







目录
🎓查看进程深度解析(标识符pid/ppid)
上一篇文章我们了解了进程的概念,并学会了创建进程和查看进程,在查看进程的时候,我们重点了解了一个属性叫做PID,即进程标识符。

- 每个进程在系统层面上,要被管理就必须要有进程身份标识,即唯一标识符PID
- 就像每个同学在学校里都有一个身份标识,在操作系统中都有一个PID来标识进程
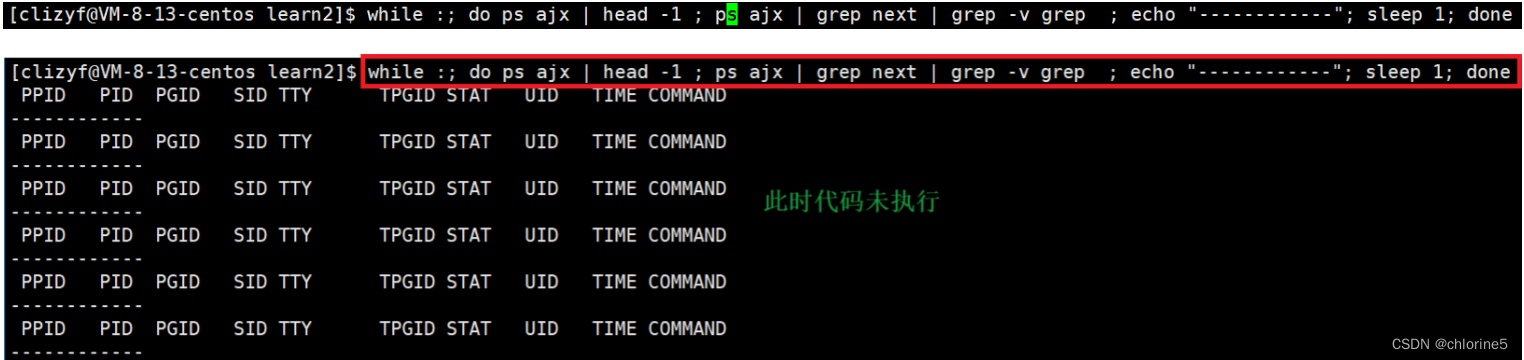
我们先分析解释下面一指令行的意思,再继续分析pid/ppid标识符情况
🎈查看进程分析(ps)
![]()
- 管道连接head -1就是去只显示ps axj展示出来的所有信息的第一行(即那个表头信息)

- 管道连接grep proc就是去搜索ps ajx展示出来的所以带有"proc"字符串的文件

先将在ajx中所有信息中的第一行信息展示出来,指令执行完毕后,然后在ajx中展示带有"proc"字符串文件,指令执行完毕,带个&&,代表左边执行成功,右边也执行成功。用;也是可以的,就相当于第一批执行完毕,再执行下一批。然后我们就看到我们所在运行的./proc可执行文件的PID是6625。
我们肯定很疑惑在执行文件./proc下面的一个显示器上显示,本来我只想查找./proc,但是也显示了下面一行 grep也查到了,这是为什么?
主要是因为当你在查这个信息的时候,最后要过滤这个proc关键字的时候,我么通过管道grep proc找到了./proc文件,没毛病,可是我们不要忘了,grep当你自己在过滤时,grep自己也要变成进程,因为grep过滤的关键词是proc,所以我们在过滤进程时段的时候,把给自己也带上了,你在grep proc时给自己也过滤出来了,这里证明在所有命令在运行时,其实都是进程。
如果我们不想要这一行,我们可以grep -v grep,其中-v选项是我之前指令一节讲过的,grep -v选项是不包含grep的留下来,只剩下我查找的proc的了


🎈pid(变化)
但是我们有想过,这个PID有什么用呢?用什么方式管理进程呢?
🕶️用户杀进程
kill -9 6625 表示用kill命令给6625的PID发送9号信号,然后直接给这个进程干掉


