







 本文详细介绍了堆的概念,包括小根堆和大堆的定义,以及它们在数据结构中的重要性。重点讲解了堆的相关算法,如初始化、销毁、向下调整、堆的插入和删除,以及堆排序和Top-K问题的解决方案。
本文详细介绍了堆的概念,包括小根堆和大堆的定义,以及它们在数据结构中的重要性。重点讲解了堆的相关算法,如初始化、销毁、向下调整、堆的插入和删除,以及堆排序和Top-K问题的解决方案。
一、堆的概念
如果有一个n个元素的集合
,把它的所有元素按照完全二叉树的顺序存储方式存储在一个一维数组中,并满足:
且
,则称之为小根堆或最小堆,简称为小堆。大堆的定义与之相反。
简而言之,堆就是一颗顺序存储的对元素排列顺序有要求的完全二叉树。
从定义不难看出:大堆的根节点是所有元素中最大的,父节点的值大于等于孩子节点;小堆的根节点是所有元素中最小的,父节点的值小于等于孩子节点。
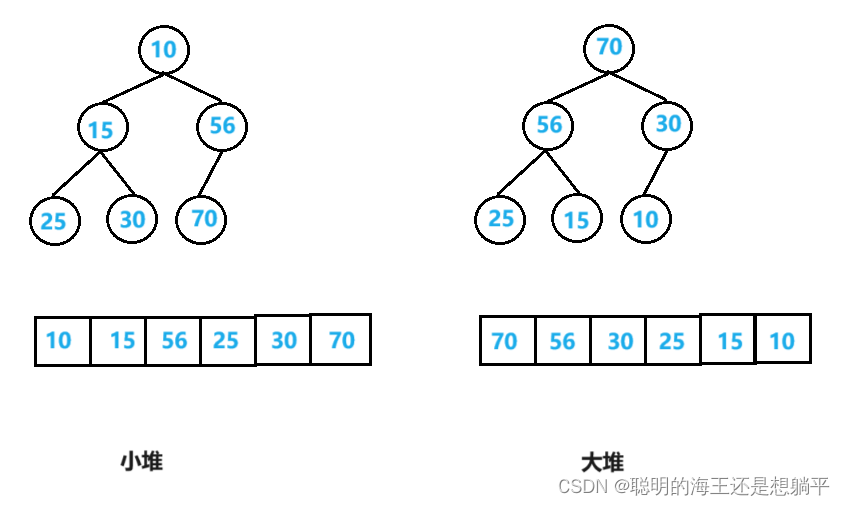
注:堆只对父节点和它的孩子节点的大小关系作出要求,对兄弟节点的大小关系不做要求。
二、堆的相关算法(以小堆为例)
1.类型声明
typedef int HPDataType;
typedef struct Heap
{
HPDataType* a;
int size;
int capacity;
}HP;2.初始化
void HeapInit(HP* h)
{
assert(h);
h->a = NULL;
h->size = h->capacity = 0;
}3.销毁
void HeapDestroy(HP* h)
{
assert(h);
free(h->a);
h->a = NULL;
h->size = h->capacity = 0;
}4.向下调整算法
该算法是堆最重要的算法之一,是其他算法和应用的基础!
现在有一颗完全二叉树,其根节点的左子树和右子树都满足小堆的性质,只有根节点不满足,要想让这棵树变成小堆,就需要从根节点开始,逐步向下交换父节点和其较小的孩子节点,直至满足小堆。该过程就叫做向下调整。(注:向下调整的前提是其左右子树必须都是小堆)
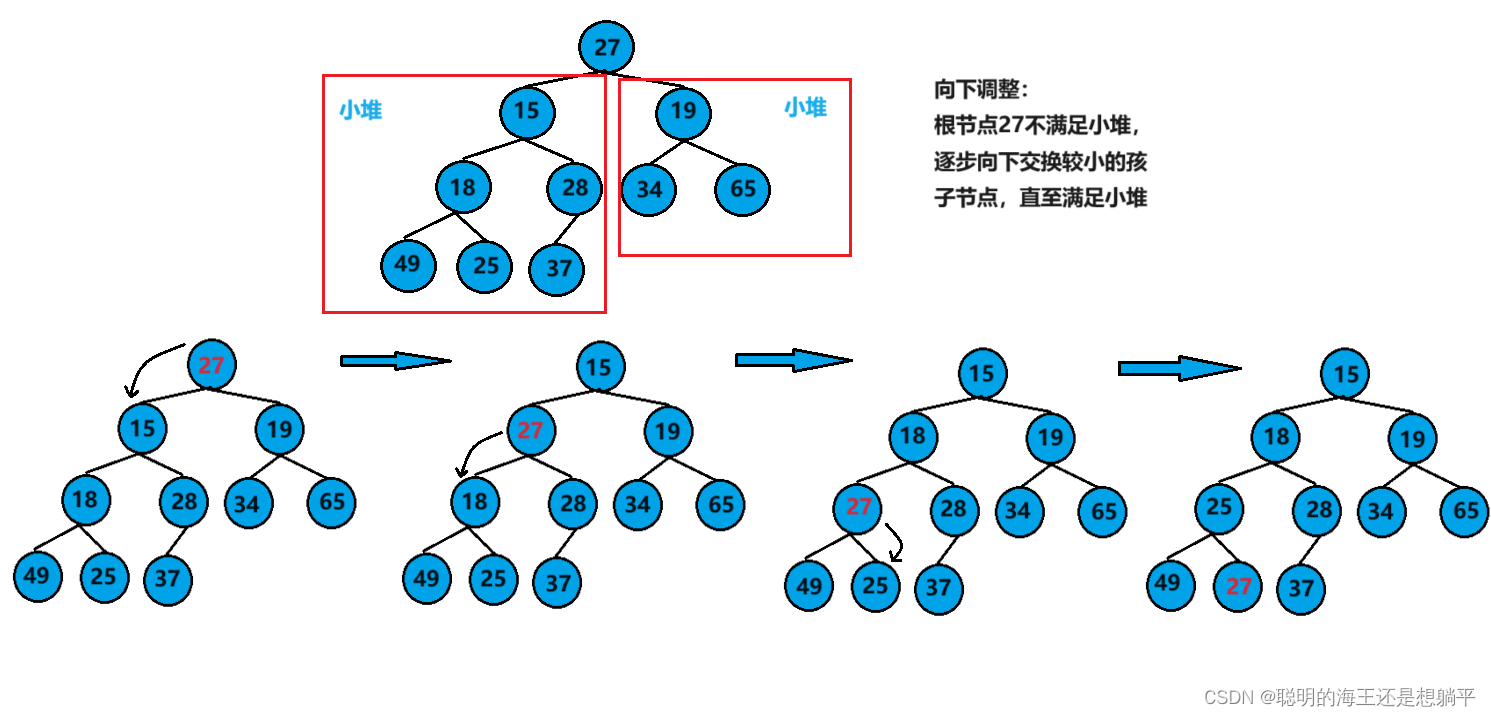
代码实现:
void Swap(HPDataType* x, HPDataType* y)
{
HPDataType temp = *x;
*x = *y;
*y = temp;
}
void AdjustDown(HPDataType* a, int size, int parent)
