







 BERT是基于Transformer的预训练语言模型,采用双向编码器和MaskedLanguageModeling提升语义理解。Transformer以自注意力机制处理序列数据,而BERT在Transformer基础上解决了单向性和上下文理解问题,适用于多种NLP任务。
BERT是基于Transformer的预训练语言模型,采用双向编码器和MaskedLanguageModeling提升语义理解。Transformer以自注意力机制处理序列数据,而BERT在Transformer基础上解决了单向性和上下文理解问题,适用于多种NLP任务。
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的预训练语言模型,它在自然语言处理任务中取得了重大突破。BERT模型的出现引起了广泛关注,但许多人可能对BERT与Transformer之间的关系感到困惑。本文将介绍BERT模型和Transformer模型之间的关系,帮助读者更好地理解它们的联系和差异。
BERT模型和Transformer模型之间有何关系?

-
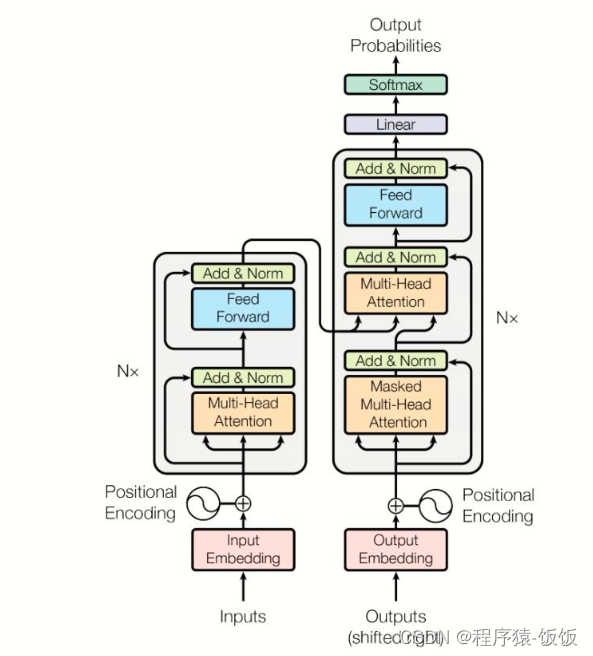
Transformer模型简介:
- Transformer是一种基于自注意力机制的深度学习模型,最初用于机器翻译任务。它通过多头自注意力和前馈神经网络构成的编码器-解码器结构,实现了在序列转换任务中的卓越性能。
- Transformer模型的核心思想是使用自注意力机制来捕捉输入序列中不同位置之间的依赖关系,而不依赖于循环或卷积操作。这种自注意力机制能够同时考虑到整个输入序列的信息,使得模型能够更好地处理长距离依赖。
-
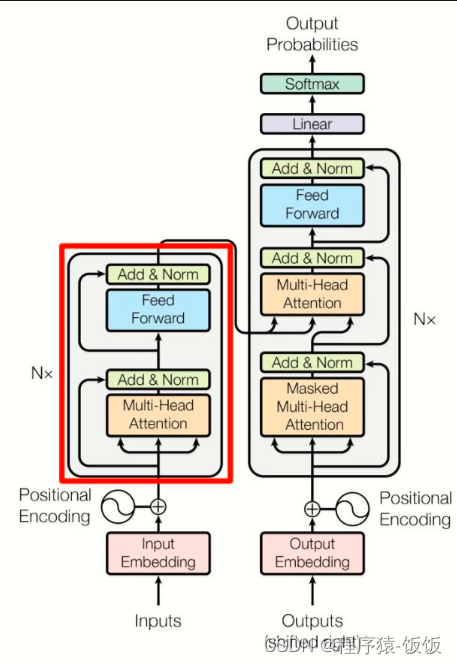
BERT模型的改进:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1012
1012

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









