






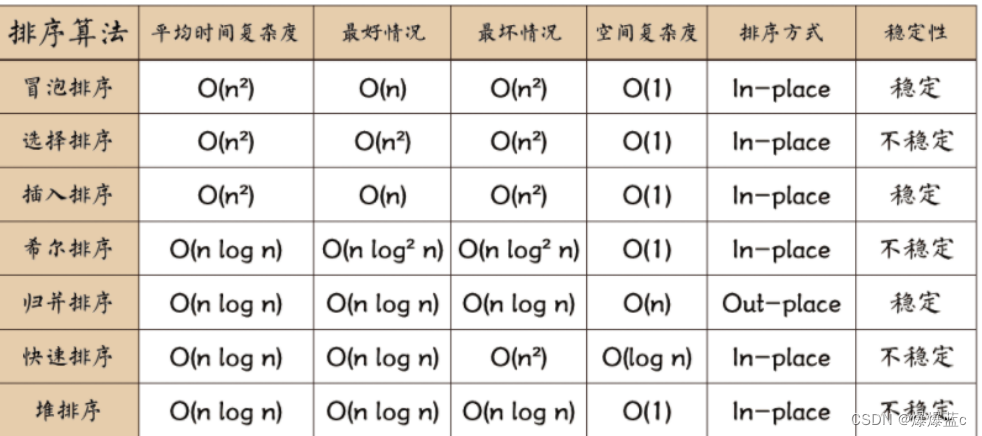
A内部排序 (无论什么数据都能用)
写排序算法代码的技巧:在具体实现这几种排序算法的代码时一定要注意无序区间和有序区间在算法最开始时的定义!
什么是排序算法的稳定性:待排序的序列中,若存在值相等的元素,经过排序之后,相等元素之间原有的顺序保持不变,这种特性称为排序算法的稳定性()
稳定性的理解比如原数组:{9,2,5a,7,5b,4,3,6} 排序之后{2,3,4,5a,5b,6,7,9} 5a在5b前面,排序稳定性保持顺序不变意思是5b不能在5a前面。
稳定性排序算法有什么作用:将来项目中有可能在不同时刻根据不同的属性进行排序(如果在进行多轮排序(依据的属性不同),后面的排序不对前面的排序产生影响,我们就优先使用稳定性的排序算法),若都是对同一属性的排序,则稳定性没啥影响。
B外部排序(不能独立存在,大多需要借助外存)![]()

外部排序对于数据的特点要求非常的高,应用场景很有限,只能在特定的数据集上使用。
七大排序
1.基于选择的思想:每次从无序区间中选择最小/最大值,放在无序区间的最开始或最后面,直到整个数组有序。
1.1直接选择排序:
在整个区间中选择最小值放在无序区间的最开始,每次都将当前区间的最小值放在数组最开始的为位置,每次选一个元素,这个元素就放在了正确的位置。(无序区间的元素个数-1,有序区间的元素个数+1)
{1, 5, 3, 2, 4, 10, 7, 9, 8, 30, 25, 26, 21, 15}
最开始时 无序区间[0...n] 有序区间[ ],min是当前最小值索引
每次在无序区间中选择最小值放在无序区间的最开始位置这个流程每走一次,就有一个元素放在了正确的位置,有序区间个数+1,无序区间元素个数-1.


