







***接上一篇博客:C++指针***
十九、动态分配内存
19.1 C++内存模型
C++的内存模型可以简单描述为包括四个主要的区域:栈区、堆区、全局区(数据段)和程序代码区(代码段)。
1.栈区(Stack): 栈区是由编译器自动管理的内存区域,用于存储函数调用的上下文信息、局部变量和函数参数等。栈区的分配和释放速度非常快,遵循先进后出(LIFO)原则。栈区的大小是有限的,由编译器设置,默认情况下栈区大小在几MB到几GB之间。
2.堆区(Heap): 堆区是由开发人员手动分配和释放的内存区域,用于存储动态分配的变量、对象等。堆区的分配和释放需要使用特定的操作符,如`new`和`delete`。堆区的大小比较大,一般要比栈区大得多。在堆区中,变量的生命周期不受函数的限制,即可以在函数外部使用。 3.全局区(Data Segment): 全局区用于存储全局变量、静态变量和常量等,在程序运行期间始终存在。全局区的变量可以在程序的任何位置访问。全局变量和静态变量都保存在全局区中,静态变量的生命周期延长到整个程序的运行期间。
4.程序代码区(Code Segment): 程序代码区存放着程序的执行代码,包括所有的函数和操作指令。程序代码区是只读的,不允许对其进行写操作。 此外,还有一些其他的内存区域,如常量区、字符串字面量区等,它们用于存储常量和字符串字面量等。 需要注意的是,不同的编译器和操作系统对内存模型的实现可能存在细微的差异,上述描述仅为一般情况下的内存模型概述。在实际编程中,需要根据具体的编译器和操作系统的规范来合理地使用内存。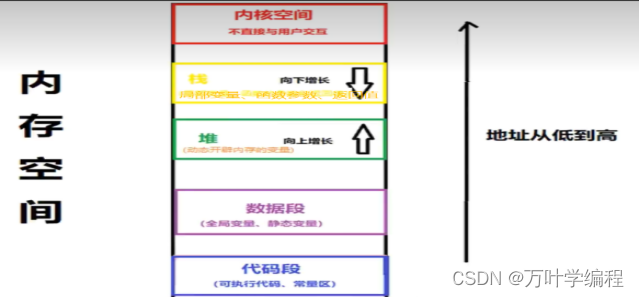
栈和堆的主要区别:
1)管理方式不同: 栈是编译器自动管理的,在出作用域时,将自动被释放,堆需手动释放,若程序中不释放,程序结束时由操作系统回收。
2)空间大小不同: 堆内存的大小受限于物理内存空间,而栈就小得可怜,一般只有 8M(可以修改系统参数)。
3)分配方式不同: 堆是动态分配;有静态分配和动态分配(都是自动释放)。
4)分配效率不同: 栈是系统提供的数据结构,计算机在底层提供了对栈的支持,进栈和出栈有专门的指令,效率比较高;堆是由 C++函数库提供的。
5)是否产生碎片: 进栈和出栈都有着严格的顺序(先进后出),不会产生碎片,而堆频繁的分配和释放,会造成内存空间的不连续,容易产生碎片,太多的碎片会导致性能的下降。
6)增长方向不同: 栈向下增长,以降序分配内存地址,堆向上增长,以升序分配内存地址。
19.2 动态分配内存new和 delete
使用堆区内存的有四个步聚:
1)声明一个指针;
2)用new运算符向系统申请一块内存,让指针指向这块内存;
3)通过对指针解引用的方法,像使用变量一样使用这块内存;
4)如果这块内存不用了,用 delete 运算符释放它;
申请内存的语法:new 数据类型(初始值);// C++11 支持{}
如果申请成功,返回一个地址,如果申请失败,返回一个空地址(暂时不考虑失败的情况)。
释放内存的语法: delete 地址
注意:
·动态分配出来的内存,没有变量名,只能通过指向它的指针来操作内存中的数据。
·如果动态分配的内存不用了,必须用 delete 释放它,否则有可能用尽系统的内存。
·动态分配的内存生命周期与程序相同,程序退出时,如果没有释放,系统将自动回收。
·就算指针的作用域已失效,所指向的内存也不会释放。
·用指针跟踪已分配的内存时,不能跟丢。
二十、数组
数组是一组数据类型相同的变量,可以存放一组数据。
20.1 一维数组
1)创建数组
声明数组的语法:数据类型 数组名[数组长度]
注意:数组长度必须是整数,可以是常量,也可以是变量和表达式。
C90规定必须用常量表达式指明数组的大小,C99允许使用整型非常量表达式。经测试,在VS中可以用整型非常量表达式,不能用变量,但是,Linux 中还可以用变量。
2)数组的使用
可以通过下标访问数组中元素,数组下标从0开始。
数组中每个元素的特征和使用方法与单个变量完全相同。
语法:数组名 [数组下标]
注意:
·数组下标也必须是整数,可以是常量,也可以是变量。
·合法的数组下标取值是: 0~(数组长度-1)。
3)数组占用内存的情况
数组在内存中占用的空间是连续的。
用sizeof(数组名)可以得到整个数组占用内存空间的大小(只适用于C++基本数据类型)
