







一.数据的类型
1 结构化的数据
结构化的数据是指可以使用关系型数据库表示和存储,表现为二维形式的数据,一般特点是:数据以行为单位,一行的数据表示一个实体的信息,每一行数据的属性是相同的.
2 半结构化数据
非关系模型的,有基本的固定的结构模式的数据,例如日志文件,XML文档,jsonW文档等.
3 非结构化的数据
见名知意,就是没有固定结构的数据,各种文档,图片,视频/音频都是属于非结构化的数据,对于这类数据,我们一般直接整体进行存储,而且一般存储为二进制的数据格式.
二.简介HTML
1 HTML
Ⅰ HTML 是一种超文本标记语言(Hyper Text Markup Language)是用来描述网页的一种语言.
①超文本的解释
它可以加入图片,声音,动画,多媒体等内容,即:超越文本的限制;不仅如此,它还可以从一个文件跳转到另一个文件,与世界各地的主机的文件连接,即:超级链接文本
Ⅱ HTML 不是一种编程语言,而是一种标记语言(markup language)
Ⅲ 标记语言是一套标记标签(markup tag)
Ⅹ 简单来说,就是:网页是由网页元素组成的,这些元素利用HTML标签描述出来,然后通过浏览器解析,就可以显示给用户了.
2 HTML 的骨架标签总结
①基本的框架如下图所示:
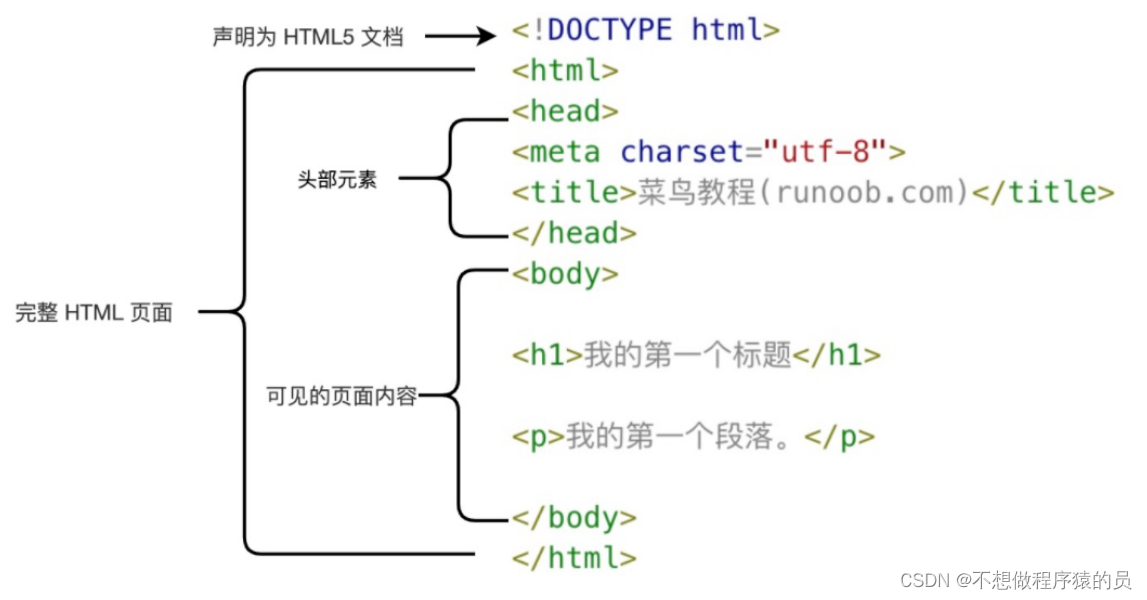
② 各个标签的解释如图

