






数据库设计
- 数据库开发生命周期
可行性分析→ 数据库设计(概念设计、逻辑设计、物理设计)→ 数据库实现 → 测试 → 维护
主要看数据库设计:
1.概念设计(E/R图)
独立于DBMS,不需要考虑物理结构。需要用户的需求规格说明。
2.逻辑数据库设计
需要明确数据库的类型(关系数据库?网状数据库?层次?等等),也不需要考虑物理细节。
需要考虑映射关系:

从E/R模型变成关系模型的映射。
从联系映射成关系(一个表),里面的属性是连接实体的码或是联系自带的属性。
3.物理数据库设计
存储结构、存取方法(顺序访问、随机访问),做到高效的存储和读取。
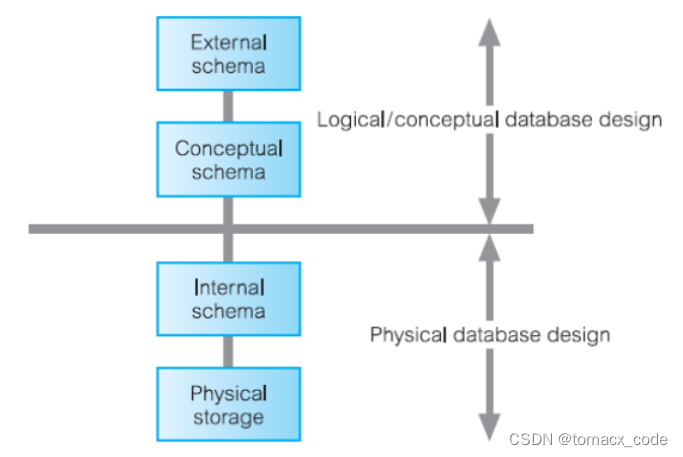
上图为三者的联系示意图。 - E/R模型
E/R模型静态地展示数据库结构的设计,包括了完整性约束但是不包括操作。
E/R模型的一些元素:实体(Entity)、实体集(Entity Sets)、属性(Attributes)、属性取值范围(Attribute Domain)、码(Keys)、联系(Relationship)、联系类型(Relationship Type)