4)数组的初始化
声明的时候初始化:
数据类型 数组名[数组长度] =[ 值 1,值 2 ...}
数据类型 组名[] =[ 值 1,值 2 ...}:
数据类型 数组名[数组长度] = { 0 }; // 把全部的元素初始化为 0。
注意:
如 {} 内不足数组长度个数据,剩余数据用0补全,但是,不建议这么用,你可能在数组中漏了某个值。如果想把数组中全部的元素初始化为0,可以在0内只填一个0或什么也不填。
5)清空数组
用memset()函数可以把数组中全部的元素清零。 (只适用于C++基本数据类型)
函数原型:void * memset ( void * ptr, int value, size_t num );(num是字节数)
注意,使用memcpy()函数需要包含头文件#include <string.h>
例:
#include<iostream>
#include<string>
using namespace std;
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
memset(arr, 0, 40);//重置数组的各个元素
for (int i = 0; i < 10; i++)
{
cout << arr[i]<<"\n";
}
return 0;
}6)复制数组
用 memcpy{}函数可以把数组中全部的元素复制到另一个相同大小的数组。 (只适用于 C++基本数据类型)
函数原型:void * memcpy ( void * destination, const void * source, size_t num );
#include<iostream>
#include<string.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };//原始数组
int a[10] = { 0 };//
memcpy(a, arr, 100);
for (int i = 0; i < 10; i++)
{
std::cout << a[i]<<"\n";
}
return 0;
}
20.2 一维数组和指针
1)指针的算术
将一个整型变量加1后,其值将增加 1。
但是,将指针变量(地址的值)加1后,增加的量等于它指向的数据类型的字节数。
2)数组的地址
a)数组在内存中占用的空间是连续的;
b) C++将数组名解释为数组第0个元素的地址;
c)数组第0个元素的地址和数组的首地址取值是相同的;
d)数组第n个元素的地址是:数组首地址+n
e) C++编译器把 数组名[下标] 解释为 *(数组首地址+下标)
3)数组的本质
数组是占用连续空间的一块内存,数组名被解释为数组第0个元素的地址。
C++操作这块内存有两种方法:数组解释法和指针表示法,它们是等价的。
4)数组名不一定会被解释为地址
在多数情况下,C++将数组名解释为数组的第0个元素的地址,但是,将 sizeof 运算符用于数组名时,将返回整个数组占用内存空间的字节数。
可以修改指针的值,但数组名是常量,不可修改。
注意:
数组名实际上是一个指向数组第一个元素的指针。因此,当你尝试打印数组的地址时,你会得到一个指向整数的指针,而不是一个长整数。这就是为什么你需要将结果强制转换为long long类型,以便正确地显示64位地址。
如果你不使用long long,你可能只会看到32位地址的一部分,这可能会导致错误的结果。例如,如果你的系统是64位的,那么32位地址可能会被解释为无效地址,导致程序崩溃。
20.3 一维数组用于函数的参数
1)指针的数组表示
在C++内部,用指针来处理数组。企
C++编译器把 数组名[下标] 解释为 *(数组首地址+下标);
C++编译器把 地址[下标] 解释为 *(地址+下标);
2)一维数组用于函数的参数
维数组用于函数的参数时,只能传数组的地址,并且必须把数组长度也传进去,除非数组中有最后一个元素的标志。
书写方法有两种:
void func(int* arr, int len):
void func(int arrll, int len);
注意:
在函数中,可以用数组表示法,也可以用指针表示法。
在函数中,不要对指针名用 sizeof 运算符,它不是数组名。
20.4 用new动态创建一维数组
普通数组在栈上分配内存,栈很小;如果需要存放更多的元素,必须在堆上分配内存。