如果有时候ctrl c干不掉,可以用kill -9 PID就直接干掉,这就是所谓的用户可以杀进程
🕶️如何获取PID?
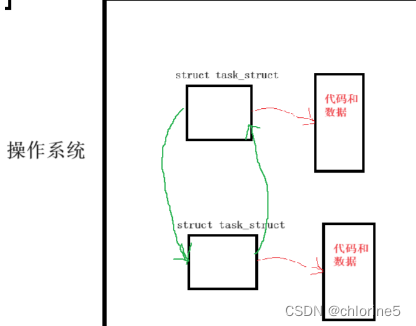
我们曾经说过,创建一个进程需要我们操作系统创建PCB,linux创建task_struct对象,task_struct是操作系统内部所申请的数据结构对象,而struct task_struct最终也能找到自己所对应的代码和数据,换句话说,我们操作系统中存在多个进程,一定会有很多的pcb,我们就可以通过单链表或者双向链表连接起来,只要找到这个链表的头,我们就可以所需要的进程。
为了区分每个进程的不同,所以我们就带给了不同进程不同的PID。
那我们想一想,进程中的PID是在哪放的?PID是进程的属性,那么属性在哪里放的。
我们曾经也说过,学校里的保安在学校里面待着,那我是不是学校的学生呢?或者说在学校这个大环境中,我人在你们学校,那我就是学校的学生?——显然不是
其实人在不在根本就不重要,关键是各位学生的属性就是个人信息是不是在学校教务管理系统里,才是学校的学生。所以学生的属性必须在学校教务管理系统中才能认定你是学校的学生,换言之,我是保安,我给自己编一个学号,那这个学号认嘛?——当然不认
因为这个学号信息必须要保存在学校教务系统中的特定的字断里。
这里就说明了,一个进程对应了特定的PID,这个PID一定是在自己的PCB中(task_struct)
先描述再组织,描述是每个学生属性的时候,需要给自己的学号一样加入其中。
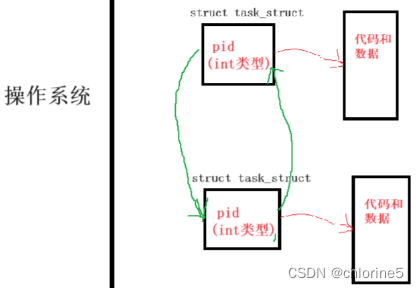
所以在ps搜索中
ps的本质是:遍历单链表,然后遍历的时候,再对应struct结构体相当的属性都拿出来,然后给格式化打印出来,所以我们看到的ps ajx有很多
既然ps能遍历链表,也能显示所有列表进程信息,那我如何想获取自己的PID呢??怎么样能拿到我自己的PID呢?
task_struct是内核维护的结构,那么PID数字也是操作系统内维护的,我们也知道,操作系统不相信任何人,我们不可能直接拿着task_struct对象进行访问PID,不能让ps ajx指令绕过操作系统直接访问里面的数据,必须得通过系统调用接口,所以我们就可以想到,系统内肯定有一个可以调用系统调用接口的指令——getpid()(或者进程标识符)
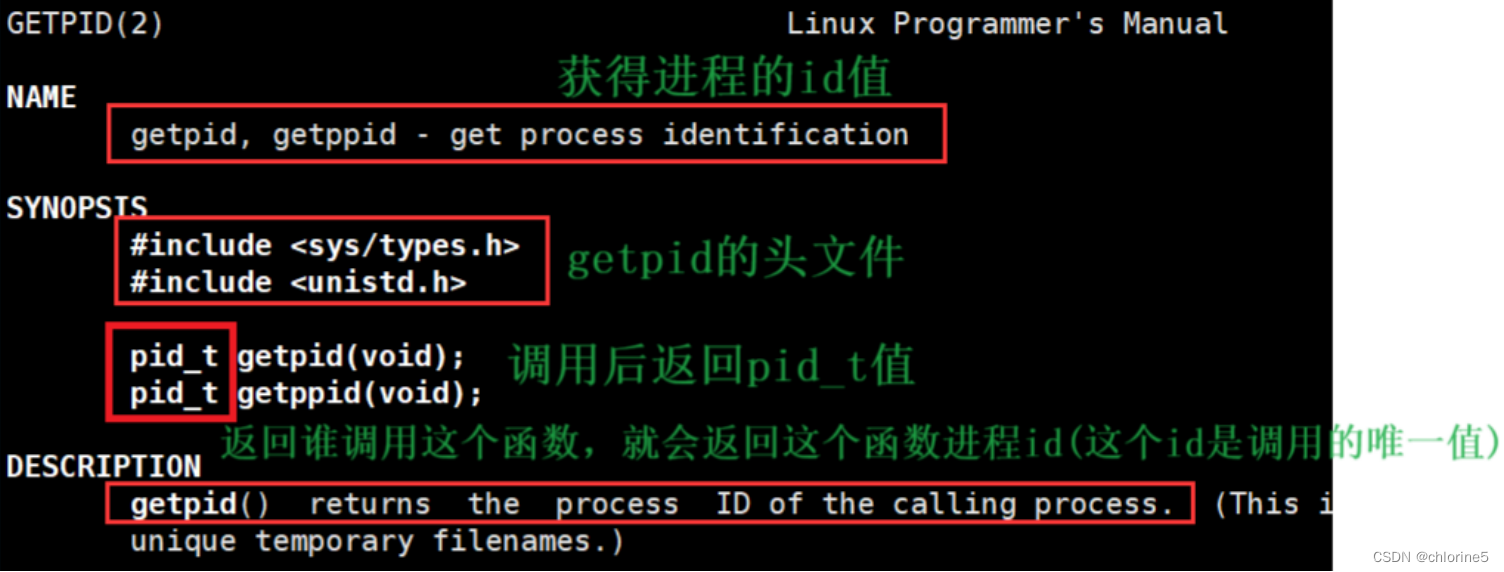
再系统中找到自己task_struct,从中找到pid值,然后返回给上层,上层就拿到了我的pid

