







本章内容我们从C/C++程序的内存分布开始,探索Linux下进程地址分布。探索过程中围绕“在同一个地址上的变量怎么会有2个不同的值?”逐步引入“虚拟内存”“页表”。引入页表后我们会接着介绍为什么要有“页表”。在了解“进程地址空间”和“页表后”我们回过头来解释问题“同一个地址上的变量为什么会有2个不同的值?”。最后我们还会通过这一章节的内容解释“malloc和new实际上申请的空间是在哪里?”和“为什么要?”
研究背景:
- kernel 2.6.32
- 32位平台
Linux下进程地址空间分布
Linux下进程的内存分布如下(本章节仅仅研究用户空间):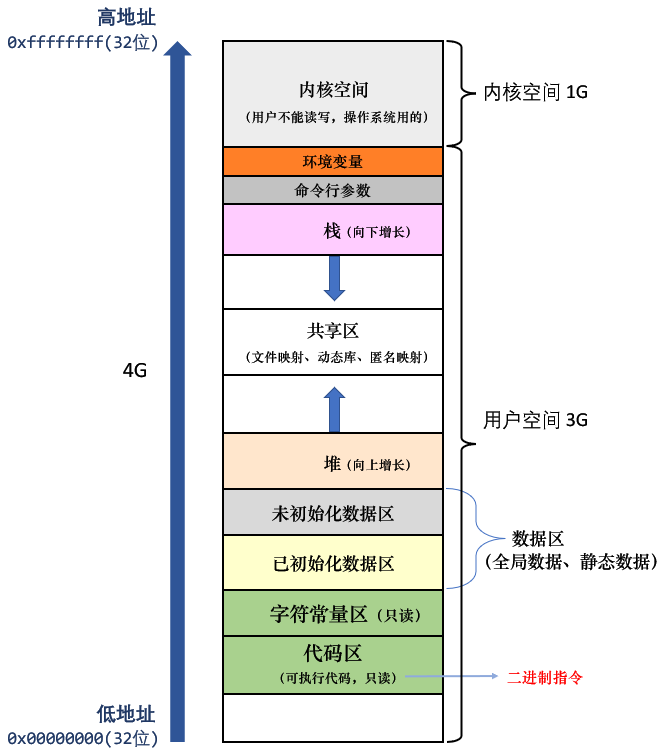
- 验证各个区域分布大致情况
int main(int argn, char** argv, char** env)
{
printf("Code Addr:%p\n", main);//用main函数地址表示代码区
const char* p_constant = "hello Linux!";
printf("Constant Addr:%p\n", p_constant);
printf("Init Addr:%p\n", &init_g_val);
printf("UnInit Addr:%p\n", &uninit_g_val);
char* heap = (char*)malloc(20);
printf("Heap Addr:%p\n", heap);
printf("Stack Addr:%p\n", &heap);
for (int i = 0; i < argn; i++)
{
printf("argv[%d]:%p\n",i, &argv[i]);
}
for (int i = 0; env[i]; i++)
{
