






移动语义
为什么要用移动语义?
我们回顾一下之前模拟的String.cc
#include <string.h>
#include <iostream>
using std::cout;
using std::endl;
class String
{
public:
String()
//不将字符串初始化为空指针,因为如果使用print函数或者输出流运算符,进行对空指针的访问,会使程序中断。
/* : _pstr(nullptr) */
: _pstr(new char[1]())
{
cout << "String()" << endl;
}
String(const char *pstr)
: _pstr(new char[strlen(pstr) + 1]())
{
cout << "String(const char *)" << endl;
strcpy(_pstr, pstr);
}
String(const String & rhs)
: _pstr(new char[strlen(rhs._pstr) + 1]())
{
cout << "String(const String &)" << endl;
strcpy(_pstr, rhs._pstr);
}
String & operator=(const String & rhs)
{
cout << "String &operator=(const String &)" << endl;
if(this != &rhs)
{
if(_pstr)
{
delete [] _pstr;
}
_pstr = new char[strlen(rhs._pstr) + 1]();
strcpy(_pstr, rhs._pstr);
}
return *this;
}
size_t length() const
{
size_t len = 0;
if(_pstr)
{
len = strlen(_pstr);
}
return len;
}
const char * c_str() const
{
if(_pstr)
{
return _pstr;
}
else
{
return nullptr;
}
}
~String()
{
cout << "~String()" << endl;
if(_pstr)
{
delete [] _pstr;
_pstr = nullptr;
}
}
void print() const
{
if(_pstr)
{
cout << "_pstr = " << _pstr << endl;
}else{
cout << endl;
}
}
private:
char * _pstr;
};
void test0(){
String s1("hello");
//拷贝构造
String s2 = s1;
//先构造,再拷贝构造
//利用"hello"这个字符串创建了一个临时对象
//并复制给了s3
//这一步实际上new了两次
String s3 = "hello";
