






想要了解赫夫曼树,我们要先理解以下几个概念:
路径:(通常是结点之间的)树中一个结点到另外一个结点之间的分支构成的路径。
路径长度:两个结点之间的分支数。
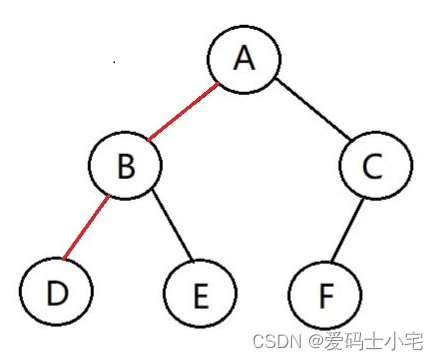
如下图中AD结点之间的路径就是标红的那一段,路径长度就是2。可见每一层的结点到根结点的路径长度是固定的,第2层路径长度为2,第3层路径长度为3。
树的简单路径长度(树的路径长度):从树的根结点到每一个结点的路径长度之和。设根节点所在层位于第0层,计算方法:树的简单路径长度=第几层×该层的结点数。下图的数的简单路径长度为:1*2+2*3=8
权:重要性或者理解为权重、关键字等。
为什么要有权?
如果将一棵二叉树中叶子结点看成是查找过程最终获取的信息,那么,中间的分支结点中存放的就是查找过程中选择查找方向的条件。
叶子结点中的信息不同,被查找的频率就不同,使用频率越高的信息,其重要性就越高,也可以说,其权值就越大。而中间的分支结点中的查找条件是查找程序所需要的,不是用户所关心的的内容,站在用户的角度,中间分支结点的权值就可以视为0。
叶结点的加权路径长度:从该叶子结点到树根之间的路径长度与该叶子结点上的权的乘积。
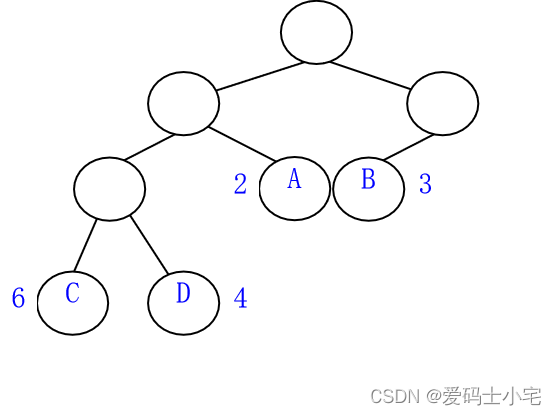
树的加权路径长度:树中所有权不为0的叶子结点的加权路径长度之和。下图的树的加权路径长度为: 6*3+4*3+2*2+3*2=40
赫夫曼树又称为最优二叉树。有n个结点,它们分别具有不同的权值,将这n个结点作为叶结点可以构造出m种不同的二叉树,这些二叉树具有不同的加权路径长度,则其中加权路径长度最小的二叉树称为最优二叉树或赫夫曼树。
构造方法这里只利用链表结构及二叉树结构完成构造赫夫曼树,还有利用堆等方法。
首先定义数据结构的类型,赫夫曼树中结点的结构定义为:
struct HuffmanNode
{
HuffmanNode *link; //指向链表中的后继结点
WeightType weight; //权值
ElementType data; //结点的信息值
HuffmanNode *LChild; //指向左孩子结点
HuffmanNode *RChild; //指向右孩子结点
};
第一个成员是链表的链接域。构建赫夫曼树时,要先将所有的赫夫曼结点链接为一个链表结构。
第二个成员是结点的权值,是构建赫夫曼树的关键字。数据类型可以为整型,也可以为三浮点型等。
第三个成员是结点的实际信息值。。
第四和第五成员是构成赫夫曼树孩子结点的左右链接域。
下面给出链表结构的赫夫曼的构造过程。为了简化描述,下面图中只给出构建赫夫曼树时的权值,其他域的值省略。
现在开始!首先,将结点存为一个简单链表,如图

然后,按权值从小到大排序,完成赫夫曼树的初始化。

删除前面两个权值最小的结点,并将这两个结点的权值相加;
权值相加的和存储到新申请的一个赫夫曼结点的权值成员域中;
并将删除的两个结点链接到新申请的赫夫曼结点的左、右孩子链接域上,成为一棵二叉子树,新申请的赫夫曼结点就是这个二叉子树的根;
再将这个新赫夫曼结点重新插入到链表结点中,并保证链表是按权值大小有序的。
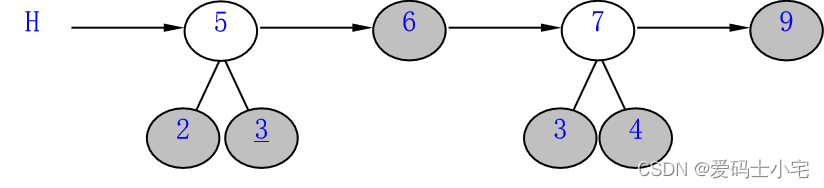
下图删除了2和3,并把这两个作为5的左右孩子,5按顺序插入链表之中。

重复上面这个过程(删2插1),直到链表上只有一个结点为止。
删了3,4;插了7
删了5,6;插了11。删了7,9;插了16
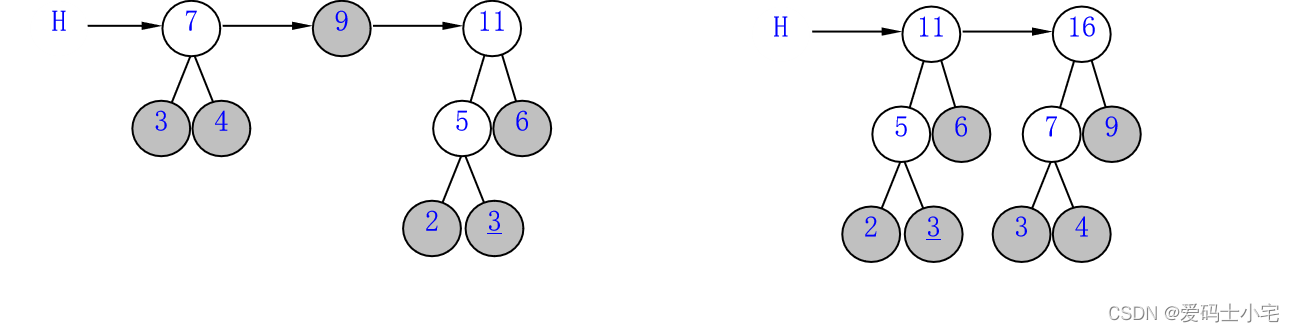
删了11、16;插了27
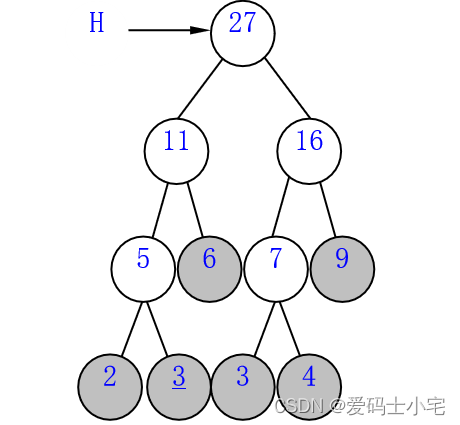
构造完成!从过程来看:赫夫曼树中权值越小的结点就越接近底层,权值越大越靠近根结点。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