{
//交换的孩子为较小的那一个
int child = parent * 2 + 1;
while (child < size)
{
if (child + 1 < size && a[child + 1] < a[child]) //
{
child++;
}
if (a[child] < a[parent]) //
{
Swap(a + child, a + parent);
parent = child;
child = child * 2 + 1;
}
else
{
break;
}
}
}5.堆的插入及向上调整算法
在小堆上插入一个元素并保持新的集合依然是一个小堆,应该怎么操作呢?
先在数组尾部插入一个元素,然后从该节点开始,逐步向上交换孩子节点和父节点,直至满足小堆。
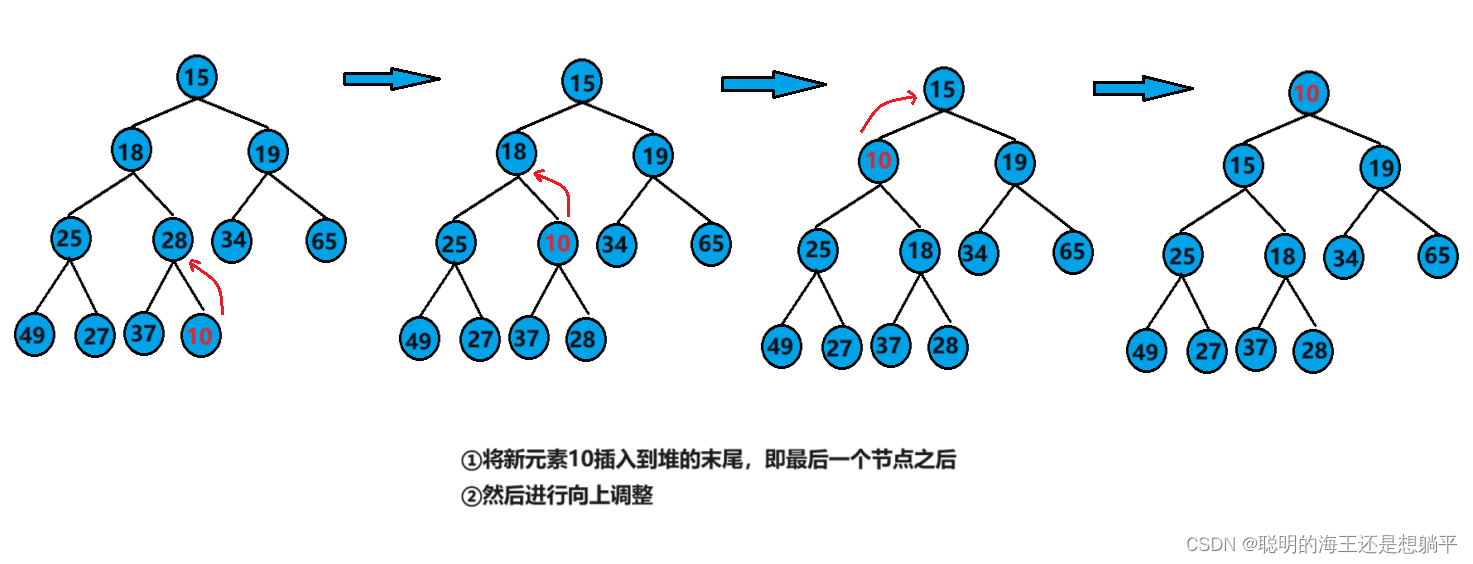
代码实现:
void AdjustUp(HPDataType* a, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] < a[parent]) //
{
Swap(a + child, a + parent);
child = parent;
parent = (parent - 1) / 2;
}
else
{
break;
}
}
}
void HeapPush(HP* h,HPDataType x)
{
assert(h);
if (h->capacity == h->size)
{
int newcapacity = h->capacity == 0 ? 4 : h->capacity * 2;
HPDataType* temp = (HPDataType*)realloc(h->a, sizeof(HPDataType) * newcapacity);
if (temp == NULL)
{
perror("realloc fail");
exit(-1);
}
h->a = temp;
h->capacity = newcapacity;
}
h->a[h->size++] = x;
AdjustUp(h->a, h->size - 1);
}6.堆的创建
现在给一个数组,其中的元素是乱序的,从逻辑上可以把它看做一颗完全二叉树,但不是堆。需要通过调整算法将其变成堆。
方法有二:
①向下调整建堆
