






本文希望通过部署Hadoop为主线,对Hadoop的框架组成、各部分协同工作的原理、技术细节形成一个初步的认知和了解。
Hadoop安装前置知识
现在比较常见的Linux系统安装方式是选择虚拟机安装,在安装前进行方法调研的时候笔者发现:近三年几乎所有方法都是基于虚拟机安装的。而林子雨老师视频中也对两种方法的选择进行了说明:
总的来说,双系统安装并不是使用Linux系统的最优解。主要原因还是使用时较为不方便,一台电脑上最多只能支持同时使用一个系统。其他原因可能是浪费磁盘空间、双系统的配置比较复杂等。但是相比于虚拟机安装,双系统安装的优点是两个系统都能够直接访问硬件。
在部署Hadoop之前,需要了解一定的Linux基础知识,如:
Shell:是指“提供使用者使用界面”的软件(命令解析器),类似于DOS下的command和后来大家比较熟知的cmd.exe。它主要用于接收用户命令然后调用相应的应用程序。
**sudo命令:**是Ubuntu中一种权限管理机制。管理员可以授权给一些普通用户去执行一些需要root权限执行的操作。当使用sudo命令时,就需要输入当前用户的密码。
密码输入:Linux系统终端输入密码时是不会显示当前输入的内容和输入提示的,不要误以为键盘没有响应。
复制粘贴:在Ubuntu终端窗口中,复制粘贴的快捷键需要加上shift。
Hadoop有以下几种运行模式:
单机/本地模式:这是Hadoop的默认模式(又称非分布式模式),无需进行其他配置即可运行非分布式即单Java进程,方便进行本地开发调试,适合需要快速安装、体验Hadoop的用户。它访问的是本地磁盘,并不会去访问分布式文件系统HDFS。
伪分布式模式:学习Hadoop一般是在伪分布式模式下进行。伪分布式的意思是虽然各个模块是在各个进程上分开运行的,但是最终还是运行在一个操作系统上,并不是真正的分布式。在该模式下,Hadoop可以在单节点上以伪分布式的方式运行,Hadoop进程以分离的JAVA进程来运行,节点既作为Namenode也作为Datanode,同时读取的是HDFS中的文件。简单来说,这个模式就是在一台机器上各个进程上运行Hadoop的各个模块。下文我们也主要采用这个模式来部署Hadoop。
分布式模式:使用多台服务器构成集群环境来运行Hadoop,该模式是生产环境采用的模式。
Hadoop安装记录
由于笔者决定采用伪分布式模式运行Hadoop框架,该模式并非生产环境所采用的模式,笔者只是希望通过该模式了解Hadoop集群的一些功能,因此没有非常严格地去查看安装的Hadoop框架以及对应的JDK版本,只是照本宣科地跟着林子雨老师的教程过了一遍。正常的Hadoop框架配置应当预先准备好这一步。
查看环境
参考资料:https://blog.csdn.net/YUE_sasa/article/details/115334502
笔者采用的命令是:
uname -a
在装好Ubuntu系统后,在安装Hadoop之前还需要一些工作。
创建Hadoop用户
首先是创建一个名为"h a d o o p hadoophadoop"的用户,创建该用户命令如下:
$ sudo useradd -m hadoop -s /bin/bash
该命令创建了可以登陆的"h a d o o p hadoophadoop"用户,然后可以为其设置密码。
$ sudo passwd ******(个人密码)
同时我们还可以为h a d o o p hadoophadoop用户增加管理员权限,方便部署,在学习过程中可以解决一些比较复杂棘手的权限问题。
$ sudo adduser hadoop sudo
最后注销当前用户,返回登录界面,选择刚才创建的h a d o o p hadoophadoop用户进行登录。




