






一:启动之前
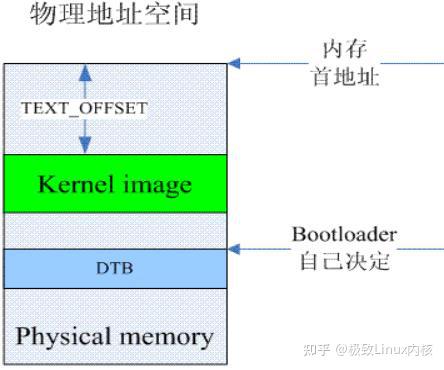
在内核启动之前,bootloader会将kernel image和DTB搬移到内存的指定位置。其中TEXT_OFFSET是kernel image相对内存起始地址的偏移。这时候MMU是关闭的,因此CPU看到的地址即是物理地址空间。
二:初始化MMU
跳转到内核执行,内核便完全掌控了内存系统的控制权。它首先要做的事情就是打开MMU,而为了打开MMU,必须要创建kernel正常运行需要的页表。
在体系结构相关的汇编初始化阶段,我们会准备二段地址的页表:一段是identity mapping,其实就是把地址等于物理地址的那些虚拟地址mapping到物理地址上去,打开MMU相关的代码需要这样的mapping(别的CPU不知道,但是ARM ARCH强烈推荐这么做的)。第二段是kernel image mapping,内核代码欢快的执行当然需要将kernel running需要的地址(kernel txt、rodata、data、bss等等)进行映射了。具体的映射情况可以参考下图:

启动MMU相关代码放在.idmap.text段中,对应上图中IDMAP_TEXT这个block。这部分代码被映射了两次:首先作为kernel image的一部分被映射到__idmap_text_start开始的虚拟地址上去,其次,它还被映射到__idmap_start开始的虚拟地址上去,而这个虚拟地址与其物理地址是相等的,这也是被称为idenity mapping的原因。上图中的PAGE_OFFSET是kernel image的起始虚拟地址,它核__idmap_start地址的高低核具体处理器的实现有关。
编译器感知的是kernel image的虚拟地址,在内核的链接脚本中定义了若干的符号,都是虚拟地址。但是在内核刚开始,没有打开MMU之前,这些代码实际是运行在物理地址上的,因此,内核刚开始的汇编代码基本上是PIC(位置无关)的。内核首先需要定位到页表的位置,然后在页表中填入kernel image mapping和identity mapping的页表项。页表的起始位置在bss段之后,具体的size需要确保能够覆盖kernel image mapping和identity mapping的地址段,然后又不会太浪费。我们以kernel image mapping为例,描述确定页表size的思考过程。假设48bit的虚拟地址配置,4k的page size,这时候需要四级映射,地址被分成9(level 0 or PGD) + 9(level 1 or PUD) + 9(level 2 or PMD) + 9(level 3 or PTE) + 12(page offset),这里每级页表有512个页表项,乘以64bit等于4k,正好是一页的大小。假设我们分配4个page分别保存level 0至level 3的页表,那么可以建立的最大地址映射范围是512(level 3中有512个entry)4k=2M。2M这个size不一定能够容纳kernel image的大小,怎么办?使用section mapping,让PMD执行block descriptor,这样使用3个page就可以映射5122M=1G的地址空间范围。当然这个办法有一个缺点,PAGE_OFFSET必须2M对齐。对于16k或者64k的page size,使用section就有点不合适了,因为这时候对齐要求太高了。对于16k的page size,level的长度为11bit(2^11*64bit=16k),所以对齐要求是(2^11*2^14)32M;对于64k的page size,level的长度为13bit(2^13*64bit=64k),所以对齐要求是(2^13*2^16)512M。不过当page size变大时,不使用section mapping也没什么,因为这时候映射的范围已经足够大了,比如对于16k的page size,可以映射的地址范围是32M,对于64k的page size,映射的地址范围是512M(大小和对齐大小一致)。结论:swapper进程(内核空间)需要预留页表的size是和page table level相关,如果使用了section mapping,那么需要预留PGTABLE_LEVELS-1个page,如果不适用section mapping,则需要预留PGTABLE_LEVELS个page。
上面的结论起始是适合大部分情况下的identity mapping,但是还是有特例(需要考虑的点主要和其物理地址的位置相关)。我们假设这样的一个配置:虚拟地址配置为39bit,而物理地址是48个bit,同时,IDMAP_TEXT这个block的地址位于高端地址(大于39 bit能表示的范围)。在这种情况下,上面的结论失效了,因为PGTABLE_LEVELS 是和虚拟地址的bit数、PAGE_SIZE的定义相关,而是和物理地址的配置无关。linux kernel使用了巧妙的方法解决了这个问题,大家可以自己看代码理解,这里就不多说了。
一旦设定完了页表,那么打开MMU之后,kernel正式就会进入虚拟地址空间的世界,美中不足的是内核的虚拟世界没有那么大。原来拥有的整个物理地址空间都消失了,能看到的仅仅剩下kernel image mapping和identity mapping这两段地址空间是可见的。不过没有关系,这只是刚开始,内存初始化之路还很长。
三:看见DTB
虽然可以通过kernel image mapping和identity mapping来窥探物理地址空间,但终究是管中窥豹,不了解全局,那么内核是如何了解对端的物理世界呢?答案就是DTB,但是问题来了,这时候,内核还没有为DTB这段内存创建映射,因此,打开MMU之后的kernel还不能直接访问,需要先创建dtb mapping,而要创建address mapping,就需要分配页表内存,而这时候还没有了解内存布局,内存管理模块还没有初始化,如何来分配内存呢?下面这张图给出了解决方案:

整个虚拟地址空间那么大,可以被平均分成两半,上半部分的虚拟地址空间主要各种特定的功能,而下半部分主要用于物理内存的直接映射。对于DTB而言,我们借用了fixed-mapped address这个概念。Fixed map 是被Linux Kernel用来解决一类问题的机制,这类问题的共同点就是:(1)在很早期的阶段需要地址映射,而此时,由于内存管理模块还没有完成初始化,不能动态分配内存,也就是无法动态分配创建映射需要的页表内存空间。(2)物理地址是固定的,或者是在运行时就可以确定的。对于这类问题,内核定义了一段固定映射的虚拟地址,让使用fixed map机制的各个模块可以在系统的早期就可以创建地址映射,当然这种机制不是那么灵活,因为虚拟地址都是编译时固定分配的。
好,我们可以考虑第三段地址映射了,当然,要创建地址映射就要创建各个level中描述符。对于fixed-mapped address这段虚拟地址空间,由于也是位于内核空间,因此PGD当然就是服用swapper进程的PGD了(其实整个系统就一个PGD),而其它level的Translation Table则是静态定义的(arch/arm64/mm/mmu.c),位于内核bss段,由于所有的Translation Table都在kernel image mapping的范围内,因此内核可以毫无压力的访问,并创建fixed-mapped address这段虚拟地址空间对应的PUD、PMD、和PTE的entry。所有中间level的Translation Table都是在early_fixmap_init函数中完成初始化的,最后一个level则是在各个具体的模块进行的,对于DTB而言,这发生在fixmap_remap_fdt函数中。
系统对DTB的size有要求,不能大于2M,这个要求主要时确保在创建地址映射(create)mapping)的时候不能分配其它的translation table page,也就是说,所有的translation table都必须静态定义。为什么呢?因为这时候内存管理模块还没有初始化,即便是memblock模块(初始化阶段分配内存的模块)都尚未初始化(没有内存布局的信息),不能动态分配内存。
【文章福利】小编推荐自己的Linux内核技术交流群: 【977878001】整理一些个人觉得比较好得学习书籍、视频资料共享在群文件里面,有需要的可以自行添加哦!!!前100进群领取,额外赠送一份 价值699的内核资料包(含视频教程、电子书、实战项目及代码)

内核资料直通车:Linux内核源码技术学习路线+视频教程代码资料
学习直通车:Linux内核源码/内存调优/文件系统/进程管理/设备驱动/网络协议栈
四:early ioremap
除了DTB,在启动阶段,还要其它的模块也想要创建地址映射,当然,对于这些需要,内核统一采用了fixmap的机制来应对,fixmap的具体信息如下:

从上面这个图片可以看出fix-mapped虚拟地址分为两段,一段是permanent fix map,一段是temporary fixmap。所谓permanent表示映射关系是永远都存在的,例如FDT区域,一旦完成地址映射,内核可以访问DTB之后,这个映射关系一直都是存在的。而temporary fixmap则不然,一般而言,某个模块使用了这部分的虚拟地址之后,需要尽快释放这段虚拟地址,以便给其它模块使用。
你可能会奇怪,因为传统的驱动模块中,大家通常用ioremap函数来完成地址映射,为什么还有一个early IO remaop呢?其它ioremap函数的使用需要一定的前提条件的,在地址映射过程中,如果某个level的translation table不存在,那么该函数需要调用伙伴系统模块的接口来分配一个page size的内存来创建某个level的translation table,但是在启动阶段,内存管理的伙伴系统还没有ready,其实这时候,内核连系统中有多少内存都不知道。而early io
remaop则在early_ioremap_init之后就可以被使用了。更具体信息参考mm/early_ioremap.c。
结论:如果想在伙伴系统初始化之前进行设备寄存器的访问,那么可以考虑early IO remap机制。
五:内存布局
完成DTB的映射之后,内核就可以访问这一段的内存了,通过解析DTB中的内容,内核可以勾勒出整个内存布局的情况,为后续内存管理初始化奠定基础。收集内存布局的信息主要来自下面几条途径:
choosen node。该节点有一个bootargs属性,该属性定义了内核的启动参数,而在启动参数中,可能包括了mem=nn[KMG]这样的参数项。initrd-start和initrd-end参数定义了initial ramdisk image的物理地址范围。
memory node。这个节点主要定义了系统中的物理内存布局,主要的布局信息是通过reg属性来定义的,该属性定义了若干的起始地址和size条目。
DTB header中的memreserve域。对于dts而言,这个域是定义root node之外的一行字符串,例如:/memreserve/ 0x05e00000 0x00100000;,memreserve之后的两个值分别定义了起始地址和size。对于dtb而言,memreserve这个字符串被DTC解析并称为DTB header中的一部分。更具体的信息可以参考device tree基础文档,了解DTB的结构。
reserved-memory node。这个节点及其子节点定义了系统中保留的内存地址区域。保留内存有两种,一种是静态定义的,用reg属性定义的address和size。另外一种是动态定义的,只是通过size属性定义了保留内存区域的长度,或者通过alignment属性定义对齐属性,动态定义类型的子节点的属性不能精准的定义出保留内存区域的起始地址和长度。在建立映射方面,可以通过no-map属性来控制保留内存区域的地址映射关系的建立。
通过对DTB中上述信息的解析,其实内核已经基本对内存布局有数了,但是如何来管理这些信息呢?这也就是著名的memblock模块,主要负责在初始化阶段用来管理物理内存。一个参考性的示意图如下:

内核在收集了若干和memory相关的信息后,会调用memblock模块的接口API(例如memblock_add、memblock_reserve、memblock_remove)来管理这些内存布局的信息。内核需要动态管理起来的内存资源被保存在memblock的memory type的数组中(上图中的绿色block,按照地址的大小顺序排列),而那些需要预留的,不需要内核管理的内存被保存在memblock的reserve_type的数组中(上图中的青色block,也是按照地址的大小顺序排列)。要想进一步了解,请参考内核代码中国的setup_machine_fdt和arm64_memblock_init这两个函数的实现。
六:看到内存
了解到当前的物理内存的布局,但是内核仍然只是能够访问部分内存(kernel image mapping和DTB那两段内存,上图中黄色block),大部分的没存仍然处于黑暗中,等待光明的到来,也就是说需要创建这些内存的地址映射。
在这个时间点上,创建内存的地址映射有一个悖论:创建地址映射需要分配内存,但是这时候伙伴系统还没有ready,无法动态分配。也许你会说,memblock不是已经ready了吗,不可以调用memblock_alloc进行物理内存分配吗?当然可以,memblock_alloc分配的物理内存仍然需要通过虚拟地址访问,而这些内存都还没有创建地址映射,因此内核一旦访问memblock_alloc分配的物理内存,悲剧就发生了。
怎么办呢?内核采用了一个巧妙的方法:那就是控制创建地址映射、memblock_alloc分配页表内存的顺序。也就是说刚开始时候创建的地址映射不需要页表内存的分配,当内核需要调用memblock_alloc进行物理地址分配的时候,很多已经创建映射的内存已经ready了,这样,在调用create_mapping的时候不需要分配页表内存,更具体的解释参考下图:

我们知道,在内核编译的时候,在BSS段之后分配了几个page用于swapper进程地址空间(内核空间)的映射,当然,由于kernel image不需要mapping那么多的地址,因此swapper进程translation table的最后一个level中的entry不会全部的填充完毕。换句话说:swapper进程页表可以支持远远大于kernel image mapping那一段的地址区域,实际上,它可以支持的地址段的size是SWAPPER_INIT_MAP_SIZE。为(PAGE_OFFSET,PAGE_OFFSET+SWAPPER_INIT_MAP_SIZE)这段虚拟内存创建地址映射,mapping到(PHYS_OFFSET,PHYS_OFFSET+SWAPPER_INIT_MAP_SIZE)这段物理内存的时候,调用create_mapping不会发生内存分配,因为所有的页表都已经存在了,不需要动态分配。
一旦完成了(PHYS_OFFSET,PHYS_OFFSET+SWAPPER_INIT_MAP_SIZE)这段物理内存的地址映射,这时候,终于可以自由使用memblock_alloc进行内存分配了,当然,要进行限制,确保分配的内存位于(PHYS_OFFSET,PHYS_OFFSET+SWAPPER_INIT_MAP_SIZE)这段物理内存中。完成所有memory type类型的memory region的地址映射之后,可以解除限制,任意分配memory了。而这时候,所有memory type的地址区域(上上图中绿色block)都已经可见,而这些宝贵的内存资源就是内存管理模块需要管理的对象。具体代码请参考paging_init--->map_mem函数的实现。
七:结束语
目前为止,所有为内存管理做的准备工作已经完成:收集了整个内存布局的信息,memblock模块中已经保存了所有需要管理memory region的信息,同时,系统也为所有的内存(reserved除外)创建了地址映射。虽然整个内存管理系统没有ready,但是通过memblock模块已经可以在随后的初始化过程中进行动态内存的分配。 有了这些基础,随后就是真正的内存管理系统的初始化了。














 756
756











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