动态创建一维数组的语法:数据类型* 指针=new 数据类型[数组长度];
释放一维数组的语法:delete[] 指针;
注意:
·动态创建的数组没有数组名,不能用 sizeof 运算符。
·可以用数组表示法和指针表示法两种方式使用动态创建的数组。
·必须使用 delete[]来释放内存。(不能只用 delete)
·不要用 delete[]来释放不是 newl分配的内存。
·不要用 deletel]释放同一个内存块两次 (否则等同于操作野指针)。
·对空指针用 delete[]是安全的 (释放内存后,应该把指针置空 nullptr)。
·声明普通数组的时候,数组长度可以用变量,相当于在栈上动态创建数组,并且不需要释放
·如果内存不足,调用new 会产生异常,导致程序中止;如果在 new 关键字后面加(std::nothrow)选项,则返回 nullptr,不会产生异常。(#include <cstdlib>)
·为什么用 delete口释放数组的时候,不需要指定数组的大小? 因为系统会自动跟踪已分配的内存。
举例:
#include<iostream>
#include<cstdlib>
int main()
{
int* p = new(std::nothrow)int[10];
for (int i = 0; i < 10; i++)
{
p[i] = i;
}
for (int i = 0; i < 10; i++)
{
std::cout<<"p["<<i<<"]==" << p[i] << std::endl;
}
delete[] p;
return 0;
}
20.5 数组的排序 qsort
qsort0函数用于对各种数据类型的数组进行排序。
函数的原型:
void qsort(void *base, size t nmem, size t size, int (*compare)(const void *, const void *))
第一个参数:数组的起始地址。
第二个参数:数组元素的个数(数组长度)。
第三个参数:数组元素的大小 (sizeof(数组的数据类型))。
第四个参数:回调函数的地址。
回调函数决定了排序的顺序,声明如下:
int compare(const void *p1, const void *p2):
1)如果函数的返回值< 0,那么 p1所指向元素会被排在 p2所指元素的前面;
2)如果函数的返回值==0,那么 p1 所指向元素与 p2所指元素的顺序不确定;
3)如果函数的返回值> 0,那么 p1所指元素会被排在 p2所指元素的后面.
在 sort 函数中,我们可能会对数组进行排序,这可能涉及到元素的移动和交换。如果我们不保护这些元素不被修改,那么在排序过程中可能会出现错误。因此,我们需要使用 const 关键字来确保这些元素不会被修改。
qsort0函数的其它细节:
·形参中的地址用 void 是为了支持任意数据类型,在回调函数中必须具体化。
·size_t是C标准库中定义的,在64 位系统中是8字节无符号整型(unsigned long long)。
·排序的需求除了升序和降序,还有很多不可预知的情况,只能用回调函数。
#include<iostream>
#include<cstdlib>
int compare(const void* a, const void* b)
{
return *((int*)a) - *((int*)b);
}
int main()
{
int a[10] = { 1,2,5,7,8,9,4,3,8,3 };
std::cout << "排序前:" ;
for (int i = 0; i < 10; i++)
{
std::cout << a[i] << " ";
}
std::cout << "\n";
qsort(a, sizeof(a) / sizeof(int), sizeof(int), compare);
std::cout << "排序后:" ;
for (int i = 0; i < 10; i++)
{
std::cout << a[i] << " ";
}
return 0;
}20.6 折半查找(二分查找)

20.7 C风格的字符串
C语言约定:如果字符型(char)数组的末尾包含了空字符0(也就是0),那么该数组中的内容就是一个字符串.