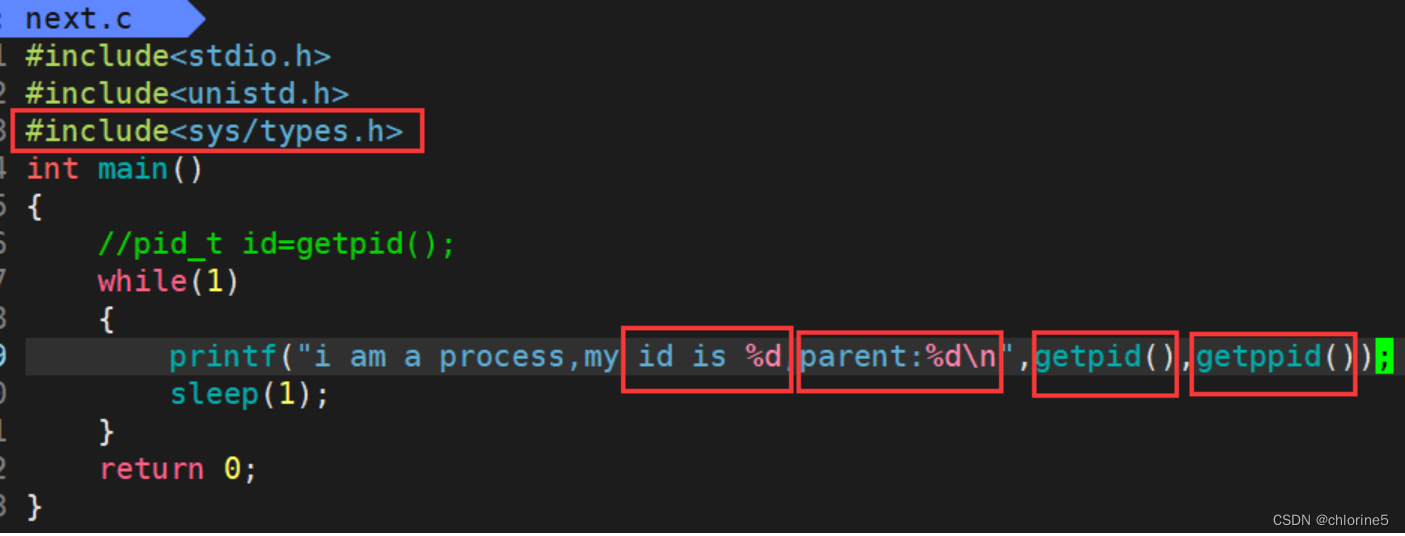
我们先给next.c文件编辑,带上getpid调用函数
设置脚本让其一直循环
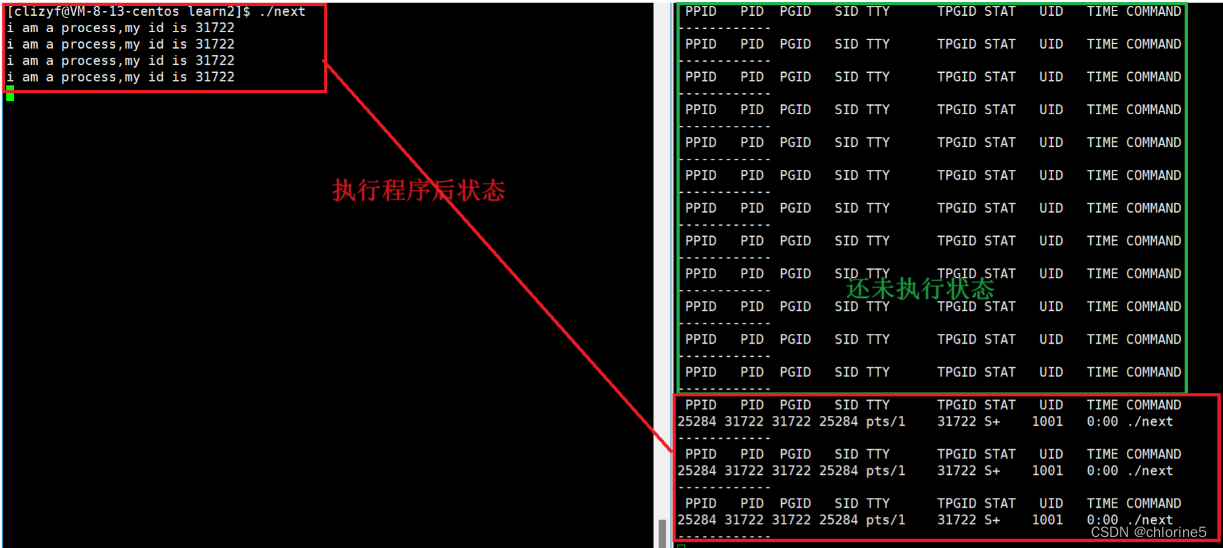
当程序一执行,更新,就可以看到PID——31722
ctrl c结束程序后,监视进程空了
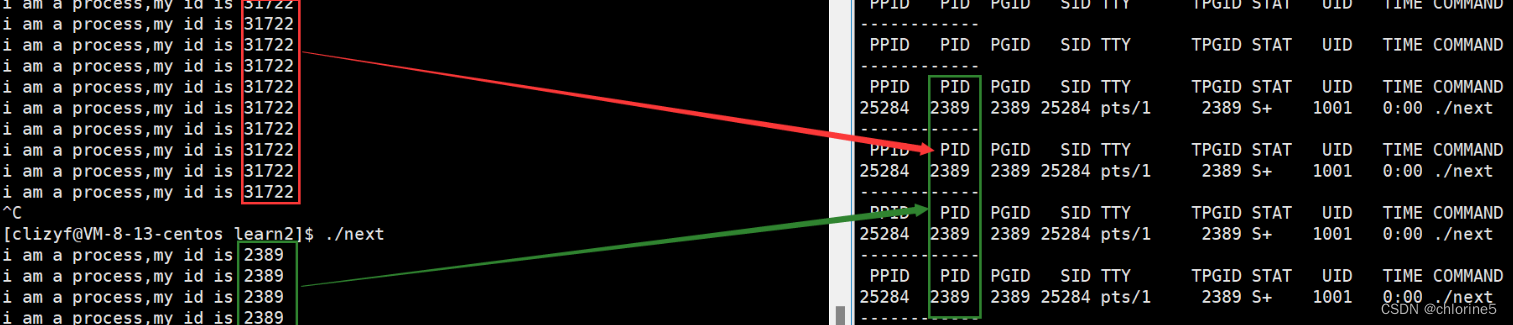
我们清晰的发现,我们每进程一次,每次的pid都是不同的。(高考考入一个大学,学号是23,对其大学不满意回去复读,另一年考入另一所自己满意的大学,学号是24,不同批次的学生进来,学校都会给出不一样的学号)
每次运行进程时都会分配一个pid给此进程,但是pid只在此进程中有效,关闭后就失效,下次再启动进程时,就是不一样的pid虽然都是一样的可执行程序。

