







摘要
本文旨在从专业的角度对Hadoop技术进行全面而深入的剖析,探讨其在大数据处理领域的核心地位、关键特性、架构设计、数据存储与处理机制,以及在实际应用中所展现的优势与面临的挑战。同时,本文还将对Hadoop的发展历程、社区生态、技术演进以及未来趋势进行前瞻性的分析,以期为相关领域的研究者和从业者提供有价值的参考和指导。

一、引言
Hadoop作为一种开源的分布式存储和计算框架,已成为大数据处理领域的基石。其独特的架构设计和强大的数据处理能力,使其在处理海量数据集时具有显著优势。本文将从专业的视角出发,对Hadoop的原理、架构、数据存储与处理机制进行深入分析,并探讨其在实际应用中的优势与挑战。
二、Hadoop技术概述
Hadoop是一个开源的分布式存储和计算框架,由Apache基金会维护。它的目标是提供一个可靠、可扩展且高效的平台,以支持大规模数据处理和分析。Hadoop的核心组件包括Hadoop Distributed File System (HDFS)和MapReduce。HDFS负责存储大量数据,而MapReduce则是一个编程模型,用于处理这些数据。此外,Hadoop还包含其他重要组件,如YARN(资源管理框架)、Hive(数据仓库工具)和Pig(高级脚本语言)等。这些组件共同构建了一个强大的大数据处理平台。
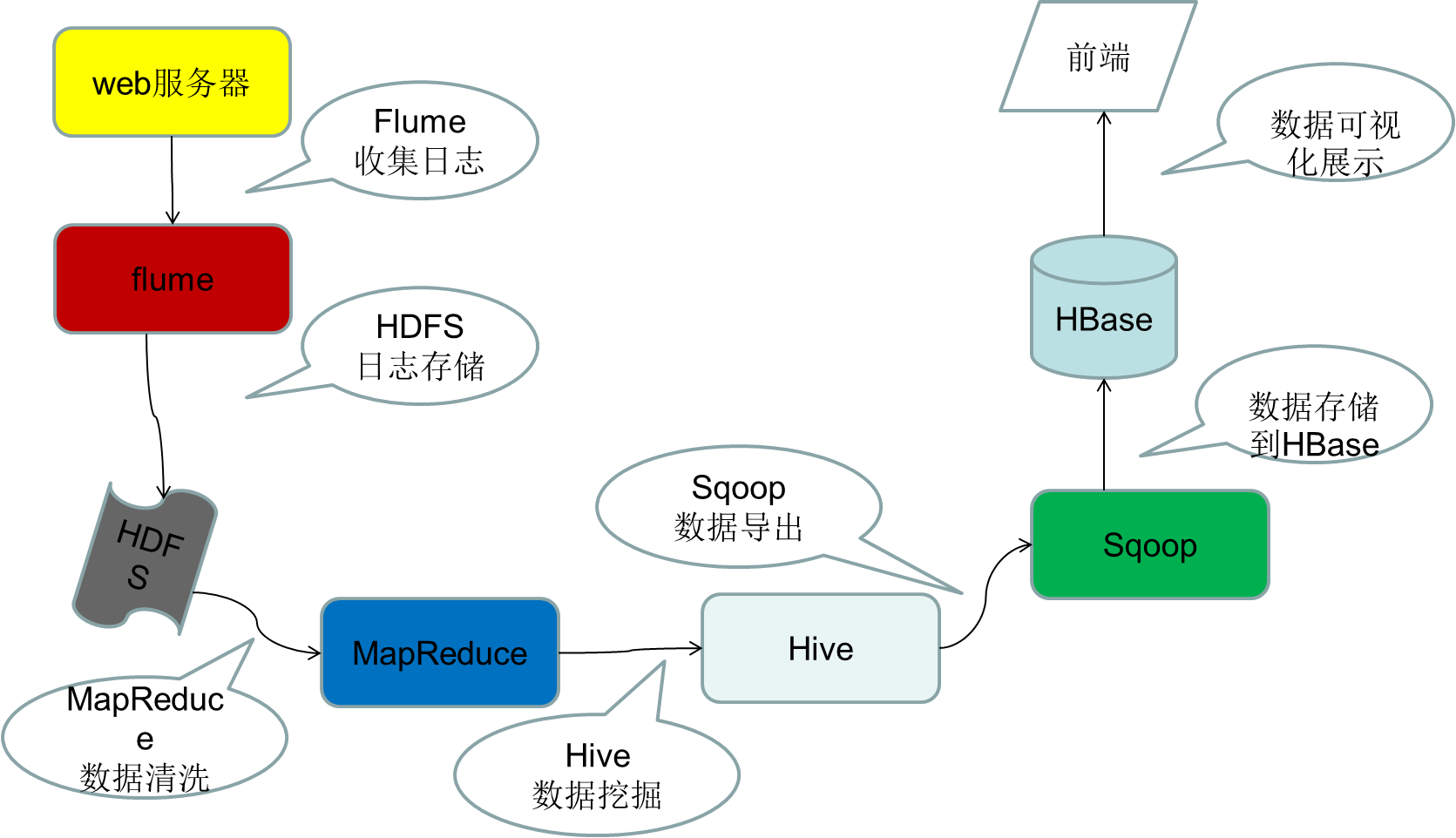
三、Hadoop的架构设计
Hadoop的架构设计非常清晰,主要围绕其核心组件进行构建,以确保高效、可靠地处理和分析大规模数据集。以下是Hadoop架构设计的主要组成部分和特点:
-
Hadoop生态体系:
- Hadoop不仅是一个单独的技术,而是一个完整的生态系统,包括多种组件和工具,用于处理各种大数据任务。
- 核心组件包括Hadoop Distributed File System (HDFS)、MapReduce、YARN等。
-
HDFS(Hadoop Distributed File System):
- 分布式文件系统,用于存储大规模数据集。
- 采用主从架构,包括一个NameNode(管理元数据)和多个DataNode(存储数据块)。
- 默认情况下,每个数据块会有三个副本,存储在不同的DataNode上,以提高数据可靠性。
-
MapReduce:
- 编程模型,用于处理和分析存储在HDFS上的大数据。
- 将计算过程分为两个阶段:Map(映射)和Reduce(归约)。
- Map阶段并行处理输入数据,Reduce阶段对Map结果进行汇总。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2714
2714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