}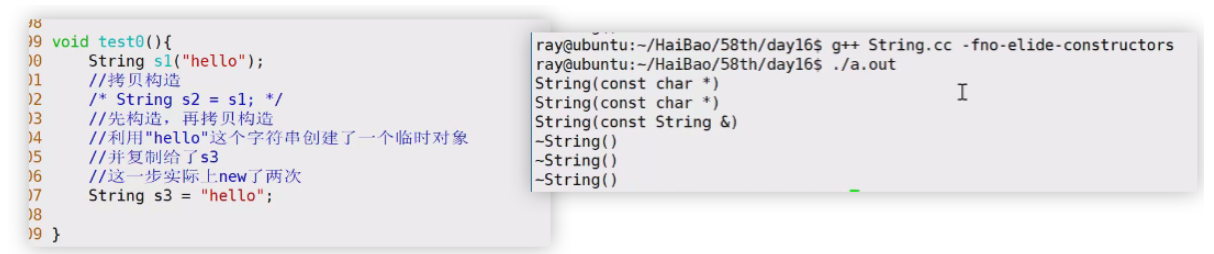
创建s3的过程中实际创建了一个临时对象,也会在堆空间上申请一片空间,然后把字符串内容复制给s3的pstr,这一行结束时临时对象的生命周期结束,它申请的那片空间被回收。这片空间申请了,又马上被回收,实际上可以视作一种不必要的开销。我们希望能够少new一次,可以直接将s3能够复用临时对象申请的空间。
这其实也可以视为是一种隐式转换。
注意:
编译后面加参数 -fno-elide-constructors(会取消编译器对函数的优化效果 尤其是拷贝构造)
如果还是没有出现上面的这种结果再在 后面加上 -std=c++11

左值与右值
左值和右值是针对表达式而言的,左值是指表达式执行结束后依然存在的持久对象,右值是指表达式执行结束后就不再存在的临时对象。
之前说的 右值只能放在等于号的右边(错误的)下面就是使用左值给左值赋值,编译器还没有报错,所以说明对左值和右值的最本质的区分就是能不能取地址。
那如何进行区分呢?其实也简单,能对表达式取地址的,称为左值;不能取地址的,称为右值。
在实际使用过程中,字面值常量、临时对象(匿名对象)、临时变量(匿名变量),都称为右值。右值又被称为即将被销毁的对象。
字面值常量,也就是10, 20这样的数字,属于右值,不能取地址。
字符串常量,“world",是属于左值的,位于内存中的文字常量区。
关于存储区域
右值的存储位置
关于右值的存储位置,它们可以存储在内存中,也可以仅存在于寄存器中,这取决于具体的实现和上下文。编译器优化策略在很大程度上影响了这一点:
在内存中存储: 尽管右值通常被视为临时的,但它们可以在内存中创建并存储,尤其是当它们是较大的对象或者编译器决定这样做更高效时。例如,一个复杂的右值对象(比如一个大的临时结构体或对象)可能会在内存中分配空间,以便存储其状态。
仅存在于寄存器中: 对于简单的右值(如基本数据类型的算术表达式结果),编译器可能会选择将其存储在寄存器中以优化性能。寄存器的使用减少了内存访问的需要,可以加快程序的执行速度。当一个右值用于简单表达式或作为函数参数传递时,这种情况更常见。
优化和存储决策
C++标准并没有具体规定对象必须存储在内存还是寄存器中,这留给了编译器作为实现细节。现代编译器使用复杂的优化策略来决定何时在内存中分配空间以及何时使用寄存器。这些决策基于减少程序的总运行时间和内存使用,同时还要满足程序的语义要求。
因此,是否一个右值会短暂存储在内存中或只会存在寄存器中,取决于多种因素,包括但不限于右值的类型、大小、上下文以及编译器的优化策略。在实际编程中,除非在性能调优阶段需要深入了解这些细节,否则开发者通常不需要过分关注这一点。
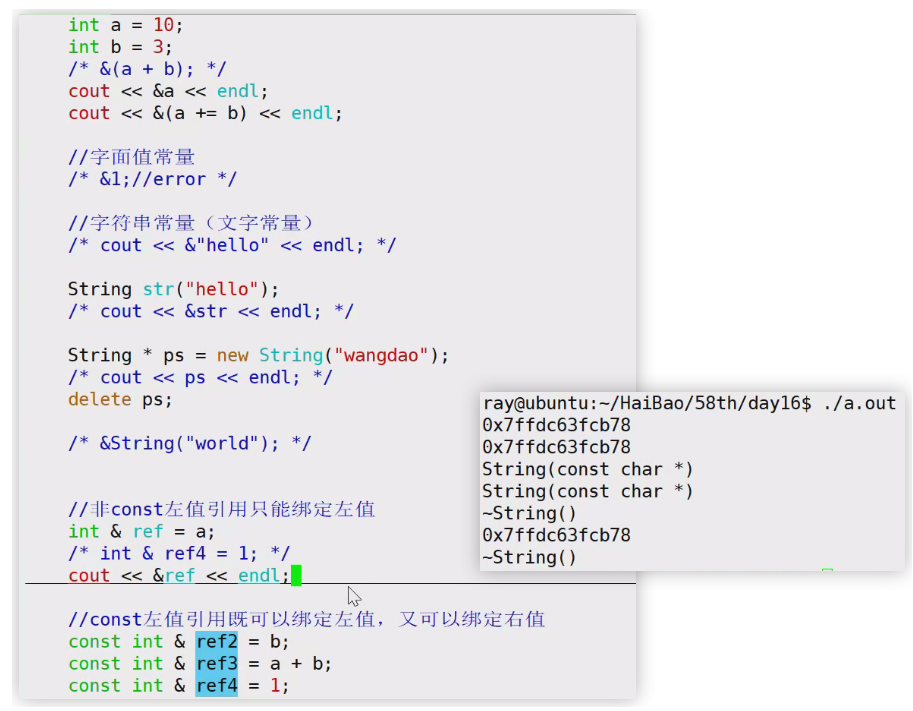
试试看下面这些取址操作和引用绑定操作是否可行:
void test1() {
int a = 1, b = 2;
&a;
&b;
&(a + b);
&10;
&String("hello");
//非const引用尝试绑定
int & r1 = a;
