







 本文介绍了哈希算法的基本原理,特别是图片hash的三种方法(平均哈希、感知哈希和差异哈希),并展示了如何用Python的imagededup库进行图片去重和基于模板查找相似图片的应用实例。
本文介绍了哈希算法的基本原理,特别是图片hash的三种方法(平均哈希、感知哈希和差异哈希),并展示了如何用Python的imagededup库进行图片去重和基于模板查找相似图片的应用实例。
一、背景知识
1.1 什么是hash
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,基本原理就是把任意长度的输入,通过Hash算法变成固定长度的输出。这个映射的规则就是对应的Hash算法,而原始数据映射后的二进制串就是哈希值。与指纹一样,就是以较短的信息来保证文件的唯一性的标志,这种标志与文件的每一个字节都相关,而且难以找到逆向规律。 活动开发中经常使用的MD5和SHA都是历史悠久的Hash算法。
hash算法的特点:
- 从hash值不可以反向推导出原始的数据
不可逆 - 输入数据的微小变化会得到完全不同的hash值,相同的数据会得到相同的值
唯一对应 - hash算法的冲突概率要小
冲突概率小 - 哈希算法的执行效率要高效,长的文本也能快速地计算出哈希值
高效计算
由于hash的原理是将输入空间的值映射成hash空间内,而hash值的空间远小于输入空间(输入空间是无限长度,而hash空间是有限的)。根据抽屉原理,一定会存在不同的输入被映射成相同输出的情况。那么作为一个好的hash算法,就需要这种冲突的概率尽可能小。
以上内容参考自:https://zhuanlan.zhihu.com/p/309675754
一般使用hash算法是为了校验文件是否被篡改或有传输损失。例如:某网站提供了文件下载地址和文件hash,我们下载文件后可以通过校验hash,确认文件没有发生传输损失(我下载的文件hash值,与网站公布的hash值一致)。又例如:某计算机考试,让学生提交作业文档和文档hash值给老师,确保作业未被篡改。
1.2 图片hash
哈希相似度算法(Hash algorithm),它的作用是对每张图片生成一个固定位数的Hash 值(指纹 fingerprint)字符串,然后比较不同图片的指纹,结果越接近,就说明图片越相似。图像Hash算法准确的说有三种,分别为平均哈希算法(aHash)、感知哈希算法你(pHash)和差异哈哈希算法(dHash)。
图像hash与上文中描述的hash算法目的不同,图像hash主要可用于判断或查找相似的图片,我们要尽可能的是图像hash值具有意义,与内容相关。他应当具备以下特点:
-
1、高效计算,能适应于不同尺寸的图像(
图像hash都要进行resize(8x8)) -
2、存在相似性,使相似的图像hash值相似(
根据图像的内容生成hash值)三种Hash算法都是通过获取图片的hash值,再比较两张图片hash值的汉明距离来度量两张图片是否相似。两张图片越相似,那么两张图片的hash数的汉明距离越小。
平均哈希算法(aHash)
平均哈希算法是三种Hash算法中最简单的一种,它通过下面几个步骤来获得图片的Hash值,这几个步骤分别是(1) 缩放图片;(2)转灰度图; (3) 算像素均值;(4)根据相似均值计算指纹。具体算法如下所示:

得到图片的ahash值后,比较两张图片ahash值的汉明距离,通常认为汉明距离小于10的一组图片为相似图片。汉明距离:字符串差异计算,相同位置下字符不同,则距离值加1
感知哈希算法(pHash)
感知哈希算法是三种Hash算法中较为复杂的一种,它是基于DCT(离散余弦变换)来得到图片的hash值,其算法几个步骤分别是(1) 缩放图片;(2)转灰度图; (3) 计算DCT;(4)缩小DCT; (5)算平均值;(6) 计算指纹。具体算法如下所示:

得到图片的phash值后,比较两张图片phash值的汉明距离,通常认为汉明距离小于10的一组图片为相似图片。
差异哈希算法(dHash)
相比pHash,dHash的速度要快的多,相比aHash,dHash在效率几乎相同的情况下的效果要更好,它是基于渐变实现的。其算法几个步骤分别是(1) 缩放图片;(2)转灰度图; (3) 算差异值;(4) 计算指纹。具体算法如下所示:

得到图片的phash值后,比较两张图片phash值的汉明距离,通常认为汉明距离小于10的一组图片为相似图片。
以上内容参考自:https://www.cnblogs.com/Yumeka/p/11260808.html
二、图片hash的运用
2.1 删除重复图片
要删除文件夹内重复的图片,可以使用 imagededup库。 imagededup是一个基于Python的图片查重工具库,它简化了在图像集合中查找精确重复和近似重复的任务。可以使用CNN(卷积神经网络)、PHash、DHash、WHash(小波散列)、以及AHash这几种方法之一对图像生成编码,然后根据编码进行比对图像是否重复,并提供一些工具生成图片重复项快照。

通过 pip 安装
安装命令
pip install imagededup
具体使用案例
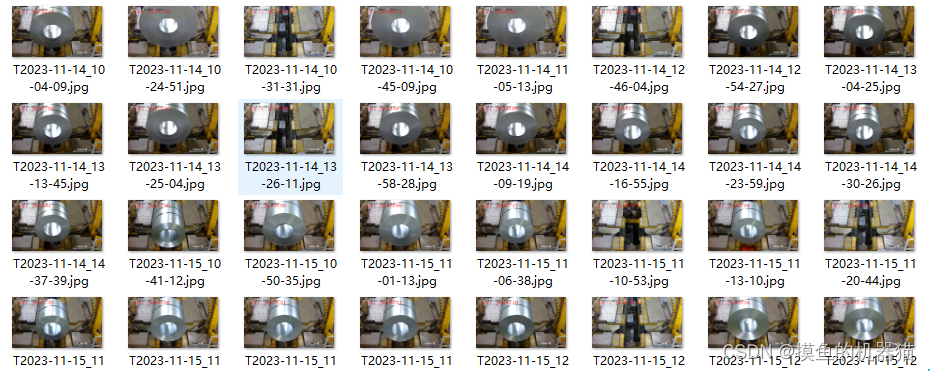
对一个文件夹内相同图片进行去重操作。本博文运用的是PHash(感知hash算法)。原始文件夹内的数据如下图所示:
注意如果是windows系统的话要加上if name==‘main’: ,因为它会默认使用多线程进行处理,不加的话会报错。
完整代码:
import os
from imagededup.methods import PHash
def process_file(img_path):
"""
处理图片去重
:return:
"""
try:
phasher = PHash()#WHash、AHash
# 生成图像目录中所有图像的二值hash编码
encodings = phasher.encode_images(image_dir=img_path)
#print(encodings)
# 对已编码图像寻找重复图像
duplicates = phasher.find_duplicates(encoding_map=encodings)
print(duplicates)
only_img = [] # 唯一图片
like_img = [] # 相似图片
for img, img_list in duplicates.items( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3093
3093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