printf("env[%d]:%p\n", i, &env[i]);
}
return 0;
}
测试结果: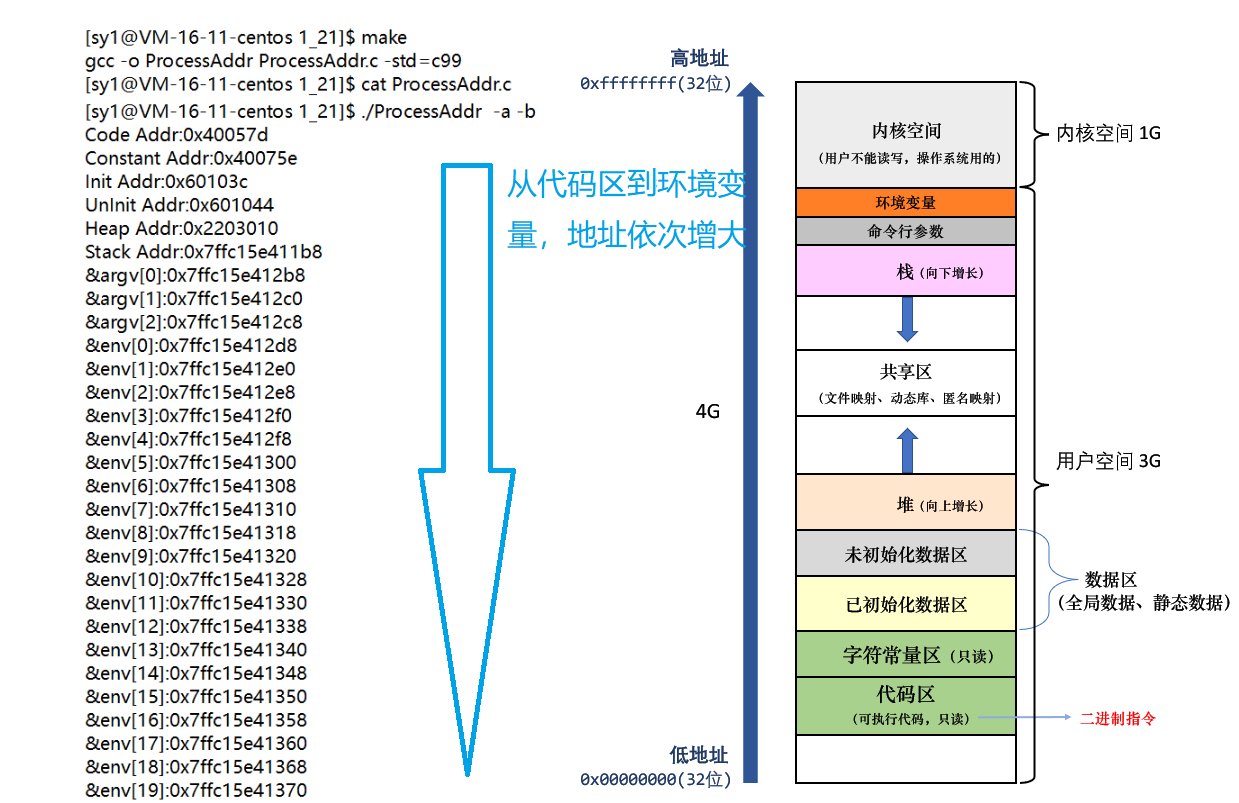
**结论:**Linux下进程内存分布的确是代码区<常量区已初始化数据区<未初始化数据区<堆区<栈区<命令行参数<环境变量
**注意:**处于数据区的变量在进程退出前一直存在,被static修饰的变量也会存放在数据区
-
验证堆区栈区的生成方向:
int main() { char* heap[3]; for (int i = 0; i < 3; i++) { heap[i] = (char*)malloc(5); } int a, b, c; printf("Heap grow:%p->%p->%p\n", heap[0], heap[1], heap[2]); printf("Stack grow:%p->%p->%p\n", &a, &b, &c); return 0; }测试结果:
 栈从高地址往低地址增长,堆从低地址往高地址增长。
栈从高地址往低地址增长,堆从低地址往高地址增长。 -
验证命令行参数表/环境表的地址与其指向字符串地址的关系:
int main(int argn, char** argv, char** env) { for (int i = 0;argv[i]; i++) { printf("&argv[%d]:%p\n", i, &argv[i]); } for (int i = 0;argv[i]; i++) { printf("argv[%d]:%p\n", i, argv[i]); } for (int i = 0; i<3; i++) { printf("&env[%d]:%p\n", i, &env[i]); } for (int i = 0; i<3; i++) { printf("env[%d]:%p\n", i, env[i]); } return 0; }测试结果:
[sy1@VM-16-11-centos 1_21]$ ./ProcessAddr -a -b &argv[0]:0x7ffc5c453148 &argv[1]:0x7ffc5c453150 &argv[2]:0x7ffc5c453158 argv[0]:0x7ffc5c45380c argv[1]:0x7ffc5c45381a argv[2]:0x7ffc5c45381d &env[0]:0x7ffc5c453168 &env[1]:0x7ffc5c453170 &env[2]:0x7ffc5c453178 env[0]:0x7ffc5c453820 env[1]:0x7ffc5c453836 env[2]:0x7ffc5c45384f命令行参数的地址在参数表的上方,环境变量的地址在环境表的上方,命令行参数的地址在环境变量地址的下方,因此表和它们参数的分布以如下形式:
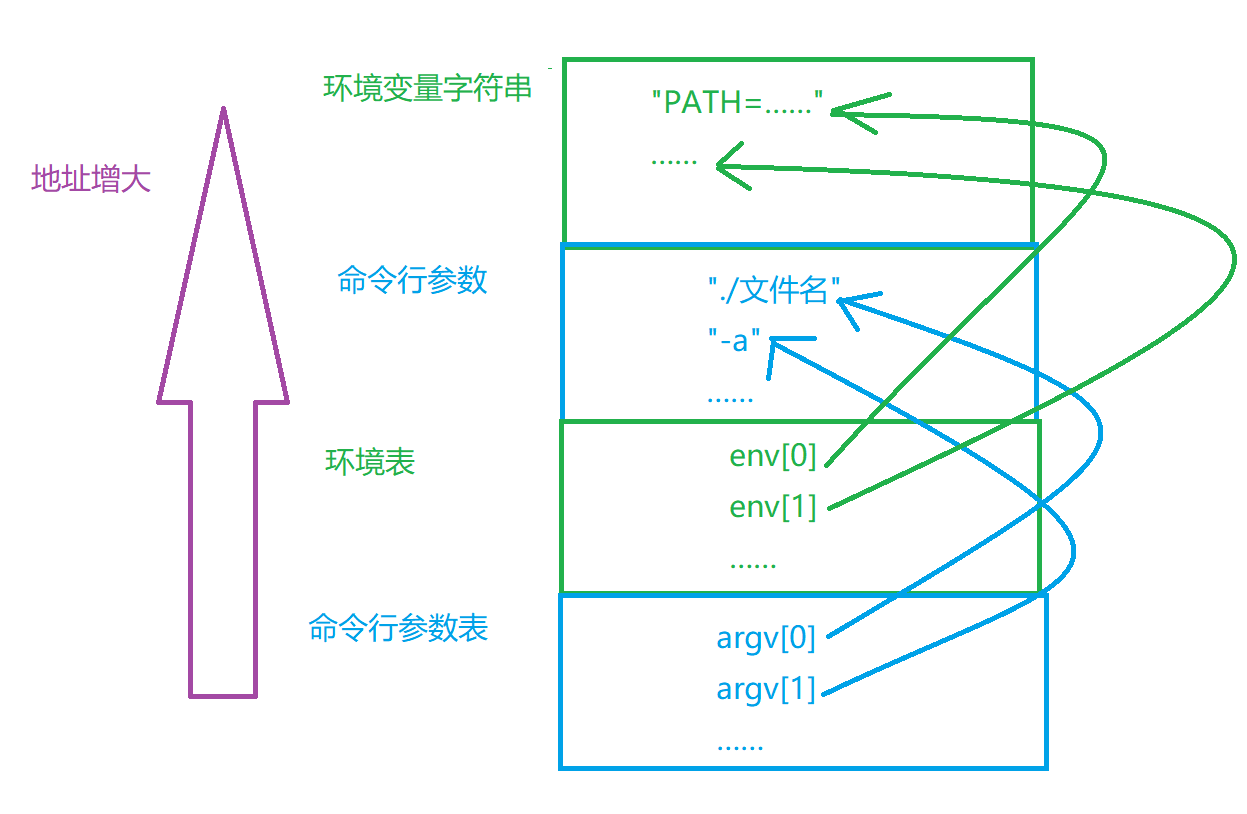
进程地址空间
有了上述知识,我们只是知道了进程地址空间具体的分布是怎么样的,但是仍然不知道进程地址空间是什么以及为什么要有进程地址空间,为了更好地理解进程地址空间,我们来看下面的代码:
int g_val = 0;
int main()
{
pid_t id = fork();
if (id < 0)
{
perror("fork:");
return 0;
}
else if (id == 0)
{
//子进程
printf("&g_val:%p, g_val=%d\n", &g_val, g_val);
}
else
{
//父进程
printf("&g_val:%p, g_val=%d\n", &g_val, g_val);
}
return 0;
}
output:
 上述结论是理所应当的,因为fork之后子进程以父进程为模板,父子进程都指向代码空间,且父子进程都没有写入g_val,不会发生
上述结论是理所应当的,因为fork之后子进程以父进程为模板,父子进程都指向代码空间,且父子进程都没有写入g_val,不会发生写时拷贝,所以父子进程看到的值和地址都是相同的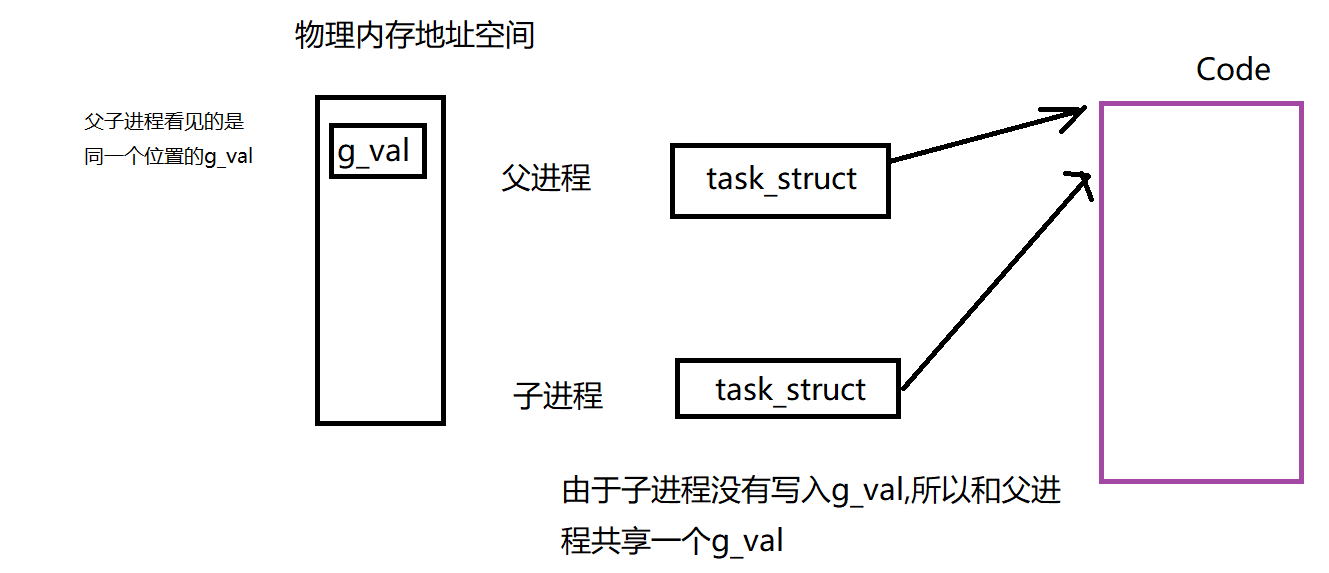
对上述代码修改一下:
int g_val = 0;
int main()
{
pid_t id = fork();
if (id < 0)
{
perror("fork:");
return 0;
}
else if (id == 0)
{
//子进程
g_val = 1;//子进程写入g_val
printf("&g_val:%p, g_val=%d\n", &g_val, g_val);
}
else
{
//父进程
printf("&g_val:%p, g_val=%d\n", &g_val, g_val);
}
return 0;
}
在子进程中对g_val进行写入,我们知道,当父子进程中有一个对共同数据进行写入时会发生写时拷贝,因此我们看到的现象应该是子进程的g_val被拷贝到物理内存中新的位置,这个新位置不同于父进程值为0的g_val。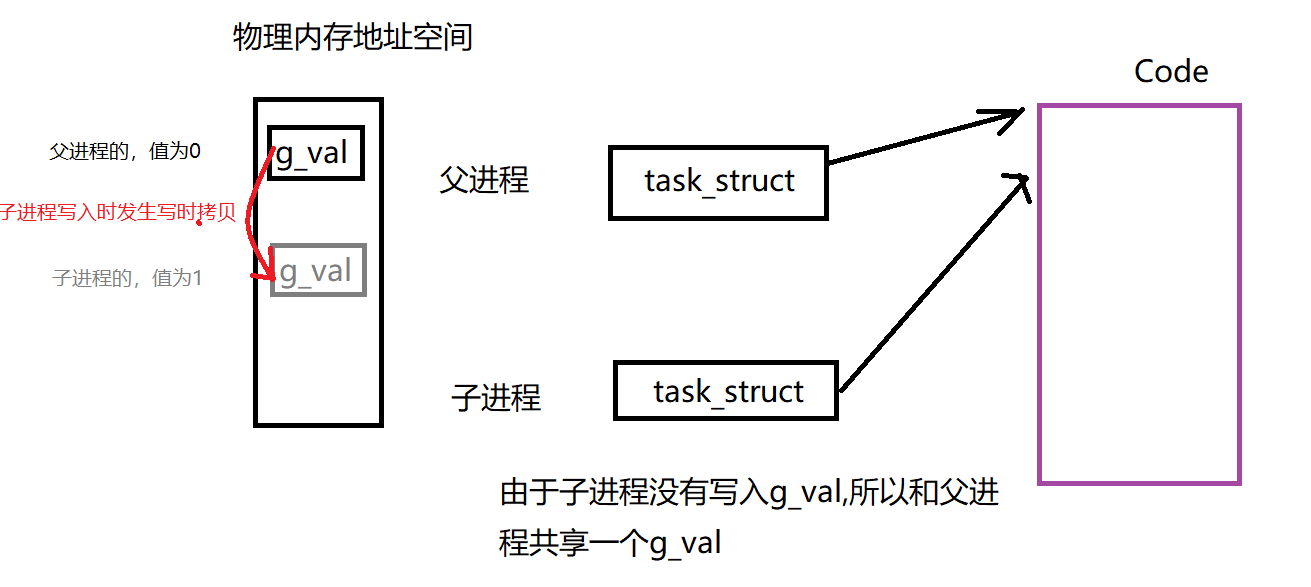
output:
父子进程的g_val地址值仍然相同,并且同一个地址同时存放了两个值。事实上,想要解释这个现象我们需要知道什么是虚拟地址和页表。
虚拟地址
物理内存中的地址称为物理地址,虚拟地址是区分物理地址而创建的一块虚拟区域,该虚拟区域没有硬件结构,所以没办法存储数据,而是通过某一种映射(页表)映射到物理地址中,实际上存储数据的还是物理地址。
对于物理地址来说,同一个地址不可能同时存放2个值(两个变量)。因此上述的0x601048不是物理地址,而是虚拟地址。
