






在Python数据分析可视化中,数据预处理是非常重要的一步。通过数据合并、数据清洗和数据转换,我们可以有效地准备数据,以便后续的分析和可视化。
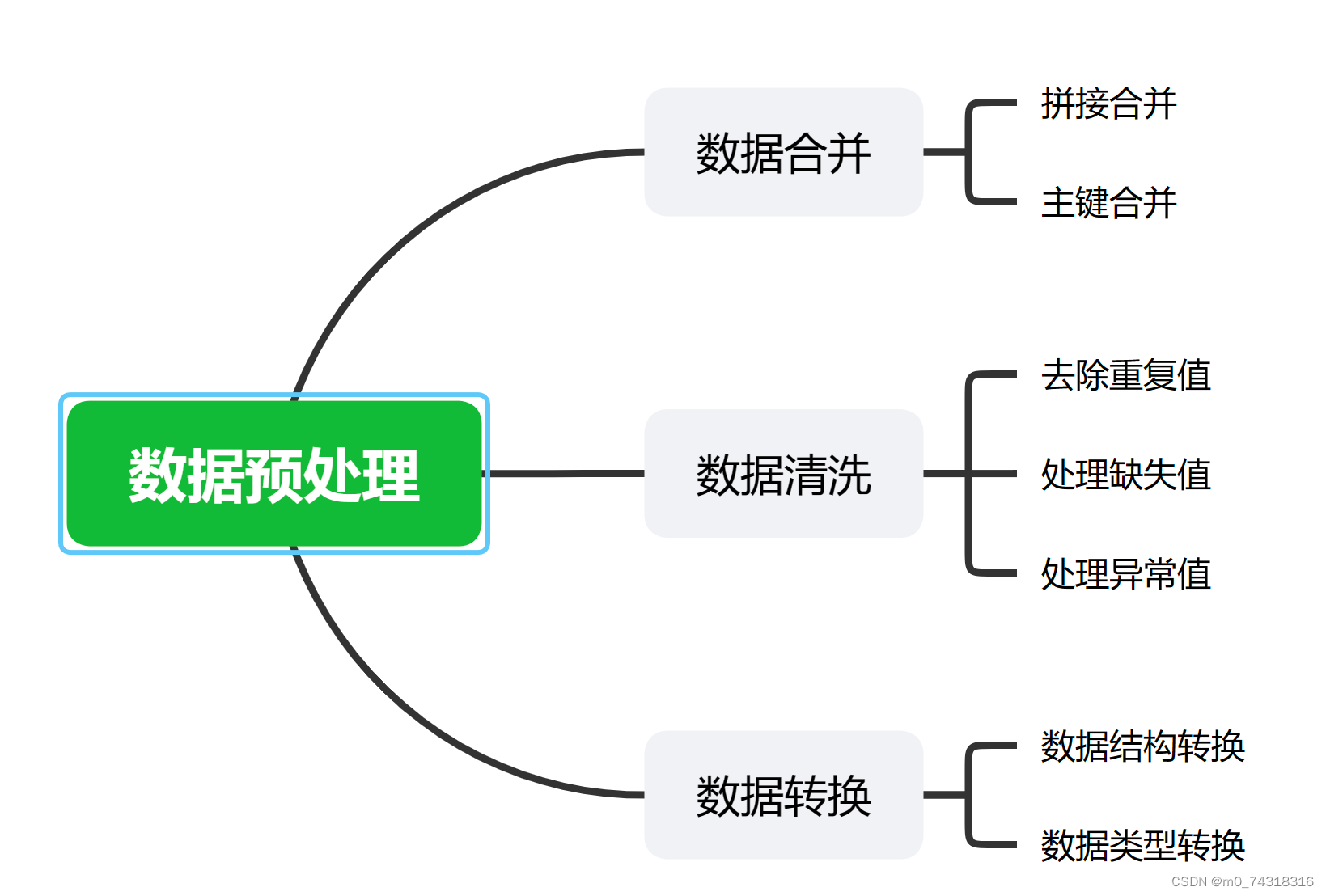
数据预处理学习思路图↑
数据合并:
一般来说我们使用 Pandas库中的merge()函数:
#首先,我们要先确保你的pandas库以及安装,如果未安装需要先安装,
pip install pandas
之后,我们在使用merge函数进行数据合并操作
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False)
这个函数主要用于根据一个或多个键将两个DataFrame进行合并。how参数可以设置为’inner’(默认)、‘outer’、‘left’或’right’,分别对应于内连接、外连接、左连接和右连接。
除此之外,还可以使用concat()函数
pd.concat(objs, axis=0, join='outer', ignore_index=False)
这个函数用于沿着一个轴将多个对象堆叠在一起。常用于水平或垂直堆叠DataFrame。
join方法:
df1.join(df2, on=key, how='left')
这是DataFrame的一个方法,用于根据指定的键将另一个DataFrame与当前DataFrame进行合并。
数据合并是将多个数据集合并成一个的过程。在实际的数据分析中,我们可能会从不同的数据源获取到不同的数据,通过数据合并,我们可以将这些数据整合在一起,方便后续的分析。常见的数据合并方式包括按行合并和按列合并。
数据清洗是指对数据进行清理和处理,以去除数据中的噪音、缺失值或异常值,使数据更加规范和可靠。常见的数据清洗操作包括去除重复值、处理缺失值、处理异常值等。
数据转换是指将原始数据转换成我们需要的形式,以便后续的分析和可视化。常见的数据转换操作包括数据类型转换、数据重塑、数据归一化等。
接下来到我们的数据清洗操作
-
处理缺失值:
- 删除含有缺失值的行或列:
df.dropna()。这个函数可以删除任何含有缺失值的行或列,可以通过设置how参数(‘any’或’all’)来决定是删除含有任何缺失值的行或列,还是删除所有值都为缺失的行或列。 - 填充缺失值:使用平均值、中位数、众数等进行填充,如
df.fillna(df.mean())。这里使用了mean()函数计算平均值,也可以使用median()或mode()函数分别计算中位数和众数。 -
- 异常值处理:
- 使用统计方法(如Z-score或IQR)识别异常值,并选择删除、替换或修正。例如,可以使用
z_scores = (df - df.mean()) / df.std()计算Z-score,然后设定一个阈值(如3),将绝对值大于该阈值的值视为异常值。 - 可视化检测异常值,例如使用箱线图。箱线图可以清晰地展示数据的四分位数和异常值。
- 删除含有缺失值的行或列:
-
数据类型转换:
- 将字符串数据转换为数值类型:
pd.to_numeric(df['column'], errors='coerce')。这个函数会尝试将指定列的数据转换为数值类型,如果无法转换,则将其设置为NaN。通过设置errors参数,可以控制遇到无法转换的值时的行为。 - 将日期字符串转换为日期格式:
pd.to_datetime(df['date_column'])。这个函数会尝试将指定列的字符串数据转换为日期格式。
- 将字符串数据转换为数值类型:
-
去除重复值:
- 使用
df.duplicated()检查重复值,返回一个布尔型Series,表示每一行是否为重复行。然后使用df.drop_duplicates()删除重复行。
- 使用
-
数据规范化/标准化:
- 对数据进行缩放,如最小-最大缩放(
MinMaxScaler)、Z-score标准化(StandardScaler)等。这些操作可以帮助数据满足某些算法的假设(如方差齐性、均值为0等)。
- 对数据进行缩放,如最小-最大缩放(
-
字符串操作:
- 清理文本数据:可以使用Python的内置字符串方法(如