由于向下调整的前提是其左右子树均为堆,现在的数组完全乱序,所以不能从根节点开始调整。应该从最后一个非叶子节点开始,依次往前,直到根节点,都进行一次向下调整,最后就能得到一个堆。
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}②向上调整建堆
每插入一个元素都要调用向上调整算法,最终的堆可以看做将数组中的每个元素依次插入堆,因此对每个元素都调用一次向上调整算法即可。
for (int i = 1; i < n; i++)
{
AdjustUp(a, i);
}既然如此,在实际应用中使用哪一种方法呢?答案是第一种:向下调整建堆!
可以证明(证明从略),向下调整建堆的时间复杂度为,而向上调整建堆的时间复杂度为
,因此选择第一种方法。
7.堆的删除
堆的删除是删除堆顶的元素,操作为:先将堆顶元素与最后一个元素交换,然后删除最后一个元素并对根节点(堆顶)进行向下调整。
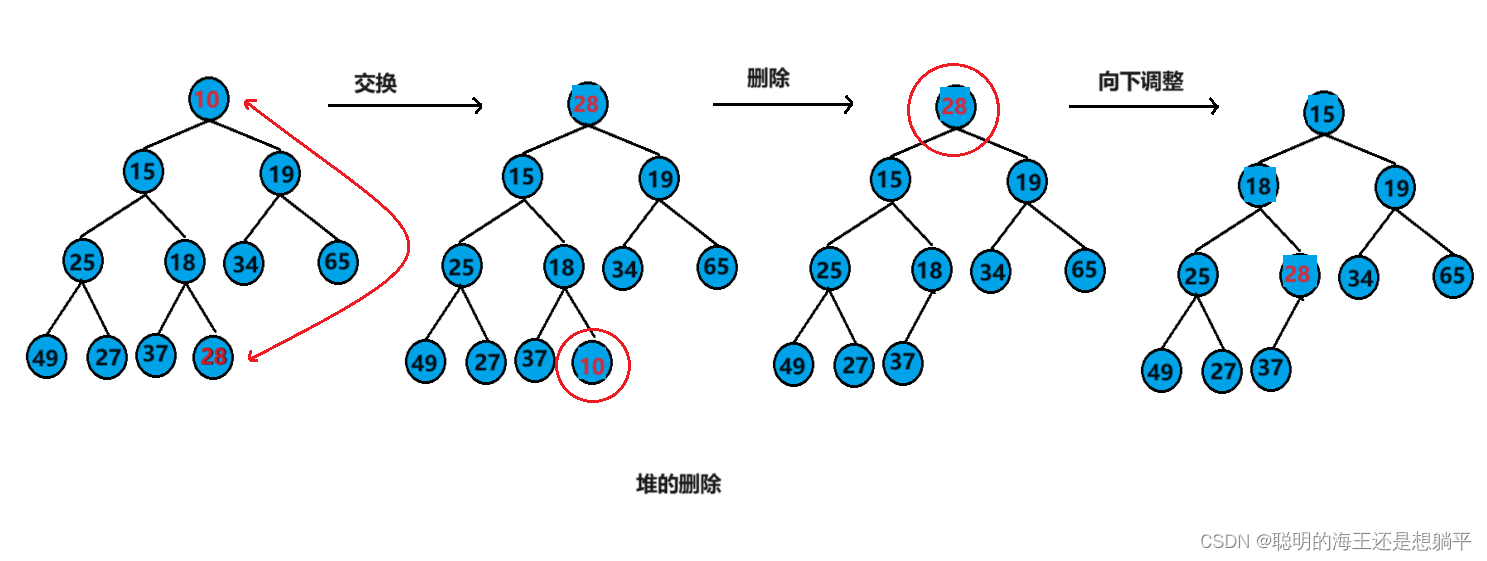
代码实现:
void HeapPop(HP* h)
{
assert(h);
assert(h->size > 0);
//首尾交换
Swap(h->a, h->a + h->size - 1);
//尾删
h->size--;
//向下调整
AdjustDown(h->a, h->size, 0);
}三、堆的应用
1.堆排序
堆排序即利用堆的思想进行排序,步骤为:
①建堆
升序:建大堆
降序:建小堆
②利用堆的删除思想进行排序
交换堆顶(第一个)和堆尾(最后一个)元素,这样最后一个元素就是所有元素中最小的(小堆)或最大的(大堆);将剩余元素看做一个集合,对堆顶元素进行向下调整,重新变成堆;重复上述步骤
void HeapSort(HPDataType* a, int n)
{
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
int index_end = n - 1;
while (index_end > 0)
{
Swap(a, a + index_end);
AdjustDown(a, index_end, 0);
index_end--;
}
}2.Top-K问题
现在有一组非常庞大的数据,要求找出其中最大的(或最小的)前K个数据。(K通常很小)
思路:首先想到的最直接的方法就是排序,排序确实可以达到目的,但不可取,因为数据量非常庞大,时间开销很大。正确的做法是:
①用数据集合中的前K个元素建堆
找最大的前K个:建小堆
找最小的前K个:建大堆
