
data = Reference(sheet, min_col=4, min_row=1, max_col=4, max_row=17)
'''
设置横坐标范围,取第一列为横坐标,行范围为2行到17行
'''
categories = Reference(sheet, min_col=1, min_row=2, max_row=17)
chart.add_data(data, titles_from_data=True)
chart.set_categories(categories)
'''
设置标题
'''
chart.title = "工资统计图形"
'''
参数1: 需要插入的char对象
参数2: F1表示插入统计图的左上角位置
'''
sheet.add_chart(chart, "F1")
image = Image("shizi.jpg")
'''
按原图比例来设置图片的尺寸
'''
origin_w = image.width
origin_h = image.height
image.width = 400
image.height = int(400 / (origin_w / origin_h))
'''
参数1: 需要插入的图片
参数2: 图片的左上角的位置
'''
sheet.add_image(image, 'A20')
# 保存工作簿
workbook.save('example.xlsx')十五,数据导入导出
通过案例来表示
import openpyxl
from openpyxl import load_workbook
from pymysql import connect
connection = connect(user="root", password="123456",
host="localhost", port=3306,
database="test", charset="utf8",
autocommit=True)
cursor = connection.cursor()
workbook = load_workbook('demo.xlsx')
sheet = workbook['Sheet1']
for row in sheet.iter_rows(min_row=2, values_only=True):
print(f"name:{row[0]}, age:{row[1]}, sex:{row[2]}, salary:{row[3]}")
sql = "INSERT INTO t_emplogy (name, age, sex, salary) VALUES (%s, %s, %s, %s)"
s = 1
if row[2] == '女':
s = 2
values = (row[0], row[1], s, row[3])
cursor.execute(sql,values)
connection.commit()
connection.close()import openpyxl
from openpyxl import load_workbook
from pymysql import connect
# 创建connection连接对象
connection = connect(user="root", password="123456",
host="localhost", port=3306,
database="test", charset="utf8",
autocommit=True)
# 创建游标对象
cursor = connection.cursor()
"""
workbook = load_workbook("demo.xlsx")
sheet = workbook["Sheet1"]
"""
"""for row in sheet.iter_rows(min_row=2, values_only=True):
name = row[0]
age = row[1]
sex = row[2]
if sex == "男":
sex = 1
else:
sex = 2
salary = row[3]
cursor.execute("insert into t_emplogy(age,name,sex,salary) values (%s,%s,%s,%s)",(age,name,sex,salary))
"""
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet.title = "工资表"
# 表头
sheet['A1'] = '编号'
sheet['B1'] = '姓名'
sheet['C1'] = '年龄'
sheet['D1'] = '性别'
sheet['E1'] = '收入'
# list = [i for i in cursor.fetchall()]
#
# for row in range(len(list)):
# for cell in range(len(list[row])):
# if cell == 3:
# if list[row][cell] == 1:
# sheet.cell(row + 2, cell + 1, "男")
# else :
# sheet.cell(row + 2, cell + 1, "女")
# else :
# sheet.cell(row+2,cell+1,list[row][cell])
cursor.execute("select * from t_emplogy")
for d,d1,d2,d3,d4 in cursor.fetchall():
if d3 == 1:
d3 ="男"
else:
d3 = "女"
sheet.append((d,d1,d2,d3,d4))
connection.close()
workbook.save('example01.xlsx')import openpyxl
from pymysql import connect
#链接数据库
connection = connect(user="root", password="123456",
host="localhost", port=3306,
database="test", charset="utf8",
autocommit=True)
cursor = connection.cursor()
sql = "select * from t_emplogy"
cursor.execute(sql)
records = cursor.fetchall()
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet['A1'] = 'ID'
sheet['B1'] = '名称'
sheet['C1'] = '年龄'
sheet['D1'] = '性别'
sheet['E1'] = '工资'
row = 2
for r in records:
for c in range(len(r)):
sheet.cell(row,c+1,r[c])
row += 1
# 获取当前日期,格式化后作为导出的文件名的一部分
current_date = datetime.date.today()
nowStr = current_date.strftime("%Y%m%d")
workbook.save(f"员工信息_{nowStr}.xlsx")十六,flask框架的使用
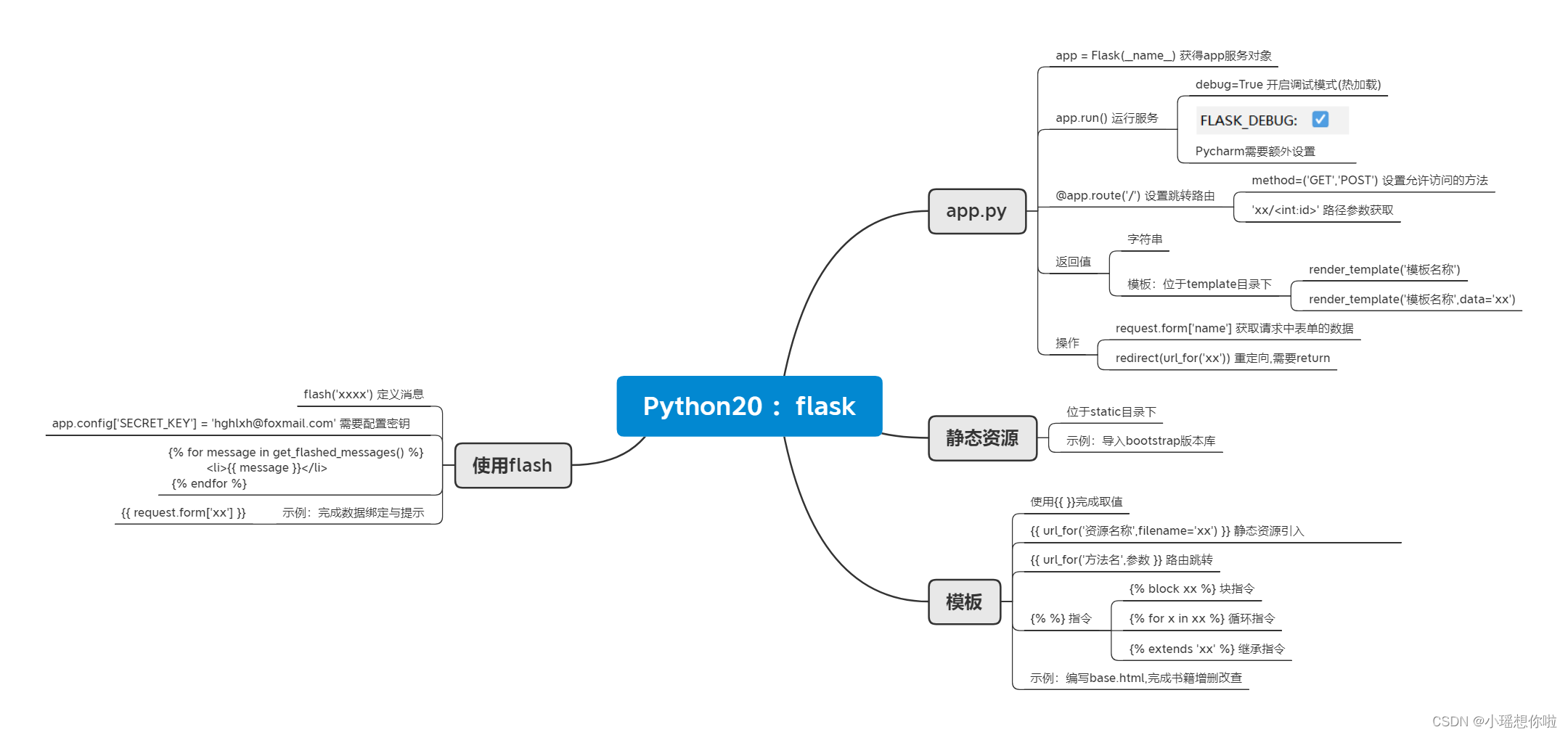
from flask import Flask, render_template, request, redirect, url_for
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
class Config(object):
user = 'root'
password = 'root123'
database = 'meeting'
# 连接语句
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://%s:%s@127.0.0.1:3306/%s' % (user, password, database)
# 查询时会显示原始SQL语句
app.config['SQLALCHEMY_ECHO'] = True
# 禁止自动提交数据处理
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = False
# 读取配置
app.config.from_object(Config)
# 创建数据库sqlalchemy工具对象
db = SQLAlchemy(app)
class User(db.Model):
# 定义表名
__tablename__ = 'meeting_user'
# 定义字段
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
nickname = db.Column(db.String)
account = db.Column(db.String)
password = db.Column(db.String)
role_id = db.Column(db.String)
@app.route('/')
def index():
users = ({"username": "sa", "tel": '10086'}, {"username": "sb", "tel": '10010'})
return render_template('index.html', users=users)
@app.route('/user/list')
def user_list():
return render_template('list.html', users=User.query.all())
@app.route('/user/insert', methods=['GET'])
def user_insert():
user = User(nickname=request.args['nickname'],
password=request.args['password'],
account=request.args['account'],
role_id=request.args['role_id'])
db.session.add(user)
db.session.commit()
return redirect(url_for('user_list'))
@app.route('/user/delete/<id>', methods=['GET'])
def user_delete(id):
db.session.delete(User.query.get(id))
db.session.commit()
return redirect('/user/list')
@app.route('/user/edit', methods=['GET'])
def user_edit():
user = User.query.get(request.args['id'])
user.password = request.args['password'],
