






零、写在前面
本文用于记录“书生·浦语大模型全链路开源开放体系”的有关信息。
一、大模型现状
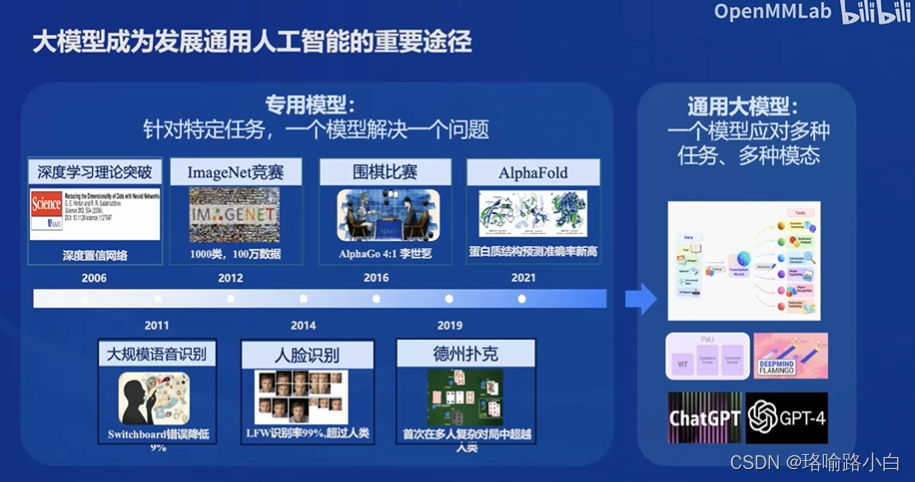
- 大模型是发展通用人工智能的关键途径。
- 过去智能集中在专用模型解决特定问题,现在大模型能应对多种任务和模态。
二、书生浦语大模型开源历程及现状
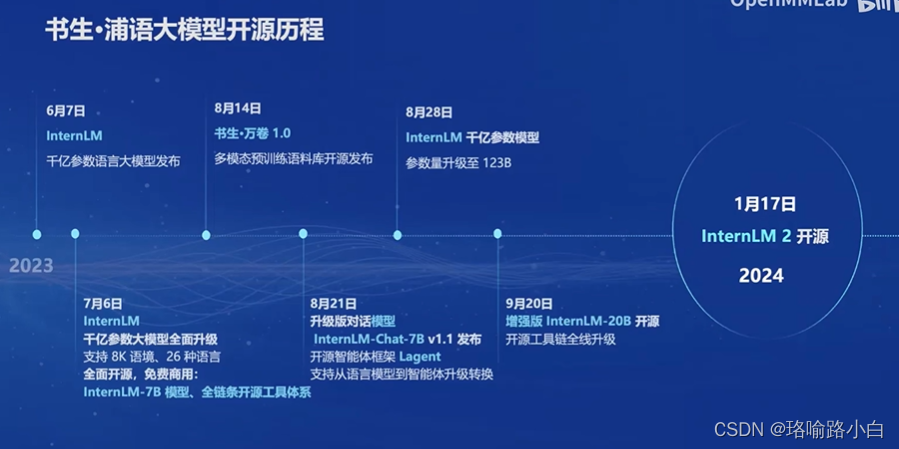
