






简介
Filebeat是一个轻量级的日志收集工具,主要用于转发和集中服务器、虚拟机和容器生成的日志数据。它属于Elastic Stack(通常称为ELK Stack)的一部分,是Beats家族的一员。
Filebeat的工作原理是通过Harvester逐行读取指定的日志文件或位置,并将收集到的日志事件转发到Elasticsearch或Logstash进行索引。Filebeat由两个主要组件组成:prospector和harvesters。Prospector负责发现和监控日志文件,而Harvesters则负责读取这些文件的内容并将其发送到输出目标。
Filebeat具有多种内置模块,这些模块可以简化常见格式日志的收集、解析和可视化过程。例如,它内置了Apache、Cisco ASA、Microsoft Azure、Nginx和MySQL等模块,只需一条命令即可完成日志的收集和处理。此外,Filebeat还支持自定义日志字段,以满足特定需求。
Filebeat的优势在于其轻量级特性,它基于Go语言开发,无任何依赖,因此不会对生产机器带来过高的资源占用。这使得Filebeat非常适合安装在各种服务器上,以实现高效、可靠的日志管理。
在实际应用中,Filebeat经常用于经典的EFK(Elasticsearch、Fluentd、Kibana)架构中,作为前端收集日志的组件,将日志传给Kafka,然后由Logstash从Kafka中读取并处理。Filebeat也可以直接对接Elasticsearch、Logstash、Kafka和Redis等目标存储库。
总之,Filebeat提供了一种简单而高效的方式来收集和转发日志数据,适用于大规模日志管理场景,并且通过其丰富的模块和灵活的配置选项,能够满足不同用户的需求
Filebeat 传输数据到 Elasticsearch 的步骤相对直接,但确实可能会遇到一些问题。以下是传输步骤和可能遇到的问题的概述:
Filebeat 传输到 Elasticsearch 的步骤:
-
安装 Filebeat:
-
在需要传输日志的服务器上下载并安装 Filebeat。
elasticsearch![]() https://scn1p2vbv13p.feishu.cn/wiki/EyLBwKMxWiQiXPkvjZochIHxnBh?from=from_copylink
https://scn1p2vbv13p.feishu.cn/wiki/EyLBwKMxWiQiXPkvjZochIHxnBh?from=from_copylink
-
配置 Filebeat:
-
编辑
filebeat.yml配置文件,设置输入(inputs)、输出(output)、处理器(processors)等。
安装Filebeat
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.x.y-linux-x86_64.tar.gz
tar xzvf filebeat-7.x.y-linux-x86_64.tar.gz
cd filebeat-7.x.y-linux-x86_64/
配置Filebeat
cat > filebeat.yml <<EOF
filebeat.inputs:
-
type: log
paths:
-
/path/to/your/logfile.log
output.elasticsearch:
hosts: ["http://localhost:9200"]
-
定义 Inputs:
-
在配置文件中定义需要收集的日志文件的位置和类型。
-
设置 Elasticsearch 输出:
-
在
output.elasticsearch部分配置 Elasticsearch 的连接信息,包括主机地址、端口、索引名称等。
-
可选 - 配置 ILM:
-
如果你使用 ILM 来管理索引,确保配置了 ILM 和索引模板。
-
启动 Filebeat:
-
保存配置文件并启动 Filebeat 服务。
-
验证配置:
-
检查 Filebeat 的日志输出,确认没有错误,并且数据正在传输到 Elasticsearch。
-
监控:
-
使用 Kibana 的 Discover 功能查看数据是否正确地出现在 Elasticsearch 中。
可能出现的问题:
-
连接问题:
-
Filebeat 无法连接到 Elasticsearch。
-
确保 Elasticsearch 服务正在运行并且可以被 Filebeat 服务器访问。
-
-
配置错误:
-
配置文件语法错误或者配置参数不正确。
-
仔细检查
filebeat.yml文件的配置。
-
-
权限问题:
-
Filebeat 没有足够的权限读取日志文件或者写入 Elasticsearch。
-
确保 Filebeat 有适当的文件读取权限和 Elasticsearch 的写入权限。
-
-
索引问题:
-
索引名称配置错误,导致无法写入数据。
-
检查
output.elasticsearch.index配置项是否正确。
-
https://jiangxl.blog.csdn.net/article/details/117730085?fromshare=blogdetail&sharetype=blogdetail&sharerId=117730085&sharerefer=PC&sharesource=m0_74342244&sharefrom=from_link
-
别名和模板冲突:
-
使用的索引别名与现有别名冲突。
-
检查 Elasticsearch 中的现有别名和索引模板配置。
-
-
ILM 配置问题:
-
如果使用 ILM,策略配置错误可能导致索引未按预期滚动。
-
检查 ILM 策略和索引模板配置。
-
-
数据丢失或不完整:
检测步骤
 https://scn1p2vbv13p.feishu.cn/wiki/D6FYwGBlHiV6YoknU1IcYgMVn8e