🎈ppid(不变化)
除了我们自己的pid之外,进程还有自己的父pid(ppid)


我们先给next.c文件编辑,带上getppid调用函数指自己的父母

这个和pid过程一样
我们联想到王婆和操作系统之间的事
王婆不想给自己的牌子砸了,所以就找了些实习生去解决,不需要王婆亲自去解决了,派实习生去解决,所以我们的-bash就是王婆
- 1.运行一个进程时,系统会自动创建bash进程
- 2.命令行再执行所有的程序或者指令时,它所对应的进程,所对应的父进程就是bash本身。我们自己执行的程序或者指令都是bash进程的子进程。
- 3.执行出问题的时候,只会是子进程出问题,不会影响bash进程(关于为什么不影响以后再说)
- 4.我们启动xshell时候,系统自动生成bash进程,显示命令行。


这就是为什么我们执行程序或者指令的时候,我们的父进程ppid都是不改变的。pid每次都是变化的。
- 计算机中没有母亲进程,只有父亲进程。
- pid是自己的,ppid是父亲的
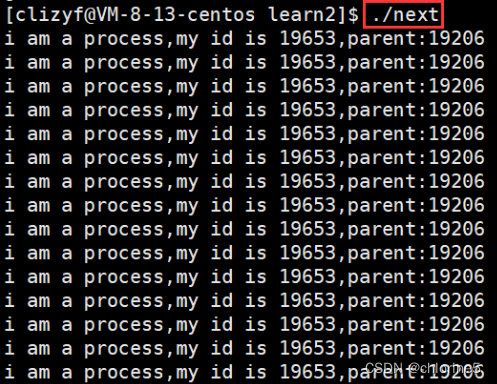
我们进行下一个问题:使用系统调用接口和c接口一样的,在系统角度上./next表示创建进程,那如何手动创建进程呢?接下来带来了解fork
🎓通过系统调用创建进程-fork初识
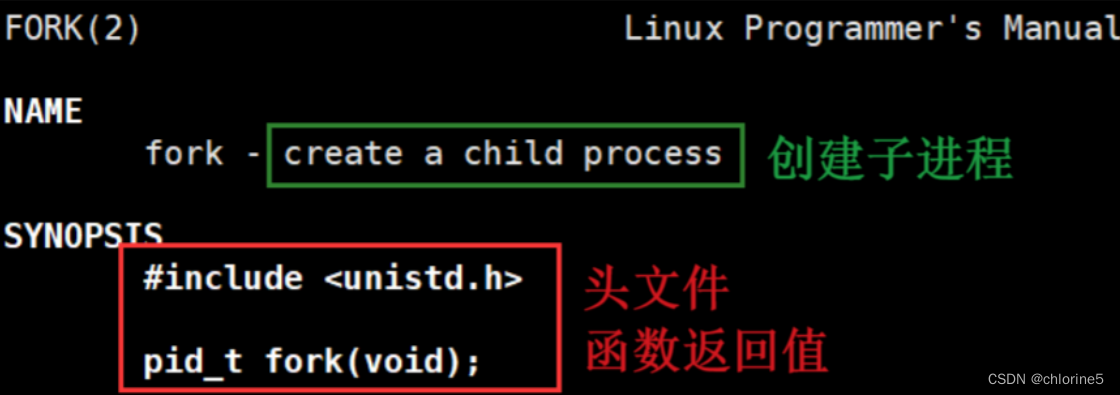
- 运行 man fork 认识fork
- fork有两个返回值
- 父子进程代码共享,数据各自开辟空间,私有一份(采用写时拷贝)
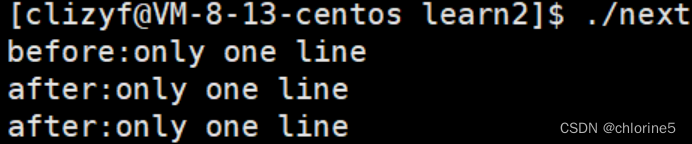


