









该部分主要参考的资料如下堆概述 - CTF Wiki (ctf-wiki.org)
目录
什么是堆
在程序运行过程中,堆可以提供动态分配的内存,允许程序申请大小未知的内存。堆其实就是程序虚拟地址空间的一块连续的线性区域,它由低地址向高地址方向增长。我们一般称管理堆的那部分程序为堆管理器。
堆管理器处于用户程序与内核中间,主要做以下工作
- 响应用户的申请内存请求,向操作系统申请内存,然后将其返回给用户程序。同时,为了保持内存管理的高效性,内核一般都会预先分配很大的一块连续的内存,然后让堆管理器通过某种算法管理这块内存。只有当出现了堆空间不足的情况,堆管理器才会再次与操作系统进行交互。
- 管理用户所释放的内存。一般来说,用户释放的内存并不是直接返还给操作系统的,而是由堆管理器进行管理。这些释放的内存可以来响应用户新申请的内存的请求。
Linux 中早期的堆分配与回收由 Doug Lea 实现,但它在并行处理多个线程时,会共享进程的堆内存空间。因此,为了安全性,一个线程使用堆时,会进行加锁。然而,与此同时,加锁会导致其它线程无法使用堆,降低了内存分配和回收的高效性。同时,如果在多线程使用时,没能正确控制,也可能影响内存分配和回收的正确性。Wolfram Gloger 在 Doug Lea 的基础上进行改进使其可以支持多线程,这个堆分配器就是 ptmalloc 。在 glibc-2.3.x. 之后,glibc 中集成了 ptmalloc2。
目前 Linux 标准发行版中使用的堆分配器是 glibc 中的堆分配器:ptmalloc2。ptmalloc2 主要是通过 malloc/free 函数来分配和释放内存块。
需要注意的是,在内存分配与使用的过程中,Linux 有这样的一个基本内存管理思想,只有当真正访问一个地址的时候,系统才会建立虚拟页面与物理页面的映射关系。 所以虽然操作系统已经给程序分配了很大的一块内存,但是这块内存其实只是虚拟内存。只有当用户使用到相应的内存时,系统才会真正分配物理页面给用户使用。
malloc
在 glibc 的 malloc.c 中,malloc 的说明如下
/*
malloc(size_t n)
Returns a pointer to a newly allocated chunk of at least n bytes, or null
if no space is available. Additionally, on failure, errno is
set to ENOMEM on ANSI C systems.
If n is zero, malloc returns a minumum-sized chunk. (The minimum
size is 16 bytes on most 32bit systems, and 24 or 32 bytes on 64bit
systems.) On most systems, size_t is an unsigned type, so calls
with negative arguments are interpreted as requests for huge amounts
of space, which will often fail. The maximum supported value of n
differs across systems, but is in all cases less than the maximum
representable value of a size_t.
*/可以看出,malloc 函数返回对应大小字节的内存块的指针。此外,该函数还对一些异常情况进行了处理
- 当 n=0 时,返回当前系统允许的堆的最小内存块。
- 当 n 为负数时,由于在大多数系统上,size_t 是无符号数(这一点非常重要),所以程序就会申请很大的内存空间,但通常来说都会失败,因为系统没有那么多的内存可以分配。
free
在 glibc 的 malloc.c 中,free 的说明如下
/*
free(void* p)
Releases the chunk of memory pointed to by p, that had been previously
allocated using malloc or a related routine such as realloc.
It has no effect if p is null. It can have arbitrary (i.e., bad!)
effects if p has already been freed.
Unless disabled (using mallopt), freeing very large spaces will
when possible, automatically trigger operations that give
back unused memory to the system, thus reducing program footprint.