int & r2 = 1;
//const引用尝试绑定
const int & r3 = 1;
const int & r4 = a;
String s1("hello");
String s2("wangdao");
&s1;
&s2;
&(s1 + s2);
}如上定义的
int & r1和const int & r3叫作左值引用与const左值引用非const左值引用只能绑定到左值,不能绑定到右值,也就是非const左值引用只能识别出左值。
const左值引用既可以绑定到左值,也可以绑定到右值,也就是表明const左值引用不能区分是左值还是右值。
——希望能够区分出右值,并且还要进行绑定
就是为了实现String s3 = "hello"的空间复用需求。
对左值右值的认识
对其引用之后不可更改,因为引用的本质是指针,只是不能取到其地址,引用的本质类型是 指针常量(以int 为例 const int* p),就是不能改变其指向,但是可以改变指向目标的值。
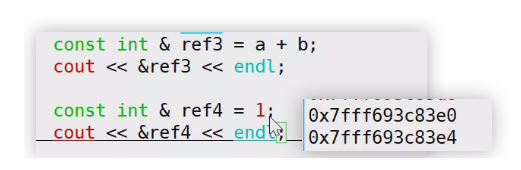
a+b是右值,虽然不能能对右值取地址,当他被const左值引用后,就可以对其取地址了,实际上他一开始就是存储在内存中的,只是不能够对其取地址,下面对 ref4 取地址就不一样了,1是存储在寄存器中的,对其const左值引用,其实是复制了一份存储在内存中,然后对其进行绑定。
右值引用
C++11提出了新特性右值引用
右值引用不能绑定到左值,但是可以绑定到右值,也就是右值引用可以识别出右值
//非const左值引用不能绑定右值 int & r1 = a; int & r2 = 1; //error //const左值引用既可以绑定左值,又可以绑定右值 const int & r3 = 1; const int & r4 = a; //右值引用只能绑定右值 int && r_ref = 10; int && r_ref2 = a; //error右值引用本身是左值还是右值?
—— 对r_ref取地址是可行的,r_ref本身是一个左值。但这并不代表右值引用本身一定是左值。
实际上,右值引用既可以是左值(比如:作为函数的参数、有名字的变量),也可以是右值(函数的返回类型)
这个问题,我们留到1.1.6章节再做讨论。
移动构造函数(重要)
有了右值引用后,实际上再接收临时对象作为参数时就可以分辨出来。
之前String str1 = String("hello");这种操作调用的是拷贝构造函数,形参为const String & 类型,既能绑定右值又能绑定左值。为了确保右值的复制不出错,拷贝构造的参数设为const引用;为了确保进行左值的复制时不出错,一律采用重新开辟空间的方式。有了能够分辨出右值的右值引用之后,我们就可以定义一个新的构造函数了 —— 移动构造函数。
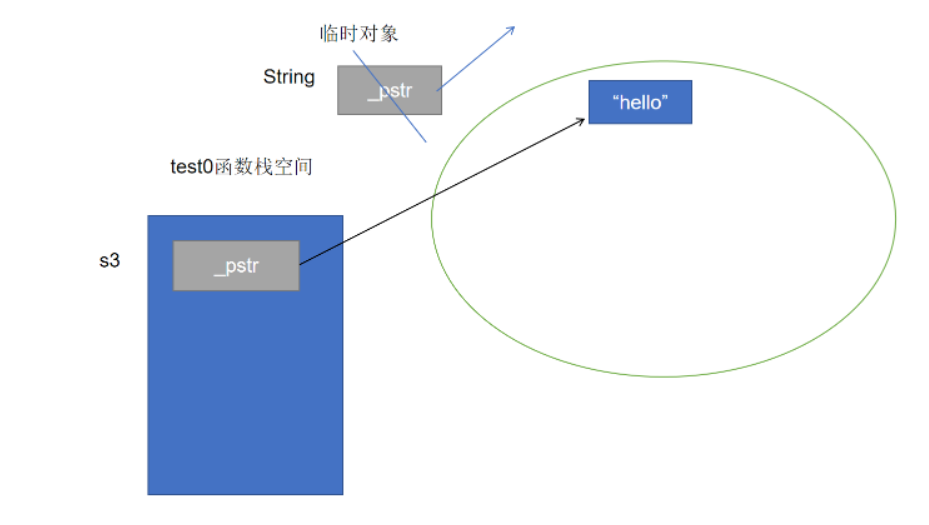
给String类加上移动构造函数,在初始化列表中完成浅拷贝,使s3的pstr指向临时对象的pstr所指向的空间(复用),还不能忘记要将右操作数(临时对象)的pstr设为空指针,因为这个临时对象会马上销毁(要避免临时对象调用析构函数回收掉这片堆空间)