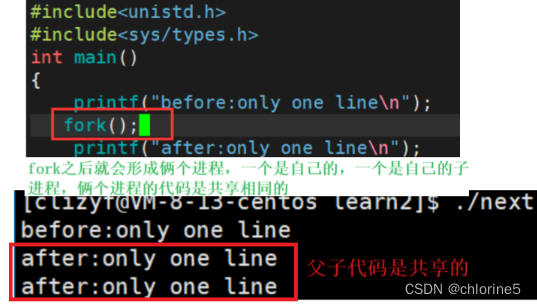
fork函数执行后,after打印了俩次,这种现象是为什么呢?
因为用fork创建进程的时候,fork执行之前只有一个执行流,fork执行之后,就会变成俩个进程。
🎈Linux中的fork()函数
在Linux中,fork()函数是创建进程的基础。它是一个系统调用,用于创建一个新的进程作为当前进程的副本。新进程将拥有与原进程相同的代码、数据和堆栈,但是拥有不同的进程ID(PID),并且它是原进程的子进程。
🎈函数功能
fork()函数的作用是在当前进程中创建一个新的子进程。
🎈函数返回值
如果fork()函数成功创建了一个子进程,则在父进程中返回子进程的PID,在子进程中返回0。如果出现错误,则返回一个负值。
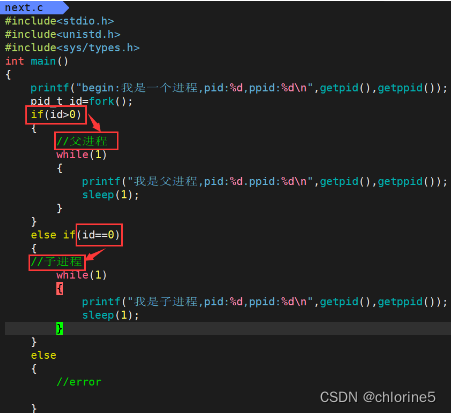
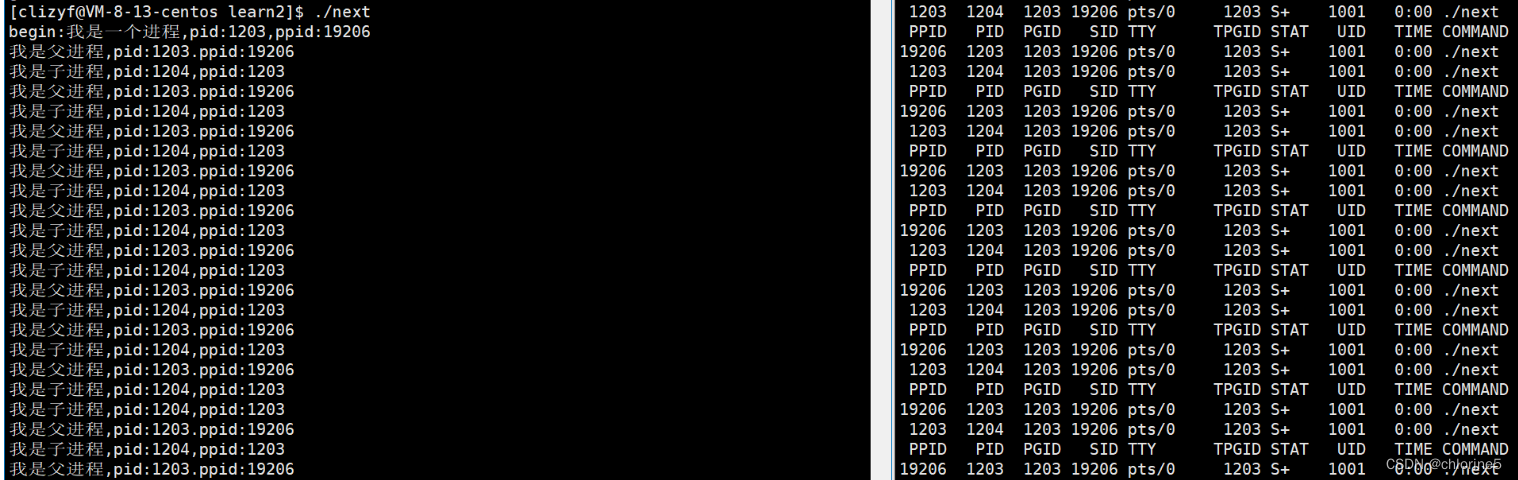
我们可以清晰的看见,同一个程序中,有俩个死循环在进行。在以前在学习的时候,c代码是不可能出现俩个死循环在进行,但现在实现了俩个死循环在进行,为什么呢?
因为fork之后变成了俩个进程。这俩个进程分别叫做父进程,子进程。而
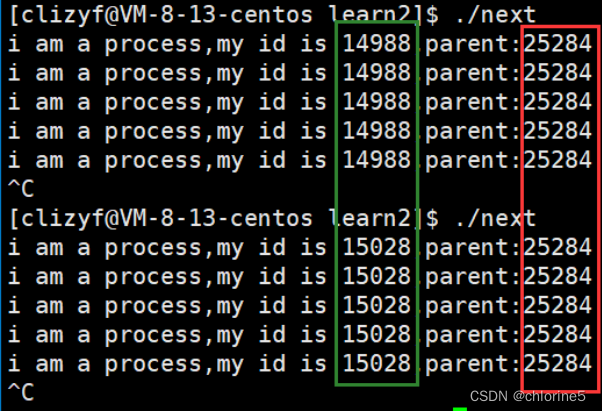
- 返回值大于0,代表的是父进程,返回的ppid值是19206,pid值是1203
- 返回值等于0,代表的是子进程,返回的ppid值是1203,pid的值1204
说明俩者关系是父子关系。
一开始的ppid是19206,然后我们查看,19206就是我们起初的bash