我们之前在C/C++程序中使用的/看见的地址均为虚拟地址,包括上述Linux下进程地址空间的分布也是虚拟地址空间的分布,若在栈中存储数据,实际上是用栈中该变量的地址通过映射关系映射到物理地址中,在物理地址中存储数据,只不过上层人员可以不关系这个过程,简单地认为“栈帮我们存储了变量”。
进程地址空间就是虚拟地址空间
为了更好的讲解,后续所说的虚拟地址=虚拟内存=进程地址空间=虚拟地址空间=地址空间
-
每一个进程都有自己的进程地址空间
先记住结论,每一个进程都会有自己对应进程地址空间,32位平台下进程地址空间为4G,64位下进程地址空间8G。
每一个进程都有自己的进程地址空间,那么不同的进程地址空间可以存放不同的变量,但是变量在它们所处进程的地址空间中处于相同位置。现在就可以初步解释上面的的现象了。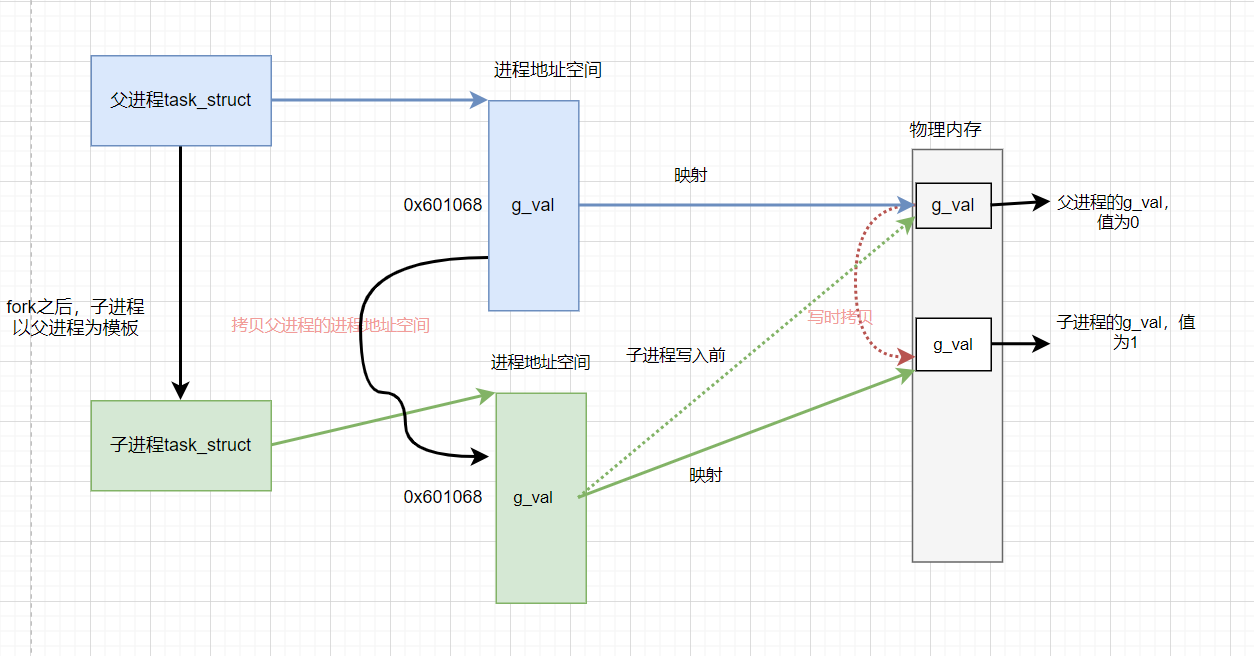
-
首先fork之后,子进程以父进程为模板创建,子进程拷贝父进程的虚拟地址空间,父子进程的&g_val在虚拟内存中都是0x601068,父子进程的g_val通过同一个映射关系映射到物理内存中。
-
当子进程尝试对与父进程共享的g_val进行写入,OS会在物理内存中发生
写时拷贝,在修改子进程虚拟地址空间中的g_val和物理内存的映射关系。 -
之后在父进程中访问g_val会根据虚拟内存中g_val的地址映射到物理内存g_val的地址,在物理内存就可以访问到父进程的g_val。在子进程中访问g_val同样会从虚拟内存g_val地址映射到物理内存地址上去,只不过由于发生写时拷贝后映射关系会改变,所以映射到物理内存的地址和父进程映射得到的不一样,g_val的值也不一样。但是在父子进程的虚拟内存中,g_val的地址是一样的。
-
因为程序中打印的地址是虚拟地址,但是访问变量是会根据映射去物理内存中访问,所以打印的地址值一样,值不一样。