String(String && rhs)
: _pstr(rhs._pstr)
{
cout << "String(String&&)" << endl;
rhs._pstr = nullptr;
}再运行代码String s3 = "hello";
加上编译器的去优化参数 -fno-elide-constructors
发现没有再调用拷贝构造函数,而是调用了移动构造函数。
对比函数形参的三种写法:

移动构造函数的特点:
1.如果没有显式定义构造函数、拷贝构造、赋值运算符函数、析构函数,编译器会自动生成移动构造,对右值的复制会调用移动构造。
2.如果显式定义了拷贝构造,而没有显式定义移动构造,那么对右值的复制会调用拷贝构造。
3.如果显式定义了拷贝构造和移动构造,那么对右值的复制会调用移动构造。
总结:移动构造函数优先级高于拷贝构造函数。
可以理解为:如果显式定义了拷贝构造和移动构造,利用一个已存在的对象创建一个新对象时,会先尝试调用移动构造,如果这个对象是右值,就使用移动构造函数创建出新对象,如果这个对象是左值,移动构造使用不了,就会调用拷贝构造。
移动赋值函数(重要)
有了移动构造函数的成功经验,很容易想到原本的赋值运算符函数。
比如,我们进行如下操作时
String s3("hello");
s3 = String("wangdao");原本赋值运算符函数的做法
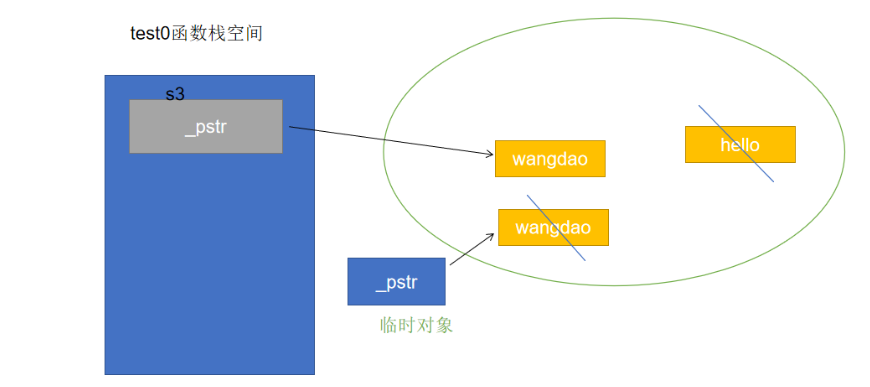
我们希望复用临时对象申请的空间,那么也同样需要赋值运算符函数能够分辨出接收的参数是左值还是右值,同样可以利用右值引用
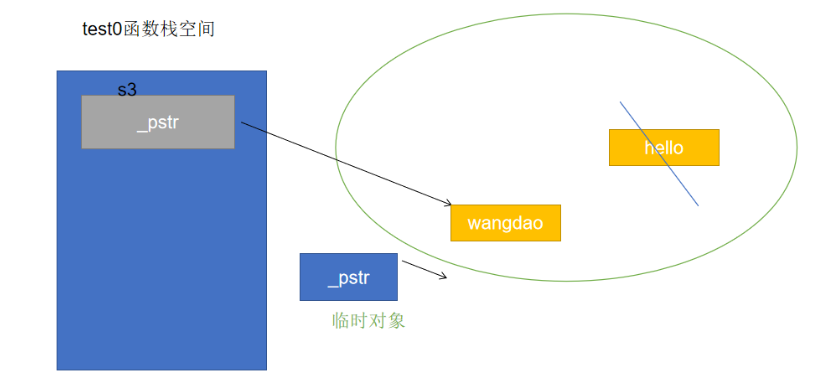
再写出移动赋值函数(移动赋值运算符函数)
String & operator=(String && rhs){ if(this != &rhs){ delete [] _pstr; //浅拷贝 _pstr = rhs._pstr; rhs._pstr = nullptr; cout << "String& operator=(String&&)" << endl; } return *this; }移动赋值函数的特点:
1.如果没有显式定义构造函数、拷贝构造、赋值运算符函数、析构函数,编译器会自动生成移动赋值函数。使用右值的内容进行赋值会调用移动赋值函数。
2.如果显式定义了赋值运算符函数,而没有显式定义移动赋值函数,那么使用右值的内容进行赋值会调用赋值运算符函数。
3.如果显式定义了移动赋值函数和赋值运算符函数,那么使用右值的内容进行赋值会调用移动赋值函数。
移动赋值函数优先级也是高于赋值运算符函数
总结:
将拷贝构造函数和赋值运算符函数称为具有复制控制语义的函数;
将移动构造函数和移动赋值函数称为具有移动语义的函数(移交控制权);
具有移动语义的函数优于具有复制控制语义的函数执行。
思考:移动赋值函数中的自赋值判断是否还有必要?