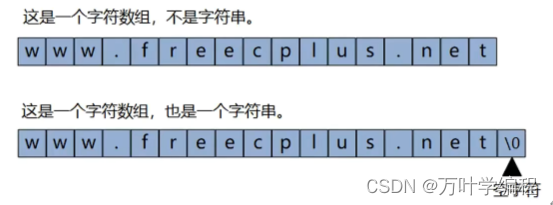
因为字符串需要用0结尾,所以在声明字符数组的时候,要预留多一个字节用来存放0。
char name[21]; // 声明一个最多存放 20 个英文字符或十个中文的字符串。
1)初始化方法
char name[11];//可以存放 10 个字符,没有初始化,里面是垃圾值。
char name[11] = "hello";// 初始内容为 hello。
char namel]= [ "hello" ];// 初始内容为 hello系统会自动添加\0,数组长度是 6。
char name[11] = ( "hello" );// 初始内容为 hello.
char name[11] "hello"; // 初始内容为 hello。
Char name[11]={0};// 把全部的元素初始化为\0。
2)清空字符串
memset(name,0,sizeof(name));// 把全部的元素置为 0。
name[0]=0://不规范,有隐患,不推荐
3)字符串复制或赋值 strcpy()
char *strcpy(char* dest, const char* src);
例:strcpy (str2,str1);
功 能:将参数src字符串拷贝至参数 dest 所指的地址。
返回值: 返回参数 dest 的字符串起始地址。
头文件:#include<cstring>
复制完字符串后,会在 dest 后追加 0。
如果参数 dest 所指的内存空间不够大,会导致数组的越界。
4)字符串复制或赋值 strncpy
char * strncpy(char* dest,const char* src, const size t n);
功能:把src前n个字符的内容复制到 dest 中
返回值: dest 字符串起始地址
如果src 的长度大于等于n,就截取 src 的前 n个字符,不会在 dest 后追加0。
如果参数 dest 所指的内存空间不够大,会导致数组的越界
5)获取字符串的长度strlen()
Size_t strlen( const char*str);
功能:计算字符串的有效长度,不包含 0。
返回值: 返回字符串的字符数。
strlen0函数计算的是字符串的实际长度,遇到0结束。
6)字符串拼接 strcat()
char *strcat(char* dest,const char* src);
功能:将src 字符串拼接到 dest 所指的字符串尾部。
返回值: 返回 dest 字符串起始地址。
dest 最后原有的结尾字符0会被覆盖掉,并在连接后的字符串的尾部再增加一个 0。
如果参数 dest 所指的内存空间不够大,会导致数组的越界。
7)字符串拼接 strncat()
char *strncat (char* dest,const char* src, const size_t n);
功能:将src字符串的前n个字符拼接到 dest 所指的字符串尾部。“
返回值: 返回 dest 字符串的起始地址。“
如果n大于等于字符串 src的长度,那么将 src全部追加到dest 的尾部,如果n小于字符串 src的长度,只追加 src的前 n 个字符。e
strncat 会将 dest 字符串最后的0覆盖掉,字符追加完成后,再追加0。4
如果参数 dest 所指的内存空间不够大,会导致数组的越界。
8)字符串比较 strcmp0)和 strncmp(
nt strcmp(const char *str1, const char *str2 )
功能:比较str1和str2的大小。“
返回值:相等返回0,str1 大于 str2返回1,str1小于str2 返回-1;
nt strncmp(const char *str1,const char *str2 ,const size t n)
功能:比较str1和str2前n个字符的大小。
返回值:相等返回0,str1 大于 str2 返回1,str1小于str2 返回-1;“
两个字符串比较的方法是比较字符的 ASCII 码的大小,从两个字符串的第一个字符开始,如果分不
9)字符查找 strchr()和strrchr()
har *strchr(const char *s,const int c);
返回一个指向在字符串s 中第一个出现c的位置,如果找不到,返回0。个
10)字符串查找 strstr()4