1.实体集
是一些拥有相同性质的实体组成的集合
2.属性
包括单属性和复合属性
单属性:独立存在
复合属性:两个属性以上,比如说地址(省、市、镇)。
单值属性:单个值。
多值属性:多个值,比如说,一个人可以拥有很多个手机号。
派生属性:算出来的值
3.码
候选码(CK)、主码(PK)、备用码(AK)、复合候选码(Composite Key)
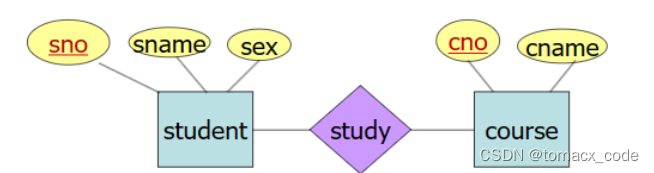
E/R图
实体集-长方形表示
属性-椭圆表示
主键-下划线
联系-用菱形表示
多值属性用两个椭圆,虚线椭圆表示派生属性、属性再连出去椭圆表示复合属性。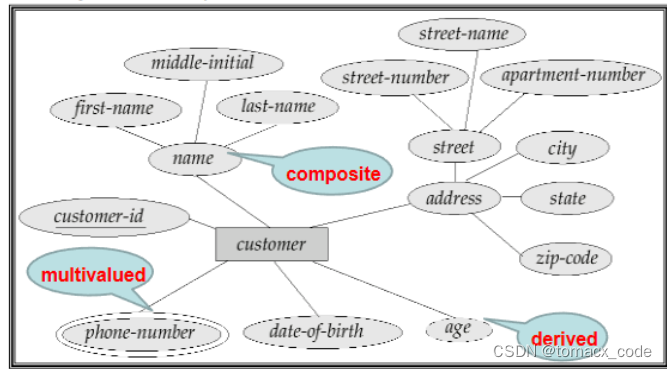
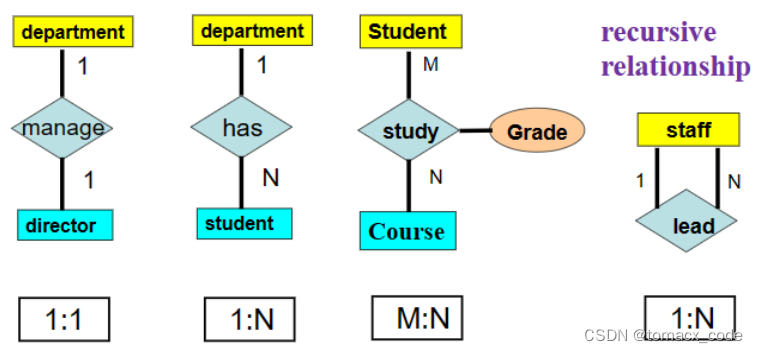
联系的类型
联系的元数:参与联系的实体集的个数。
(二元联系、三元联系、四元联系)
二元联系
一对一、一对多、多对多。