String s1("hello");
//右值给左值赋值,肯定不是同一个对象
s1 = String("world");
//创建了两个内容相同的临时对象,也不是同一对象
String("wangdao") = String("wangdao");来看下面代码,思考下面代码是不是,同一对象呢?
编译结果发现,并不是同一对象,发现编译器调用了两次构造函数和两次析构函数,所以不是同一对象。
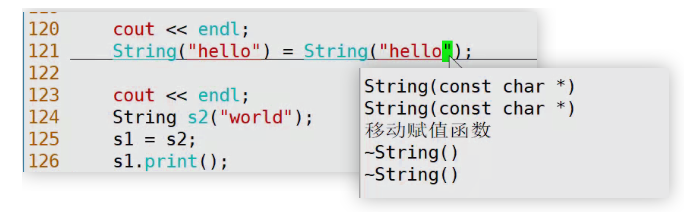
似乎去掉自复制判断不会造成问题,但是c++11提出了一种方式,将左值转为右值,就是std::move函数
std::move函数
在一些使用移动语义的场景下,有时需要将左值转为右值。std::move函数的作用是显式的将一个左值转换为右值,其实现本质上就是一个强制转换。
当将一个左值转换为右值后,如果利用右值引用绑定std::move的返回值,并进行修改操作,那么原来的左值对象也会随之修改,可能无法正常工作了,必须要重新赋值才可以继续使用。
void test() {
int a = 1;
&(std::move(a)); //error,左值转成了右值
String s1("hello");
cout << "s1:" << s1 << endl;
String s2 = std::move(s1);
cout << "s1:" << s1 << endl;
cout << "s2:" << s2 << endl;
}下面代码中的s1不能正常使用是因为,在移动构造中,将左值的指针指向右值的指针指向的地址,然后将右值指针置空,这样再使用print()的时候就不能访问到之前s1的内容了。如果再没有判空操作就会使程序中断。
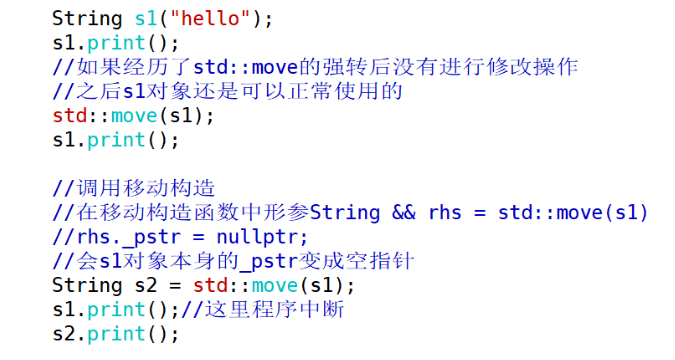
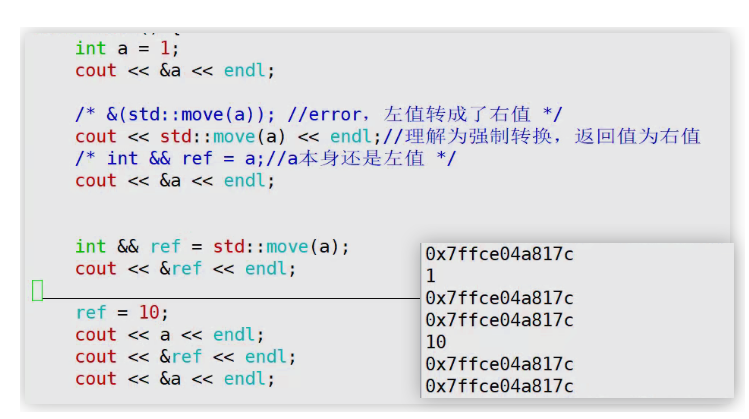