-
-
进程地址空间是一种数据结构(链表)
每一个进程都有进程地址空间,OS要对进程做管理,所以OS也会对进程地址空间做管理,即OS会管理进程地址空间,管理的本质是对数据进行管理,管理的方式是先管理、再组织。进程地址空间在本质是一种数据结构(描述),在Linux下,这种数据结构为链表(组织)。
task_struct中有一个属性是指针,指向该进程的进程地址空间。
-
Linux下进程地址空间各区域的划分方式
进程地址空间是一个数据结构,进程地址空间中有Stack、Heap……等区域,为了严格表示这些区域处于地址空间中不同的位置,Linux下的进程地址空间用如下结构体描述:
struct mm_struct { //进程地址空间的其他属性 //进程地址空间的区域划分通过整形来表示 unsigned long total_vm, locked_vm, shared_vm, exec_vm; unsigned long stack_vm, reserved_vm, def_flags, nr_ptes; unsigned long start_code, end_code, start_data, end_data; unsigned long start_brk, brk, start_stack; unsigned long arg_start, arg_end, env_start, env_end; struct list_head mmlist;//指向下一个进程地址空间 }task_struct中有指向mm_strut的属性
struct task_struct { //进程的其他属性 struct mm_struct *mm, *active_mm;//指向对应进程地址空间的属性 }
页表