user.account = request.args['account'],
user.role_id = request.args['role_id']
user.nickname = request.args['nickname']
db.session.commit()
return redirect('/user/list')
# 建表
# db.create_all()
# 删表
# db.drop_all()
# 增加
# db.session.add()
# 增加多个
# db.session.add_all([])
# 删除
# db.session.del()
# 提交
# db.session.commit()
# redirect() 重定向
# url_for() 跳转某个方法
if __name__ == '__main__':
app.run()
十七,flask数据库
web开发
-
模板的使用示例
模板页面
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>{{ name }}'s Watchlist</title>
</head>
<body>
<h2>{{ name }}'s Watchlist</h2>
{# 使用 length 过滤器获取 movies 变量的长度 #}
<p>{{ movies|length }} Titles</p>
<ul>
{% for movie in movies %} {# 迭代 movies 变量 #}
<li>{{ movie.title }} - {{ movie.year }}</li> {# 等同于 movie['title'] #}
{% endfor %} {# 使用 endfor 标签结束 for 语句 #}
</ul>
<footer>
<small>© 2018 <a href="http://helloflask.com/book/3">HelloFlask</a></small>
</footer>
</body>
</html>python
@app.route("/index")
def index():
name = 'Grey Li'
movies = [
{'title': 'My Neighbor Totoro', 'year': '1988'},
{'title': 'Dead Poets Society', 'year': '1989'},
{'title': 'A Perfect World', 'year': '1993'},
{'title': 'Leon', 'year': '1994'},
{'title': 'Mahjong', 'year': '1996'},
{'title': 'Swallowtail Butterfly', 'year': '1996'},
{'title': 'King of Comedy', 'year': '1999'},
{'title': 'Devils on the Doorstep', 'year': '1999'},
{'title': 'WALL-E', 'year': '2008'},
{'title': 'The Pork of Music', 'year': '2012'},
]
return render_template('index.html', name=name, movies=movies)1,作为weeb服务返回json数据
@app.route("/api/test/<id>", methods=['GET'])
def hello_api(id):
"""
id为路径参数
:param id:
:return:
"""
trucks = [
{'id': 1, 'year': 2017, 'model': 'model1'},
{'id': 2, 'year': 2019, 'model': 'model2'},
{'id': 3, 'year': 2020, 'model': 'model3'},
{'id': 4, 'year': 2016, 'model': 'model4'}
]
json = {
"code": 1,
"id": id,
"msg": '操作成功',
"data": trucks
}
return json获取请求参数,提交方法,提交的表达数据等
# 获取请求参数param = request.args.get("name")# 获取提交方法print(request.method)print(param)# 获取提交表达request.form
使用session
Session(会话)数据存储在服务器上。会话是客户端登录到服务器并注销服务器的时间间隔。需要在该会话中保存的数据会存储在服务器上的临时目录中。
为每个客户端的会话分配会话ID。会话数据存储在cookie的顶部,服务器以加密方式对其进行签名。对于此加密,Flask应用程序需要一个定义的SECRET_KEY。
Session对象也是一个字典对象,包含会话变量和关联值的键值对。
# 设置会话密钥app = Flask(__name__)app.secret_key = 'your_secret_key'@app.route("/test02")def get_args():session['name'] = "hello session"print(session.get("name"))return "ok"
使用cookie
@app.route("/set_cookies")
def set_cookie():