*/可以看出,free 函数会释放由 p 所指向的内存块。这个内存块有可能是通过 malloc 函数得到的,也有可能是通过相关的函数 realloc 得到的。
此外,该函数也同样对异常情况进行了处理
- 当 p 为空指针时,函数不执行任何操作。
- 当 p 已经被释放之后,再次释放会出现乱七八糟的效果,这其实就是 double free。
- 除了被禁用 (mallopt) 的情况下,当释放很大的内存空间时,程序会将这些内存空间还给系统,以便于减小程序所使用的内存空间。
内存分配背后的系统调用
在前面提到的函数中,无论是 malloc 函数还是 free 函数,我们动态申请和释放内存时,都经常会使用,但是它们并不是真正与系统交互的函数。这些函数背后的系统调用主要是 (s)brk 函数以及 mmap, munmap 函数。
如下图所示,我们主要考虑对堆进行申请内存块的操作。
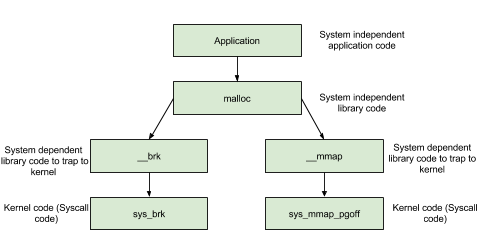
(s)brk
对于堆的操作,操作系统提供了 brk 函数,glibc 库提供了 sbrk 函数,我们可以通过增加 brk 的大小来向操作系统申请内存。
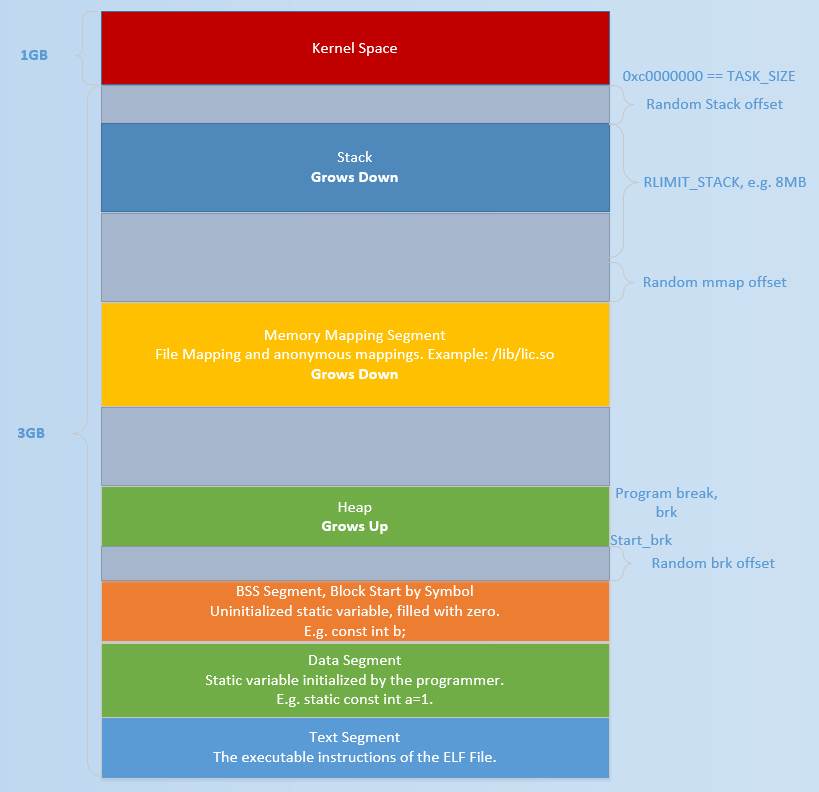
初始时,堆的起始地址 start_brk 以及堆的当前末尾 brk 指向同一地址。根据是否开启 ASLR,两者的具体位置会有所不同
- 不开启 ASLR 保护时,start_brk 以及 brk 会指向 data/bss 段的结尾。
- 开启 ASLR 保护时,start_brk 以及 brk 也会指向同一位置,只是这个位置是在 data/bss 段结尾后的随机偏移处。
具体效果如下图(这个图片与网上流传的基本一致,这里是因为要画一张大图,所以自己单独画了下)所示
例子
/* sbrk and brk example */
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
void *curr_brk, *tmp_brk = NULL;
printf("Welcome to sbrk example:%d\n", getpid()); //获取进程ID号
/* 获取程序断点位置 */
tmp_brk = curr_brk = sbrk(0);
printf("Program Break Location1:%p\n", curr_brk);
getchar();
/* brk(addr) increments/decrements program break location */
brk(curr_brk+4096);//使用brk将程序断点增加 4096 字节,即分配额外的 4 KB 堆内存。
curr_brk = sbrk(0); //使用sbrk(0)获取增加后的程序断点的新位置。
printf("Program break Location2:%p\n", curr_brk);
getchar();
brk(tmp_brk); //使用brk将程序断点减少回到初始位置,释放之前分配的内存
curr_brk = sbrk(0); //使用sbrk(0)获取减少后的程序断点的新位置。
printf("Program Break Location3:%p\n", curr_brk);
getchar();
return 0;
}需要注意的是,在每一次执行完操作后,都执行了 getchar() 函数,这是为了我们方便我们查看程序真正的映射。
这个程序通过使用brk函数和sbrk实现了malloc函数和free函数。
brk()函数功能是为堆上分配内存。
sbrk(0)函数就检索当前程序断点
在第一次调用 brk 之前
从下面的输出可以看出,并没有出现堆。因此
- start_brk = brk = end_data = 0x804b000
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/syscalls$ ./sbrk
Welcome to sbrk example:6141
Program Break Location1:0x804b000
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/syscalls$ cat /proc/6141/maps
...
0804a000-0804b000 rw-p 00001000 08:01 539624 /home/sploitfun/ptmalloc.ppt/syscalls/sbrk