下面代码中,先定义一个a,为左值,打印地址,然后对std::move(a)取地址发现不可以,因为他返回值为右值属性,(可以理解为欺骗了编译器,因为a本质还是没有变化的),因为返回值为右值属性,所以ref 使用右值引用就可以绑定td::move(a),然后对ref取地址发现他绑定的地址还是a原来的地址,对ref赋值,然后再打印a,发现a的值也发生了变化。(所以可以理解为欺骗了编译器,因为a的本质还是左值)
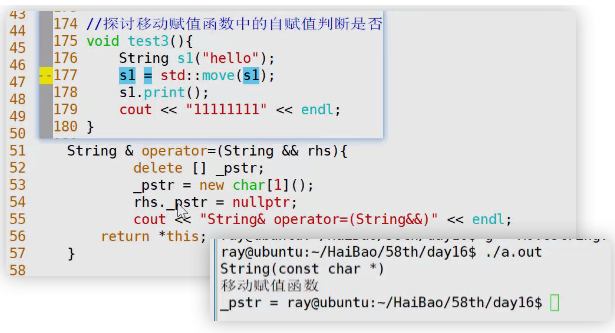
如果将移动赋值函数的自赋值判断去除,如下情况依然会调用移动赋值函数,但是s1的pstr所指向的空间被回收,且被设为了空指针,会出错
String s1("hello");
s1 = std::move(s1);
s1.print();
验证:将移动赋值函数中的浅拷贝去掉,让左操作数s1 的 _pstr重新指向一片空间,后面对右操作数的 _pstr设为空指针,
但是通过输出流运算符输出s1的 _pstr依然造成了程序的中断,所以说明对std::move(s1)的内容进行修改,会导致s1的内容也被修改。
std::move的本质是在底层做了强制转换(并不是像名字表面的意思一样做了移动)
String & operator=(String && rhs){
delete [] _pstr;
_pstr = new char[1]();
rhs._pstr = nullptr;
cout << "String& operator=(String&&)" << endl;
return *this;
}下面这种验证方法,没有自赋值判断,下面这种方式本质还是将s1的指针设为空指针(因为本身就是一个指针,s1一直是没有变化的),在使用print()时,就不能访问,会出现空指针,使得程序断掉。
下面是没有检查自赋值的情况,本质也是将自己的指针置为了空指针,使得最后使用空指针来访问地址,使得程序崩溃。