- 书生浦语大模型自6月7日起经历了多次更新和开源。
- 包括多模态预训练语料库的发布和参数量升级至123B的InternLM。
- InternLM2是书生浦语2.0的版本,它在多个能力方向进行了强化,并在评测中表现优异。
三、InternLM2体系
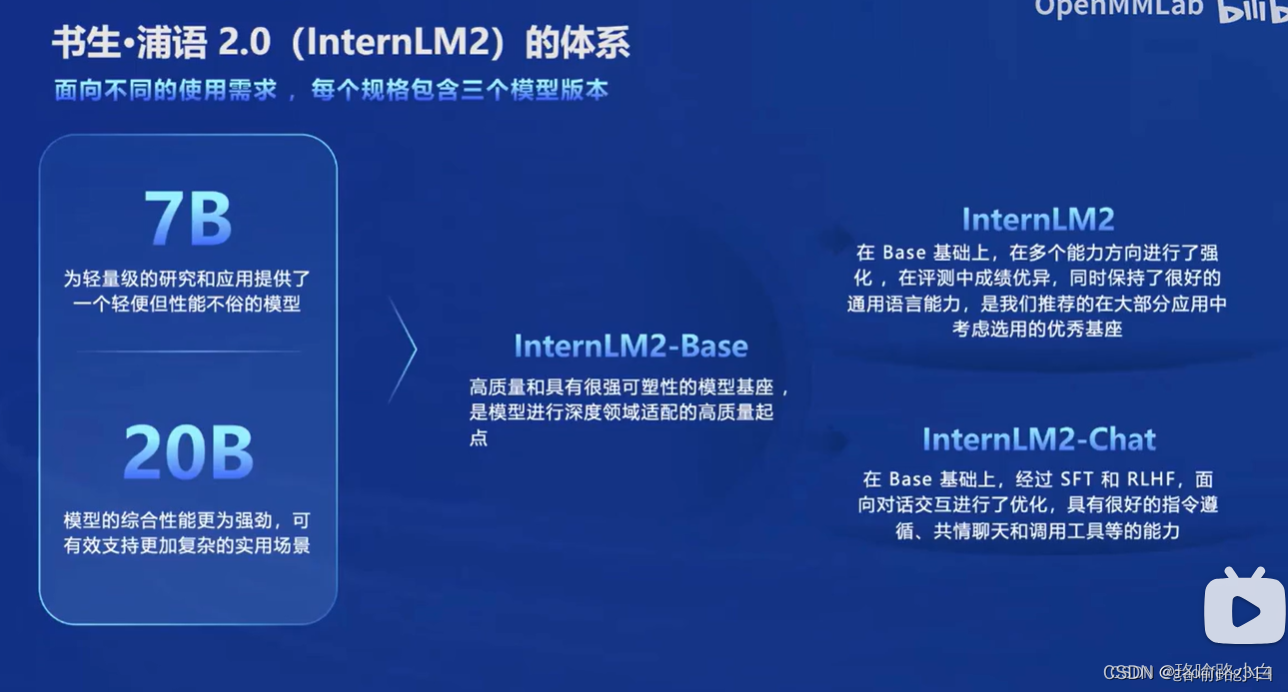
- InternLM2-Base:高质量、强可塑性的模型基座,适合深度领域适配。