②用剩余的元素依次与当前堆顶元素进行比较
以小堆为例,若比堆顶元素小,则直接进行下一个元素的比较;若比堆顶元素大,则用该元素替换堆顶元素,并进行向下调整重新变成小堆。
这样最后堆上的K个元素就是所求。
程序代码实现:
//创建一个庞大数据集
void CreateData()
{
FILE* fp = fopen("big.txt", "w");
if (fp == NULL)
{
perror("fopen error");
return;
}
srand(time(NULL));
int n = 1000000;
for (int i = 0; i < n; i++)
{
int x = (rand() + i) % 1000000;
fprintf(fp, "%d\n", x);
}
fclose(fp);
}
void PrintTopk(FILE* fp, int k)
{
//最大k个,建小堆
//向下调整建堆
/*int* a = (int*)malloc(sizeof(int) * k);
for (int i = k - 1; i >= 0; i--)
{
fscanf(fp, "%d", a + i);
if (i <= (k - 1 - 1) / 2)
{
AdjustDown(a, k, i);
}
}*/
//向上调整建堆
int* a = (int*)malloc(sizeof(int) * k);
for (int i = 0; i < k; i++)
{
fscanf(fp, "%d", a + i);
AdjustUp(a, i);
}
int temp;
while (fscanf(fp, "%d", &temp) != EOF)
{
if (temp > a[0])
{
a[0] = temp;
AdjustDown(a, k, 0);
}
}
for (int i = 0; i < k; i++)
{
printf("%d ", a[i]);
}
}
int main()
{
CreateData();
FILE* fp = fopen("big.txt", "r");
if (fp == NULL)
{
perror("fopen error");
return 1;
}
PrintTopk(fp, 6);
return 0;
}














 5727
5727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









