






本篇文章是初学YOLO整理的笔记,记录YOLO基础知识
前言
以下是对 YOLO 基础知识 的 超详细记录,涵盖从目标检测基础到 YOLO 核心概念的完整内容,每个关键点都清晰易懂。
一、目标检测基础
1. 目标检测的任务
目标检测需要完成以下两个任务:
- 定位(Localization):找到图像中物体的位置(用边界框表示)。
- 分类(Classification):判断物体属于什么类别(如猫、狗、人等)。
2. 核心概念
(1) 边界框(Bounding Box)
- 定义:矩形框,用于标定物体的位置。
- 两种表示方式:
- 绝对坐标:
(x_min, y_min, x_max, y_max)- 左上角和右下角的像素坐标。
- 归一化中心坐标(YOLO 使用):
(x_center, y_center, width, height)x_center = 中心点横坐标 / 图像宽度y_center = 中心点纵坐标 / 图像高度width = 框宽 / 图像宽度height = 框高 / 图像高度- 所有值在
[0,1]之间。
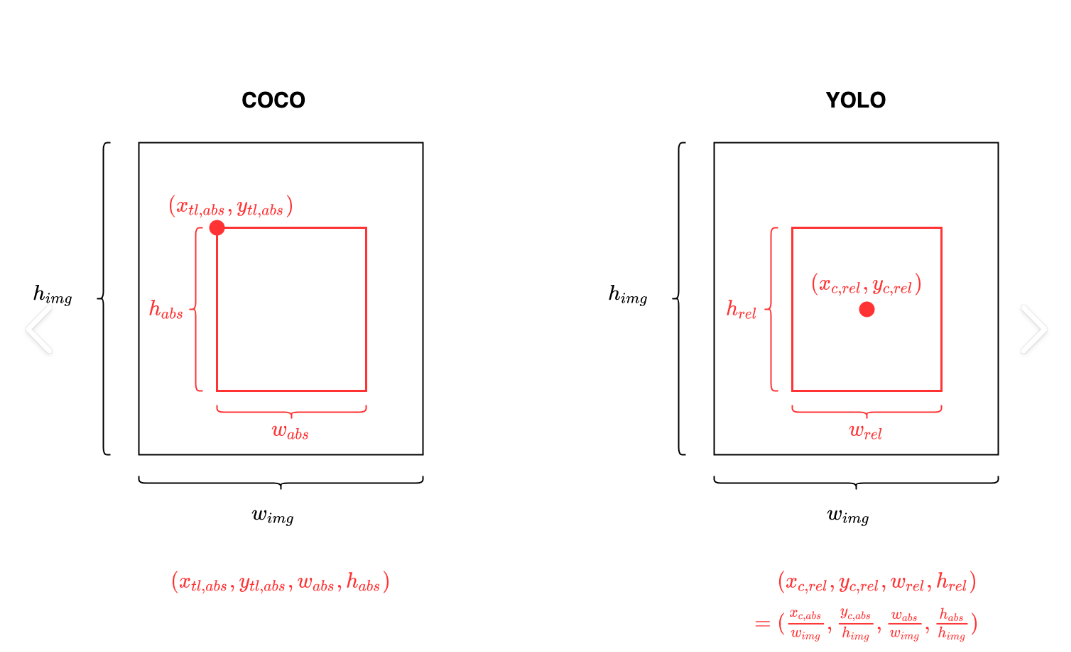
- 绝对坐标:
(2) 置信度(Confidence Score)
-
定义:模型对预测框内存在物体的信心程度,值在
[0,1]之间。 -
公式:
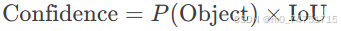
P(Object):预测框内有物体的概率。IoU:预测框与真实框的交并比。
(3) IoU(交并比,Intersection over Union)
-
作用:衡量预测框与真实框的重合程度。
-
公式:

- 如果 IoU > 0.5,通常认为预测框是正确的。
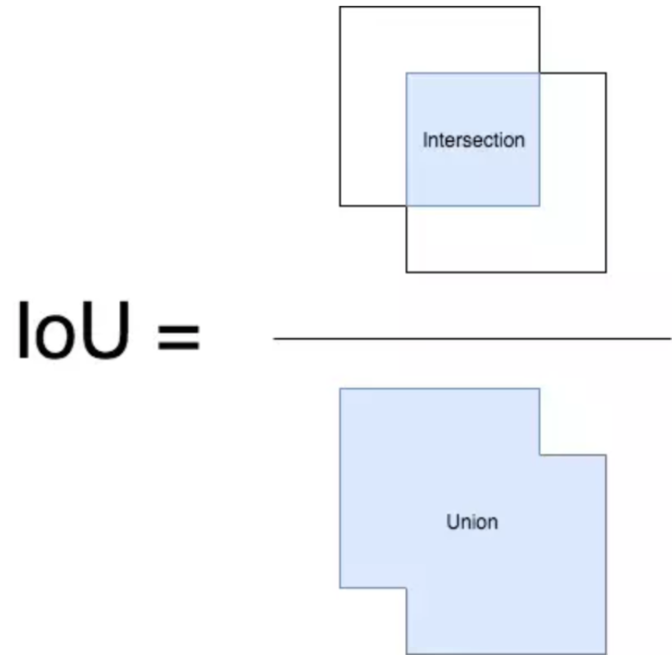
- 如果 IoU > 0.5,通常认为预测框是正确的。