- InternLM2:在Base基础上强化多个能力方向,保持通用语言能力。
- InternLM2-Chat:针对对话交互优化,具备指令遵循、共情聊天等能力。
四、InternLM2技术亮点
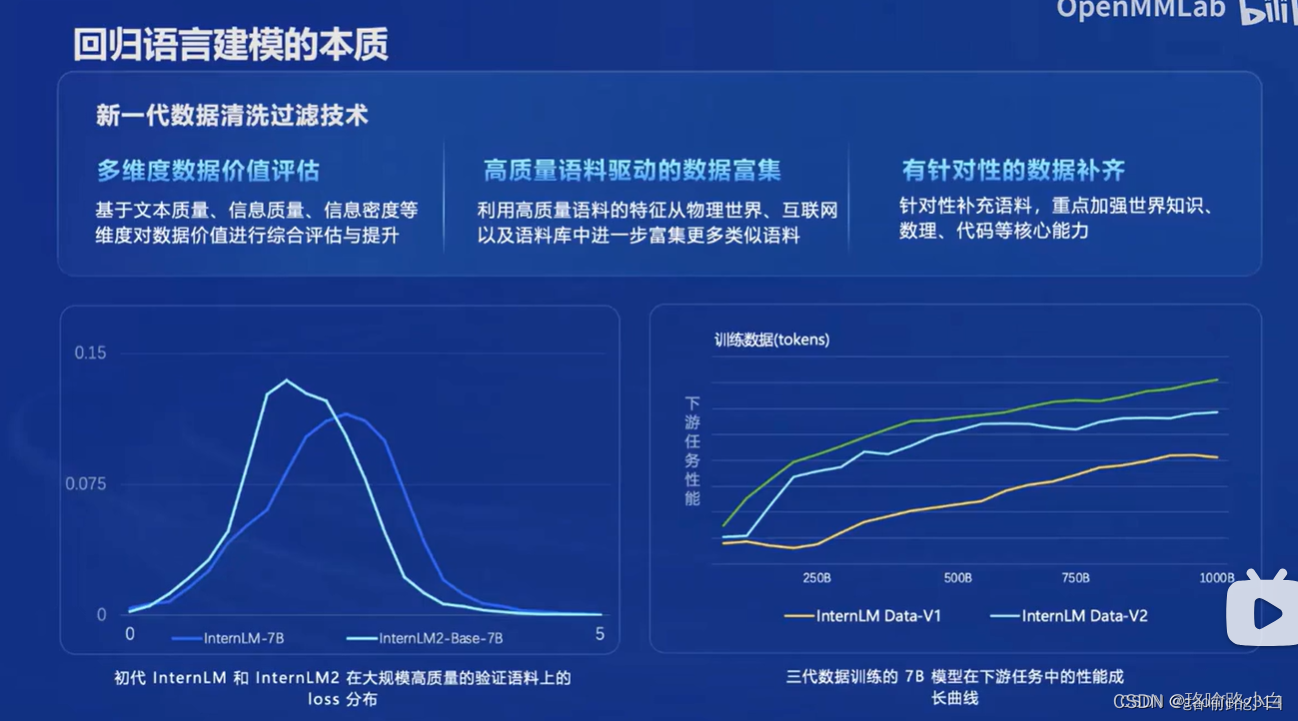
- 回归语言建模本质,采用新一代数据清洗过滤技术。
- 多维度数据价值评估,高质量语料驱动的数据富集。