1.Hbase相关定义
(1)数据模型
NameSpace
命名空间 类似于关系型数据库中的database概念,每个命名空间下可以放多个表。它为表的业务划分提供了方便,有助于更好地组织和管理表。
Table
表 类似关系型数据库中的table表概念,HBase定义表时只需要声明列族即可,不需要声明具体的列。
Column
列 HBase中的每个列都由ColumnFamily(列族)和ColumnQualifier(列限定符)进行限定,例如info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。
Row
行 HBase表中的每行数据都由一个RowKey和多个Column(列)组成,数据是按照RowKey的字典顺序存储的,并且查询数据时只能根据RowKey进行检索,所以RowKey的设计十分重要。
ColumnFamily
列族 创建Hbase表时,只需要给定列族即可,在插入数据时,列(字段)可以动态、按需增加。每个列族可以有一个或多个列限定符(ColumnQualifier)。
ColumnQualifier
列限定符 在HBase中,一个列是由列族(Column Family)和列限定符(Column Qualifier)组合而成的,使用冒号(:)进行分隔,即“列族:列限定符”的形式表示一个完整的列。
RowKey
行键 RowKey在表中必须是唯一的而且必须存在的。所有对表的访问都要通过RowKey。(单个RowKey访问,或RowKey范围访问,或全表扫描)
TimeStamp
时间戳 用于标识数据的不同版本,Hbase在写入数据时会自动加上当前系统时间戳为该字段值。
Cell
单元 由{RowKey,ColumnFamily,ColumnQualifier,TimeStamp}唯一确定的单元,Cell中的数据是没有类型的,全部为字节码形式储存。
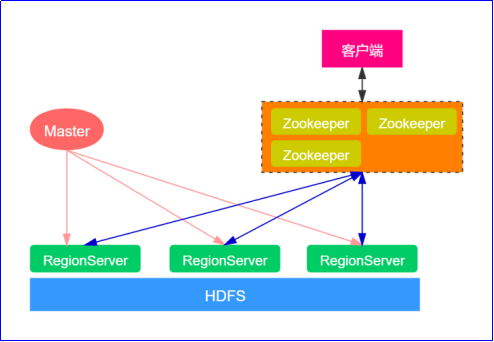
(2)HBase基本架构
①master(HMaster):作为集群的协调者,负责监控所有的RegionServer实例。
1)主要功能包括:
a.管理元数据表hbase:meta,接收并处理用户关于表的创建、修改和删除的请求。
b.监控region的分布情况,确保负载均衡,处理region的故障转移和拆分操作。
2)上述功能通过多个后台线程实现:
a.LoadBalancer:周期性检查region在RegionServer上的分布是否均衡,通过hbase.balancer.period参数配置检查周期,默认为5分钟。
b.CatalogJanitor:负责定期检查和清理hbase:meta表中的冗余或过期数据。
c.MasterProcWAL:记录master需要执行的任务到预写日志WAL中,确保在master故障时,backupMaster能够读取这些日志并恢复操作。
②RegionServer(HRegionServer):负责存储和处理HBase中的数据。
1)主要职责有:
a.处理数据的读写操作,如put(写入)和get(查询)。
b.执行region的拆分和合并操作,这些操作在master的监控下进行。
③Zookeeper:
1)HBase利用Zookeeper来管理master的高可用性、记录RegionServer的状态和位置信息,以及存储meta表的位置。
2)在HBase 2.3版本推出的MasterRegistry模式下,客户端可以直接与master通信,减少了对Zookeeper的依赖,从而减轻了Zookeeper的压力,但可能增加了master的负担。
④HDFS:作为HBase的底层存储系统,为HBase提供高可用和高容错的数据存储服务。
2.安装Zookeeper
(2)打开slave1、slave2、slave3,三台虚拟机都进入到/opt目录,全都要拖拽apache-zookeeper-3.5.7-bin.tar.gz上传到/opt目录下
(3)slave1、slave2、slave3均执行:tar -zxvf /opt/apache-zookeeper-3.5.7-bin.tar.gz -C /opt
(4)slave1、slave2、slave3均执行:mkdir -p /opt/apache-zookeeper-3.5.7-bin/zkData
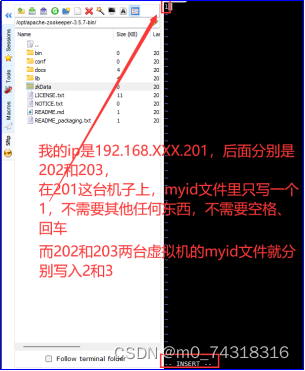
(5)slave1、slave2、slave3均执行:vi /opt/apache-zookeeper-3.5.7-bin/zkData/myid
(6)slave1、slave2、slave3均,将下/opt/apache-zookeeper-3.5.7-bin/confd的zoo_sample.cfg复制、并改名为zoo.cfg,命令:cp /opt/apache-zookeeper-3.5.7-bin/conf/zoo_sample.cfg /opt/apache-zookeeper-3.5.7-bin/conf/zoo.cfg
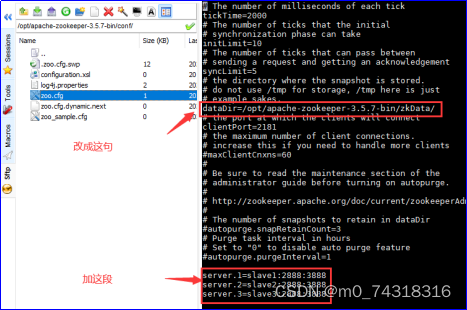
(7)修改zoo.cfg文件,vi /opt/apache-zookeeper-3.5.7-bin/conf/zoo.cfg
①添加以下内容:
server.1=slave1:2888:3888
server.2=slave2:2888:3888
server.3=slave3:2888:3888
②修改路径:dataDir=/opt/apache-zookeeper-3.5.7-bin/zkData/
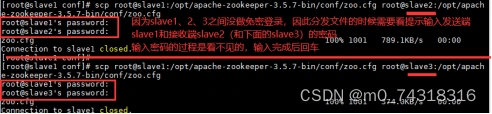
(8)同理,修改slave2、slave3的zoo.cfg文件,以下两种方法,选用一个:
①方法1:重复(7),直接去slave2、slave3的虚拟机下修改
②方法2:由于修改文件比较麻烦,使用scp分发模式,发送到slave2和slave3,命令分别是(检查slave2和slave3的文件,是否已经是分发下来的修改过了的):
scp root@slave1:/opt/apache-zookeeper-3.5.7-bin/conf/zoo.cfg root@slave2:/opt/apache-zookeeper-3.5.7-bin/conf/zoo.cfg
scp root@slave1:/opt/apache-zookeeper-3.5.7-bin/conf/zoo.cfg root@slave3:/opt/apache-zookeeper-3.5.7-bin/conf/zoo.cfg
 先去查看(13)①做免密登录)
先去查看(13)①做免密登录)
(9)master、slave1、slave2、slave3均修改vi /etc/profile.d/my_env.sh
①添加以下:
#ZK_HOME
export ZK_HOME=/opt/apache-zookeeper-3.5.7-bin
export PATH=
P
A
T
H
:
PATH:
PATH:ZK_HOME/bin
②重启profile,命令:source /etc/profile
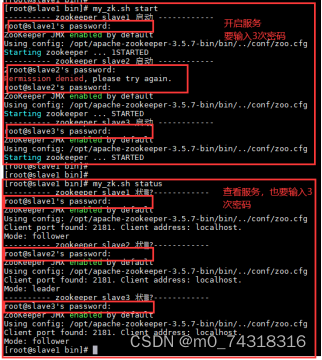
(10)分别在slave1、slave2、slave3使用zkServer.sh start,开启zookeeper