ER建模
1.划分实体集和属性
确认好实体、属性、联系
- 1.1尽可能把数据描述为属性,然后不需要进一步得描述,属性只和自己的实体有关系(除非是外键),一个实体可以拥有多个属性。
- 1.2联系的名称一般为动词;实体的名称一般为名词,实体名称不允许为“XX记录(信息、表、信息表、数据)”;实体1-联系-实体2,一般是一句完整的话,描述一个语义。
- 1.3多对多的relationship可以自带属性,把两个表的候选码拿出来+relationship自带的属性构成一张表。
设计的技术(Design Technology)
- 消除冗余
好的设计是没有冗余的
- 实体VS属性
实体,除了名称(PK),还应该有其他属性,就是实体至少应该有一个非主属性。
或者他是一个一对多或者多对多联系的多端,则它可以只包含一个主键,没有非主属性。(不过这样的话信息容易缺失,设计的表中还是至少得有三列)
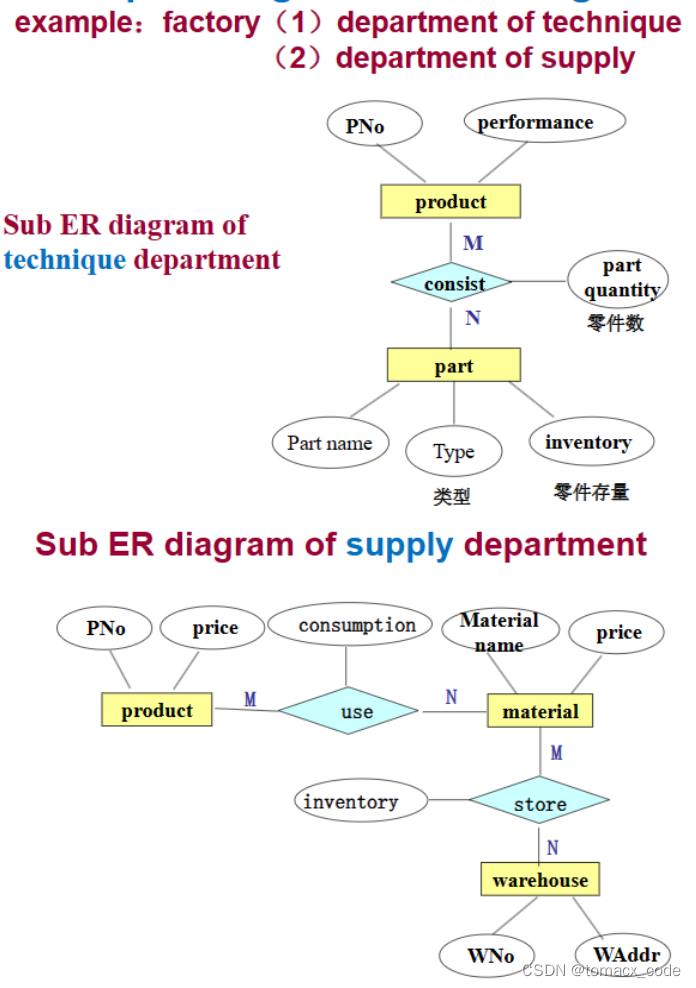
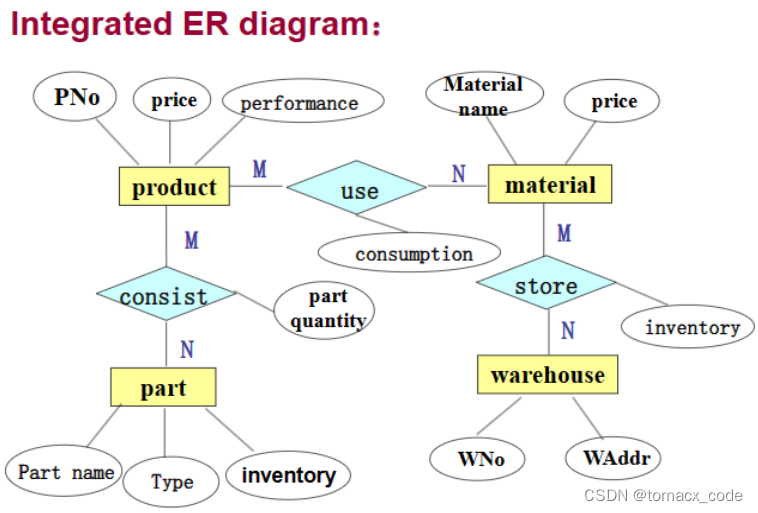