- 有针对性的数据补齐,加强数理、代码等核心能力。
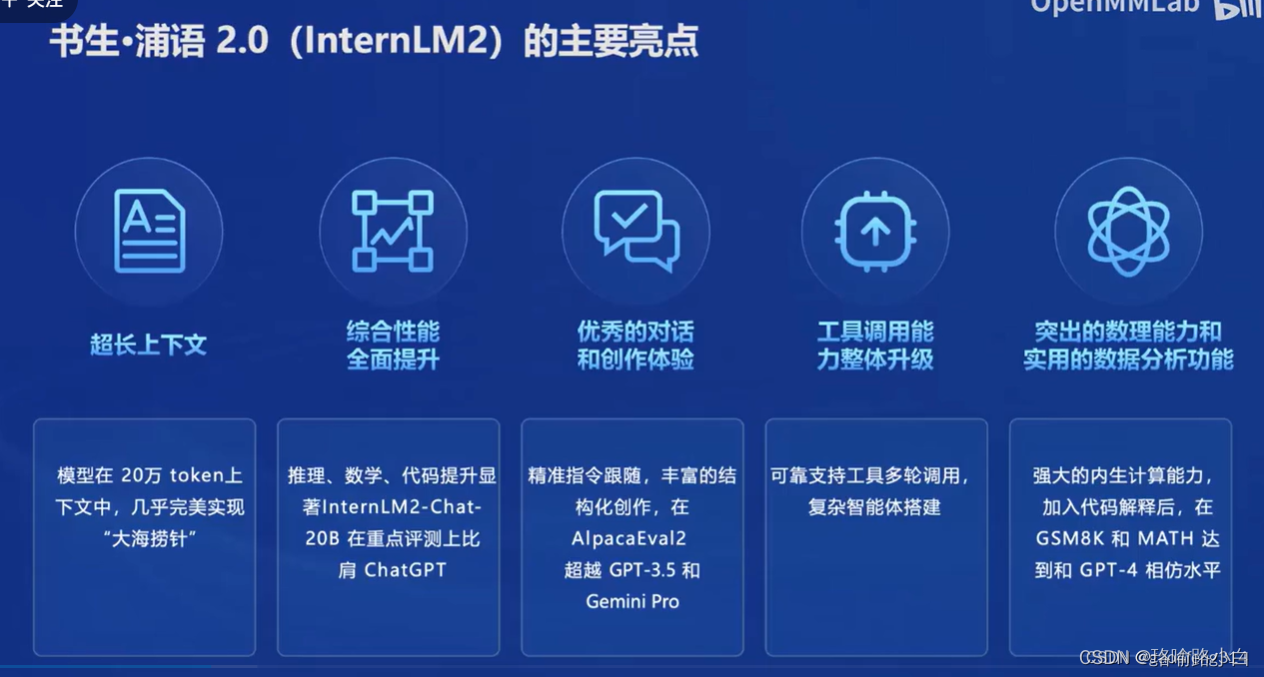
五、实用功能
- InternLM2升级了模型工具调用能力,能完成复杂任务。
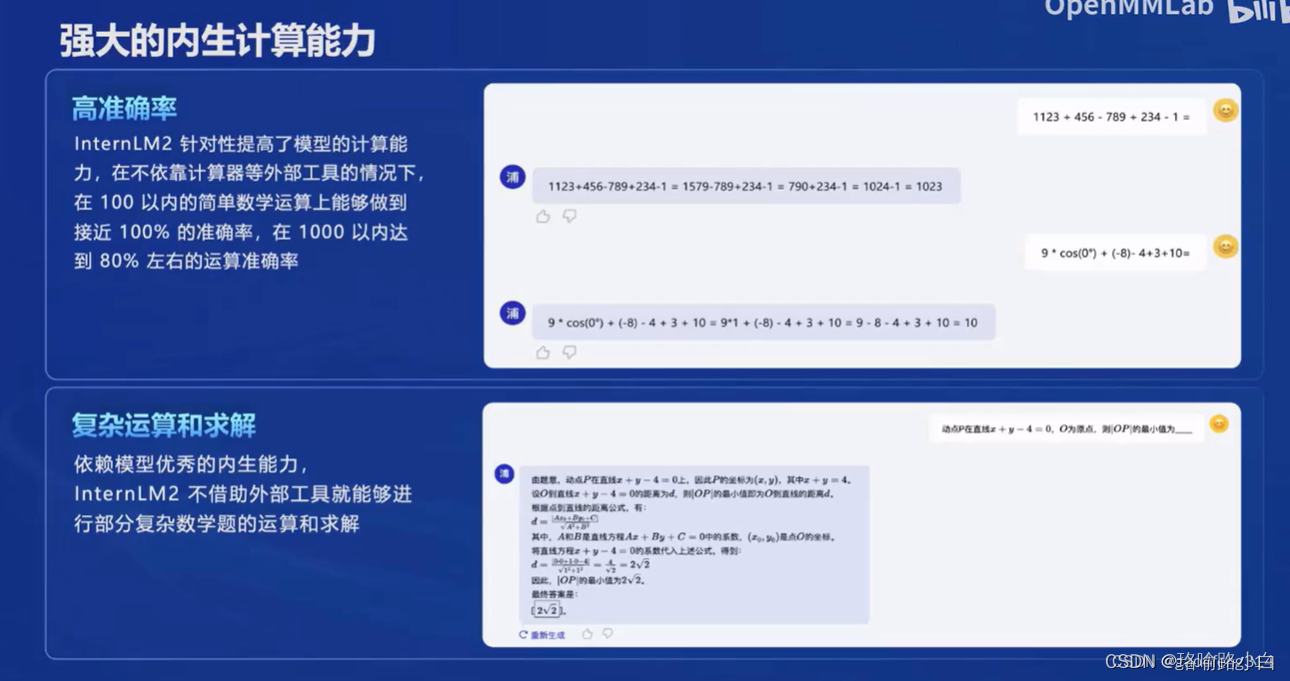
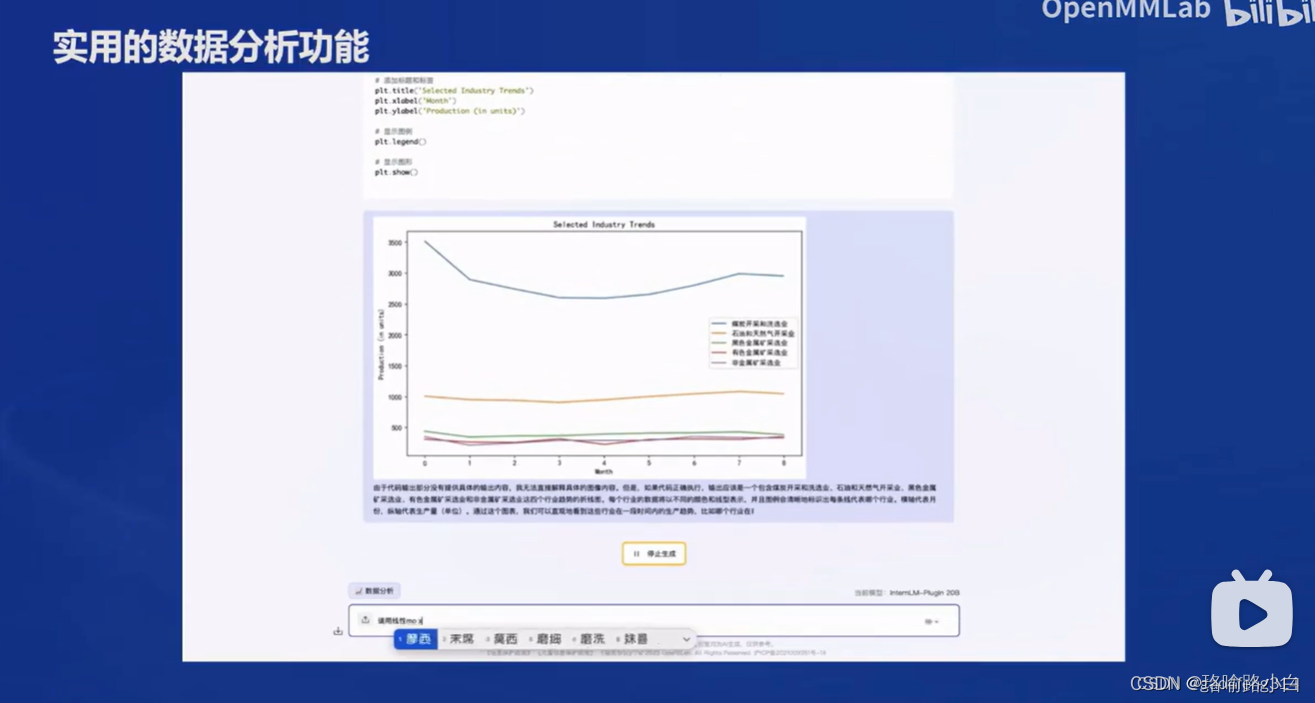
- 具有内生计算能力和实用的数据分析功能。