resp = make_response("success")
resp.set_cookie("name", "zhangsan",max_age=3600)
return resp
@app.route("/get_cookies")
def get_cookie():
cookie = request.cookies.get("name")
return cookie
@app.route("/delete_cookies")
def delete_cookie():
resp = make_response("del success")
resp.delete_cookie("name")
return resp一个表单示例
当用户访问/student时,转发到student.html页面
@app.route("/student")
def student():
return render_template("student.html")在templates目录下创建student.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<form action="http://localhost:5000/formdemo" method="POST">
<p>姓名 <input type = "text" name = "Name" /></p>
<p>语文 <input type = "text" name = "Chinese" /></p>
<p>数学 <input type = "text" name = "Maths" /></p>
<p>外语 <input type ="text" name = "English" /></p>
<p><input type = "submit" value = "submit" /></p>
</form>
</body>
</html>开发服务端,接收客户端传过来的表单数据
@app.route("/formdemo", methods=['POST'])
def form_demo():
form = request.form
return render_template("formdata.html", form=form)编写一个formdata.html页面用来显示服务端接收到的表达数据,这里只是为了展示,实际项目中应该是处理后保存到数据库
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<table border = 1>
{% for key, value in form.items() %}
<tr>
<th> {{key}} </th>
<td> {{value}}</td>
</tr>
{% endfor %}
</table>
</body>
</html>2,使用数据库
安装 SQLAlchemy
$ pip install -U Flask-SQLAlchemy增删改查实现示例
import random
from flask import Flask, render_template, redirect, url_for, request
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
"""
数据库配置类
"""
class Config(object):
"""
数据库链接配置类
"""
user = 'root'
password = '123456'
database = 'test'
# 连接语句
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://%s:%s@127.0.0.1:3306/%s' % (user, password, database)
# 查询时会显示原始SQL语句
app.config['SQLALCHEMY_ECHO'] = True
# 禁止自动提交数据处理
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = False
# 读取配置
app.config.from_object(Config)
# 创建数据库sqlalchemy工具对象
db = SQLAlchemy(app) #type: flask_sqlalchemy.extension.SQLAlchemy
class Book(db.Model):
# 定义表名
__tablename__ = 'book'
'''
定义数据表中的列,列的类型包括:
Integer: 整数类型。
Float: 浮点数类型。
Boolean: 布尔类型。
Date: 日期类型。
DateTime: 日期和时间类型。
Time: 时间类型。
Text: 长文本类型。
Unicode: 可变长度的 Unicode 文本类型。
UnicodeText: 长 Unicode 文本类型。
SmallInteger: 小整数类型。
BigInteger: 大整数类型。
Numeric: 数字类型。
Enum: 枚举类型。
'''
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
name = db.Column(db.String(50))
price = db.Column(db.Numeric(8, 2))
'''
要将数据库操作放在with app.app_context():中
否则会报:Working outside of application context.