直接选择排序: 时间复杂度:0(N^2)空间复杂度:O(1) 不稳定
1.2堆排序:也是基于选择的思想,每次从最大堆中选取最大值放在无序区间的末端,直到整个数组有序。
// 传入任意整形数组arr,对其进行原地堆排序 public static void heapSort(int[] arr) { // 1.heapify for (int i = (arr.length - 1 - 1) / 2; i >= 0; i--) { siftDown(arr,i,arr.length); } // 2.不断交换堆顶元素和数组的最后一个位置 for (int i = arr.length - 1; i > 0; i--) { swap(arr,0,i); // 交换之后,最大值已经放在了最终的位置 siftDown(arr,0,i); } } /** * 在arr数组的索引为k的位置进行siftDown操作 * arr * k * length == 之前写的size */ private static void siftDown(int[] arr, int k, int length) { // 还存在左子树 while (2 * k + 1 < length) { int j = 2 * k + 1; if (j + 1 < length && arr[j + 1] > arr[j]) { j = j + 1; } // j就保存了此时左右子树的最大值 if (arr[k] >= arr[j]) { break; }else { swap(arr,k,j); k = j; } } } public static void swap(int[] arr, int i, int j) { int temp = arr[j]; arr[j] = arr[i]; arr[i] = temp; }
时间复杂度:O(nlogn)空间复杂度O(1)稳定性:不稳定的排序(下沉过程中没有保证相等元素顺序不交换)
2.基于插入的思想:类比斗地主
插入思想:每次在无序区间选择一个元素吗,插入在有序区间的合适位置,直到整个数组有序
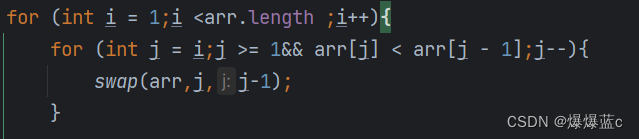
2.1直接插入排序:无序区间[i..n) 有序区间[0...i)
// 每走一次内层循环,就把无序区间的第一个元素插入到了有序区间的合适位置,直到整个数组有序。 for(int i=i; i<n-1; i++){// 不断向前(有序区间)看} 其中 i 这个下标就是有序区间和无序区间的分水岭,i之前的元素都是有序区间,i之后的元素就是待排序元素
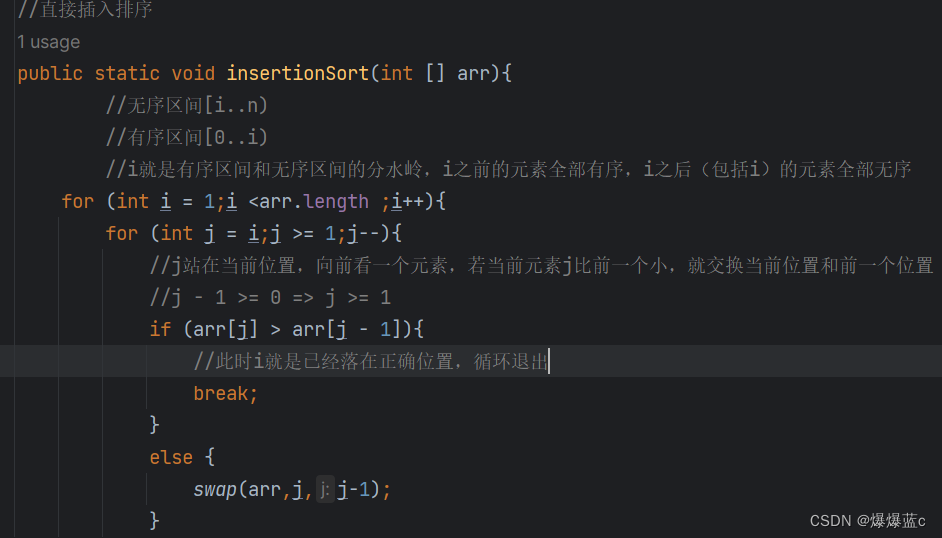
时间复杂度:O(n) 空间复杂度:
当数组近乎有序(完全有序)1 2 3 4 5 6 7 8 9
当待排序的区间很小,实验论证(16个元素以内,JDK,64个元素之间内的数组近乎都可认为是有序数组),直接使用插入排序进行排序即可。例如[1] 100%有序 ,[1,2] 50%可能有序,[1,2,3]近乎有序,因此在小数组上,元素个数没几个的情况下,数组近乎有序的
3.1希尔排序就是针对直接插入排序的优化:插入排序在近乎有序的数组上性能非常好或者在小数据规模的集合中性能也很好
能否有个好方法,将数组1.先调整的近乎有序,然后2.使用插入排序呢 ==》 希尔排序的核心思想
希尔排序的思路:宏观思路,先将数组调整的近乎有序,最终在整个近乎有序的数组上来一次插入排序
具体操作:
先预定一个整数(gap)将待排序的集合中按照gao分组(所有距离为gap的元素在同一组),对同一组的元素进行的排序,不断缩小这个gap的长度(gap /= 2,gap /= 3)重复上述的分组与排序过程,当gap == 1时,其实整个数组近乎有序,最终来一次全数组的插入排序,整个集合就有序了。
当gap > 1时,分组和组内排序就会将原数组调整的越来越有序
当gap==1时,整个数组已经近乎有序,此时再使用插入排序,效率就非常高这就是希尔排序
4.1 实现排序测试辅助
1.生成一个大小为n的,区间在 1..r的随机数数组
生成一个大小为n的,近乎有序的数组(完全有序就是近乎有序的一种,近乎有序只需要在完全有序的数组上交换几次就行了...交换的次数就可以控制这个有序的程度交换1次一定比交换2次要有序,交换0次就是完全有序)
2.测试不同的排序算法,输出排序时间
3.验证排序之后数组是否有序
排序算法的稳定性:排序之前相等元素的相对顺序在排序之后不发生改变,称为此排序算法是稳定性的排序算法。
什么时候才会用到稳定性的排序算法呢?
要排序的内容是一个复杂对象的多个数字属性,且原本的初始顺序存在意义,那么若我们需要在二次排序的基础上保持原有的排序,需要使用稳定性的排序算法。
eg:要排序的内容是一组原本按照价格从高到底的商品对象,如今再按照商品的销量进行排序,使用稳定性的排序算法,可以得到销量相同的对象仍然保持其价格按照原有的高低进行排列,只有销量不同时才会按照销量排序。
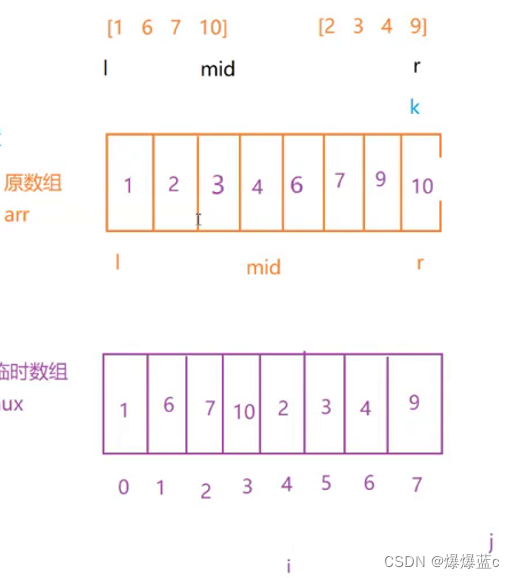
5.1归并排序:归并排序将待排序的数组划分为如下两个阶段
归而为一:阶段一:不管三七二十一,不断先将数组一分为二,直到每个数组只剩下一个元素,拆分阶段结束(此时每个子数组都是有序数组)
并而为整:阶段二:不断的将相邻的两个有序子数组,合并为一个大的有序数组,直到合并为完整的数组,此时整个数组有序!
其中在归并排序核心在于merge函数(合并操作)