b7e21000-b7e22000 rw-p 00000000 00:00 0
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/syscalls$第一次增加 brk 后
从下面的输出可以看出,已经出现了堆段
- start_brk = end_data = 0x804b000
- brk = 0x804c000
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/syscalls$ ./sbrk
Welcome to sbrk example:6141
Program Break Location1:0x804b000
Program Break Location2:0x804c000
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/syscalls$ cat /proc/6141/maps
...
0804a000-0804b000 rw-p 00001000 08:01 539624 /home/sploitfun/ptmalloc.ppt/syscalls/sbrk
0804b000-0804c000 rw-p 00000000 00:00 0 [heap]
b7e21000-b7e22000 rw-p 00000000 00:00 0
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/syscalls$其中,关于堆的那一行
- 0x0804b000 是相应堆的起始地址
- rw-p 表明堆具有可读可写权限,并且属于隐私数据。
- 00000000 表明文件偏移,由于这部分内容并不是从文件中映射得到的,所以为 0。
- 00:00 是主从 (Major/mirror) 的设备号,这部分内容也不是从文件中映射得到的,所以也都为 0。
- 0 表示着 Inode 号。由于这部分内容并不是从文件中映射得到的,所以为 0。
mmap
malloc 会使用 mmap 来创建独立的匿名映射段。匿名映射的目的主要是可以申请以 0 填充的内存,并且这块内存仅被调用进程所使用。
例子
/* Private anonymous mapping example using mmap syscall */
#include <stdio.h>
#include <sys/mman.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdlib.h>
void static inline errExit(const char* msg)
{
printf("%s failed. Exiting the process\n", msg);
exit(-1);
}
int main()
{
int ret = -1;
printf("Welcome to private anonymous mapping example::PID:%d\n", getpid());
printf("Before mmap\n");
getchar();
char* addr = NULL;
addr = mmap(NULL, (size_t)132*1024, PROT_READ|PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (addr == MAP_FAILED) //调用 mmap 进行私有匿名映射
errExit("mmap");
printf("After mmap\n");
getchar();
/* Unmap mapped region. */
ret = munmap(addr, (size_t)132*1024); //调用 munmap 解除映射:
if(ret == -1)
errExit("munmap");
printf("After munmap\n");
getchar();
return 0;
}在执行 mmap 之前
我们可以从下面的输出看到,目前只有. so 文件的 mmap 段。
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/syscalls$ cat /proc/6067/maps
08048000-08049000 r-xp 00000000 08:01 539691 /home/sploitfun/ptmalloc.ppt/syscalls/mmap