https://scn1p2vbv13p.feishu.cn/wiki/D6FYwGBlHiV6YoknU1IcYgMVn8e-
日志数据在传输过程中丢失或不完整。
-
检查 Filebeat 的日志输出和 Elasticsearch 的索引状态。
-
# 查看现有的索引模板 GET /_cat/templates # 查看索引下的文档 GET /log-2024.09.28-000030/_search { "query": { }
-
处理器错误:
-
处理器(如 dissect、json、drop_event)配置错误可能导致数据格式不正确。
-
测试并验证处理器配置以确保数据被正确处理。
-
-
版本不兼容:
-
Filebeat 和 Elasticsearch 版本不兼容。
-
确保 Filebeat 版本与 Elasticsearch 版本兼容。
-
-
资源限制:
-
Filebeat 服务器资源不足(CPU、内存、磁盘空间)。
-
监控服务器资源使用情况并根据需要进行扩展。
-
-
安全设置:
-
如果 Elasticsearch 配置了安全设置(如 SSL、认证),Filebeat 需要相应配置以连接。
-
确保 Filebeat 的配置文件中包含了必要的安全设置。
-
-
网络问题:
-
防火墙或网络配置可能阻止 Filebeat 与 Elasticsearch 的通信。
-
检查网络设置和防火墙规则。
-
解决步骤
-
看filebeat服务是否成功启动:
使用 systemctl(推荐方式): 如果你的系统使用 systemctl 来管理服务(如较新的 Ubuntu、Debian、CentOS 等版本),你可以使用以下命令来检查 Filebeat 服务的状态:
sudo systemctl status filebeat
这个命令会显示 Filebeat 服务的当前状态,包括它是否正在运行、日志条目、以及任何可能的错误信息。
使用 service 命令: 在一些旧的 Linux 发行版中,你可能需要使用 service 命令:
sudo service filebeat status
-
看filebeat是否成功监听到服务:
-
在日志中,查找与 inputs 相关的条目,看是否有关于成功监控文件的记录。如果 Filebeat 没有成功监控到文件,可能会有错误或警告信息。
#在filebeat项目的log文件下 查找: ll
# 或者 在终端中查找 tail -f /var/log/filebeat/filebeat.log
-
检查 Filebeat 配置
检查 filebeat.yml 配置文件中定义的 inputs 是否正确指向了你想要监控的文件或服务。例如,如果你想要监控一个日志文件,确保 paths 设置正确:
# filebat.yaml filebeat.inputs: - type: logenabled: true paths: - /path/to/your/logfile.log
检查文件权限
确保 Filebeat 服务有权限访问其配置文件中指定的文件或目录。权限不足可能会导致 Filebeat 无法读取文件。
重启 Filebeat
-
看filebeat 是否将日志成功传输到es中:
1.查看 Filebeat 日志
查看 Filebeat 的日志文件以确认其是否报告了与 Elasticsearch 通信的任何错误。
tail -f /var/log/filebeat/filebeat.log
2.检查 Elasticsearch
直接检查 Elasticsearch 确认数据是否已经到达。
-
检查 Elasticsearch 中的索引: 使用 Kibana 的 “Dev Tools” 或 curl 命令查看 Elasticsearch 中是否存在 Filebeat 发送的数据。
-
例如,使用 curl:
curl -X GET "http://localhost:9200/_cat/indices?v"
-
这个命令会列出所有的索引,你应该能够看到你的 Filebeat 索引(例如
filebeat-*)。
3.查询 Elasticsearch:
使用一个简单的查询来检查索引中是否有数据。
-
例如,使用 Kibana 的 “Dev Tools” 或 curl 命令:
curl -X GET "http://localhost:9200/filebeat-*/_search?pretty&q=*"
-
这个命令会返回索引
filebeat-*下的所有数据文档。
4. 检查 Elasticsearch 的日志
如果 Filebeat 日志显示数据已发送,但查询不到数据,可以检查 Elasticsearch 的日志文件。
-
Elasticsearch 日志: 日志文件通常位于
/usr/share/elasticsearch/logs/。 -
查看 Elasticsearch 的日志,确认 Filebeat 发送的数据是否被索引。
-
看kibana是否成功显示出相关es服务内容:
选择索引模式
在 Discover 视图的顶部,有一个 “Index pattern” 下拉选择器。选择你想要查看的索引模式。如果你是通过 Filebeat 发送数据,索引模式可能类似于 filebeat-*。
解决这些问题通常需要检查配置文件、查看日志文件、测试网络连接和权限设置。如果问题依然存在,你可能需要查看 Elasticsearch 的日志文件以获取更多线索。
若存在无法更改索引等问题
更改版本
https://metaso.cn/search/8528386443677478912?q=filebeat%E7%89%88%E6%9C%AC%E9%9C%80%E8%A6%81%E8%B7%9Fes%E7%89%88%E6%9C%AC%E4%B8%80%E8%87%B4%E5%90%97
用了其他的版本,就可以了
由于版本问题,可能set.ilm.enable:auto会让auto改成true、false
之前改true或false是因为版本不兼容auto