(4) 非极大值抑制(NMS,Non-Maximum Suppression)
- 问题:模型可能对同一物体预测多个重叠的边界框。
- 解决:保留置信度最高的框,抑制其他重叠框。
- 步骤:
- 按置信度从高到低排序所有预测框。
- 从最高置信度的框开始,移除所有与之 IoU 超过阈值(如 0.5)的框。
- 重复步骤 2,直到所有框被处理。
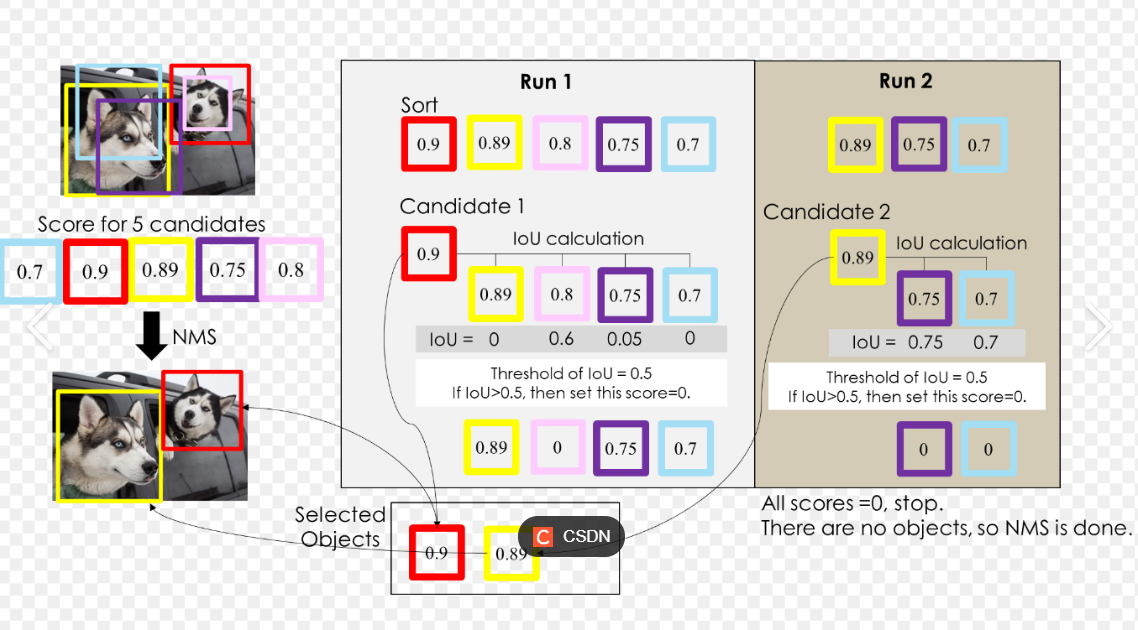
(5) mAP(平均精度,mean Average Precision)
- 定义:目标检测模型的核心评价指标,综合考虑精度(Precision)和召回率(Recall)。
- 计算步骤:
- 对每个类别,计算不同置信度阈值下的 Precision 和 Recall。
- 绘制 P-R 曲线,计算曲线下面积(即 AP)。
- 对所有类别的 AP 取平均,得到 mAP。
二、YOLO 核心原理
1. YOLO 的核心思想
- 核心口号:You Only Look Once(只看一次)。
- 特点:单阶段检测(One-Stage),将检测任务视为回归问题,直接在图像网格上预测边界框和类别概率。
2. YOLO 的通用流程
以 YOLOv3/YOLOv5 为例,流程如下:
- 输入图像预处理:将图像缩放到固定尺寸(如 640×640)。
- 特征提取:使用卷积神经网络(如 Darknet-53)提取多尺度特征图。
- 多尺度预测:在不同尺度的特征图上预测边界框(小尺度检测大物体,大尺度检测小物体)。
- 后处理:通过 NMS 筛选最终结果。
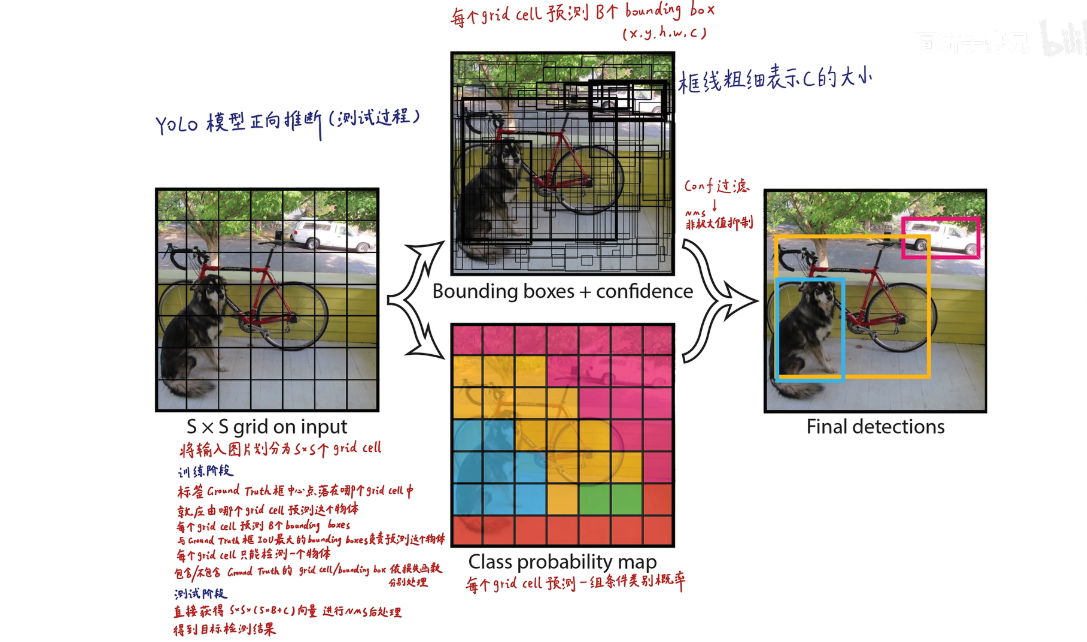
3. YOLO 的详细技术点
(1) 网格划分(Grid Cells)
- 将输入图像划分为
S×S的网格(如13×13)。 - 每个网格负责预测:
B个边界框(Bounding Box)。- 每个边界框的坐标
(x, y, w, h)和置信度(Confidence)。 C个类别的概率(每个网格预测一次类别)。