with app.app_context(): 是 Flask 中用于创建应用上下文的上下文管理器。
应用上下文是 Flask 应用程序中的关键概念,它提供了一种环境,
使得在应用程序中能够访问 Flask 的核心对象(如请求对象、数据库对象等)。、
'''
with app.app_context():
'''
用于创建数据库中定义的所有模型对应的表格,如果不存在则创建
'''
db.create_all()
'''
判断数据表中是否有记录,如果有则清空
'''
# if Book.query.first():
# db.session.query(Book).delete()
# db.session.commit()
'''
如果书本表中没有记录,则向书本信息表中插入100条测试数据
'''
if Book.query.count() <= 0:
for i in range(100):
book = Book(name=f"book{i}", price=random.uniform(50, 100))
db.session.add(book)
'''
在数据库配置中已经指定关闭了自动提交,所以此处需要手动提交,否则数据不会被加入到
数据表中
'''
db.session.commit()
@app.route('/book/<name>')
def find_book(name = ''):
"""
获取书本信息
:param name:
:return:
"""
return render_template("bookList.html",
# books=Book.query.offset(10).limit(10)
# books=Book.query.order_by(Book.price.asc())[0:10]
# 指定过滤条件,并按价格降序排序
books=Book.query.filter(Book.name.like(f"{name}%")).order_by(Book.price.desc())
)
@app.route("/book/remove/<int:id>")
def remove(id: int):
'''
删除记录,先通过ID获取对应的记录,如果存在则删除,
如果不判断,则在记录不存在时会报异常
:param id:
:return:
'''
book = Book.query.get(id)
if book is not None:
db.session.delete(book)
db.session.commit()
return redirect(url_for('find_book', name="book"))
@app.route("/addBookPage")
def addBookPage():
"""
打开书本信息增加的页面
:return:
"""
return render_template("bookForm.html")
@app.route("/addBook", methods=['POST'])
def addBook():
"""
获取表单数据,并存入数据库
:return:
"""
form = request.form
name = form['name']
price = form['price']
book = Book(name=name, price=price)
db.session.add(book)
db.session.commit()
return redirect(url_for('find_book', name="book"))
@app.route("/updateBookPage/<id>")
def updateBookPage(id):
"""
打开修改页面,通过id获取需要修改的书本信息,并传回页面显示
:param id:
:return:
"""
book = Book.query.get(id)
print(book.name)
print(book.price)
return render_template("updateBook.html", form=book)
@app.route("/updateBook", methods=["POST"])
def updateBook():
"""
通过ID获取数据库中对应的记录,直接修改记录的对应属性提交后
即可修改数据库中的记录
:return:
"""
form = request.form
id = form['id']
name = form['name']
price = form['price']
book = Book.query.get(id)
book.name=name
book.price=price
db.session.commit()
return redirect(url_for('find_book', name="book"))
if __name__ == '__main__': # main
app.run()页面:bookList.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<ul>
{% for b in books %}
<li>{{ b.id }} - {{ b.name }} - {{ b.price }}</li>
{% endfor %}
</ul>
</body>
</html>页面: bookForm.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<form action="http://localhost:5000/addBook" method="POST">
<p>书名 <input type = "text" name = "name" /></p>
<p>价格 <input type = "text" name = "price" /></p>
<p><input type = "submit" value = "submit" /></p>
</form>
</body>
</html>页面:updateBook.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<form action="http://localhost:5000/updateBook" method="POST">
<input type="hidden" name="id" value="{{ form.id }}">
<p>书名 <input type = "text" name="name" value = "{{ form.name }}" /></p>
<p>价格 <input type = "text" name="price" value = "{{ form.price }}" /></p>
<p><input type = "submit" value = "submit" /></p>
</form>
</body>
</html>宝子们,赶快学起来吧!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