08049000-0804a000 r--p 00000000 08:01 539691 /home/sploitfun/ptmalloc.ppt/syscalls/mmap
0804a000-0804b000 rw-p 00001000 08:01 539691 /home/sploitfun/ptmalloc.ppt/syscalls/mmap
b7e21000-b7e22000 rw-p 00000000 00:00 0
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/syscalls$mmap 后
从下面的输出可以看出,我们申请的内存与已经存在的内存段结合在了一起构成了 b7e00000 到 b7e21000 的 mmap 段。
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/syscalls$ cat /proc/6067/maps
08048000-08049000 r-xp 00000000 08:01 539691 /home/sploitfun/ptmalloc.ppt/syscalls/mmap
08049000-0804a000 r--p 00000000 08:01 539691 /home/sploitfun/ptmalloc.ppt/syscalls/mmap
0804a000-0804b000 rw-p 00001000 08:01 539691 /home/sploitfun/ptmalloc.ppt/syscalls/mmap
b7e00000-b7e22000 rw-p 00000000 00:00 0
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/syscalls$munmap
从下面的输出,我们可以看到我们原来申请的内存段已经没有了,内存段又恢复了原来的样子了。
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/syscalls$ cat /proc/6067/maps
08048000-08049000 r-xp 00000000 08:01 539691 /home/sploitfun/ptmalloc.ppt/syscalls/mmap
08049000-0804a000 r--p 00000000 08:01 539691 /home/sploitfun/ptmalloc.ppt/syscalls/mmap
0804a000-0804b000 rw-p 00001000 08:01 539691 /home/sploitfun/ptmalloc.ppt/syscalls/mmap
b7e21000-b7e22000 rw-p 00000000 00:00 0
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/syscalls$多线程支持
在原来的 dlmalloc 实现中,当两个线程同时要申请内存时,只有一个线程可以进入临界区申请内存,而另外一个线程则必须等待直到临界区中不再有线程。这是因为所有的线程共享一个堆。在 glibc 的 ptmalloc 实现中,比较好的一点就是支持了多线程的快速访问。在新的实现中,所有的线程共享多个堆。
在内存分配实现中,临界区(也称为互斥区)是指一段代码,一次只允许一个线程进入执行,以确保对共享资源的访问是原子的,避免并发冲突。在原始的 dlmalloc(Doug Lea's malloc)实现中,所有线程共享一个堆,因此在分配内存时需要进入临界区,防止多个线程同时修改堆结构,从而导致数据不一致或分配冲突。
在 glibc 的 ptmalloc 实现中(ptmalloc表示pthread malloc),采用了一种更先进的多线程内存分配策略,以支持多线程的快速访问。这个实现的主要特点包括:
- 多个堆:ptmalloc 为每个线程维护一个私有堆(heap),而不再共享一个全局堆。每个线程在自己的堆上进行内存分配,减少了对全局堆的竞争。
- 线程本地缓存(Thread-Caching): 每个线程都有自己的本地缓存,用于快速分配和释放小块内存。这减少了对全局数据结构的频繁访问,提高了分配和释放的性能。
- 分离锁(Per-Thread Arena):ptmalloc 使用分离锁(per-thread arena)来保护线程本地堆,使得不同线程之间的内存分配可以并行进行,而不需要进入全局临界区。
为什么需要分离锁,不是已经每个线程一个私有堆了吗?