2.合并子ER图
把子ER图都合并起来,消除冗余然后生成一个完整的ER图
将子ER图一步步合并在一起
强化的ER模型
加入:
-子类(特殊化)/父类(泛化)(Isa)
-聚合(‘has-a’ or ‘is part of’)
-组合(a special form of aggregation)
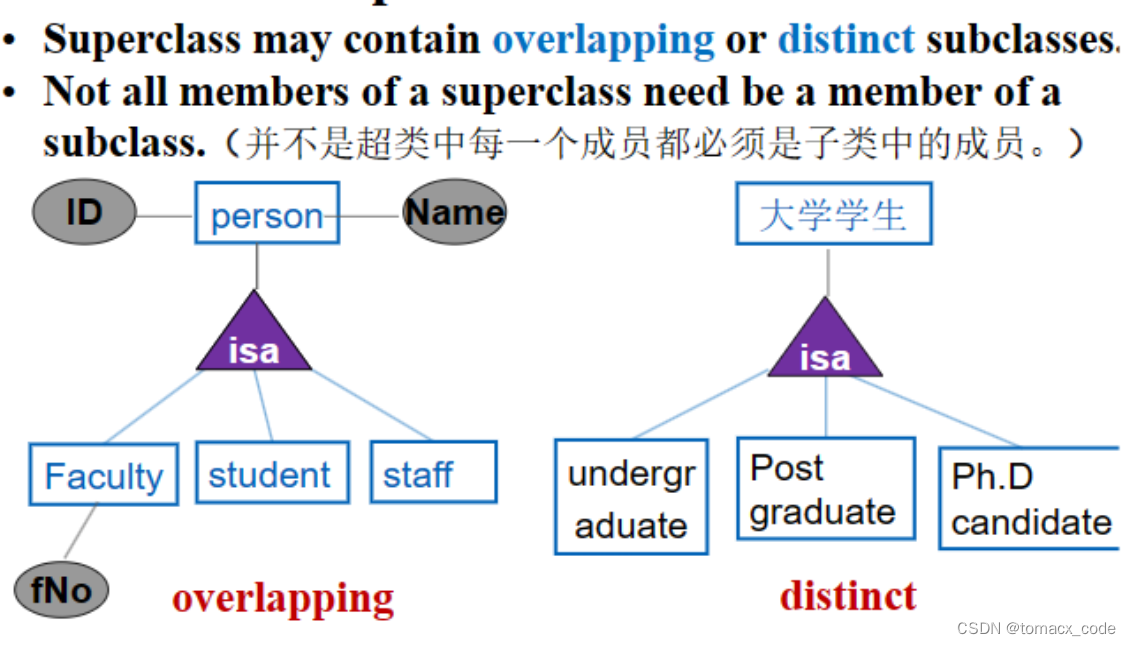
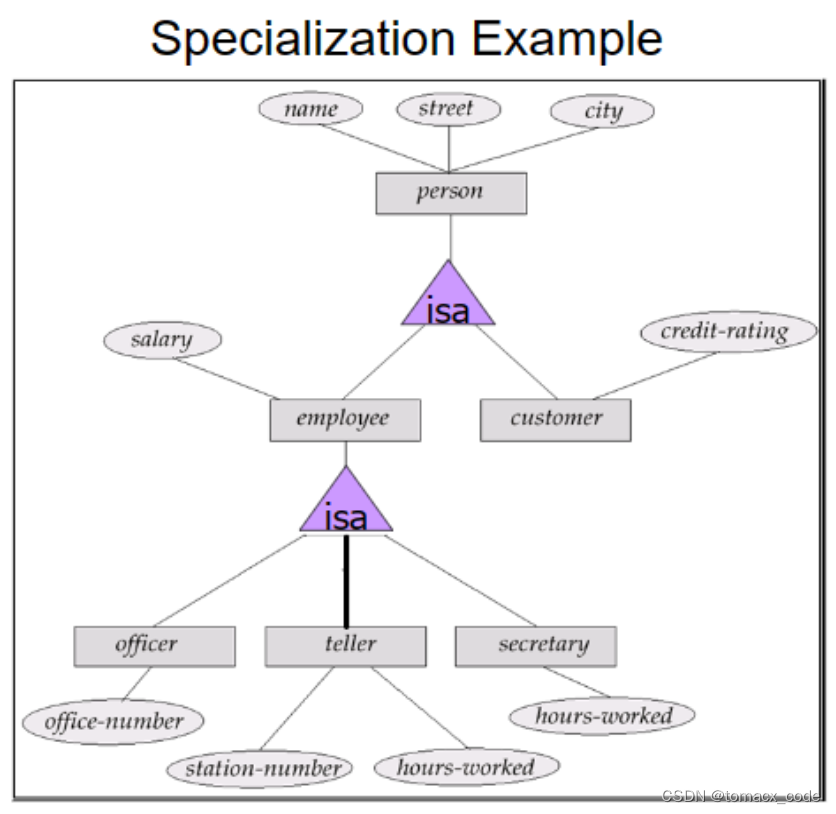
1.Specialization(特殊化,找差异)/Generalization(泛化、找共同点)
前者就是最大差异(子类),后者就是最小差异(父类)。
Subclass = speacial case = fewer entites = more properties
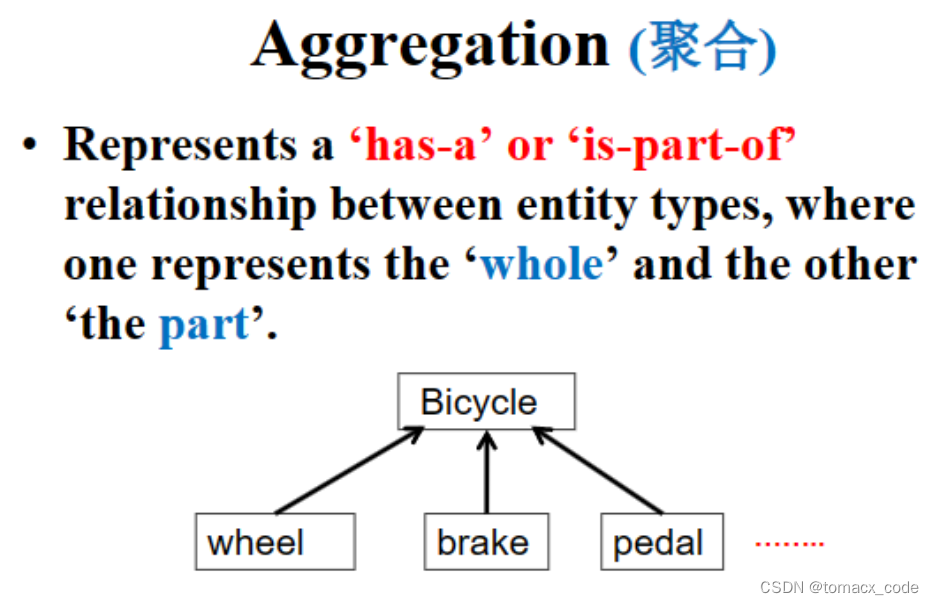
2.Aggregation(聚合)
表示一种拥有或者一部分的关系,不具有相同的生命周期。