har *strstr(const char* str,const char* substr);
功能:检索子串在字符串中首次出现的位置。“
返回值: 返回字符串 str 中第一次出现子串 substr 的地址,如果没有检索到子串,则返回0。
11)用于string的表达式
可以把C风格的字符串用于包含了 string 类型的赋值拼接等表达式中。
12)注意事项(
a)字符串的结尾标志是0,按照约定,在处理字符串的时候,会从起始位置开始搜索 0,一直找下去,找到为止(不会判断数组是否越界)。“
b)结尾标志0后面的都是垃圾内容。“
c)字符串在每次使用前都要初化,减少入坑的可能,是每次,不是第一次。
不要在子函数中对字符指针用 sizeof 运算,所以,不能在子函数中对传入的字符串进行初始化,除非字符串的长度也作为参数传入到了子函数中。“
e)在VS中,如果要使用C标准的字符串操作函数,要在源代码文件的最上面加
#define _CRT_SECURE_NO_WARNINGS
20.8 二维数组
一维数组的数学概念是线性表,二维数组的数学概念是矩阵。
1)创建二维数组
声明二维数组的语法:数据类型 数组名[行数][列数];
注意:数组长度必须是整数,可以是常量,也可以是变量和表达式
C90规定必须用常量表达式指明数组的大小,C99允许使用整型非常量表达式。经测试,在VS中可以用整型非常量表达式,不能用变量;但是,Linux 中还可以用变量。
2)二维数组的使用
可以通过行下标和列下标访问二维数组中元素,下标从0开始。
二维数组中每个元素的特征和使用方法与单个变量完全相同。
语法:数组名[行下标][列下标];
注意:
·二维数组下标也必须是整数,可以是常量,也可以是变量。
·合法的行下标取值是:0~(行数-1)。
·合法的例下标取值是:0~(列数-1)。
3)二维数组占用内存的情况
用sizeof(数组名)可以得到整个二维数组占用内存空间的大小(只适用于 C++基本数据类型)。
二维数组在内存中占用的空间是连续的。
4)二维数组的初始化
声明的时候初始化:
数据类型 数组名[行数][列数] = {{据 1,数据 2},{据 3,数据 4 },..... .};
数据类型 数组名[行数][列数] ={ 数据 1,数据 2,数据 3,数据 4,.....};
......
C++11 标准可以不写等于号。
- 清空二维数组
用memset()函数可以把二维数组中全部的元素清零函数原型:
void *memset(void *s, int c, size_t n)
注意,在 Linux 下,使用 memset()函数需要包含头文件#include <string.h>
- 复制二维数组
用memcpy0函数可以把二维数组中全部的元素复制到另一个相同大小的数组(没说多少维)。
(只适用于 C++基本数据类型)
函数原型:void *memcpy(void *dest, const void *src, size_t n);
注意,在 Linux下,使用 memcpy0函数需要包含头文件#include <string.h>
20.9 二维数组用于函数的参数
int* p;//整型指针。
int* p[3];//一维整型指针数组,元素是 3 个整型指针 (p[]、p[1]、p[2])
int* p();// 函数 p 的返回值类型是整型的地址
int (*p)(int ,int);// p 是函数指针,函数的返回值是整型。
1)数组指针
声明数组指针的语法:数据类型 (*行指针名)[行的大小]; // 行的大小即数组长度
例;
int(*p1)[3]; // p1 是数组指针,用于指向数组长度为 3 的 int 型数组。
double (*p3)[5]; // p2 是数组指针,用于指向数组长度为 5 的 double 型数组。
一维数组名被解释为数组第0个元素的地址。
2)把二维数组传递给函数
int bh[2][3] = ( (11,12,13)(21,22,23) );
int (*p)[3]=bh;
如果要把 bh 传给函数,函数的声明如下:
func(int (*p)[3],int len):
void func(int pll[3],int len);
本章完。
















 885
885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











