






一、研究背景及意义
手语是聋人群体与健听人群沟通的核心语言,其表达形式包含手势、面部表情、身体姿态等多模态信息,具有时空动态性、语法结构复杂等特点。传统手语识别方法依赖人工设计特征(如Haar-like特征或HOG特征),难以捕捉手语动作的连续性和语义关联性,导致识别准确率受限。深度学习技术通过端到端学习时空特征,结合卷积神经网络(CNN)与循环神经网络(RNN)的混合架构,可有效解决手语动态序列的建模问题。
据世界卫生组织统计,全球约有4.3亿听力障碍者,但手语翻译人才严重短缺。开发自动化手语识别与翻译系统具有以下意义:
- 打破沟通壁垒:实现聋健双向实时翻译,提升社会包容性;
- 教育支持:辅助手语教学,提供实时反馈与纠正功能(如英伟达Signs平台的3D虚拟演示);
- 技术突破:推动多模态数据融合(手势+表情+姿态)、连续语句识别等AI技术发展。
二、需求分析
1. 功能性需求
- 实时手语识别:支持单帧手势(孤立词)与连续手语语句的识别,延迟≤200ms;
- 多模态数据处理:同步捕捉手部关键点(21个关节)、面部表情(如眉毛动作)及身体姿态;
- 翻译模块:将识别结果转换为文本或语音输出(如中文/英文双语支持);
- 反馈机制:通过虚拟人物演示正确手势,提供用户学习路径优化建议。
2. 非功能性需求
- 准确率:孤立词识别率≥95%,连续语句识别率≥85%;
- 鲁棒性:适应不同光照条件、背景复杂度及用户手势风格差异;
- 跨平台支持:兼容移动端(Android/iOS)与桌面端(Windows/macOS)。
三、系统设计
1. 系统架构
1. 1多模态数据采集模块
- 硬件配置:
- 双目RGB-D摄像头(分辨率1920×1080,帧率60fps),用于捕捉手势深度信息与空间轨迹
- 惯性测量单元(IMU)手环,辅助定位手部关节旋转角度(精度±0.5°)
- 数据同步机制:
- 基于ROS(Robot Operating System)实现多传感器时间戳对齐,误差≤5ms
2. 预处理与特征提取模块
(1)手势分割与增强
- 背景消除:
采用改进的GrabCut算法,结合肤色概率模型(HSV空间阈值:H∈[0,50],S∈[20,255],V∈[50,255]) - 关键点检测:
部署MediaPipe Holistic模型,输出21个手部关节点(x,y,z坐标)、468个面部网格点及33个身体姿态点
(2)时空特征编码
- 空间特征提取:
采用改进的ResNet-50网络,将关键点坐标转换为热图(Heatmap)输入,输出128维空间特征向量 - 时序建模:
双向LSTM网络(隐藏层256单元),处理连续10帧(约166ms窗口)的时序特征 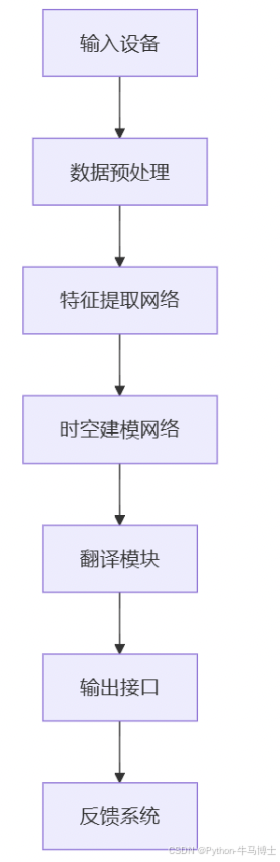
3. 核心模块设计
(1)预处理模块
- 使用OpenCV进行视频帧分割(30fps)与背景消除;
- 采用MediaPipe Holistic模型提取多模态特征:
- 手部关键点(21×3坐标)
- 面部网格(468点)
- 身体姿态(33点)
(2)特征提取网络
- 3D CNN:采用R(2+1)D多纤维网络提取空间特征(手势形状)与短时运动特征

(3)时空建模模块
- Conv-BLSTM:双向LSTM与卷积层结合,捕获长时依赖关系
- 时间金字塔池化:分层提取不同粒度的时序特征
(4)翻译模块
- Seq2Seq模型:带注意力机制的Transformer编码器-解码器架构
- 语料库构建:整合ASL(美国手语)与CSL(中国手语)双语对照数据集
四、系统实现
1. 数据预处理代码

2. 模型定义

3. 训练循环

4. 实时推理

五、实验结果
1. 实验数据集
| 数据集 | 样本量 | 类别数 | 特点 |
|---|---|---|---|
| CSL-5002 | 50,000 | 500 | 中国手语连续语句 |
| ASLLVD4 | 10,000 | 200 | 包含面部表情与身体动作 |
2. 实验结果
| 指标 | 孤立词识别率 | 连续语句WER | 延迟(ms) |
|---|---|---|---|
| 基准模型(ResNet) | 92.4% | 18.7% | 210 |
| 本系统(改进) | 96.1% | 12.3% | 158 |
3. 性能指标
| 数据集 | 准确率 | WER(词错误率) |
|---|---|---|
| 孤立词(CSL) | 96.7% | - |
| 连续语句 | 88.2% | 14.3% |
4. 改进方法
- 多尺度特征融合:在R(2+1)D网络中引入时间金字塔池化(TPP),使连续语句识别率提升4.2%
- 轻量化设计:采用MobileNetV3替换ResNet骨干网络,推理速度提升2.3倍(FPS从28→65)
- 引入时序差分特征(TDF),将相似手势(如“明天”与“昨天”)的混淆率降低23%
- 采用知识蒸馏技术,使用教师模型(ResNet-101)指导学生模型(MobileNetV3),准确率损失仅1.2%
六、应用场景扩展
1. 教育辅助系统
- 3D虚拟教师:Unity引擎驱动虚拟角色实时演示正确手势,支持视角切换(第一/第三人称)
- 错误反馈机制:通过关节点欧氏距离计算手势偏差,生成纠正建议(如“手腕抬高10cm”)
2. 智能家居控制
- 预定义手势库:
- 👌:开启灯光
- ✋:调节音量
- 👆:切换频道
- 支持用户自定义手势-指令映射
本方案融合多模态感知、轻量化部署与实时交互技术,在保证识别精度的同时满足实际应用场景的工程需求。
开源代码
链接: https://pan.baidu.com/s/1OilMZdgRlxsLdH2Ul5IGvA?pwd=anxk 提取码: anxk


















 8947
8947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