对于每个线程有一个私有堆(private heap)的设计,确实可以减少线程之间的竞争,但在实际情况中,仍然存在一些全局数据结构需要进行访问和维护。ptmalloc 使用分离锁(Per-Thread Arena)的设计来进一步减小竞争,提高并发性。
虽然每个线程都有一个私有堆,但在某些情况下,仍然需要访问全局数据结构,比如管理整个堆的结构。例如,ptmalloc 中有一个数据结构称为 arena,它负责管理线程私有堆的分配和释放。即使每个线程有自己的堆,多个线程在分配和释放时可能仍然需要对 arena 进行访问,比如在执行扩展堆的操作时。
为了避免多个线程同时访问全局数据结构时的竞争条件,ptmalloc 使用了分离锁。这意味着为每个线程维护一个独立的锁,每个线程可以独立地对其私有堆进行操作,而不需要竞争全局的锁。
总结一下,分离锁的设计在私有堆的基础上,为全局数据结构引入了一层额外的锁机制,确保多个线程在对堆进行管理时能够并行执行,减小了竞争,提高了并发性。这是为了在多线程环境下更好地平衡性能和对全局数据结构的访问控制。
什么叫独立的锁,我竞争全局资源,这个资源不还是临界资源吗?
在多线程编程中,我们通常使用锁来控制对共享资源的访问,以防止竞争条件。一个独立的锁是指为每个线程维护一个单独的锁,每个线程独立地拥有和使用这个锁。这与传统的全局锁不同,全局锁是一个全局共享的锁,当一个线程持有这个锁时,其他线程必须等待,无法同时执行关键代码段。
对于 ptmalloc 中的分离锁的情况,我们考虑有一个全局性的数据结构(例如 arena),需要在多线程环境中被访问。如果使用一个全局锁,那么每个线程在要访问 arena 时都必须等待获取这个全局锁,这样就引入了竞争。多个线程争夺同一个锁可能导致性能下降,因为每次只有一个线程可以访问 arena。
为了减小竞争的激烈程度,ptmalloc 的设计是为每个线程维护一个独立的锁。这意味着每个线程有自己的锁实例,而不再与其他线程竞争同一个锁。当一个线程要访问 arena 时,它首先尝试获取自己的锁,而不需要等待其他线程释放全局锁。如果两个线程分别访问不同的 arena,它们就可以并行执行,因为它们使用的是独立的锁。
独立的锁并不意味着不再有竞争资源。仍然存在对 arena 的竞争,但是通过为每个线程提供独立的锁,竞争的范围被减小到每个线程内部。这有助于提高并发性能,因为不同线程之间的竞争减少了,线程可以更自由地进行并行访问。
独立的锁就是说,锁住全局资源里面的其中一部分,这个线程可以控制锁开锁关?
独立的锁的概念是为每个线程提供一个单独的锁,这个锁只控制某个线程所需要访问的特定资源或数据结构。每个线程拥有自己的锁实例,因此在访问共享资源时,线程可以独立地控制其锁的状态(锁定或解锁),而不受其他线程的影响。
这样的设计可以降低锁的竞争范围,提高并发性能。当不同线程需要访问不同的资源时,它们可以独立地使用各自的锁,不需要等待其他线程释放全局锁。这样可以使得多线程的执行更为并行化,减少竞争带来的性能瓶颈。
在 ptmalloc 中,每个线程有自己的锁,用于控制对线程私有堆的访问以及可能的全局资源(如 arena)。这种独立锁的设计是为了在多线程环境中更好地平衡并发性能和对全局资源的访问控制。
这里给出一个例子。
/* Per thread arena example. */
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
#include <sys/types.h>
void* threadFunc(void* arg) {
printf("Before malloc in thread 1\n");
getchar();
char* addr = (char*) malloc(1000);
printf("After malloc and before free in thread 1\n");
getchar();
free(addr);
printf("After free in thread 1\n");
getchar();
}
int main() {
pthread_t t1;
void* s;
int ret;
char* addr;
printf("Welcome to per thread arena example::%d\n",getpid());
printf("Before malloc in main thread\n");
getchar();
addr = (char*) malloc(1000);
printf("After malloc and before free in main thread\n");
getchar();
free(addr);
printf("After free in main thread\n");
getchar();
ret = pthread_create(&t1, NULL, threadFunc, NULL);
if(ret)
{
printf("Thread creation error\n");
return -1;
}
ret = pthread_join(t1, &s);
if(ret)
{
printf("Thread join error\n");
return -1;
}
return 0;
}第一次申请之前, 没有任何堆段。