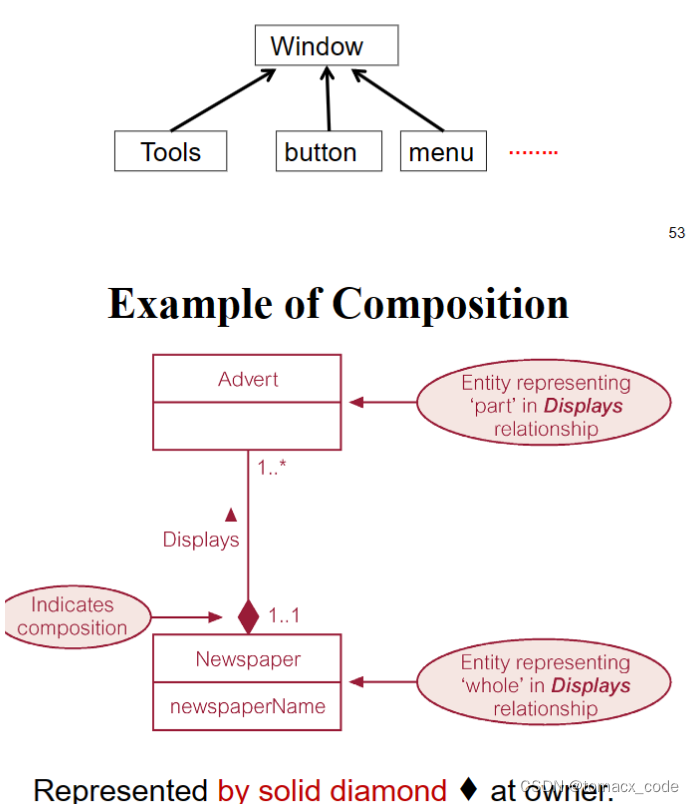
3.Composition(组合)
具有相同的生命周期。
-
E/R模型转换成表格
1.拆开所有的符合属性,确保所有的属性都是simple attribute
2.用主键/外键表示联系,父端的主键拿出来给子端做外键。
2.1父端/子端如何找
在一对一联系中,查询次数多的作为子端,查询次数多的作为父端。
在一对多联系里,“1”端指定为父端。
多对多的联系中,就把两端的属性拿出来和联系带有的属性一起形成一张表。
3.模式细化
表格要有简单的意义,数据少量复制,尽可能少的空值,好的一个表现。
需要用到规范化的内容。
(详细的规范化内容介绍关系数据理论)总结:数据库设计追求语义的明确、数据不要冗余、不要出现三种更新异常,E/R图的画法要规范以便于构造数据库的物理结构。















 2306
2306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