strip()、replace()等)或者正则表达式进行清理,例如去除标点符号、空格、大小写转换等。 - 提取或替换子字符串:可以使用Python的切片、
str.extract()、str.replace()等方法进行操作。
- 清理文本数据:可以使用Python的内置字符串方法(如
-
数据合并/融合:
- 合并多个数据集:使用
pd.merge()或pd.concat()。pd.merge()可以根据两个数据集中的共同列进行合并,而pd.concat()则是直接将数据集在行或列方向上进行堆叠。
- 合并多个数据集:使用
敲重点:
-
理解数据是关键:在开始清洗数据之前,需要对数据的来源、收集方式、含义、潜在问题等有深入的理解。这有助于我们制定合适的数据清洗策略和后续分析计划。
-
逐步迭代过程:数据清洗往往不是一次性的过程,需要反复检查和调整清洗策略。在清洗过程中可能会发现新的问题或需要进一步处理的地方。
-
可视化辅助理解:通过绘制各种图表(如直方图、散点图、箱线图等)可以帮助我们更好地理解数据的分布、关联性和异常情况。这也有助于我们评估清洗效果和决策下一步的操作。
-
代码可复用性:编写函数或模块来封装数据清洗步骤,可以提高代码的可读性和复用性。这样在处理类似的数据集时,只需要调用相应的函数即可,避免重复编写相同的代码。
-
文档和注释:记录数据清洗的过程和决策,包括使用的清洗方法、参数设置、结果验证等,对于未来回顾和解释结果非常有帮助。同时,良好的注释可以使代码更容易被他人理解和维护。
-
质量优于数量:花时间在数据清洗上通常能提高后续分析和可视化的质量和准确性。一个干净、完整、一致的数据集是进行有效分析的基础。
-
持续学习和更新知识:数据清洗的方法和工具在不断发展中,保持学习和更新知识的习惯能提升数据清洗的效率和效果。可以通过阅读相关书籍、文章、博客、参加研讨会等方式获取最新的知识和技巧。
在Python的数据分析和可视化过程中,数据转换是非常重要的一环。以下是一些常用的数据转换方法:
、
-
Pandas库:
-
选择和过滤数据:Pandas提供了多种选择和过滤数据的方法。
.loc和.iloc是最常用的两种,.loc基于标签进行选择,而.iloc基于位置进行选择。.ix则是两者结合的用法,但在新版本的Pandas中已被弃用。示例:
df.loc[:, 'column_name'] # 选择所有行的'column_name'列 df.iloc[0:3, 1:3] # 选择前3行的第2列到第3列- 重塑数据:
.stack()和.unstack()用于将数据从宽格式转换为长格式或反之。.melt()函数则可以将宽格式的数据转化为长格式。
示例:
df.stack() # 将宽格式数据转化为长格式 df.unstack() # 将长格式数据转化为宽格式 df.melt(id_vars='id_column', value_vars=['var1', 'var2']) # 将宽格式数据转化为长格式 - 重塑数据:
-
数据清洗:处理缺失值和重复值是数据预处理的重要步骤。
.fillna()函数用于填充缺失值,可以使用特定值、前一个或后一个非缺失值、平均值等进行填充。.dropna()函数则直接删除含有缺失值的行或列。.duplicated()和.drop_duplicates()用于查找和删除重复的行。
示例:
df.fillna(value=0) # 使用0填充缺失值 df.dropna() # 删除含有缺失值的行 df.drop_duplicates() # 删除重复的行-
数据类型转换:
.astype()函数用于转换数据类型,如将字符串转换为数字,或将分类变量转换为类别型数据。示例:
df['column_name'].astype(int) # 将'column_name'列转换为整数类型
-
-
NumPy库:
-
数学运算:NumPy提供了丰富的数学运算功能,包括基本的加减乘除、指数、对数、平方根等操作,以及矩阵和数组的运算。
示例:
import numpy as np a = np.array([1, 2, 3]) b = np.array([4, 5, 6]) np.add(a, b) # [5, 7, 9] np.exp(a) # [2.71828183e+00, 7.38905610e+00, 2.00855369e+01] np.log(a) # [0. , 0.69314718, 1.09861229] np.sqrt(a) # [1. , 1.41421356, 1.73205081] -
统计函数:NumPy提供了许多统计函数,如
.mean()、.median()、.std()、.sum()等,用于计算描述性统计量。示例:
a.mean() # 2.0 a.median() # 2.0 a.std() # 1.0 a.sum() # 6 -
矩阵运算:NumPy支持各种矩阵和数组运算,如转置、矩阵乘法等。
示例:
a.T # 转置 np.dot(a, b) # 矩阵乘法
-
-
Scikit-learn库:
-
特征缩放:特征缩放是预处理的重要步骤,可以提高模型的性能和稳定性。
StandardScaler和MinMaxScaler是常用的两种缩放方法,分别用于标准化和归一化。示例:
from sklearn.preprocessing import StandardScaler, MinMaxScaler scaler = StandardScaler() scaled_data = scaler.fit_transform(data) scaler = MinMaxScaler() scaled_data = scaler.fit_transform(data)
-
-
特征选择:通过
SelectKBest、RFE(递归特征消除)等方法可以选择最重要的特征,减少模型的复杂性和过拟合风险。示例:
from sklearn.feature_selection import SelectKBest, chi2 selector = SelectKBest(chi2, k=5) selected_features = selector.fit_transform(X, y) from sklearn.feature_selection import RFE from sklearn.linear_model import LogisticRegression estimator = LogisticRegression() selector = RFE(estimator, n_features_to_select=5) selected_features = selector.fit_transform(X, y)- 特征工程:创建新的特征或者转换现有的特征可以提高模型的性能。这可能包括编码分类变量、提取日期特征、计算交互项等。
最后我们来总结一下:
-
理解数据:在开始分析和可视化之前,充分理解你的数据是非常重要的。这包括了解数据的结构、变量的含义、数据的质量(如是否存在缺失值或异常值)、数据分布、相关性等。
-
实践出真知:理论知识固然重要,但只有通过实际操作才能真正掌握数据分析和可视化的技巧。不断练习和实验可以帮助你更好地理解和应用各种方法,同时也能发现并解决实际问题。
-
选择合适的工具:Python提供了许多库用于数据分析和可视化,如Pandas、NumPy、Matplotlib、Seaborn、Scikit-learn等。根据你的具体需求选择最合适的工具可以使工作更有效率。
-
可视化的重要性:良好的可视化不仅可以帮助你更好地理解数据,也可以有效地传达你的发现给他人。因此,花时间学习和实践如何创建有效的可视化是非常值得的,包括选择合适的图表类型、颜色、标签、标题等。
-
持续学习:数据分析和可视化是一个不断发展和变化的领域,新的方法和技术不断出现。保持学习和更新知识的习惯可以帮助你保持竞争力,例如关注相关的博客、书籍、在线课程和社区。
-
问题导向:在进行数据分析时,始终明确你的目标和问题是什么。这将帮助你专注于最重要的任务,并确保你的分析和可视化能够提供有价值的见解。同时,也要注意避免过度解读数据和假设检验的重要性。















 1250
1250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