现在用了之前的版本,就可以用auto了
setup.ilm.enabled设置为true的时候
索引名称只能为filebeat开头

-
在
filebeat.yml配置文件中,字段标签用于定义Filebeat的行为和日志处理逻辑。以下是一些常见配置项的含义、作用以及用法,包括具体的例子。
1. Processors (处理器)
processors定义了处理日志事件的处理器链。
例子:
processors: - dissect: when: equals: fields.log_source: "xxx" tokenizer: '{"level":"info","{\"xxx\":\"%{xxx}\",\"xxx\":\"%{xxx}\",\"xxx\":%{xxx},\"price_type\":\"%{price_type}\",\"message\":\"%{msg}\",}}","service":"user-service","xxx":"%{xxx}"}' field: message target_prefix: '' overwrite_keys: true
-
dissect: 使用dissect处理器拆分日志行。 -
when: 条件判断,仅当fields.log_source等于vip时执行。 -
tokenizer: 定义了如何拆分日志行。并且通过固定的格式对字段信息进行匹配解析 -
field: 指定要拆分的字段是message。 -
target_prefix: 新字段的前缀,这里为空。 -
overwrite_keys: 是否覆盖已有字段。
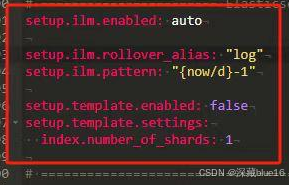
2. ILM (索引生命周期管理)
setup.ilm定义了Elasticsearch索引的生命周期管理设置。
例子:
setup.ilm.enabled: auto setup.ilm.rollover_alias: "log" setup.ilm.pattern: "{now/d}-1"
-
enabled: auto: 自动管理索引生命周期。 -
rollover_alias: "log": 定义滚动别名为log。 -
pattern: "{now/d}-1": 定义索引模式,每天滚动一次。
3. Index Template (索引模板)
setup.template定义了Elasticsearch索引模板的设置。
例子:
setup.template.enabled: false setup.template.settings: index.number_of_shards: 1
-
enabled: false: 禁用自动索引模板设置。 -
settings: 定义索引的设置,例如分片数。
4. Modules (模块)
filebeat.config.modules定义了Filebeat模块的配置路径和是否启用自动重载。
例子:
filebeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: false
-
path: 指定模块配置文件的路径。 -
reload.enabled: false: 禁用自动重载模块配置。
5. Inputs (日志输入)
filebeat.inputs定义了Filebeat监控的日志文件的位置和相关的行为。
例子:
- type: log enabled: true tail_files: true paths: - /www/wwwroot/xxx/xxx.log include_lines: # 包含包含特定关键词的行 - 'xxx' fields: log_source: "xxx"
-
type: log: 指定输入的类型是日志文件。 -
enabled: true: 启用这个输入。 -
tail_files: true: 继续监控新追加到文件末尾的内容。 -
paths: 指定日志文件的路径。 -
include_lines: 包含包含特定关键词的行。使得只有具备关键字的信息才会被自定义字段log_source调用processors: - dissect:进行解析匹配 -
fields: 添加自定义字段log_source,值为xxx。
6. Fields (字段)
fields用于给日志事件添加额外的信息。
例子:
fields: log_source: "xxx"
-
fields: 自定义字段,log_source表示日志来源,这里标记为xxx。
7. Tags (标签)
tags用于对事件进行分类。
例子:
fields: tags: ["production", "webserver"]
-
tags: 添加标签production和webserver,用于分类和过滤。
8. Drop_fields (删除字段)
drop_fields用于从日志事件中删除指定的字段。
例子:
- drop_fields: fields: ["status_code", "http_version", "user_agent"] ignore_missing: true
-
drop_fields: 删除status_code、http_version和user_agent字段。 -
ignore_missing: 如果字段不存在,则不执行任何操作。
9. Drop_event (丢弃事件)
drop_event用于丢弃符合特定条件的日志事件。
例子:
- drop_event: when: regexp: message: "rsp msg"
-
drop_event: 如果message字段匹配正则表达式rsp msg,则丢弃该事件。
这些配置项使Filebeat成为一个灵活的日志收集工具,能够满足各种日志处理需求。

















 1957
1957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