我们在进程中bash和普通执行./next一样,创建进程了,创建之后系统就会给这个进程分配了一个pid 1203,后来进程被操作系统调用之后,运行到fork后,就一分为二分成俩个执行分支,一个是父进程,一个是子进程,父进程就是自己,子进程就是自己创建的分支,这就是进程之间的关系。
所以程序都可以执行,只不过是单进程,但今天遇到fork,它会建立自己的子进程,就形成了俩个进程。
🎈总结
创建进程俩种方式:
- ./运行我们的程序——指令级别
- fork()——代码层面创建自己的子进程
fork英文意思是分叉,一分为二的意思。
所以我们断定,在c代码中不可能实现俩个死循环同时进行,在此可以实现,那么肯定是有俩个进程。我们肯定还有些问题:
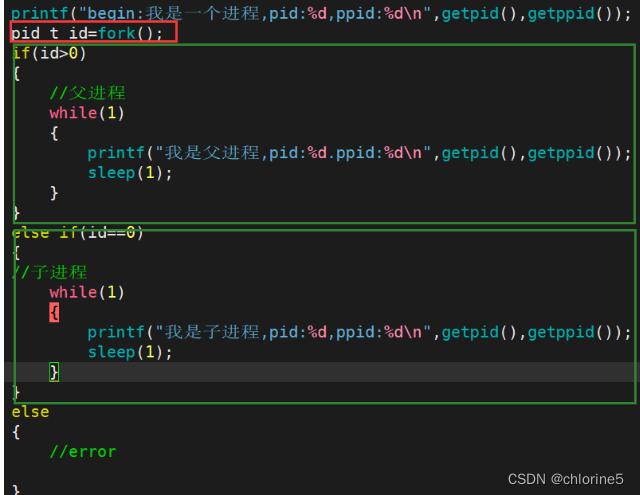
- 1.为什么fork要给子进程返回0,给父进程返回子进程pid?
一般而言fork之后的代码父子共享返回不同的返回值,是为了区分让不同的执行流,执行不同的代码块。