归并排序由的merge函数
拆分过程中不会产生新的子数组只是下标的索引

子数组1:[l...mid]
子数组2:[mid+1 ...r]
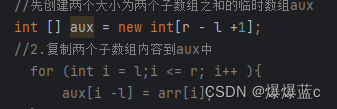
1.先创建一个大小为 r-l+1 的临时数组 aux
2.将两个子数组的所有内容复制到aux中、
3.进行两个子数组的比较合并过程知直到两个子数组合并完成
k索引表示当前覆盖到原数组的那个位置了
if(aux[i -1])<= aux[j - l] {arr[k] = aux[i-1];}
int i = l;int j = mid +1;
对应原数组1的元素aux[ j - l]就对应子数组2的元素
1.情况1:i > mid 说明什么?子数组1的所有元素已经处理完毕,直接将子数组2的剩余元素覆盖即可
2.情况2:j > r 说明子数组2的所有元素处理完毕,将子数组1的剩余元素进行覆盖
3和4进行两个子数组的元素内容大小比较。if(aux[i - 1])选择子数组1的元素进行覆盖,保证了相等元素的稳定性!
k索引表示当前覆盖到原数组的那个位置了
数组的部分深拷贝
System.arraycopy(原数组名称,原数组起始索引,新数组名称,新数组起始索引,拷贝长度);
这个方法比我们使用for循环去 --复制效率高的多因为这个方法是一个native方法(c++方法)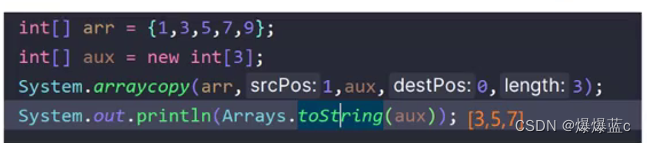
/*
在数组arr[l...r]上进行归并排序
*/
private static void mergeSortInternal(int [] arr,int l, int r) {
//base case
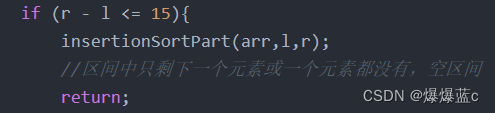
if (r - l <= 15){
insertionSortPart(arr,l,r);
//区间中只剩下一个元素或一个元素都没有,空区间
return;
}
int mid = l + (r -1) >> 1;
//先在左半区间数组arr[l...mid]上进行归并排序
mergeSortInternal(arr,l,mid);
//先在右半区间数组arr[mid+1...r]上进行归并排序
mergeSortInternal(arr,mid+1,r);
//现在开始合并左右两个有序子数组
//优化:若arr[mid] <arr[mid + 1]说明整个数组有序
if (arr[mid] > arr[mid + 1]) {
merge(arr, l, mid, r);
}
}
private static void insertionSortPart(int[]arr,int l,int r) {
for (int i = l + 1;i <= r;i++){
for (int j = i;j > l && arr[j-1] > arr[j];i --){
swap(arr,j,j-1);
}
}
}
/*
合并arr[l..mid]和arr[mid+1...r]两个有序子数组为一个大的新的有序数组
*/
private static void merge(int[] arr, int l, int mid, int r) {
//先创建两个大小为两个子数组之和的临时数组aux
int [] aux = new int[r - l +1];
//2.复制两个子数组内容到aux中
// for (int i = l;i <= r; i++ ){
// aux[i -l] = arr[i];
// }
//加餐,使用System类的数组 跟上面for循环效果一样
System.arraycopy(arr,l,aux,0,r-l+1);
int i = l,j = mid + 1;
for (int k = i;k <= r;k++){
if (i > mid){
arr[k] = arr[j - l];
j ++;
}else if (j > r){
arr[k] = arr[i - l];
i ++;
}else if (arr[i - l] > arr[j - l]){
arr[k] = arr[j - l];
j ++;
}else {
arr[k] = arr[i -l];
i++;
}
}
}
public static void mergeSort(int [] arr){
mergeSortInternal(arr,0,arr.length-1);
}优化1.其中在小数组区间上我们可以使用插入排序进行优化,减少了很多没必要的递归合并过程快速排序