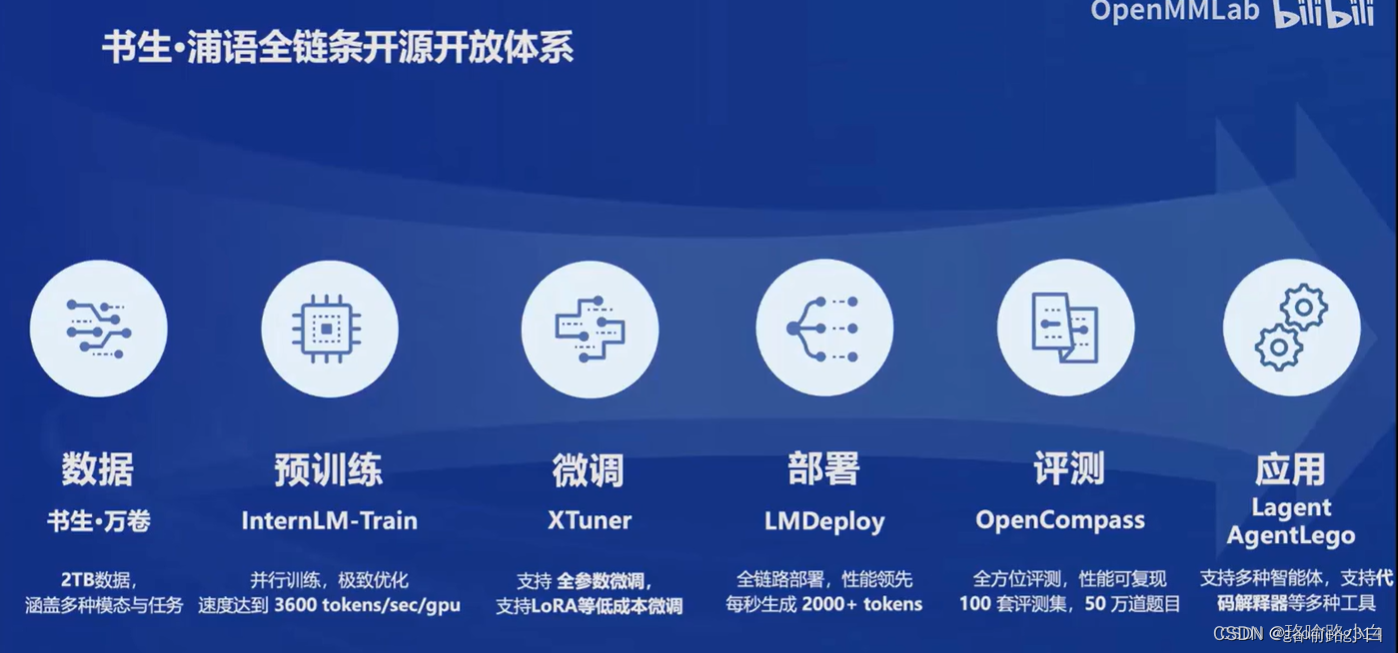
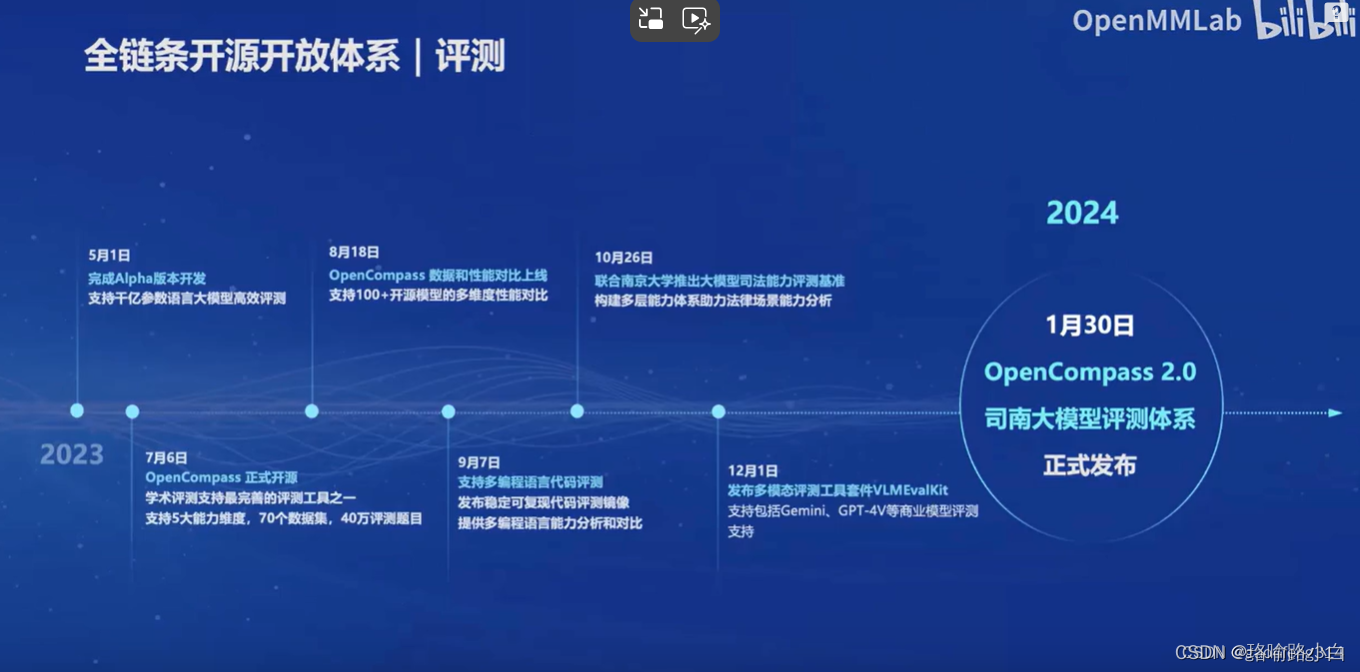
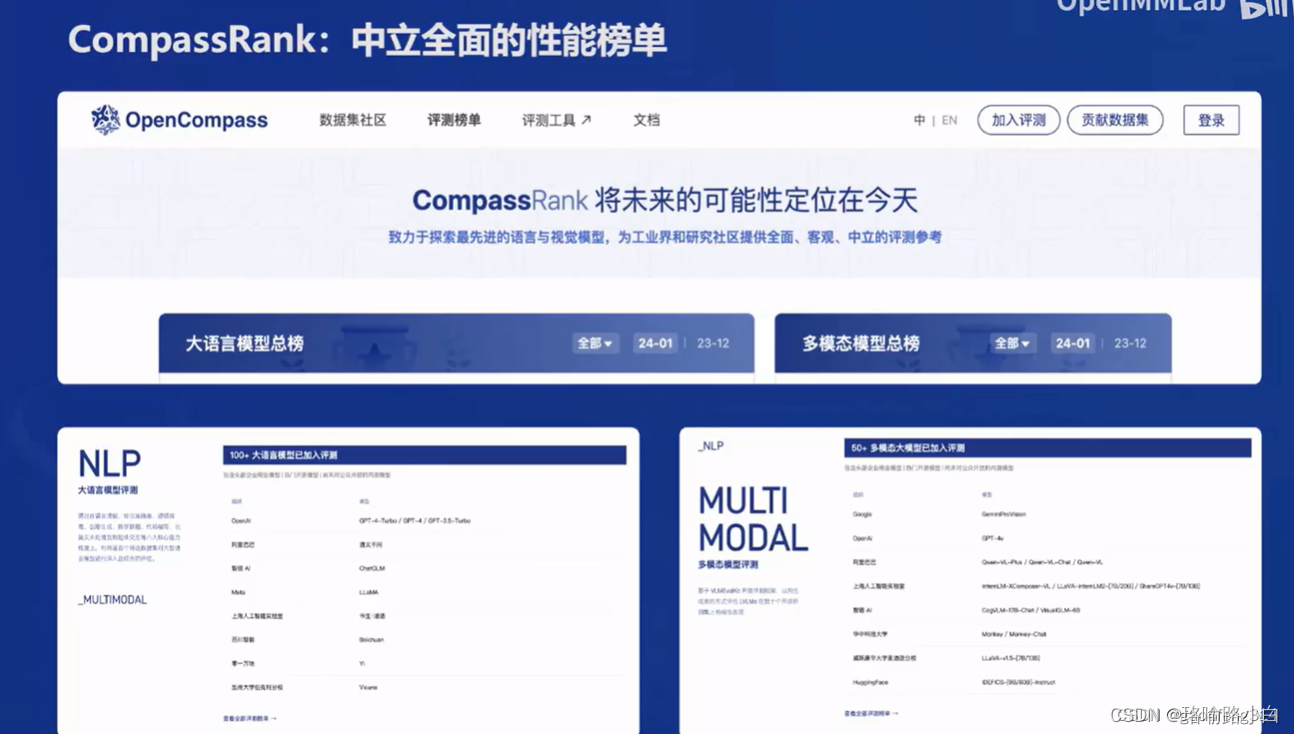
六、全链条开源开放体系
- 高质量语料数据,8G显存可微调7B模型。
- 获得Meta官方推荐的国产大模型评测体系。




七、技术报告笔记
- InternLM2是一个开源的大型语言模型,克服了性能和实用性局限。
- 在长上下文建模和开放式主观评估方面取得显著进展。
- 使用InternEvo框架训练,支持多种并行化策略和GPU内存优化技术。

八、数据收集处理方法
- 报告指出文本数据主要来自网页、书籍、技术文献等。
- 通过多阶段过滤获得高质量预训练数据。
- 长上下文数据通过特定步骤处理确保质量。
九、对齐阶段技术
- 使用监督微调(SFT)和条件在线人类反馈强化学习(COOL RLHF)。
- COOL RLHF引入条件奖励模型,避免奖励操纵行为。
十、总结
- InternLM2通过创新的预训练和优化技术,在多个维度和基准测试中表现优异。
- 开放不同训练阶段和模型大小的模型,为社区提供了分析模型演变的资源。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