进程地址空间中不具备对我们的代码和数据保存的能力,代码和数据是保存在物理内存中!我们需要通过一种映射方式将地址空间上的虚拟地址转化到物理内存中的地址上。
给我们进程提供映射方式的是一张表---页表
当可执行程序运行起来后:
-
操作系统会将硬盘上可执行程序代码拷贝到物理内存中,为进程创建
PCB结构;为进程创建进程地址空间;为进程创建页表;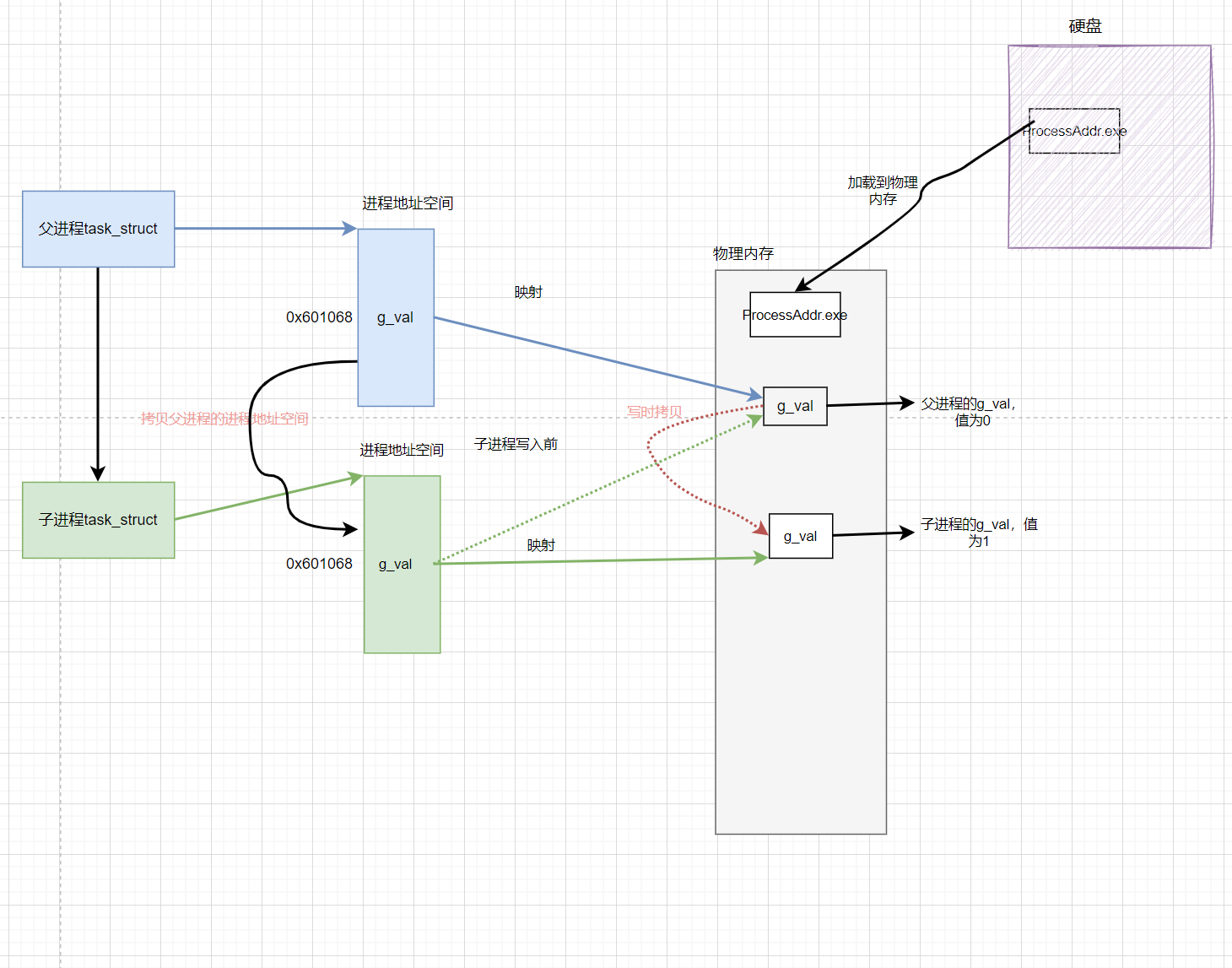
-
OS会将代码存放在虚拟地址中的
code区,此时代码既在虚拟内存上,又在物理内存上,就可以在页表中记录代码对应的虚拟地址和物理地址形成映射。 -
进程创建变量时:OS在虚拟地址中申请空间存储数据,若要对变量进行写入,OS会在内存中找一块空间存储变量,并在页表中写入该变量在虚拟内存和物理内存中的地址形成映射。
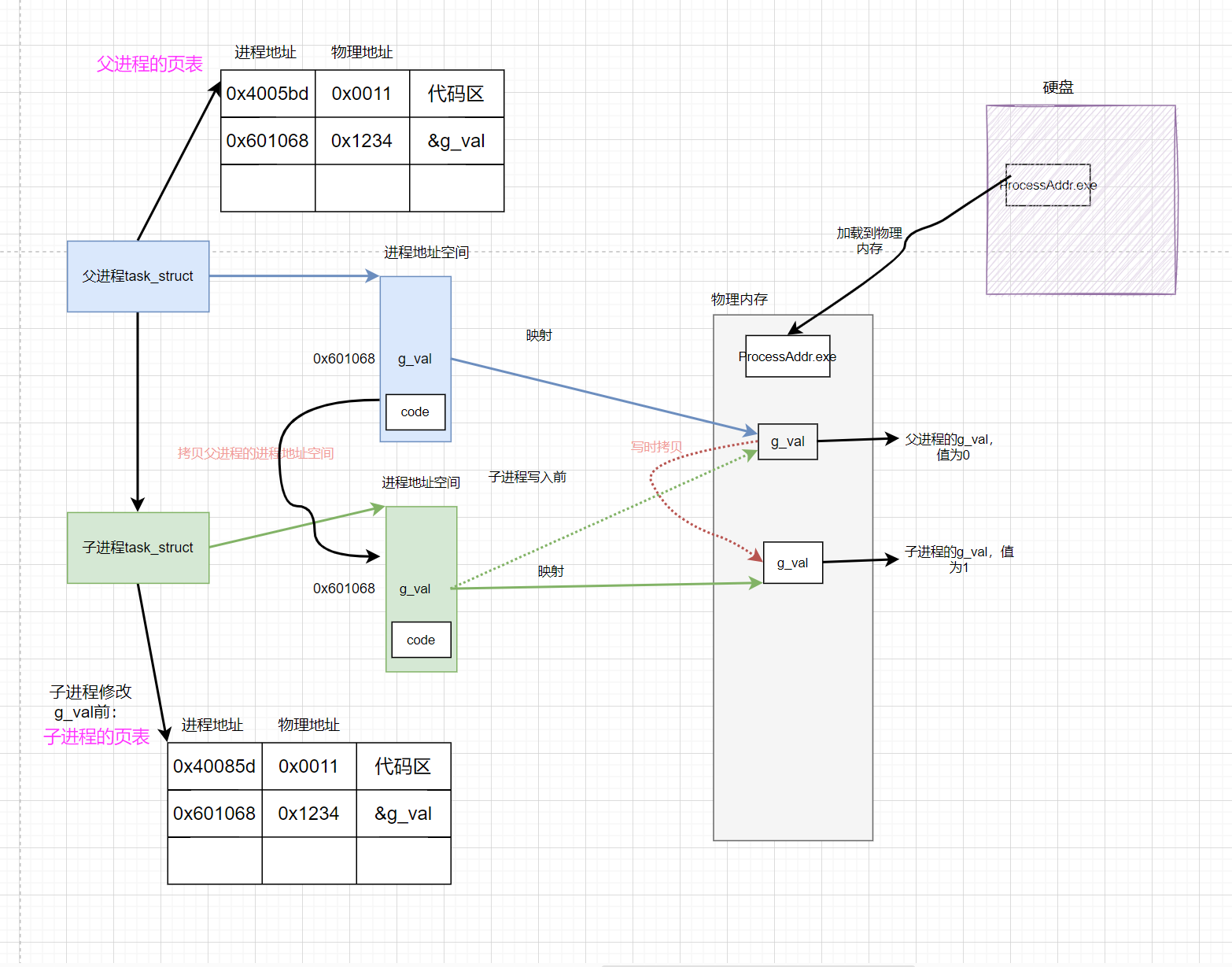
-
访问进程中的变量时:会根据该变量地址在页表中的映射找到存储的物理地址。例如上述访问g_val时,编译时g_val已经变成进程地址0x601068,页表中的映射为0x1234,于是OS会读取物理地址0x1234中存储的值。
-
创建子进程时:子进程的页表也是以父进程为模板创建的。所以在子进程没有修改数据前,父子进程的页表映射方式是一样的,所以看见变量的值和地址都是一样的。
-
当子进程尝试修改g_val:OS会在物理内存中发生生成子进程修改的的g_val。意味需要在子进程的页表中需要更改映射关系。
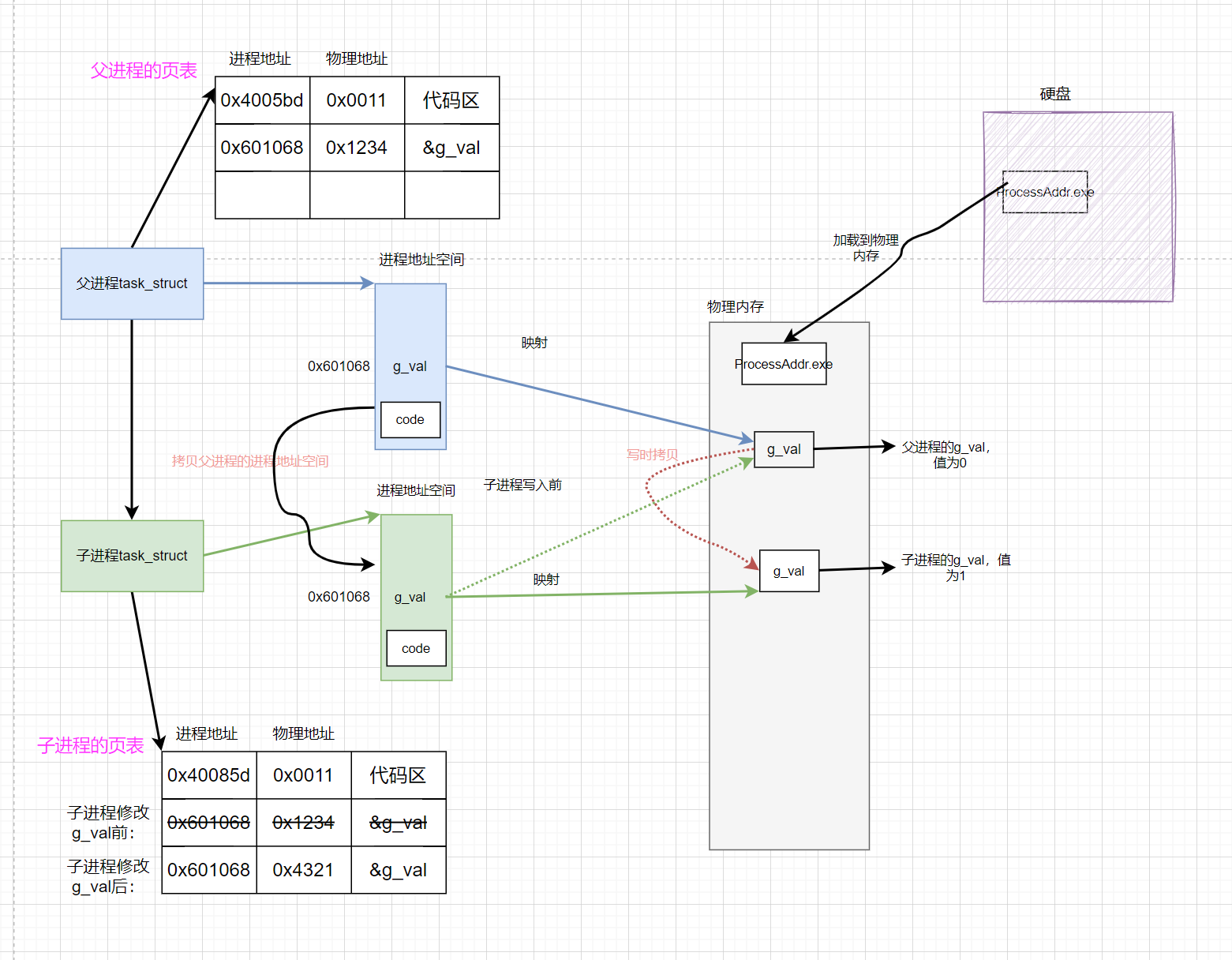
-
子进程再次访问g_val时:g_val的进程地址0x601068通过子进程的页表映射到物理地址0x4321中,OS就会读取该物理地址上的值。
[!Note]
页表也会被OS通过数据结构管理起来
为什么要有虚拟地址空间和页表?
-
将物理内存从无需变有序,让进程以统一的视角看待内存