归并排序用于海量数据处理(数据规模大到内存放不下,需要借助外存)
eg:内存只有1g,需要排序的数据为100g
a先待排序的数据划分为200份,每份0.5g
b分别将每份数据加载到内存中,使用任意排序方法对其排序
c进行200份有序文件的归并过程,最终整体数据有序了merge
归并排序的时间复杂度和空间复杂度O(nlogn),O(n)稳定性的排序算法

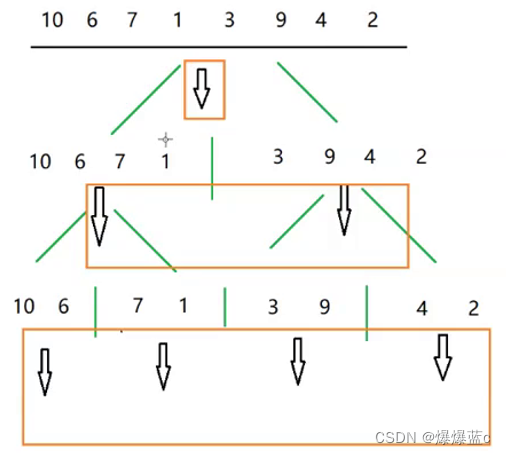
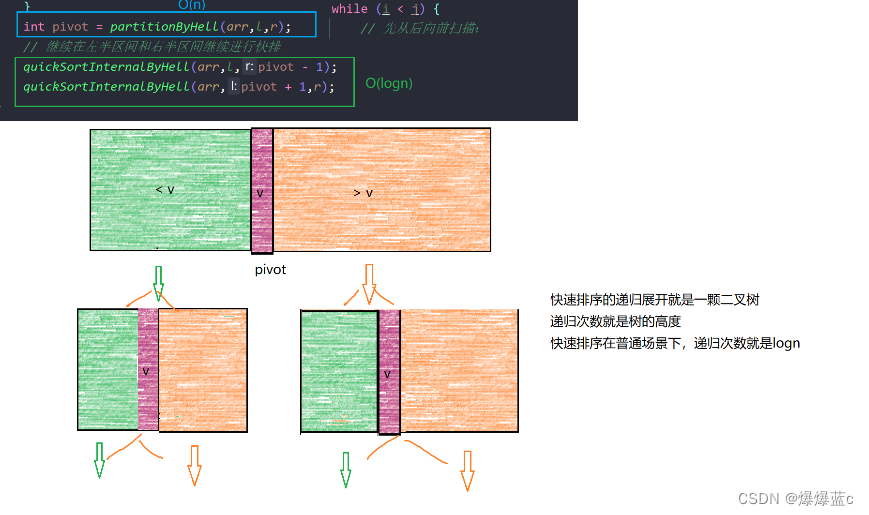
看到logn这个复杂度,则问题一定和“树”有关
不断将原数组拆分递归的过程本质就是一颗二叉树
递归的次数/拆分的次数其实就是树的高度 递归函数的调用次数就是O(logn)
merge函数时间复杂度是O(n) 因此归并排序时间复杂度O(nlogn)
空间复杂度为O(n)
20世纪最伟大的算法之一 快速排序
思路:先在无序数组中选取一个区间(数组中的一个元素),扫描整个集合
将比当前分区点小的元素放在区间点数值的左侧,比分区间点大的元素放在分区点数值的右侧,直接将分区点数值放在正确位置=》 分区点数值就放在了正确位置=》重复上述过程,继续在左半区间和右半区间进行快速排序
分区方法Hoare法

分区方法,2.挖坑法(校招中默认考察的分区方法,经典数据结构教材中的推荐分区方法实现) 针对Hoare法的改进(减少很多Hoare元素交换过程,直接进行赋值)

快速排序的时间复杂度和空间复杂度 平均时间复杂度O(nlogn)空间复杂度O(1)
快速排序是否稳定性看分区函数的具体实现,分区函数众多,不能保证稳定性















 319
319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