(2) 锚框(Anchor Boxes)
-
定义:预先定义的一组边界框模板(如
(10×13), (16×30), ...),用于捕捉不同形状的物体。 -
作用:模型预测的是相对于锚框的偏移量,而不是直接预测绝对坐标,提升定位精度。
-
偏移量计算:
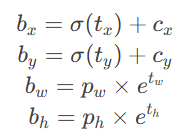
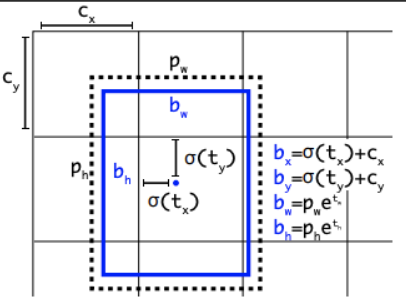
(c_x, c_y):网格左上角坐标。(p_w, p_h):锚框的宽高。(t_x, t_y, t_w, t_h):模型预测的偏移量。σ:Sigmoid 函数,将坐标约束在[0,1]。
(3) 多尺度预测(Feature Pyramid)
- 目的:解决小物体检测难题。
- 方法:在不同层级的特征图上进行预测:
- 高层特征图(分辨率低):检测大物体。
- 低层特征图(分辨率高):检测小物体。
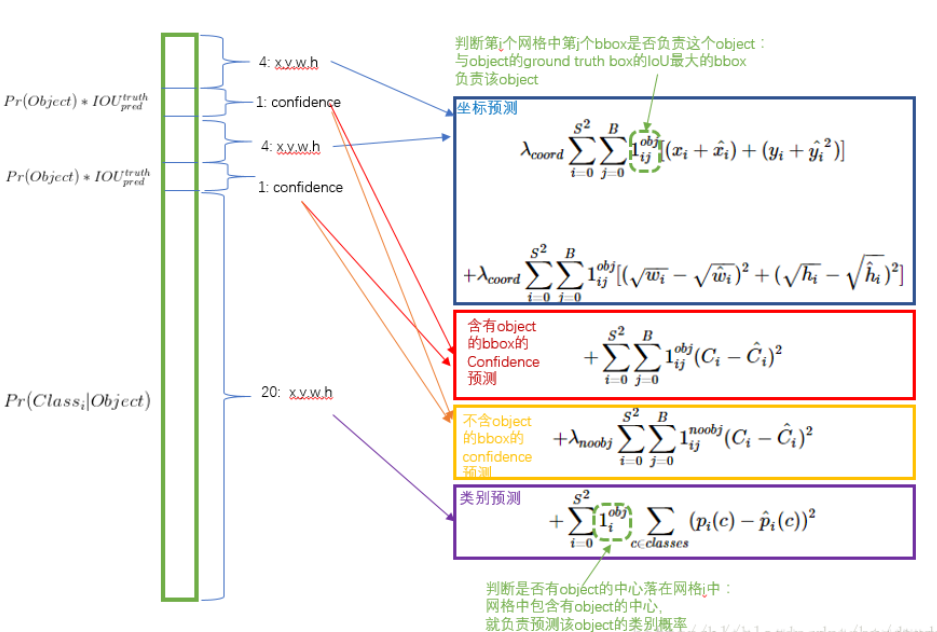
(4) 损失函数(Loss Function)
YOLO 的损失函数由三部分组成:
- 边界框坐标损失(均方误差):

- 置信度损失(交叉熵):
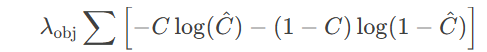
- 类别损失(交叉熵):
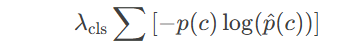
λ是权重系数,用于平衡不同损失项。
4. YOLO 的不同版本对比
| 版本 | 核心改进 |
|---|---|
| YOLOv1 | 首次提出网格划分和直接回归预测框。 |
| YOLOv2 | 引入锚框(Anchor Boxes)和批量归一化(BatchNorm)。 |
| YOLOv3 | 多尺度预测、更深的网络(Darknet-53)、使用残差连接。 |
| YOLOv4 | 引入 CSPDarknet、PANet、Mish 激活函数,优化训练策略。 |