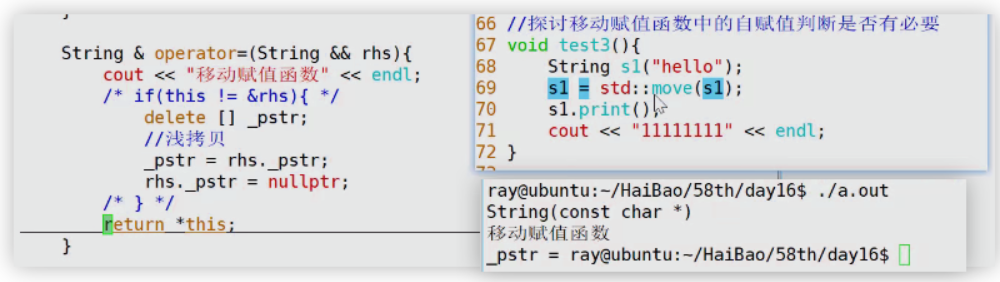
—— 所以移动赋值函数的自赋值判断不应该省略。
当有自赋值判断时,就不会出现上面这种情况。因为 使用右值引用后对std::move取地址,本身就是this指针的地址,所以两个地址是相同的,所以就会直接return *this;不会对最后结果产生影响。

右值引用本身的性质
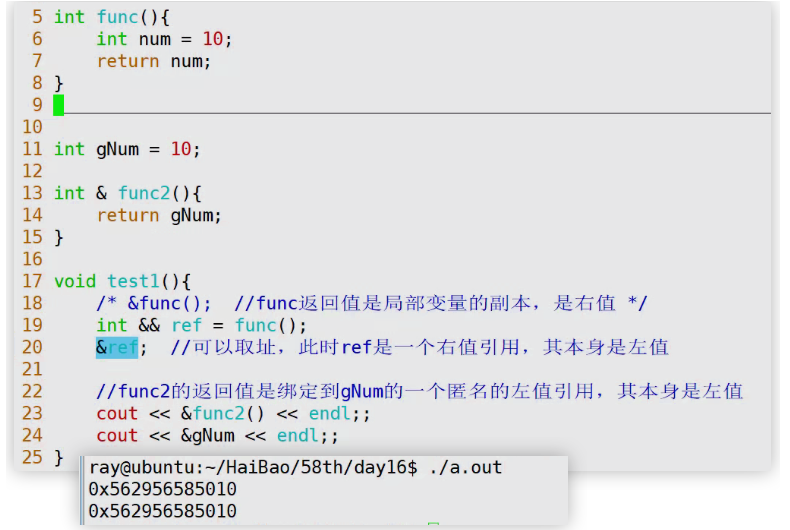
我们来定义一个返回值是右值引用的函数
int gNum = 10;
int && func(){
return std::move(gNum);
}
void test1(){
// &func(); //无法取址,说明返回的右值引用本身也是一个右值
int && ref = func();
&ref; //可以取址,此时ref是一个右值引用,其本身是左值
}当返回值为匿名的右值引用,其本质还是右值,不能够取地址,如果再使用右值引用来进行绑定,对其取地址会报警告,因为其地址不在内存中,而是存在在寄存器中不会隐式生成对象存储。 下面解释和 int && ref = 1; 的区别
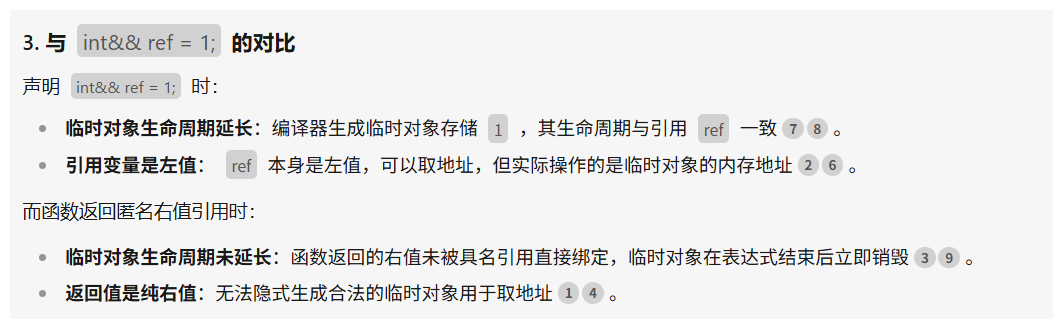
右值引用本身是左值还是右值,取决于是否有名字,有名字就是左值,没名字就是右值。

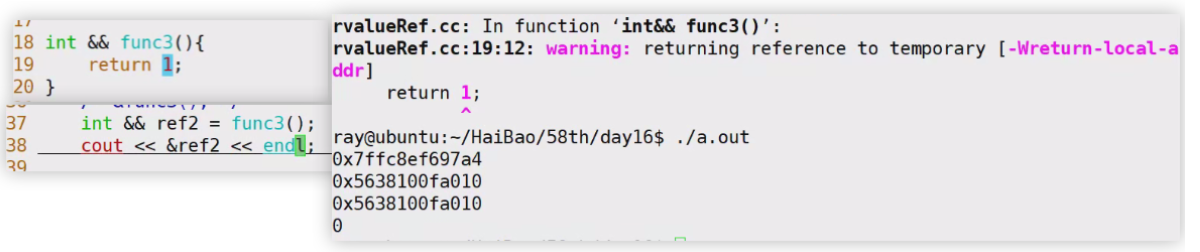
值得一提的是,如果我们写出如下的代码,func的返回值是一个匿名右值引用,其绑定的内容是一个即将销毁的右值,这是一个不安全的操作,因为func2的返回值,这个没有名字的右值引用无法持续有效地延长这个临时变量的生命周期,这个临时变量本体销毁后,返回值真实的性质是一个”悬空引用“。接下来虽然还能用右值引用绑定这个返回值,但是任何尝试访问的行为都可能导致未定义的错误。