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$ ./mthread
Welcome to per thread arena example::6501
Before malloc in main thread
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$ cat /proc/6501/maps
08048000-08049000 r-xp 00000000 08:01 539625 /home/sploitfun/ptmalloc.ppt/mthread/mthread
08049000-0804a000 r--p 00000000 08:01 539625 /home/sploitfun/ptmalloc.ppt/mthread/mthread
0804a000-0804b000 rw-p 00001000 08:01 539625 /home/sploitfun/ptmalloc.ppt/mthread/mthread
b7e05000-b7e07000 rw-p 00000000 00:00 0
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$第一次申请后, 从下面的输出可以看出,堆段被建立了,并且它就紧邻着数据段,这说明 malloc 的背后是用 brk 函数来实现的。同时,需要注意的是,我们虽然只是申请了 1000 个字节,但是我们却得到了 0x0806c000-0x0804b000=0x21000 个字节的堆。这说明虽然程序可能只是向操作系统申请很小的内存,但是为了方便,操作系统会把很大的内存分配给程序。这样的话,就避免了多次内核态与用户态的切换,提高了程序的效率。我们称这一块连续的内存区域为 arena。此外,我们称由主线程申请的内存为 main_arena。后续的申请的内存会一直从这个 arena 中获取,直到空间不足。当 arena 空间不足时,它可以通过增加 brk 的方式来增加堆的空间。类似地,arena 也可以通过减小 brk 来缩小自己的空间。
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$ ./mthread
Welcome to per thread arena example::6501
Before malloc in main thread
After malloc and before free in main thread
...
sploitfun@sploitfun-VirtualBox:~/lsploits/hof/ptmalloc.ppt/mthread$ cat /proc/6501/maps
08048000-08049000 r-xp 00000000 08:01 539625 /home/sploitfun/ptmalloc.ppt/mthread/mthread
08049000-0804a000 r--p 00000000 08:01 539625 /home/sploitfun/ptmalloc.ppt/mthread/mthread
0804a000-0804b000 rw-p 00001000 08:01 539625 /home/sploitfun/ptmalloc.ppt/mthread/mthread
0804b000-0806c000 rw-p 00000000 00:00 0 [heap]
b7e05000-b7e07000 rw-p 00000000 00:00 0
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$在主线程释放内存后,我们从下面的输出可以看出,其对应的 arena 并没有进行回收,而是交由 glibc 来进行管理。当后面程序再次申请内存时,在 glibc 中管理的内存充足的情况下,glibc 就会根据堆分配的算法来给程序分配相应的内存。
一些常见的 glibc 内存管理策略包括:
- 延迟释放(Delayed Free):glibc 的内存管理器可能会将一些释放的内存块保留在内部的数据结构中,并延迟将它们返回给操作系统。这样做的目的是为了减少频繁向操作系统请求内存的开销。
- 内存池(Memory Pooling):glibc 可能会维护一些内存池,以备将来再次分配给程序。这可以提高内存分配的速度,因为不必每次都向操作系统请求新的内存。
- 分配算法优化:ptmalloc 等内存管理器会使用一些优化的分配算法,以提高内存的利用率,减少内存碎片。
由于这些策略,即使你在主线程释放了内存,操作系统的 free 函数并不一定会立即将内存返回给系统。相反,内存管理器会尽量在需要的时候进行内部的管理和优化。
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$ ./mthread
Welcome to per thread arena example::6501
Before malloc in main thread
After malloc and before free in main thread
After free in main thread
...