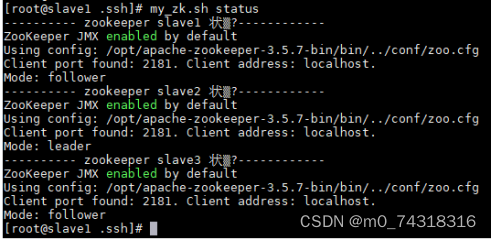
(11)分别在slave1、slave2、slave3使用zkServer.sh status,查看状态。其中slave2是leader

(12)由于每次在3台机器上执行开启、查看状态、停止命令太麻烦。要做2给步骤
①在slave1添加启动文件vi /opt/apache-zookeeper-3.5.7-bin/bin/my_zk.sh,群控slave1、slave2、slave3机器:
#!/bin/bash
case $1 in
“start”){
for i in slave1 slave2 slave3
do
echo ---------- zookeeper $i 启动 ------------
ssh $i “/opt/apache-zookeeper-3.5.7-bin/bin/zkServer.sh start”
done
};;
“stop”){
for i in slave1 slave2 slave3
do
echo ---------- zookeeper $i 停止 ------------
ssh $i “/opt/apache-zookeeper-3.5.7-bin/bin/zkServer.sh stop”
done
};;
“status”){
for i in slave1 slave2 slave3
do
echo ---------- zookeeper $i 状态 ------------
ssh $i “/opt/apache-zookeeper-3.5.7-bin/bin/zkServer.sh status”
done
};;
esac
②添加执行权限:chmod u+x /opt/apache-zookeeper-3.5.7-bin/bin/my_zk.sh
(13)由于每次都需要登录,繁琐,这里考虑又做一次slave1对slave2、slave3直接的免密登录:
①免密过程:
slave1 ssh-keygen -t rsa(执行命令后,对弹出提示连续按3次回车键)
cd ~
ll -al
cd .ssh
ssh-copy-id slave1
ssh-copy-id slave2
ssh-copy-id slave3
②免密验证:
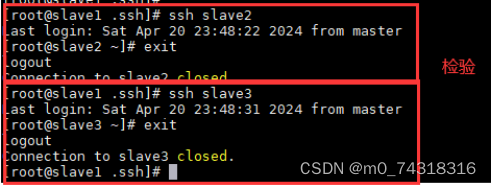
③Zookeeper指令验证:my_zk.sh status


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