3 HTML标签关系
父子级的标签
<head>
<title> </title>
</head>
兄弟级的标签
<head></head>
<body></body>
1 html双标签可以分为: 一种是 父子级 包含关系的标签 一种是 兄弟级 并列关系的标签
三.CSS选择器的详解
在css种,选择器是一种模式,用于选择需要添加样式的元素,那么我们就可以使用css选择器,在html中找到所对应的标签.
1 简单的例子如下:
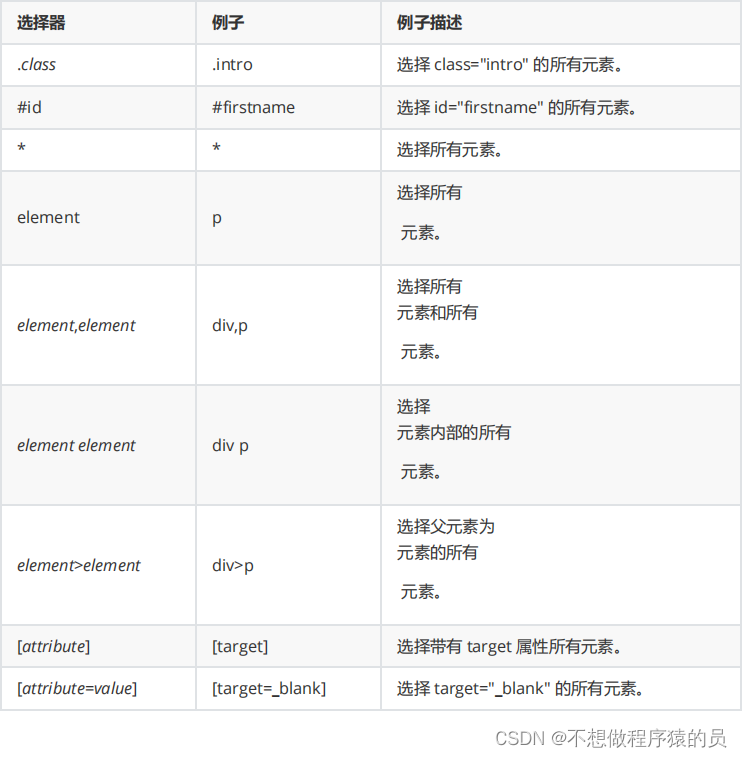
2 标签选择器
标签选择器其实就是我们经常说的html代码中标签.例如:html, span, p, div, a, img等等;比如我们想要设置网页中的p标签内的一段文字的字体和颜色.那么css的代码就如下所示:
# 简化的html标签
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p>css标签选择器的介绍</p>
<p>标签选择器、类选择器、ID选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
import parsel
selector = parsel.Selector(html)
span = selector.css('span').getall()
print(span)
运行结果:
[‘ 我是一个span标签’]
3 类选择器
类选择器在我们今后的css样式编码中是最常见到的,它是通过为元素设置单独的class来赋予元素样式效果,使用语法:(我们在这里为p标签单独设置一个class 类属性,代码就如下所示)
# 简化的html标签
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p class="top">css标签选择器的介绍</p>
<p class="top">标签选择器、类选择器、ID选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
import parsel
selector = parsel.Selector(html)
p = selector.css('.top').getall()
print(p)
运行结果:
[‘
css标签选择器的介绍
’, ‘标签选择器、类选择器、ID选择器
’]详细的讲解:
- 类选择器都是使用英语的圆点(.)开头.
- 每个元素可以有多个类名,名称可以任意起名(但是不要取中文名,一般都是与内容相关的英文的缩写)
4 ID选择器
ID选择器类似于类选择器,作用同类选择符相同,但是也有一些区别.
# 简化的html标签
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p class="top">css标签选择器的介绍</p>
<p class="top">标签选择器、类选择器、ID选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
import parsel
selector = parsel.Selector(html)
p = selector.css('#content').getall()
print(p)
结果如下:
[‘
css标签选择器的介绍
’, ‘标签选择器、类选择器、ID选择器
’]详细的讲解:
1.ID选择器为标签设置id=“ID名称”,而不是class=“类名称”
2.ID选择符的前面是符号为井号(#),而不是英文圆点(.).
3.ID选择器的名称是唯一的,即相同名称的id选择器在一个页面中只能出现一次;
5 组合选择器
可以多个选择器一起使用,就是组合选择器.
# 简化的html标签
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p class="top">css标签选择器的介绍</p>
<p class="top">标签选择器、类选择器、ID选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
import parsel
selector = parsel.Selector(html)
result = selector.css('p#contend.top').getall()
print(result)
结果如下:
[‘
css标签选择器的介绍
’, ‘标签选择器、类选择器、ID选择器
’]6 伪类选择器
可以用==:==指定选择想要提取的第几个标签.
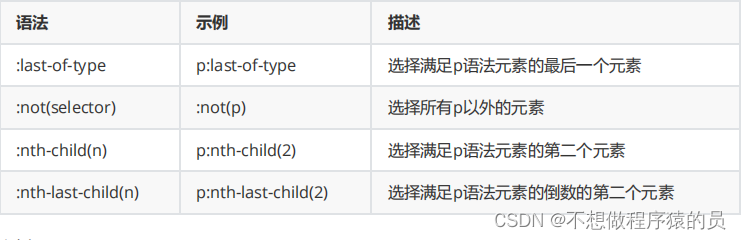
# 简化的html标签
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p class="top">css标签选择器的介绍</p>
<p class="top">标签选择器、类选择器、ID选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
import parsel
selector = parsel.Selector(html)
result = selector.css('p:nth-child(2)::text').getall()
print(result
结果如下:
[‘标签选择器、类选择器、ID选择器’]
7 属性提取器
可以用==::==来提取标签包含的属性.
# 简化的html标签
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p class="top">css标签选择器的介绍</p>
<p class="top">标签选择器、类选择器、ID选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<span> 我是一个span标签</span>
</body>
</html>
"""
import parsel
selector = parsel.Selector(html)
result = selector.css('p#contend.top::text').getall()
print(result)
result = selector.css('a::attr(href)').getall()
print(result)
结果如下:
[‘css标签选择器的介绍’, ‘标签选择器、类选择器、ID选择器’]
[‘https://www.baidu.com’]
四. 学习CSS的好处
CSS作为前端的三大功能之一,学习好了之后对于我们的前端的帮助也是很大的,在爬虫中还有其他的两种数据分析的方法(正则表达式,xpath),小编会尽快的更新的.感谢你们的陪伴.
















 960
960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