sploitfun@sploitfun-VirtualBox:~/lsploits/hof/ptmalloc.ppt/mthread$ cat /proc/6501/maps
08048000-08049000 r-xp 00000000 08:01 539625 /home/sploitfun/ptmalloc.ppt/mthread/mthread
08049000-0804a000 r--p 00000000 08:01 539625 /home/sploitfun/ptmalloc.ppt/mthread/mthread
0804a000-0804b000 rw-p 00001000 08:01 539625 /home/sploitfun/ptmalloc.ppt/mthread/mthread
0804b000-0806c000 rw-p 00000000 00:00 0 [heap]
b7e05000-b7e07000 rw-p 00000000 00:00 0
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$在第一个线程 malloc 之前,我们可以看到并没有出现与线程 1 相关的堆,但是出现了与线程 1 相关的栈。
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$ ./mthread
Welcome to per thread arena example::6501
Before malloc in main thread
After malloc and before free in main thread
After free in main thread
Before malloc in thread 1
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$ cat /proc/6501/maps
08048000-08049000 r-xp 00000000 08:01 539625 /home/sploitfun/ptmalloc.ppt/mthread/mthread
08049000-0804a000 r--p 00000000 08:01 539625 /home/sploitfun/ptmalloc.ppt/mthread/mthread
0804a000-0804b000 rw-p 00001000 08:01 539625 /home/sploitfun/ptmalloc.ppt/mthread/mthread
0804b000-0806c000 rw-p 00000000 00:00 0 [heap]
b7604000-b7605000 ---p 00000000 00:00 0
b7605000-b7e07000 rw-p 00000000 00:00 0 [stack:6594]
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$第一个线程 malloc 后, 我们可以从下面输出看出线程 1 的堆段被建立了。而且它所在的位置为内存映射段区域,同样大小也是 132KB(b7500000-b7521000)。因此这表明该线程申请的堆时,背后对应的函数为 mmap 函数。同时,我们可以看出实际真的分配给程序的内存为 1M(b7500000-b7600000)。而且,只有 132KB 的部分具有可读可写权限,这一块连续的区域成为 thread arena。
注意:
当用户请求的内存大于 128KB 时,并且没有任何 arena 有足够的空间时,那么系统就会执行 mmap 函数来分配相应的内存空间。这与这个请求来自于主线程还是从线程无关。
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$ ./mthread
Welcome to per thread arena example::6501
Before malloc in main thread
After malloc and before free in main thread
After free in main thread
Before malloc in thread 1
After malloc and before free in thread 1
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$ cat /proc/6501/maps
08048000-08049000 r-xp 00000000 08:01 539625 /home/sploitfun/ptmalloc.ppt/mthread/mthread
08049000-0804a000 r--p 00000000 08:01 539625 /home/sploitfun/ptmalloc.ppt/mthread/mthread
0804a000-0804b000 rw-p 00001000 08:01 539625 /home/sploitfun/ptmalloc.ppt/mthread/mthread
0804b000-0806c000 rw-p 00000000 00:00 0 [heap]
b7500000-b7521000 rw-p 00000000 00:00 0
b7521000-b7600000 ---p 00000000 00:00 0
b7604000-b7605000 ---p 00000000 00:00 0
b7605000-b7e07000 rw-p 00000000 00:00 0 [stack:6594]
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$在第一个线程释放内存后, 我们可以从下面的输出看到,这样释放内存同样不会把内存重新给系统。
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$ ./mthread
Welcome to per thread arena example::6501
Before malloc in main thread
After malloc and before free in main thread
After free in main thread
Before malloc in thread 1
After malloc and before free in thread 1
After free in thread 1
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$ cat /proc/6501/maps
08048000-08049000 r-xp 00000000 08:01 539625 /home/sploitfun/ptmalloc.ppt/mthread/mthread
08049000-0804a000 r--p 00000000 08:01 539625 /home/sploitfun/ptmalloc.ppt/mthread/mthread
0804a000-0804b000 rw-p 00001000 08:01 539625 /home/sploitfun/ptmalloc.ppt/mthread/mthread
0804b000-0806c000 rw-p 00000000 00:00 0 [heap]
b7500000-b7521000 rw-p 00000000 00:00 0
b7521000-b7600000 ---p 00000000 00:00 0
b7604000-b7605000 ---p 00000000 00:00 0
b7605000-b7e07000 rw-p 00000000 00:00 0 [stack:6594]
...
sploitfun@sploitfun-VirtualBox:~/ptmalloc.ppt/mthread$














 15万+
15万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