举个生活的例子:一个父亲有多个子女,但是任何一个子女只有一个父亲,所以父进程会对子进程进行控制,一个父亲叫孩子干事情,有几个孩子在一起,到底是叫哪一个呢?必须想办法区分每个子进程,所以我们就有了返回子进程pid,父进程拥有了子进程的pid,用来标定子进程的唯一性。而子女不一样,它就一个父亲,只用返回0标识成功即可。
所以父进程返回子进程pid是为了确定自己返回的是哪个子进程,确定子进程的标识,而子进程返回0是因为只有一个父亲,只用确定自己成功标识即可。
- 2.一个函数是如何做到返回俩次的?如何理解?
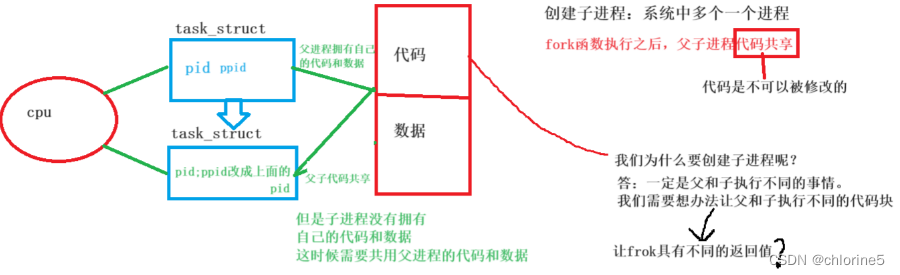
先了解以下fork干了什么事?进程=内核数据结构+代码和数据

-
3.一个变量怎么会有不同的内容?如何理解?
任何平台,进程在运行的时候,是具有独立性的。
在电脑中,xshell如果崩了,并不影响我使用csdn,一个进程退出或者崩溃,不会影响我另一个进程的运行。ps:生活中,当你成人找到工作了,你对你爸妈说你长大了独立了,可以赚钱养活自己。独立的本质就是割裂关系,不会和任何人产生关系。
子进程和父进程也是俩个进程,进程和进程之间是具有独立性,直接决定了,绝对不能让父子进程访问一个数据,因为数据可能会被修改,不能让父进程和子进程共享同一份数据。

子进程完全可以给父进程的数据拷贝一份,然后修改,互不影响,遵守了父子进程的独立性。
如果父进程的数据很多,子进程,数据层面的写时拷贝:
操作系统中,当它要访问对应的数据时,操作系统内部也会对父进程中子进程需要的数据进行拦截,而操作系统会重新给子进程创建一块空间,让子进程写入数据,这个数据就是子进程的,用多少给你多少空间,然后给子进程拷贝数据。这就是写时拷贝。
当父进程正在return写入时候,返回值是父进程的数据,父进程的return写入子进程的写入,就要发生写时拷贝,拷贝的时候,操作系统对同一个id值拷贝了俩份,最后父子进程进行时,俩个id值不一样。所以子进程读取自己id值是自己新空间的数据,父进程返回的数据是老空间的数据,同一个id值并不是同一个内存块。对于同一个变量名id,是怎么做到父子进程看到不同的值呢?——这是后面的地址空间问题,后面会详细解说。
当我们调用fork函数之后,父进程将子进程创建出来,父子进程后续的代码是共享的,父和子各自形成return,俩次返回时,在id层面上发生写时拷贝,然后显示不同的id值,所以后续,我们可以通过id对if/else判断,而对父子进程进行分流,执行不同的代码块,父进程和子进程进行不同的代码,并且在各自的进程中进行死循环运行。——fork()
我不希望自己这样,但确实我就是这样的。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