| YOLOv5 | 简化代码实现、优化数据增强、支持更灵活的部署。 |
三、YOLO 的数学推导
1. 边界框解码(从模型输出到实际坐标)
假设模型输出为 (t_x, t_y, t_w, t_h),锚框尺寸为 (p_w, p_h),网格左上角坐标为 (c_x, c_y):
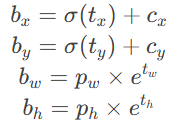
- 关键点:使用 Sigmoid 函数将
t_x, t_y约束在[0,1],确保边界框中心位于当前网格内。
2. 置信度与类别概率
- 置信度通过 Sigmoid 函数输出,表示“框内有物体”的概率。
- 类别概率通过 Softmax 或独立的 Sigmoid 输出(YOLOv3 之后使用 Sigmoid 支持多标签分类)。
四、实战前的知识检验
1. 练习题
-
计算 IoU
- 真实框:
(x1=10, y1=10, x2=50, y2=50) - 预测框:
(x1=30, y1=30, x2=80, y2=80) - 求 IoU(答案:0.175)。
- 真实框:
-
解码边界框
- 模型输出:
t_x=0.3, t_y=0.4, t_w=0.2, t_h=0.1 - 锚框尺寸:
p_w=20, p_h=30 - 网格左上角坐标:
c_x=5, c_y=5 - 求实际边界框坐标(答案:
b_x=5.57, b_y=5.60, b_w=24.43, b_h=33.16)。
- 模型输出:
2. 思考题
- 为什么 YOLO 要使用锚框?
答:锚框提供先验知识,帮助模型更高效地学习不同形状物体的位置偏移。
总结
以上内容对 YOLO 的基本概念、数学原理和实现细节进行初步总结。接下来可以开始动手配置环境并训练自己的模型了。

















 5662
5662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