int && func(int a,int b){
return a + b;
}
void test1(){
// &func(1,2); //无法取址
int && ref = func(1,2);
&ref;
}
对拷贝构造调用时机的补充
String func2(){
String str1("wangdao");
str1.print();
return str1;
}
void test2(){
func2();
//&func2(); //error,右值
String && ref = func2();
&ref; //右值引用本身为左值
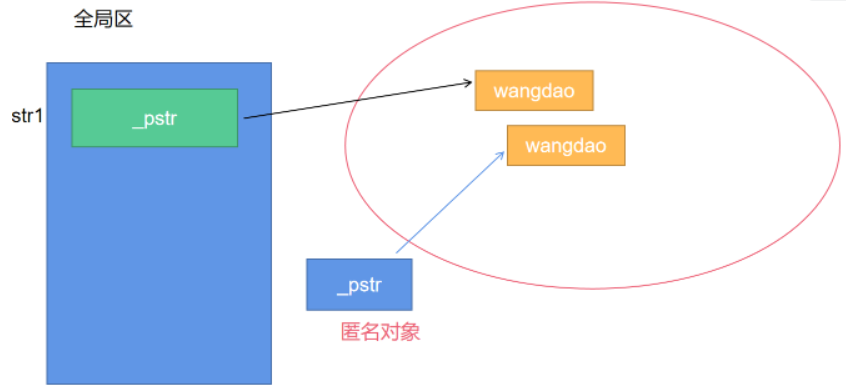
}当返回值为一个将要销毁的局部对象,这里就不使用拷贝构造了,因为str1将要销毁,销毁的对象直接移交控制权给返回值,也就是移动构造。
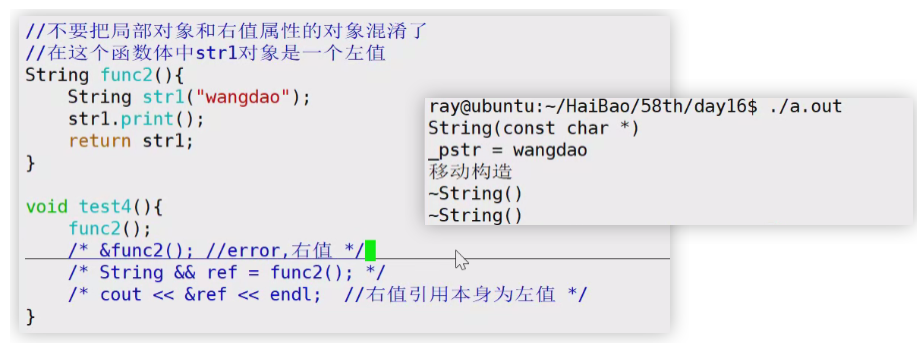
这里func2的调用按以前的理解会调用拷贝构造函数,但是发现结果是调用了移动构造函数(编译器的底层对左值对象进行处理了,所以可以使用移动构造)。
当返回的对象其本身生命周期即将结束,就不再调用拷贝构造函数,而是调用移动构造函数。

如果返回的对象其本身生命周期大于func3函数,执行return语句时还是调用拷贝构造函数
String s10("beijing");
String func3(){
s10.print();
return s10;
}
void test3(){
func3(); //调用拷贝构造函数
}
总结:当类中同时定义移动构造函数和拷贝构造函数,需要对以前的规则进行补充,调用哪个函数还需要取决于返回的对象本体的生命周期。


















 964
964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