数据和指令分散到物理内存中存储,数据和指令可以分散到不同位置,而不是按照逻辑顺序排列,这使得进程管理它们十分复杂。通过使用页表,操作系统可以将进程的虚拟地址空间划分为固定大小的页,然后将这些页映射到物理内存的对应位置。这种映射关系有助于使得物理内存的使用更加有序,提高了内存的管理效率。
进程使用虚拟地址来访问内存,每一个进程的虚拟地址空间都是一样的(分布一样、结构一样),所以每个进程所看到虚拟地址空间是一样的,因此进程看待内存的视角也是一样的。
-
将进程管理和内存管理进行解耦合
物理内存只负责拷贝数据;进程只负责为数据指令分配虚拟地址。通过页表,虚拟地址映射到物理内存上,进程不需要直接访问物理内存。 使进程管理和内存管理分开。
-
保护内存
当进程访问地址时,如果地址是合法的,那么该地址通过页表映射到物理内存中正常访问;如果地址非法,那么通过页表映射会得到一个非法地址,此时若继续访问会对物理内存产生伤害,当页表检测到我们访问地址非法时,便会拦截这次访问。
拓展
进程是具有独立性的
进程=内核数据结构+代码和数据,每一个进程都有自己的PCB,也有自己的进程地址空间,数据在内存中也是独立的。因此进程是具有独立性的。
申请内存
当我们进程通过malloc或new申请空间时,OS只会在虚拟地址空间中分配内存。只有当进程对申请的区域进行写入内容时,OS会查看写入区域是否合法,若合法则去页表中查看映射的物理地址,由于之前只在虚拟空间中分配内存,而没有分配物理内存,此时OS再去申请物理内存并进行写入。这叫做缺页中断。
只当对申请的空间进行写入时才申请物理内存的好处是:
- 充分保证物理内存的使用率,不会空转
- 提高new、malloc的效率















 1625
1625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









