







- 相关知识点
- Apriori算法:Apriori算法是基于频繁项集的关联规则学习算法,用于发掘数据中项与项之间的关联。算法通过递归地生成候选项集并计算其支持度,最终提取出满足最小支持度的频繁项集。算法的核心是“剪枝”思想,即如果某个项集不是频繁项集,那么它的超集也一定不可能是频繁项集。
- 支持度:支持度是衡量项集在数据中出现频率的指标。例如,如果一个商品在100次交易中出现了50次,那么它的支持度就是50/100 = 0.5。支持度是判断项集是否频繁的依据。
- 置信度:置信度表示在某个条件下,规则的后件出现的概率。例如,规则 {牛奶} -> {面包} 的置信度表示购买牛奶的人购买面包的概率。它是规则前件和后件共同出现的概率与前件出现的概率之比。
- 频繁项集:频繁项集是指在所有交易中,出现频率高于或等于最小支持度的项集。通过频繁项集,我们可以发现数据中经常一起发生的事件。
- 关联规则:关联规则通过从频繁项集中生成,描述了数据中不同项之间的依赖关系。其形式为 X -> Y,表示在事务中如果包含项集X,那么也很可能包含项集Y。
- 实验分析
- 数据准备:通过Pandas加载CSV文件,并将数据转换为适用于Apriori算法的事务列表形式。
- 生成候选1项集:初始步骤生成候选1项集(C1),每个事务中购买过的商品被转化为一个集合,以便后续生成频繁项集。
- 频繁项集筛选:遍历候选项集,计算每个项集在事务数据中出现的频率(支持度)。如果支持度大于或等于设定的最小支持度,则该项集被认为是频繁项集。
- 生成候选k项集:从频繁项集生成候选k项集(Ck),通过合并频繁k-1项集中的项集,生成可能的k项集。候选k项集的生成依赖于前一步骤生成的频繁项集。
- 迭代计算:重复上述过程,直到没有更多频繁项集可生成。每次迭代都会生成更高阶的候选项集,直到无法找到符合最小支持度的频繁项集。
- 生成关联规则:根据频繁项集生成关联规则。通过计算规则的置信度,筛选出满足最小置信度的规则。这些规则可以用于商品推荐、市场分析等实际应用。
- 实验代码
-
import pandas as pd # 加载数据集 data = pd.read_csv("ShopCT.csv") transactions = data.iloc[:, 1:].values.tolist() def create_c1(dataset): """生成候选 1-项集 C1""" c1 = set() for transaction in dataset: c1.update([frozenset([item]) for item, val in enumerate(transaction) if val == 1]) return list(c1) def create_freq_transaction(dataset, ck, min_support): """筛选出满足最小支持度的频繁项集""" support_data = {} # 保存支持度 freq_transaction = [] # 保存频繁项集 num_transactions = len(dataset) # 总事务数 # 遍历候选项集 for candidate in ck: count = sum(1 for transaction in dataset if candidate.issubset(transaction)) support = count / num_transactions support_data[candidate] = support if support >= min_support: freq_transaction.append(candidate) return support_data, freq_transaction def create_ck(freq_transaction): """由频繁 k-1 项集生成候选 k 项集""" ck = set() num_items = len(freq_transaction) for i in range(num_items): for j in range(i + 1, num_items): l1, l2 = list(freq_transaction[i])[:-1], list(freq_transaction[j])[:-1] if l1 == l2: # 公共前缀相同 ck.add(freq_transaction[i] | freq_transaction[j]) return list(ck) def apriori(dataset, min_support): """Apriori 算法主函数""" c1 = create_c1(dataset) support_data, l1 = create_freq_transaction(dataset, c1, min_support) all_freq_transaction = [l1] while all_freq_transaction[-1]: # 递归生成频繁项集 ck = create_ck(all_freq_transaction[-1]) support_data_k, lk = create_freq_transaction(dataset, ck, min_support) support_data.update(support_data_k) # 更新支持度数据 all_freq_transaction.append(lk) return support_data, all_freq_transaction[:-1] # 去掉最后一次的空集 def create_rules(support_data, freq_transactions, min_conf): """根据频繁项集生成关联规则""" rules = [] for i in range(1, len(freq_transactions)): # 从频繁 2-项集开始 for freq_set in freq_transactions[i]: subsets = list(freq_set) for subset in subsets: remain = freq_set - frozenset([subset]) if remain: confidence = support_data[freq_set] / support_data[frozenset([subset])] if confidence >= min_conf: rules.append((frozenset([subset]), remain, confidence)) return rules # 设置最小支持度和置信度 min_support = 0.5 min_conf = 0.7 # 生成频繁项集 support_data, all_freq_transaction = apriori(transactions, min_support) print("所有频繁项集:", all_freq_transaction) # 生成关联规则 rules = create_rules(support_data, all_freq_transaction, min_conf) for rule in rules: print(f"规则: {rule[0]} -> {rule[1]},置信度: {rule[2]:.2f}") - 运行截图
-
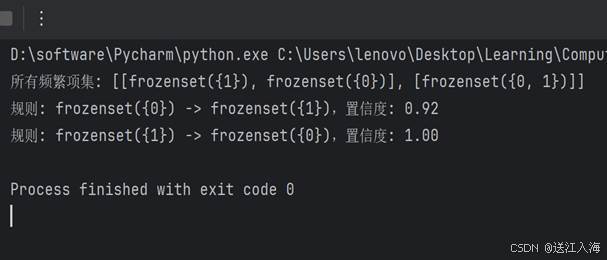
- 实验总结
- Apriori算法能够有效地挖掘出频繁项集,并基于这些频繁项集生成关联规则,帮助我们发现数据中潜在的关联关系。实验中最有意义的部分是调节最小支持度和置信度参数,这直接影响最终结果的质量。
- 关联关系。实验中最有意义的部分是调节最小支持度和置信度参数,这直接影响最终结果的质量。在实际应用中,Apriori算法能够为商品推荐、市场分析等提供有价值的数据支持。不过,算法在处理大规模数据时会遇到效率瓶颈,频繁项集的生成需要大量计算和存储,因此在大数据环境下可能需要优化。
- 总的来说,尽管Apriori算法简单易懂,但要在实际项目中应用它,需要注意性能优化和参数调整。
-
出现的问题:
- 数据读取问题:在读取CSV文件时,数据有时包含缺失值或格式不统一,导致程序无法正确加载。
- 内存占用过高:频繁项集生成过程中,数据量大时内存消耗很高。
-
解决方案(列出遇到的问题和解决办法,列出没有解决的问题)
- 数据读取问题:使用pd.read_csv()时加上na_values参数处理缺失值,或者利用dropna()清理数据,确保数据格式一致。
- 内存占用过高:通过调整最小支持度,减少候选项集的数量,优化内存使用;或者将数据分批处理,分步计算频繁项集,避免一次性加载所有数据。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









